





栏目介绍
头号作家
■ luckyfish
■ 专注大数据领域业务问题的解决和性能优化,提升大数据服务使用体验。6年大数据经验,做业务同学最信任的技术朋友!
01
减少大表扫描
02
增加并行度-聚合操作拆分
03
避免数据倾斜
04
避免大量shuffle操作
01
业务逻辑优化
02
读数据的优化
01
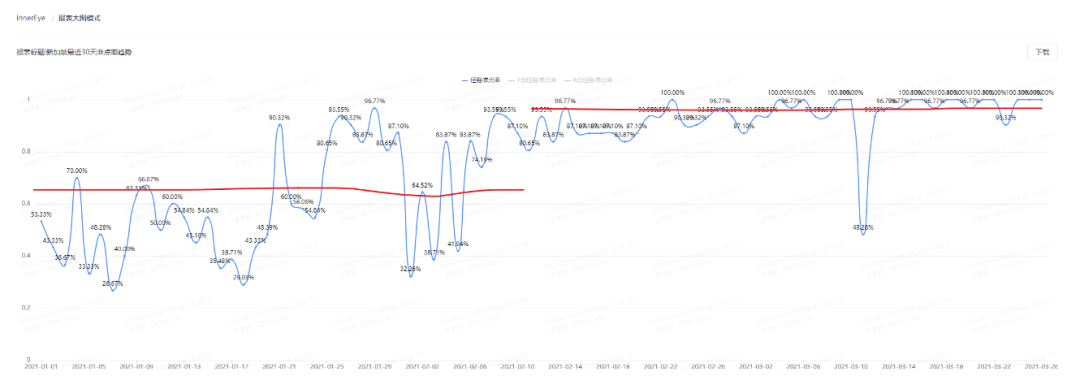
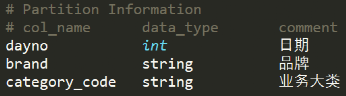
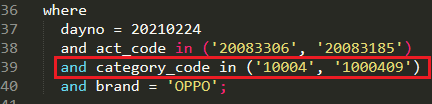
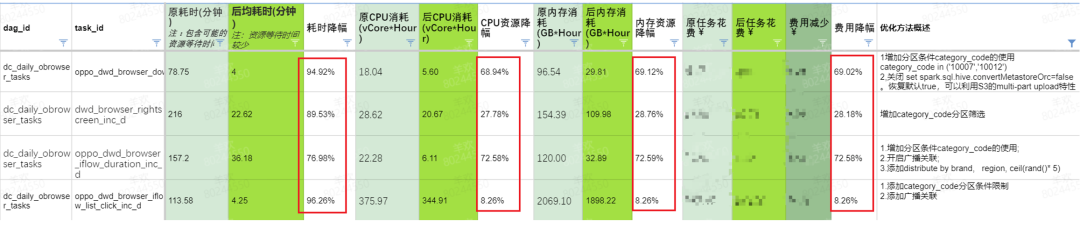
充分利用所有分区条件
02
数据分块的优化设置

03
算的优化
01
少算 - 确保数据去重后再做关联

02
少算 - 去除无意义的代码


03
争取更多资源用于计算 - 增加并行度

04
少算 - 一次就成功,减少任务重试


04
写的优化
01
同时解决小文件和写任务倾斜


02
文件格式
05
资源申请优化
01
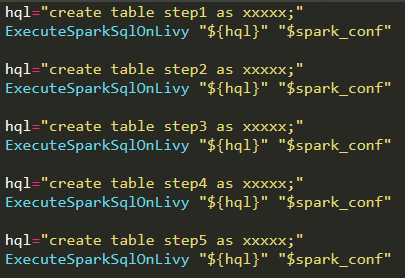
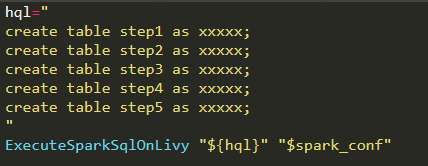
代码块本身分散,可直接拼接一起
02
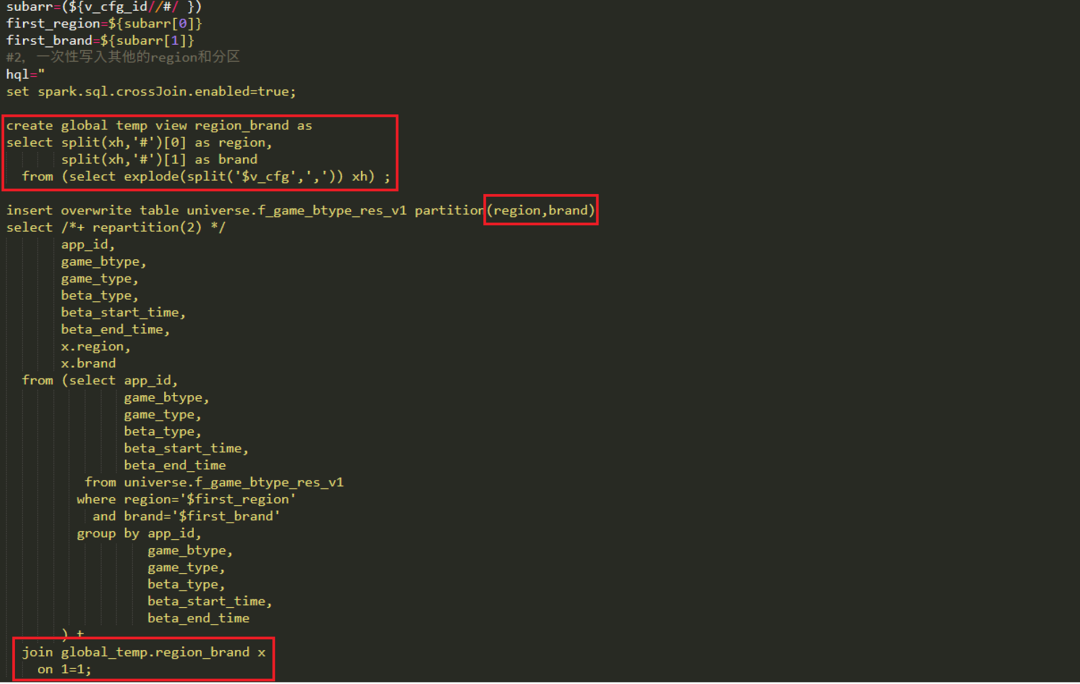
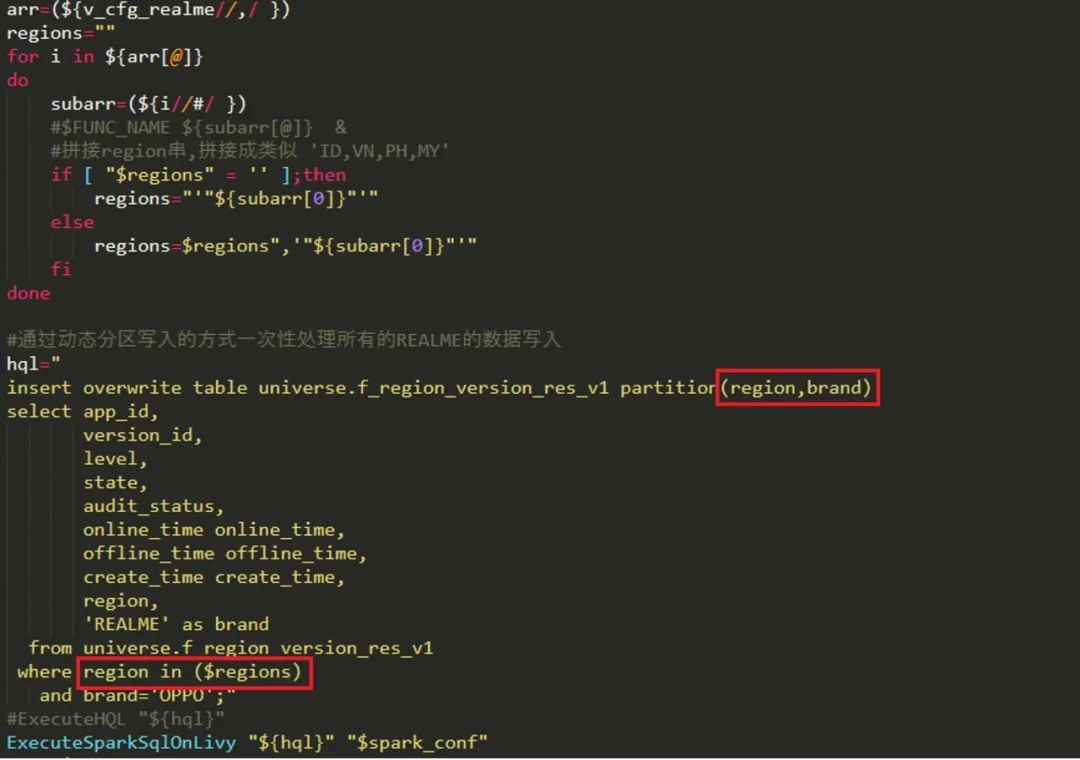
代码需要进行适当改造才能拼接

06
规范优化
01
Hive表与mysql表交互
02
代码格式
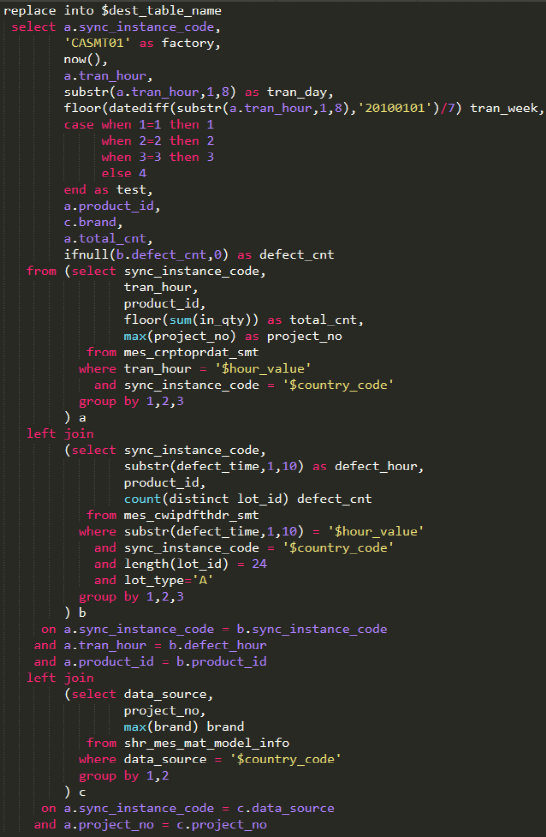
03
参数滥用问题
07
优化思路图



【宠粉时间】
回答以下问题,多重好礼等你来哦!(答案请在文中寻找)
数据计算的第一步是什么?哪两个方面需要特别注意呢?
【活动时间】
从推文发布时间起—12月10日 12:00
【奖品设置】
书包(1个)
蓝牙键盘(2个)
快来动动你的手指吧!






文章转载自OPPO TECH,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
