环境:
Ubuntu16.04 x64虚拟机,网络模式桥接,固定IP:192.168.0.109,当作Master节点
CentOS7 x64虚拟机,网络模式桥接,固定IP:192.168.0.112,当作Slave1节点
测试两台机器的IP是可以ping通的。
Hadoop 版本:3.0.0-alpha2
Java 版本:jdk8u121
2 准备工作:
2.1 修改host名字
所谓host名字,就是在网络上显示的名字。
2.1.1 修改/etc/hostname文件
该文件名字只有一行,即hostname,ubuntu的一般为ubuntu,centos可能就是各种奇奇怪怪的名字了。
在这里,将ubuntu的hostname改为Master.Hadoop。将centos的改为Slave1.Hadoop。
master和slave可以理解为字面意思,在Hadoop里其实就是namenode和datanode的关系,在mapreduce里就是 jobtracker和tasktracker的关系,在yarn里就是resourcemanager和nodemanager的关系。
2.1.2 修改/etc/hosts文件
该文件就如DNS解析一般,将hostname和IP对应。
默认会有一行:127.0.0.1 localhost
我们要做的是在后面加上127.0.0.1 Master.Hadoop(Slave1.Hadoop)。
2.1.3 查看结果
直接在终端输入hostname,在我这里centos没有问题直接修改过,而ubuntu重启了机器才生效。
2.2 新建Hadoop用户
几乎每篇教程都会提到这个问题。为什么一定要用Hadoop用户?用其他用户当然也是可以的,但是为Hadoop专门建立用户,比较安全,也会保证路径一致。Master节点的守护进程开启的时候,会去Slave节点相同的路径启动。
需要用useradd -d /home/hadoop -m hadoop
其中,d参数指定了hadoop的用户文件夹,m参数指定了用户名。
2.3 ssh无密码登录
这是老生常谈的话题了,但是里面还是会有坑。
2.3.1 ssh服务器下载
centos好像默认自带openssh-server,而ubuntu可能需要下载。
centos的命令是:yum install openssh-server
ubuntu的命令是:apt-get install openssh-server
如果ubuntu报找不到apt源,可以去我的博客翻一翻我的older posts。
安装完以后可以在终端输入ssh试试看。
2.3.2 ssh钥匙
运行: ssh-keygen -t rsa
一路enter下去,会在/home/用户/.ssh/下创建公钥(id_rsa.pub)和私钥(id_rsa)。
而ssh认证的文件叫做authorized_keys,里头存放各种公钥,这个文件默认是不生成的。
所以要么把公钥拷贝成这个名字,要么用cat指令。其中,cat 文件A >文件B,跟cp命令无差别。而cat 文件A >>文件B,则是append在末尾。我们选择第二种,因为公钥肯定不止一个。
这里首先把刚刚生成的本地的公钥拷贝一份至authorized_keys。
2.3.3 公钥共享,免密登录
在这里澄清一个概念。A电脑的公钥拷贝给B电脑,意思不是B可以拿着公钥登录A电脑,而是A可以凭着它的公钥来登录B电脑。
这里用scp来远程拷贝,将master节点的公钥拷贝给slave节点。这样master节点可以用ssh访问slave节点。
