




 关注下方公众号,获取更多热点资讯
关注下方公众号,获取更多热点资讯融合LlamaIndex、DeepseekR1与Ollama,构建私有RAG知识库
本文将基于LlamaIndex实现RAG知识库,大模型选用 Deepseek-R1-7b 大模型,大模型部署采用 Ollama。
可以实现Deepseek-R1-7b与外部数据的连接,利用 LlamaIndex 与 Deepseek-R1-7b 快速部署检索增强生成(RAG)技术。
LlamaIndex起源与架构升级
LlamaIndex前身为2022年发布的GPT Index,最初专注于为GPT-3模型提供基础网页索引功能。2023年更名为LlamaIndex后,其架构经历了三次重大升级:
• 多模态支持:新增图像、音频等数据源接入能力,支持混合查询机制。 • 生态扩展:集成200+数据连接器(如Notion、MySQL),覆盖主流平台。 • 智能增强:2024年引入Agent模块,支持自动化索引更新与知识图谱构建。
本文采用框架和模型
• LLamaIndex • Deepseek-R1-14B • Ollama • bge-m3:latest(Embedding 模型)
概念介绍
RAG
RAG 指的是检索增强生成(Retrieval-Augmented Generation)
RAG 是一种将检索技术与语言模型生成能力相结合的技术架构,旨在利用外部知识来增强语言模型的生成效果,使模型能够生成更准确、更有针对性、更符合事实的文本内容。
RAG 解决的问题
知识局限问题
• 缺乏最新知识:传统语言模型基于预训练数据,无法掌握训练后新知识,如科研成果、时事新闻。RAG 检索实时外部知识源,回答新科技产品问题时可获取产品特性准确作答。 • 知识覆盖不全:预训练数据难涵盖所有知识领域细节。RAG 连接大规模外部知识库,遇特定领域专业问题可从对应库检索知识,解决模型知识盲区。
生成质量问题
• 内容准确性:语言模型易产生 “幻觉”,生成与事实不符内容。RAG 检索可靠外部知识源,提供事实依据,回答历史事件可依权威资料确保准确。 • 内容多样性:仅靠自身参数和训练数据,生成文本易模式化。RAG 引入多样外部文本数据,创作故事时可参考不同文学风格,提升创意与多样性。 • 内容连贯性:语言模型生成较长文本可能逻辑不连贯。RAG 检索的知识作额外上下文,帮助模型把握语义,生成长篇报告时保证各部分逻辑衔接紧密。
可解释性问题
• 传统模型黑箱问题:传统语言模型生成依据难解释,用户不明原因。RAG 检索过程透明,用户可见检索的外部知识来源,提高可解释性与信任度。
计算资源与效率问题
• 降低模型规模需求:传统语言模型为提升性能常增参数规模,消耗大量计算资源与训练成本。RAG 引入外部检索,弥补自身知识不足,不显著增模型规模即可提性能,节省资源与成本。 • 提高生成效率:部分情况,直接检索外部知识用于生成比模型复杂计算推理更高效,简单检索整合能回答的问题,RAG 可快速获取答案并生成,提升速度与响应效率。
实际应用
场景
这里我模拟一个场景,我使用 GPT 编写了一个工具说明,这个工具我命名为ABCD。下图是文档的部分截图,不在这里展示全部文档内容,在文章后半部分会对演示的场景同步展示文档内容。
关注公众号回复:9843 可获取所有代码和文档

环境准备
创建一个虚拟环境
方法一:手动创建环境
conda create -n llama_index python=3.10
在项目中使用
conda activate llama_index
方法二:在开发客户端中创建环境
直接在 Cursor(VSCode等都可以,习惯用 Cursor) 中配置
安装依赖
!pip install llama-index
!pip install llama-index-llms-ollama
!pip install llama-index-embeddings-ollama
完整代码
# 引入依赖
from llama_index.core import VectorStoreIndex, SimpleDirectoryReader,Settings
