




写公众号一年,41篇原创,11万字:
知乎粉丝数也突破了1万,有1.1万了。
有些地方还是颇感意外,本来觉得大伙喜欢看故事、听八卦,硬核的技术,流量一定惨不忍睹。颇出我意料的,我文章的流量之王,竟然是最深入的文章:
《深入突破基础软件开发》系列一和大结局,各有5万上下的流量,两篇合起来10万+了,着实让我意外。因为这是我出道以来,写过的最深入的技术文章,没有之一。
《深入突破基础软件开发》主要讲CPU执行阶段流水线的情况。
现代底层硬件复杂度十分惊人,潜藏着十分巨大的能效潜力,如果能更加了解你的硬件,就能更好的释放硬件潜力,这是基础软件开发者的必修课。
如果连一条指令如何在CPU中被执行的,都说不清楚,这可不是合格的基础软件开发者。
为了感谢腾讯肯把流量推给深度文章,IT知识刺客正在策划蛇年第一个系列:《从体系结构到数据库:千面内存》。
这个系列是讲内存的。
内存,是代码的舞台,是除CPU之外,最影响性能的设备。我们每时每刻都在使用它,但却不了解它。因为没有必要了解。
在现代软件工程的分层抽象思想下,内存被抽象为一个线性、一维的大数组,数组的下标就是内存地址,你给我地址,我给你数据。
对于应用层程序开发者,抽象后的内存层简单易用,而且针对性的做了足够的优化,实无必要再向下学习、研究内存设备的原理。
但对于基础层软件开发,则完全不同。抽象层做的优化,有时可能会起到反作用。
以内存抽象层为例,CPU假定开发者多以连续或小步阀、固定步阀访问内存,并因此增加预测读取机制。
比如,CPU发现你访问完地址12345的内存,又访问12346、12347、12348……,CPU会提前把12349、12350、12351……等地址处的数据,先从内存读进Cache,这就是CPU的预测机制。
这个预测机制效果如何呢?
做个简单测试,一看便知:
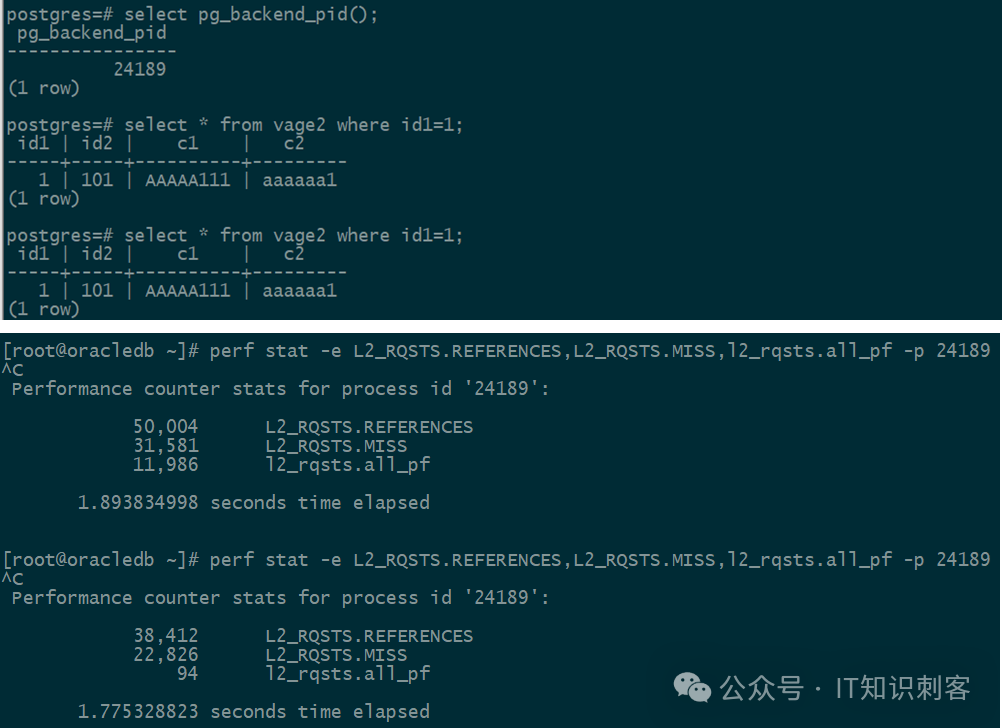
图1
图1是执行一条简单SQL期间,CPU L2 Cache的情况。
目标SQL执行了两次,下面perf也进行了两次统计。
第一次是正常执行。第二次执行时,我关掉了CPU预读机制。因此,第二次perf统计结果中,l2_rqsts.all_pf只有94,而第一次执行时,all_pf还有11,986。
