




 关注下方公众号,获取更多热点资讯
关注下方公众号,获取更多热点资讯LangChain+WebBaseLoader实现基于网页内容的问答系统
本文将详细介绍一个基于LangChain和Ollama、WebBaseLoader读取指定网页实现的RAG对话系统,从技术原理到实际代码,全面解析如何构建一个具有上下文感知能力的智能问答系统。
核心框架与库
LangChain
LangChain是一个用于构建LLM应用的框架,它提供了丰富的组件和抽象,使开发者能够轻松地将各种模型、数据源和处理逻辑连接起来。在我们的项目中,LangChain是连接各组件的核心框架。
主要使用的LangChain组件:
• langchain_core
: 提供了基础抽象和接口• langchain_community
: 包含连接各种外部服务的集成• langchain_ollama
: 与Ollama模型的集成• langchain_chroma
: 与Chroma向量数据库的集成• langchain_text_splitters
: 提供文本切分功能
Ollama
Ollama是一个强大的本地运行大型语言模型的工具,它允许我们在自己的硬件上运行各种开源模型,而无需依赖云服务。这提供了更好的隐私控制和降低了运行成本。
我们将使用Ollama来运行:
• qwen2.5:7b
: 一个强大的大语言模型,用于生成最终回答• bge-m3
: 一个高性能的嵌入模型,用于将文本转换为向量
Chroma DB
Chroma是一个专为AI应用设计的开源向量数据库。它提供了高效的向量存储和检索功能,是RAG系统中存储和检索文档向量的关键组件。
其他重要库
• bs4
(BeautifulSoup4): 用于解析和处理HTML内容• logging
: 提供日志记录功能• typing
: 提供类型注解支持
模型选择说明
在本项目中,我们选择了以下模型:
1. 大语言模型 - Qwen2.5 7B: • Qwen(通义千问)是阿里云开源的强大模型系列 • 7B参数规模在性能和资源需求间取得了良好平衡 • 支持中英文双语,特别适合中文应用场景 • 具有较强的指令理解和上下文处理能力 2. 嵌入模型 - BGE-M3: • BGE (BAAI General Embedding) 是智源研究院开发的开源嵌入模型 • M3是其多语言版本,对中文支持优秀 • 在各种向量检索基准测试中表现出色 • 通过Ollama可以方便地本地部署
环境准备与依赖安装
在开始实现RAG系统之前,我们需要先准备好开发环境和安装必要的依赖。本节将引导你完成这些准备工作。
安装依赖包
创建一个requirements.txt
文件,包含以下内容:
langchain-core
langchain-community
langchain-ollama
langchain-chroma
langchain-text-splitters
beautifulsoup4
requests
pydantic
chromadb
然后使用pip安装这些依赖:
pip install -r requirements.txt
完整代码实现
首先,我们来看整个项目的结构和必要的导入:
"""
基于检索增强生成(RAG)的对话系统
实现功能:从网页加载数据,构建向量存储,实现具有上下文感知的问答功能
作者:编程与架构
"""
import os
import logging
from typing importDict, Any, Optional
# 网页处理相关库
import bs4
from langchain_community.document_loaders import WebBaseLoader
# Langchain核心组件
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
from langchain_core.runnables import RunnableWithMessageHistory
from langchain_core.documents import Document
# Langchain模型和数据处理
from langchain_ollama import ChatOllama
from langchain_community.embeddings import OllamaEmbeddings
from langchain_text_splitters import RecursiveCharacterTextSplitter
# Langchain向量存储
from langchain_chroma import Chroma
# Langchain链和检索器
from langchain.chains.combine_documents import create_stuff_documents_chain
from langchain.chains.history_aware_retriever import create_history_aware_retriever
from langchain.chains.retrieval import create_retrieval_chain
# 聊天历史记录
from langchain_community.chat_message_histories import ChatMessageHistory