from llama_index.embeddings.huggingface import HuggingFaceEmbedding
from llama_index.llms.ollama import Ollama
# 设置日志级别,方便调试
logging.basicConfig(stream=sys.stdout, level=logging.INFO)
logging.getLogger().addHandler(logging.StreamHandler(stream=sys.stdout))
# 配置远程 Ollama 服务地址
OLLAMA_HOST = "https://u573698-94e7-29ab86b7.nmb1.seetacloud.com:8443"# 替换为你的服务器 IP 地址
# 配置 Ollama 模型,指定远程服务器地址
llm = Ollama(
model="deepseek-r1:14b",
temperature=0.7,
base_url=OLLAMA_HOST,
request_timeout=1200,
timeout=600# 设置超时时间为600秒
)
# 配置 embedding 模型,同样指定远程服务器地址
embed_model = OllamaEmbedding(
model_name="bge-m3:latest",
base_url=OLLAMA_HOST,
request_timeout=1200,
timeout=600# 设置超时时间为600秒
)
# 设置为默认的 LLM 和 embedding 模型
Settings.llm = llm
Settings.embed_model = embed_model
# 加载文档
documents = SimpleDirectoryReader("./data").load_data()
# 创建索引
index = VectorStoreIndex.from_documents(documents)
# 创建查询引擎
query_engine = index.as_query_engine()
# 验证查询
response = query_engine.query("ABCD 如何查看执行的任务记录")
print("查询结果:", response)
验证效果
问题一:ABCD 如何查看执行的任务记录

在文档中内容为
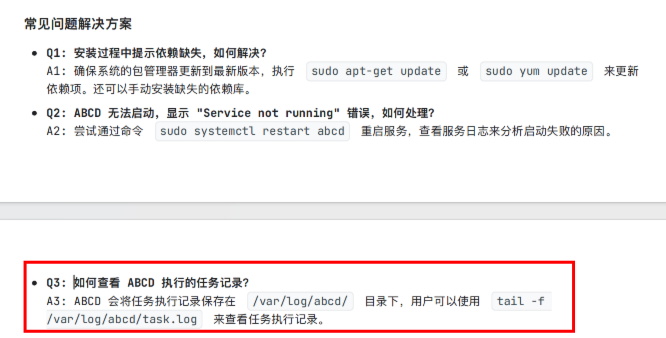
问题二:ABCD 怎么安装

文档中的对比
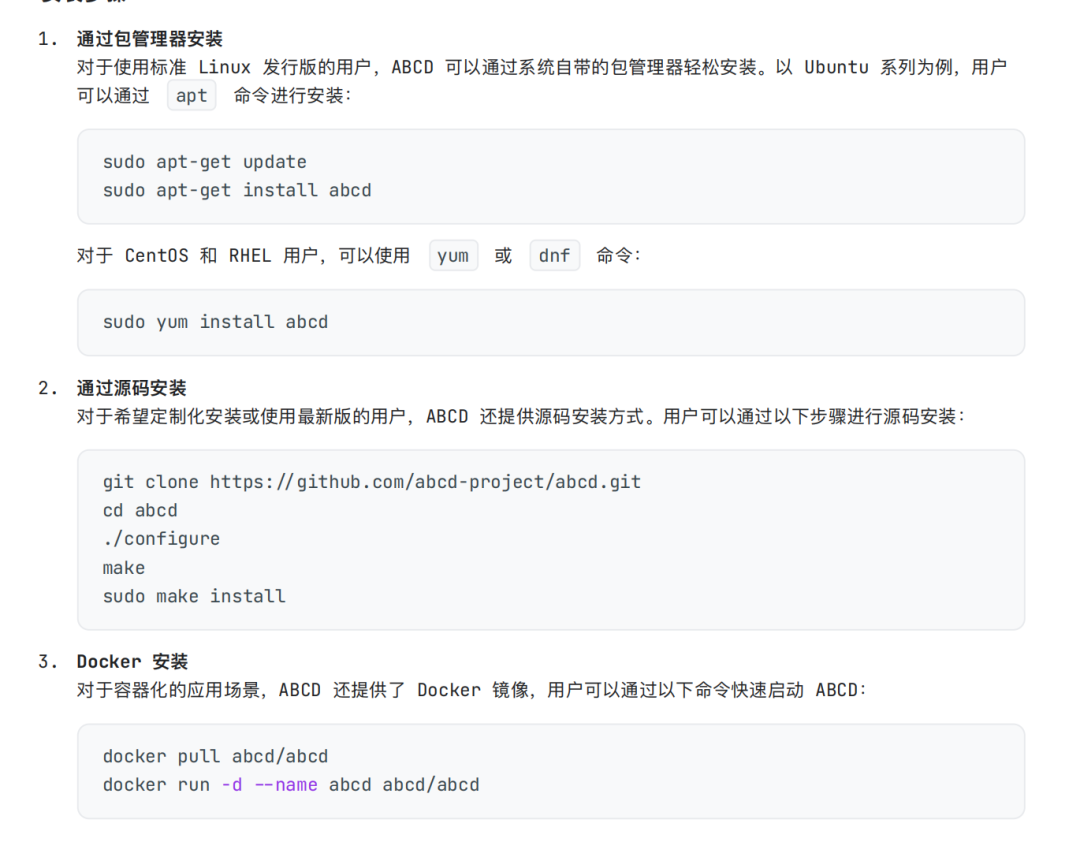
问题三:ABCD 有什么新功能规划
这里我们可以看到文档有描述:潜在的新功能
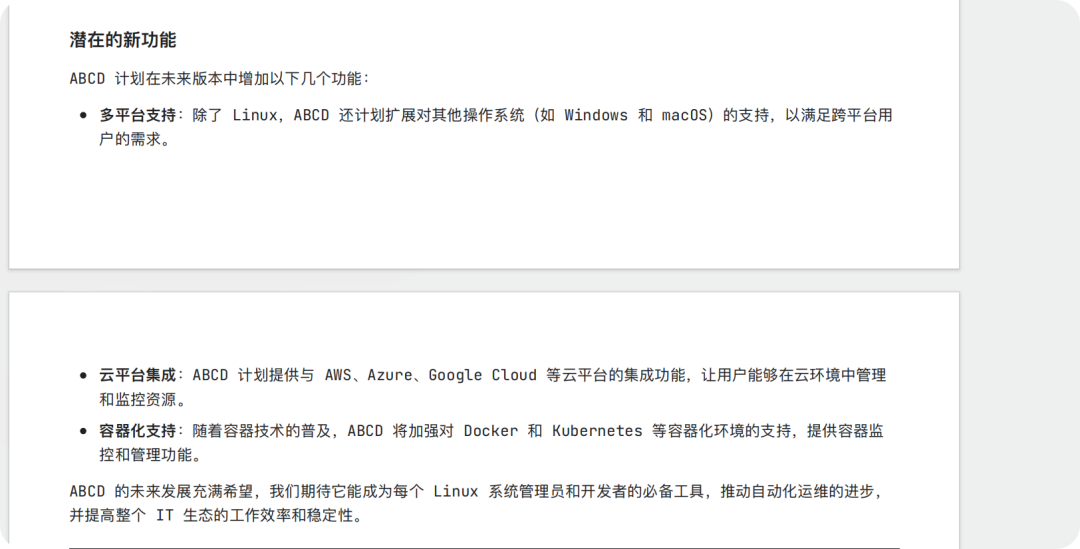
看下大模型的回答,发现他并不能理解。这里优化的方向有两个:
• 尝试更换参数更大的模型 • 优化embedding模型

补充内容
上文提到的LLM和Embedding模型都是通过Ollama调用的,这里介绍一下通过自定义LLM调用Deepseek。
这里Embedding模型还是通过Ollama调用的,LLM模型已经通过第三方接口调用,并成功运行。
import os
import sys
import logging
from openai import OpenAI
from typing importAny, Generator
from llama_index.core import VectorStoreIndex, SimpleDirectoryReader, Settings
from llama_index.embeddings.huggingface import HuggingFaceEmbedding
from llama_index.core.llms import (
CustomLLM,
CompletionResponse,
CompletionResponseGen,