注:
l2_rqsts.all_pf是L2完成的CPU硬件预取请求次数。pf,就是pre-fetch的缩写。
打开CPU预测访问(第一次执行),31581/50004,L2 Miss率为63.1%。
关闭CPU预测访问(第二次执行),22826/38412,L2 Miss率为59.4%。
关闭CPU预测L2 Miss率下降了4个百分点,而且perf统计的执行时间也从1.89秒下降到1.77秒。
对数据库来说,CPU的预测机制板上钉钉是帮了倒忙。
注:
测试SQL是OLTP型简单SQL,如果是OLAP型SQL,要另当别论。
CPU的硬件预取,就是基础数据抽象层为我们做的优化,只需要一个极简单的测试,就能证明它并不总是有效。
但如果你足够了解基础数据抽象层,则可以做到扬长避短,最大程度发挥其作用、避免负面影响。
(我再强调一边,对于应用层开发者来说,这样做没有意义,不如更加关注业务逻辑等等)
再看个和内存直接相关的吧:
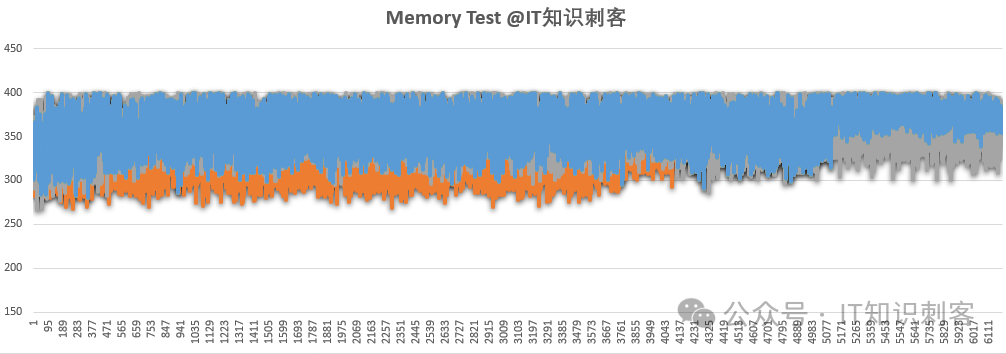
图2
这是访存性能测试图,在后续《从体系结构到数据库:千面内存》系列文章中,再详细讲解其意义,先简单说下。
Y轴是访存延时,单位是周期。因为这是从CPU角度得到的延时,因此这里的周期是CPU的时钟周期。
如果CPU主频是3GHz,3个周期1纳秒。所以Y轴只要除以3,就是以纳秒为单位的延时。
这其实是一张散点图,散点太多,连成了一片。
每一个点,是以固定间隔重复访问6次内存后的平均值(排除了L1~L3 Cache的影响)。
蓝、橙、灰三种颜色,对应三种访存间隔计算方式。
访存指令,使用Intel SIMD指令集中的vmovntdqa指令,它属于AVX2指令集,可一次读写32个字节(256 bit)。
相比传统的mov指令,矢量指令vmovntdqa没有那么多优化,完成的工作也相应少些,更容易反应真实的访存延迟。
但要注意,指令手册中虽然说vmovntdqa将绕开各级Cache,但实际并不会。
虽然做了一系列的工作,可以看到,图2的散点图中,访存延迟仍存在巨大的波动。低至270周期左右,高至400周期以上。
为什么存在如此大的波动?
举个小例子,前面说了,矢量指令vmovntdqa并不会绕过各级Cache,数据还是要先写入Cache,再读入ymm寄存器。当Cache满后,新的读取只能等待,等Cache腾出空间,再写入Cache,这一次访存延时必然更高。
还有其他原因,有的是统计程序本身造成的,等等吧,波动是难免的。但有一点值得注意,波动虽然会让延迟增高,却无法让延迟更低。
简单点说,波动会让一个200周期的访存,因为一些原因,增加到300周期,却无法让它降低到150周期。因此,图2散点图的下边缘,可以做为访存的真正延时。按照这个思路,我对图2橙、蓝、灰分别按下边缘进行了拟合处理:
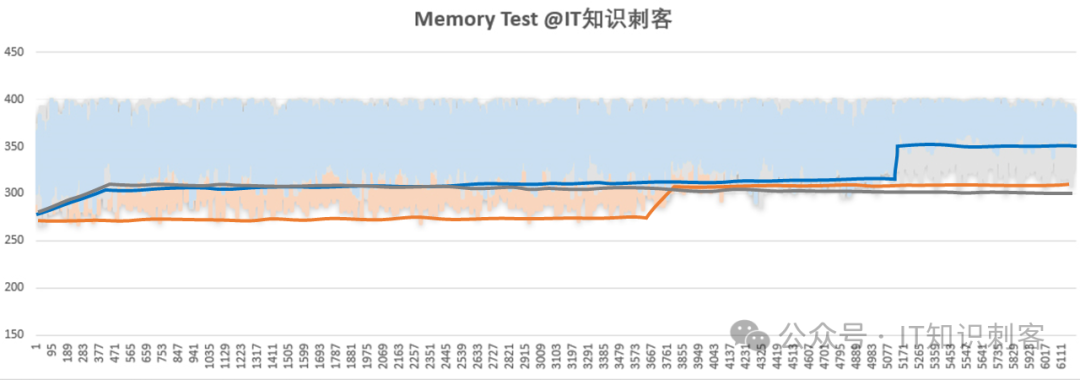
图3
将橙、蓝、灰散点图下边缘,拟合为三条橙、蓝、灰的线后,规律阅然纸上。
前面说了,橙、蓝、灰对应三种不同的间隔计算方式,其中蓝线的间隔基数最大,需要的内存也更多,测试的后半段,间隔甚至跨了NUMA节点,我把NUMA的影响在图上标记一下:
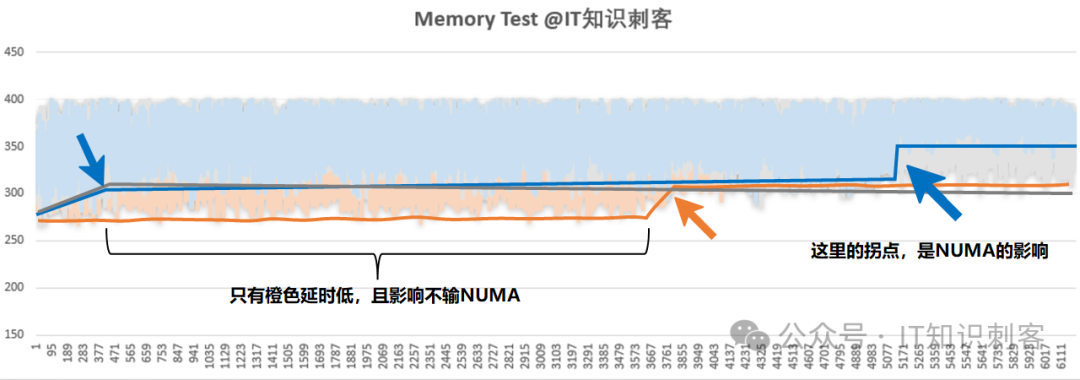
图4
蓝线后半段,延时陡然升高,其实是跨了NUMA节点。
有了NUMA做对比,很容易就能发现,橙线的前半段,延时一直低于蓝、灰,而且延时差距,和NUMA几乎不相上下。
这说明访存存在着和NUMA影响相当的因素,如果能明确这个“因素”的原理,合理的按排数据结构,甚至能取得和NUMA Aware一样的提升。
NUMA Aware是什么量级的提升呢,给你点信息感受一下:

以上宣传来自个别国库(国产数据库)头部玩家官网或搜索引擎,连右上图中非技术线的领导,都被拉到台上NUMA-Aware了。右下的NUMA-Aware多实例架构,更是在官网首页,独自撑起了国库头部玩家的一条产品线。
现在有了影响和NUMA相当的“因素”,国库头部玩家,又可以再Aware一次、再开一条产品线了。
(不过这次Aware会有点难,因为这个神秘的因素是什么呢,总要先找到它,再Aware它吧。我出十块钱,赌国库头部玩家这次Aware不了。再出十块,赌他们的NUMA-Aware也是吹牛B的水货)
那么,内存中,是什么神秘的因素潜藏着如此巨大的性能潜力?
《从体系结构到数据库:千面内存》,敬请期待。