# 配置日志
logging.basicConfig(level=logging.INFO, format='%(asctime)s - %(name)s - %(levelname)s - %(message)s')
logger = logging.getLogger(__name__)
# 如果需要使用代理,可以取消下面两行的注释并配置代理
os.environ['http_proxy'] = '127.0.0.1:7890'
os.environ['https_proxy'] = '127.0.0.1:7890'
代码解析:
1. 顶部注释:清晰说明了项目的目的、功能和作者信息,这是良好的代码文档实践。 2. 标准库导入:引入基本的Python功能 3. 标准库导入:引入基本的Python功能,如操作系统接口、日志记录和类型注解。 4. 网页处理库:用于加载和解析网页内容, bs4
是BeautifulSoup库,用于HTML解析。5. Langchain组件导入: • 核心组件:提示模板、可运行对象、文档数据结构 • 模型集成:Ollama模型和嵌入接口 • 数据处理:文本分割器 • 向量存储:Chroma数据库 • 链和检索器:文档组合、历史感知检索、检索链 • 消息历史:管理对话上下文 6. 日志配置:设置日志级别和格式,有助于调试和监控系统运行状态。 7. 代理设置:针对网络受限环境的配置选项,特别是在中国大陆等地区访问外部资源时非常有用。
RAGChatbot类定义
我们采用面向对象的方式组织代码,将RAG系统封装为一个类:
class RAGChatbot:
"""
基于检索增强生成(RAG)的对话机器人
该类实现了一个完整的RAG对话系统,包括:
1. 从网页加载知识库
2. 文本切分与向量化存储
3. 基于历史的检索增强
4. 多轮对话记忆
"""
def__init__(
self,
ollama_base_url: str = "http://localhost:11434",
llm_model: str = "qwen2.5:7b",
embedding_model: str = "bge-m3:latest",
chunk_size: int = 1000,
chunk_overlap: int = 200
):
"""
初始化RAG聊天机器人
参数:
ollama_base_url (str): Ollama API的基础URL
llm_model (str): 用于生成回答的语言模型名称
embedding_model (str): 用于文本嵌入的模型名称
chunk_size (int): 文本切片的大小
chunk_overlap (int): 文本切片的重叠大小
"""
self.ollama_base_url = ollama_base_url
self.llm_model = llm_model
self.embedding_model = embedding_model
self.chunk_size = chunk_size
self.chunk_overlap = chunk_overlap
# 存储会话历史的字典
self.session_store = {}
# 初始化模型和组件
self._initialize_components()
代码解析:
1. 类文档字符串:清晰描述了类的功能和主要组件,这是优秀的代码文档习惯。 2. 初始化方法: • 接受多个可配置参数,设置默认值便于快速上手 • 参数包括模型URL、模型选择和文本处理配置 • 所有参数都有类型注解,增强代码可读性和IDE支持 • 使用会话存储字典实现多用户支持 3. 会话存储: session_store
字典用于存储不同用户的对话历史,键是会话ID,值是聊天历史对象。4. 模块化设计:通过 _initialize_components()
方法分离初始化逻辑,使代码更整洁。
组件初始化
接下来看看组件初始化方法的实现:
def _initialize_components(self) -> None:
"""初始化所有必要的组件,包括LLM模型、嵌入模型等"""
logger.info(f"初始化LLM模型: {self.llm_model}")
self.llm = ChatOllama(
model=self.llm_model,
base_url=self.ollama_base_url
)
logger.info(f"初始化嵌入模型: {self.embedding_model}")
self.embeddings = OllamaEmbeddings(
model=self.embedding_model,
base_url=self.ollama_base_url
)
# 初始化文本分割器
self.text_splitter = RecursiveCharacterTextSplitter(
chunk_size=self.chunk_size,
chunk_overlap=self.chunk_overlap
)
代码解析:
1. LLM初始化:创建 ChatOllama
实例,配置模型名称和API地址,用于生成回答。2. 嵌入模型初始化:创建 OllamaEmbeddings
实例,配置模型和API地址,用于文本向量化。3. 文本分割器初始化:创建 RecursiveCharacterTextSplitter