LLMMetadata,
)
from llama_index.core.llms.callbacks import llm_completion_callback
from pydantic import BaseModel, Field
from dotenv import load_dotenv
from functools import cached_property
# 配置日志 创建一个与当前模块同名的 logger
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger(__name__)
# 从环境变量获取 API 密钥
load_dotenv()
API_KEY = os.getenv("DEEPSEEK_API_KEY")
classDeepSeekChat(BaseModel):
"""DeepSeek 聊天模型的封装类。"""
api_key: str = Field(default="sk-xxx")
base_url: str = Field(default="https://api.lkeap.cloud.tencent.com/v1")
classConfig:
"""Pydantic 配置类。"""
arbitrary_types_allowed = True# 允许模型接受任意类型的字段
# 这增加了灵活性,但可能降低类型安全性
# 在本类中,这可能用于允许使用 OpenAI 客户端等复杂类型
@cached_property
defclient(self) -> OpenAI:
"""创建并缓存 OpenAI 客户端实例。"""
return OpenAI(api_key=self.api_key, base_url=self.base_url)
defchat(
self,
system_message: str,
user_message: str,
model: str = "deepseek-r1",
max_tokens: int = 1024,
temperature: float = 0.7,
stream: bool = False,
) -> Any:
"""
使用 DeepSeek API 发送聊天请求。
返回流式响应或完整响应内容。
"""
try:
response = self.client.chat.completions.create(
model=model,
messages=[
{"role": "system", "content": system_message},
{"role": "user", "content": user_message},
],
max_tokens=max_tokens,
temperature=temperature,
stream=stream,
)
return response if stream else response.choices[0].message.content
except Exception as e:
logger.error(f"Error in DeepSeek API call: {e}")
raise
def_stream_response(self, response) -> Generator[str, None, None]:
"""处理流式响应,逐块生成内容。"""
for chunk in response:
if chunk.choices[0].delta.content isnotNone:
yield chunk.choices[0].delta.content
classDeepSeekLLM(CustomLLM):
"""DeepSeek 语言模型的自定义实现。"""
deep_seek_chat: DeepSeekChat = Field(default_factory=DeepSeekChat)
@property
defmetadata(self) -> LLMMetadata:
"""返回 LLM 元数据。"""
return LLMMetadata()
@llm_completion_callback()
defcomplete(self, prompt: str, **kwargs: Any) -> CompletionResponse:
"""执行非流式完成请求。"""
response = self.deep_seek_chat.chat(
system_message="你是一个聪明的 AI 助手", user_message=prompt, stream=False
)
return CompletionResponse(text=response)
@llm_completion_callback()
defstream_complete(self, prompt: str, **kwargs: Any) -> CompletionResponseGen:
"""执行流式完成请求。"""
response = self.deep_seek_chat.chat(
system_message="你是一个聪明的 AI 助手", user_message=prompt, stream=True
)
defresponse_generator():
"""生成器函数,用于逐步生成响应内容。"""
response_content = ""
for chunk inself.deep_seek_chat._stream_response(response):
if chunk:
response_content += chunk
yield CompletionResponse(text=response_content, delta=chunk)
return response_generator()
# 设置环境变量,禁用 tokenizers 的并行处理,以避免潜在的死锁问题
os.environ["TOKENIZERS_PARALLELISM"] = "false"
# 设置日志级别
logging.basicConfig(stream=sys.stdout, level=logging.INFO)
logging.getLogger().addHandler(logging.StreamHandler(stream=sys.stdout))
OLLAMA_HOST = "https://u573698-94e7-29ab86b7.nmb1.seetacloud.com:8443"# 替换为你的服务器 IP 地址
# 配置 embedding 模型,同样指定远程服务器地址
embed_model = OllamaEmbedding(
model_name="bge-m3:latest",
base_url=OLLAMA_HOST,
request_timeout=1200,
timeout=600# 设置超时时间为600秒
)
# 设置为默认的 LLM 和 embedding 模型
Settings.llm = DeepSeekLLM()
Settings.embed_model = embed_model
# 加载文档
documents = SimpleDirectoryReader("./data").load_data()
# 创建索引
index = VectorStoreIndex.from_documents(documents)
# 创建查询引擎
query_engine = index.as_query_engine()
# 验证查询
response = query_engine.query("ABCD 有什么新功能规划")
print("查询结果:", response)
参考:
https://zhuanlan.zhihu.com/p/842132629
关注公众号回复:9843 可获取所有代码和文档
欢迎关注我的公众号“编程与架构”,原创技术文章第一时间推送。
文章转载自编程与架构,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