可以打开authorized_keys看一下,每个公钥的最后都有着hostname,如果你的Hostname还是老的,那么说明你要重新更新公钥或者重启电脑了。如我的master节点公钥是:ssh-rsa 公钥信息 hadoop@Master.Hadoop
2.3.4 一个巨大的坑
拷贝完毕以后,已经可以用ssh登录slave节点了,但是在这里,我仍然需要输入密码。第一次我发现的BUG是我的主机名没有改变过来所以我重新生成了公钥。第二次还是有这样的问题。
最终解决是因为authorized_keys的权限问题。网上有说权限644即可。没试过,但是664是不可以的。600是可以的。看来除了拥有者之外,其余任何用户都不应该提供给key文件write的权限。
2.4 Java下载配置。
没啥好说的。
2.5 Hadoop下载
也没啥好说的。但是切记每个节点主机的Hadoop文件夹都在同样的路径。
3 Hadoop配置
3.1 vi etc/hadoop/hadoop-env.sh
在这里,要像在/etc/profile里配置java环境变量一样配置JAVA_HOME
即添加一行export JAVA_HOME=xxxxxxxx
3.2 vim etc/hadoop/core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://Master.Hadoop:9000</value>
<description>The name of the default file system</description>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>file:///home/hadoop/hadoop-3.0.0-alpha2/tmp</value>
</property>
</configuration>
这里的重点是,URL要写IP或主机名。而且file后面的路径是真实文件系统路径。
3.3 vim etc/hadoop/hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:///home/hadoop/hadoop-3.0.0-alpha2/hdfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:///home/hadoop/hadoop-3.0.0-alpha2/hdfs/data</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>Master.Hadoop:9001</value>
</property>
</configuration>
其中,replication 是数据副本数量,默认为3,slave少于3台就会报错。
然后是namenode和datanode的节点配置。还有第二个namenode的地址(用于主namenode故障的情况下。自己玩一玩可以写同样的主机,如果实际应用是绝对不可以的)。
3.4 vim etc/hadoop/mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.application.classpath</name>
<value>
/home/hadoop/hadoop-3.0.0-alpha2/etc/hadoop,
/home/hadoophadoop-3.0.0-alpha2/share/hadoop/common/*,
/home/hadoop/hadoop-3.0.0-alpha2/share/hadoop/common/lib/*,
/home/hadoop/hadoop-3.0.0-alpha2/share/hadoop/hdfs/*,