实例,配置切片大小和重叠,用于文档处理。4. 日志记录:每个初始化步骤都有日志记录,便于调试和监控。
文档加载与处理
下面是从网页加载文档的方法:
def load_documents_from_url(self, urls: list[str], css_class: str = 'content-wrapper') -> list[Document]:
"""
从指定多个URL加载文档
参数:
urls (list[str]): 要加载的网页URL列表
css_class (str): 要提取的HTML元素的CSS类名
返回:
list[Document]: 加载的文档列表
"""
logger.info(f"从{len(urls)}个URL加载文档")
loader = WebBaseLoader(
web_paths=urls, # 修改为接受URL列表
bs_kwargs=dict(
parse_only=bs4.SoupStrainer(class_=(css_class))
)
)
try:
docs = loader.load()
logger.info(f"成功加载文档: {len(docs)}个")
return docs
except Exception as e:
logger.error(f"加载文档失败: {e}")
raise
代码解析:
1. 多URL支持:方法接受一个URL列表,可以同时处理多个网页。 2. 内容过滤:使用 bs4.SoupStrainer
只提取指定CSS类的内容,避免加载无关元素。3. 异常处理:使用try-except捕获可能的错误,并记录详细日志。 4. 灵活配置:通过 css_class
参数允许自定义提取的内容范围。
向量存储创建
创建向量存储的方法如下:
def create_vector_store(self, documents: list[Document]) -> Chroma:
"""
创建向量存储
参数:
documents (list[Document]): 要处理的文档列表
返回:
Chroma: 创建的向量存储
"""
logger.info("处理文档并创建向量存储")
# 切分文档为小块
splits = self.text_splitter.split_documents(documents)
logger.info(f"文档切分完成,共{len(splits)}个片段")
# 创建向量存储
vector_store = Chroma.from_documents(
documents=splits,
embedding=self.embeddings
)
logger.info("向量存储创建完成")
return vector_store
代码解析:
1. 文档切分:使用初始化好的 text_splitter
将文档切分为更小的片段。2. 向量存储创建:使用 Chroma.from_documents
方法,传入文档片段和嵌入模型。3. 进度日志:记录处理步骤和结果,包括切分后的片段数量。
RAG链构建
构建RAG链的方法是整个系统的核心:
def build_rag_chain(self, vector_store: Chroma) -> RunnableWithMessageHistory:
"""
构建完整的RAG链
参数:
vector_store (Chroma): 向量存储实例
返回:
RunnableWithMessageHistory: 具有消息历史记录功能的RAG链
"""
logger.info("构建检索增强生成(RAG)链")
# 创建检索器
retriever = vector_store.as_retriever()
# 定义系统提示模板(为文档链)
system_prompt = """您是一个问答任务助手。
请使用以下检索到的上下文来回答问题。
如果您不知道答案,请坦率地说您不知道。
请使用最多三个句子,并保持回答简洁。
{context}
"""
# 创建提示模板
prompt = ChatPromptTemplate.from_messages([
("system", system_prompt),
MessagesPlaceholder("chat_history"), # 历史消息占位符
("human", "{input}"), # 用户输入占位符
])
# 创建文档链(将检索到的文档与用户问题结合)
document_chain = create_stuff_documents_chain(self.llm, prompt)
# 创建历史感知检索器的提示模板
contextualize_q_system_prompt = """给定聊天历史记录和最新的用户问题
(可能引用了聊天历史中的上下文),
请构建一个可以独立理解的问题,无需依赖聊天历史。
不要回答问题,只需在必要时重新表述问题,
否则原样返回问题。"""
retriever_history_prompt = ChatPromptTemplate.from_messages([
('system', contextualize_q_system_prompt),
MessagesPlaceholder('chat_history'),
("human", "{input}"),
])
# 创建历史感知检索器
history_aware_retriever = create_history_aware_retriever(
self.llm,
retriever,
retriever_history_prompt
)
# 创建检索链(将检索器与文档链结合)
retrieval_chain = create_retrieval_chain(history_aware_retriever, document_chain)
# 创建带有消息历史记录功能的可运行链
result_chain = RunnableWithMessageHistory(
retrieval_chain,
self.get_session_history,
input_messages_key='input',
history_messages_key='chat_history',
output_messages_key='answer'
)
logger.info("RAG链构建完成")
return result_chain
代码解析:
1. 检索器创建:从向量存储创建基本检索器。 2. 提示模板设计: • 系统提示明确指示LLM如何使用检索上下文 • 包含历史消息占位符,使模型能看到对话历史 • 用户输入占位符用于当前问题 3. 文档链创建:使用 create_stuff_documents_chain
将LLM与提示模板结合。4. 历史感知检索器: • 定义专门的提示模板指导如何处理上下文问题 • 使用 create_history_aware_retriever
创建能理解历史的检索器• 这解决了指代问题,如"它的特点是什么?"中的"它" 5. 检索链构建:将历史感知检索器与文档链结合。 6. 消息历史集成: • 使用 RunnableWithMessageHistory
包装检索链• 配置输入/输出键和历史获取方法 • 实现多会话支持
会话历史管理
会话历史管理的实现:
def get_session_history(self, session_id: str) -> ChatMessageHistory:
"""
获取或创建会话历史记录
参数:
session_id (str): 会话ID
返回:
ChatMessageHistory: 会话历史记录实例
"""
if session_id not in self.session_store:
self.session_store[session_id] = ChatMessageHistory()
return self.session_store[session_id]
代码解析:
1. 延迟初始化:只在需要时创建新的聊天历史记录,节省资源。 2. 会话隔离:不同会话ID拥有独立的历史记录,实现多用户支持。 3. 简洁实现:简单但有效的字典查找和创建逻辑。
聊天接口
用户交互的聊天接口:
def chat(self, query: str, session_id: str, rag_chain: RunnableWithMessageHistory) -> Dict[str, Any]:
"""
进行一轮对话
参数:
query (str): 用户输入的问题
session_id (str): 会话ID
rag_chain (RunnableWithMessageHistory): RAG链
返回:
Dict[str, Any]: 包含回答的字典
"""
logger.info(f"处理用户查询: '{query}' (会话ID: {session_id})")
try:
response = rag_chain.invoke(
{'input': query},
config={'configurable': {'session_id': session_id}}
)
logger.info(f"生成回答成功 (会话ID: {session_id})")
return response
except Exception as e:
logger.error(f"生成回答失败: {e}")
return {"answer": f"处理您的问题时出错: {str(e)}"}
代码解析:
1. 错误处理:使用try-except捕获可能的异常,确保系统不会崩溃。 2. 会话配置:通过config参数传递会话ID,确保使用正确的历史记录。 3. 日志详情:记录详细的操作日志,便于调试和监控。 4. 优雅失败:发生错误时返回友好的错误信息而不是直接崩溃。
主函数与演示
最后,主函数展示了如何使用这个RAG系统:
def main():
"""主函数,演示RAG聊天机器人的使用"""
# 初始化RAG聊天机器人
ollama_base_url = "http://192.168.1.1:10000"# 请根据您的实际情况修改
chatbot = RAGChatbot(
ollama_base_url=ollama_base_url,
llm_model='qwen2.5:7b',
embedding_model='bge-m3:latest'
)
# 从多个网页加载文档(修改为传入URL列表)
docs = chatbot.load_documents_from_url([
'https://www.hadoop.wiki/pages/d1d5d6/',
'https://www.hadoop.wiki/pages/554ba9'
])
# 打印文档信息
print(f"加载了{len(docs)}个文档")
print(f"文档示例: {docs[0].page_content[:200]}...")
# 创建向量存储
vector_store = chatbot.create_vector_store(docs)
# 构建RAG链
rag_chain = chatbot.build_rag_chain(vector_store)
# 使用RAG链进行对话
# 第一轮对话
user1_id = "编程与架构"
response1 = chatbot.chat("堡垒机有什么功能?", user1_id, rag_chain)
print(f"\n用户 {user1_id} 提问: 堡垒机有什么功能?")
print(f"回答: {response1['answer']}")
# 第二轮对话(不同用户)
user2_id = "访客用户"
response2 = chatbot.chat("跳板机有什么功能?", user2_id, rag_chain)
print(f"\n用户 {user2_id} 提问: 堡垒机有什么功能?")
print(f"回答: {response2['answer']}")
# 展示多轮对话能力(同一用户)
response3 = chatbot.chat("它有什么主要特点?", user1_id, rag_chain)
print(f"\n用户 {user1_id} 提问: 它有什么主要特点?")
print(f"回答: {response3['answer']}")
# 展示多轮对话能力(同一用户)
response4 = chatbot.chat("Linux释放内存脚本", user1_id, rag_chain)
print(f"\n用户 {user1_id} 提问: Linux释放内存脚本")
print(f"回答: {response4['answer']}")
# 展示多轮对话能力(同一用户)
response5 = chatbot.chat("Kafka是什么", user1_id, rag_chain)
print(f"\n用户 {user1_id} 提问: Kafka是什么")
print(f"回答: {response5['answer']}")
if __name__ == "__main__":
main()
代码解析:
1. 系统初始化: • 创建RAGChatbot实例 • 配置Ollama服务URL和模型选择 2. 数据加载: • 从两个网页加载文档 • 打印基本信息验证加载成功 3. 向量存储和RAG链: • 创建向量存储 • 构建完整RAG链 4. 多场景演示: • 展示两个不同用户的对话 • 展示同一用户的多轮对话 • 测试各种不同类型的问题 5. 实用功能演示: • 上下文感知能力("它的主要特点") • 不同领域知识问答 • 多用户隔离
通过这个主函数,我们可以看到RAG系统如何在实际场景中运行,以及它如何处理不同类型的问题和维护多用户会话。
验证
随便找了两篇之前写过的文章
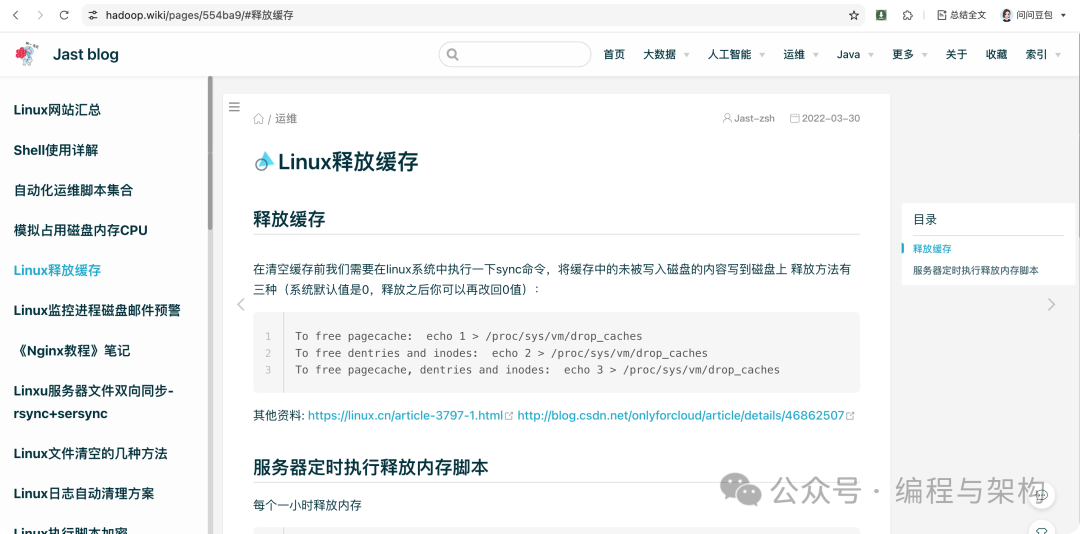
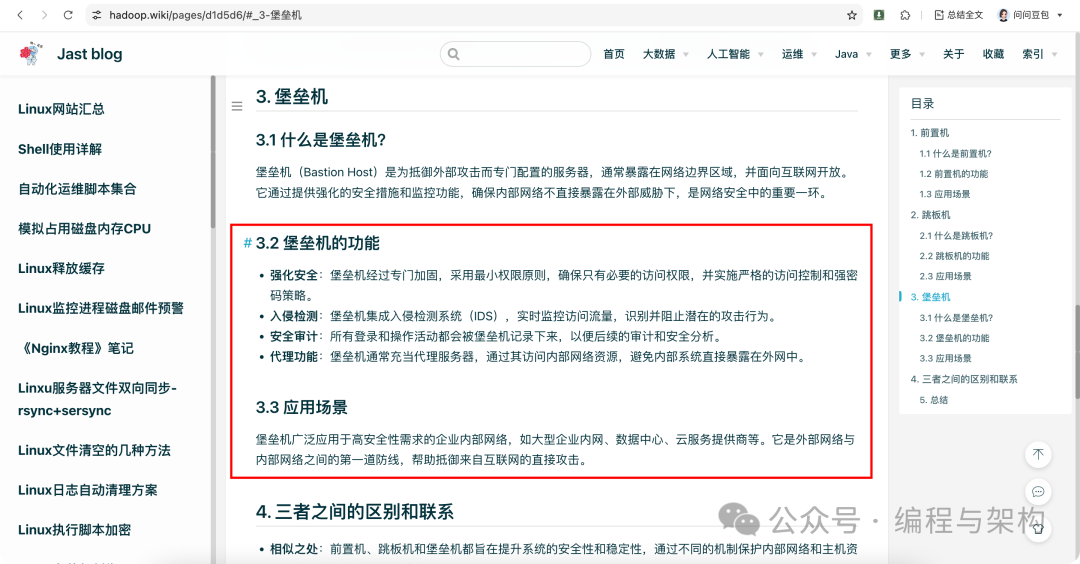
效果,这里为了方便延时,我直接复制出来了
问题一
用户 编程与架构 提问: 堡垒机有什么功能?
回答: 堡垒机具有强化安全、入侵检测和安全审计等功能。它通过实施严格的访问控制和强密码策略,确保只有必要的访问权限,并集成入侵检测系统实时监控流量以识别潜在攻击。所有登录和操作活动都会被记录下来,便于后续的安全分析。
问题二
用户 访客用户 提问: 堡垒机有什么功能?
回答: 跳板机的主要功能包括访问控制、会话管理和安全审计等,确保管理员能够安全地远程访问内部服务器,并详细记录所有访问操作以进行审计。
问题三
用户 编程与架构 提问: 它有什么主要特点?
回答: 堡垒机的主要特点是强化安全、入侵检测和严格审计。它采用最小权限原则,实施严格的访问控制和强密码策略,并集成入侵检测系统实时监控流量以识别潜在攻击。所有登录和操作活动都会被详细记录,便于后续的安全分析。
问题四
用户 编程与架构 提问: Linux释放内存脚本
回答: 在Linux中释放内存的脚本通常包括执行sync
命令以将缓存写入磁盘,然后通过以下命令释放内存:
echo 1 > proc/sys/vm/drop_caches
....
问题五
用户 编程与架构 提问: Kafka是什么
回答: 根据提供的上下文信息,没有提到Kafka的相关内容,所以我无法回答Kafka是什么。基于现有信息,我并不知道Kafka的具体含义或用途。
总结
希望这篇教程能够帮助你理解RAG系统的工作原理,掌握实现技巧,并启发你开发更多创新应用。
完整代码关注公众号回复:3684 领取
欢迎关注我的公众号“编程与架构”,原创技术文章第一时间推送。