/home/hadoop/hadoop-3.0.0-alpha2/share/hadoop/hdfs/lib/*,
/home/hadoop/hadoop-3.0.0-alpha2/share/hadoop/mapreduce/*,
/home/hadoop/hadoop-3.0.0-alpha2/share/hadoop/mapreduce/lib/*,
/home/hadoop/hadoop-3.0.0-alpha2/share/hadoop/yarn/*,
/home/hadoop/hadoop-3.0.0-alpha2/share/hadoop/yarn/lib/*
</value>
</property>
</configuration>
在这里指定map-reduce的框架是yarn,而不是mapreduce,并且配齐了class路径。
3.5 vim etc/hadoop/yarn-site.xml
<configuration>
<!– Site specific YARN configuration properties –>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandle</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>localhost:8025</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>localhost:8030</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.scheduler.fair.FairScheduler</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>localhost:8040</value>
</property>
</configuration>
在这里除了指定了yarn的一些端口之外,最重要的就是指定了调度方法(scheduler.class),在这里我们指定的是公平调度(Fair Scheduler),如果删掉这个属性,默认的调度方式是Capacity Scheduler。
3.6 vim etc/hadoop/workers
这里配的是slave的地址(主机名),把slave的主机名一行一行写下来即可。
4 启动Hadoop
在这里可以先设置一下HADOOP环境变量,类似Java环境变量一样的设置方法。设置好了可以直接用hdfs命令来运行。如果不设置,必须要在HADOOP_HOME,也就是Hadoop根目录下运行。本教程没有设置,所以所有的命令都加了bin或sbin的路径。
4.1 格式化namenode
第一次启动要格式化。
bin/hdfs namenode -format
今后可能会遇到datanode无法启动的问题,是因为多次格式化后,{HADOOP_HOME}/name/current和{HADOOP_HOME}/name/current的VERSION可能对不上。修改里面的VERSION_ID即可。
4.2 运行和停止Hadoop
sbin/start-all.sh sbin/stop-all.sh
或者运行该路径下有启动部分进程的命令如sbin/start-yarn.sh。
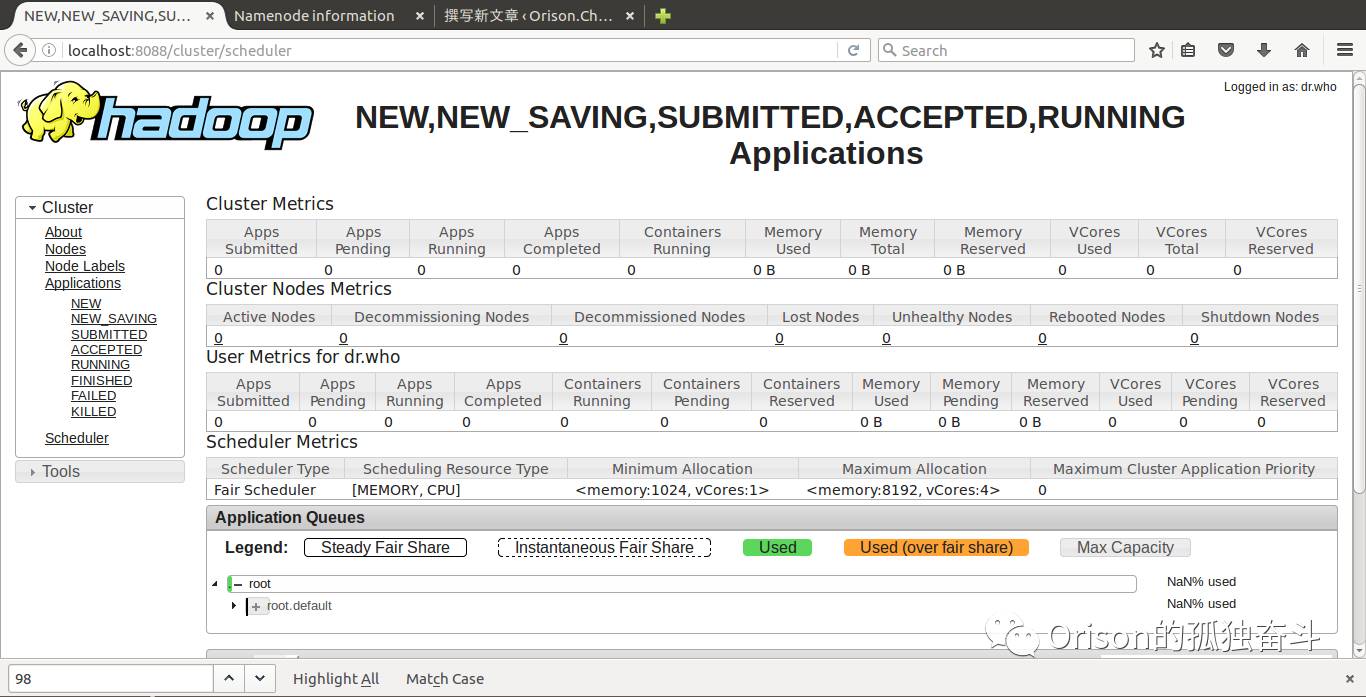
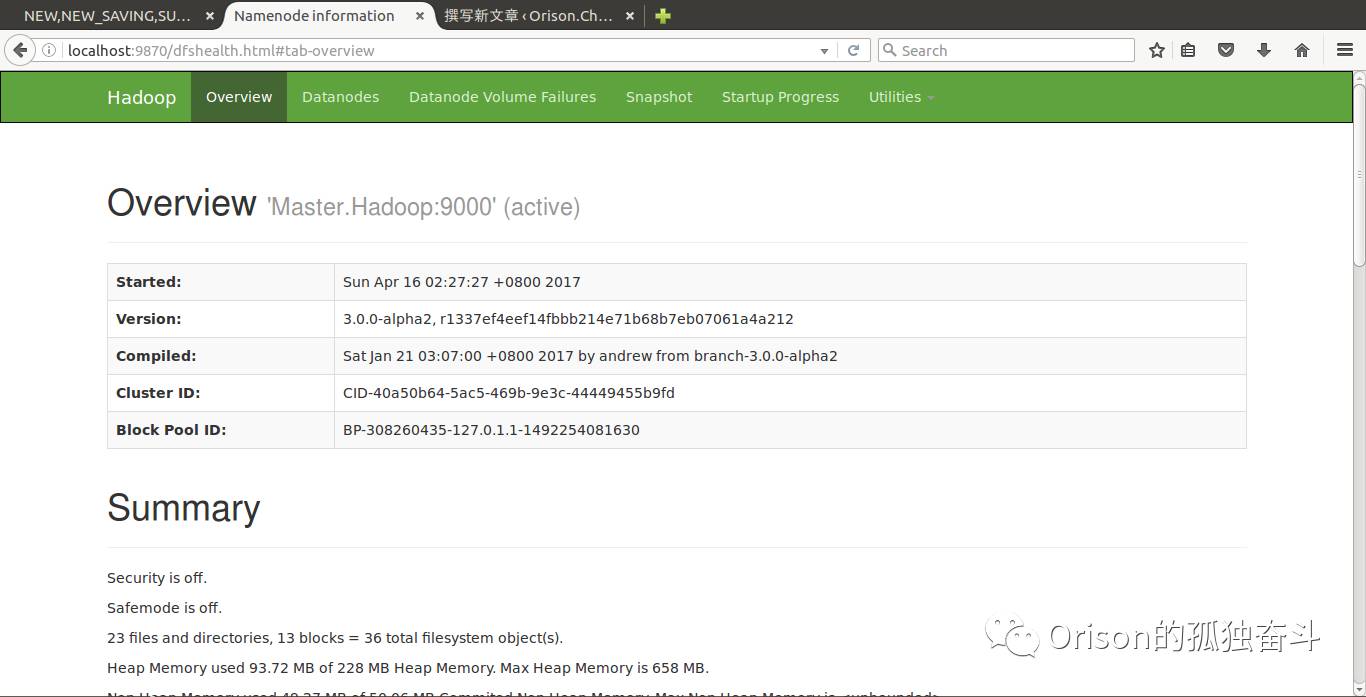
启动成功,可以访问到http://localhost:8088和http://localhost:9870,截图分别如下: