




本节我们进入数据效率的话题,所谓数据效率是指如何有效的存储数据,也就是用尽量少的存储空间存储尽量多的数据。有些同学可能觉得不太可能,毕竟一个扇区的硬盘空间就存储一个扇区的数据,总不能让一个扇区的硬盘空间存储两个扇区的数据吧?其实真的是这样,数据效率就是用一个扇区的空间存储多个扇区的数据,甚至不用存储空间就能存储数据。具体是怎么做到的呢?
数据效率包含三方面的内容,数据压缩、数据去重和数据模式。所谓数据压缩是用更少的存储空间对原始数据编码的过程。也就是通过重新编码实现减低数据存储空间的方法。数据去重是将多个相同的数据通过一个存储空间进行存储的方法。数据模式则是通过识别用于数据的规律来减少存储空间的方法。本节我们主要介绍一下数据压缩的相关内容,其他技术将在后续介绍。
重复数据无处不在,比如电商平台不同商户使用的产品图片,很多图片都是生产厂家提供了,所以内容是一致的。每个商家都会将图片上传到自己的商品展示页面,但对于平台来说,这些照片其实是相同的照片,也就是相同的数据。
另外一个案例就是我们经常使用的网盘,很多人使用网盘存储电影、MP3和一些个人资料。对于个人资料出现重复的可能性不大,但是对于电影和MP3等视频和音频文件,由于大家都是从网站下载的,大多数是相同的内容。
对于上述场景,同一份数据可能有成百上千个副本,如果存储系统重复存储这些数据,将造成存储空间的极大浪费。因此,对于存储系统来说如何高效地存储数据就成为一个非常重要的话题。对于服务提供商来说,这些重复的数据在其数据中心只需要存储一个实体,而其他用户相同的数据存储一个索引信息即可,如下图。
用户重复数据
除了文件级别的重复数据外,还有另外一种非常典型的数据就是数据块级别的。比如一个文档,我们修改了几行文字后上传到网盘。虽然从文件的角度来看与现有的文件不再是同一个文件,但是由于其中大部分数据与原始数据是相同的,如果我们把文件拆分成若干数据块,就会发现其中很多数据块是相同的。本文后续所有内容都是以块级数据去重为例进行说明的。
重复数据删除从实现位置来分,分为在线去重(In-line Deduplication)和后处理去重(Post-process Deduplication)两类。所谓在线去重就是在IO的写入过程中发现重复的数据,并进行去重处理。所谓后处理去重是指在IO写入的时候不做处理,而是通过后台任务扫描数据,发现重复的数据,然后进行去重的处理。
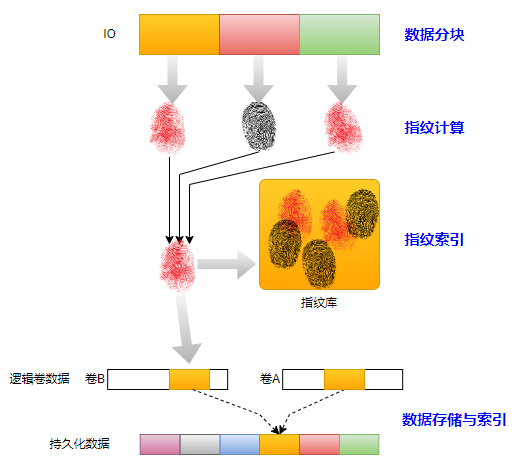
重复数据删除的原理
无论是在线去重还是后处理去重,块级数据去重的流程大体是一致的。其流程如上图}所示分为4个主要步骤,分别是数据分块、指纹计算、指纹索引和数据存储与索引。上述步骤理解起来也非常简单,但涉及工程实现则有很多难点。


数据分块(Chunking)
块级数据去重首先需要将数据划分为一个一个数据块,基于这些数据块才便于计算指纹和管理数据。分块技术从大类上分为两种,一种称为定长分块(Fixed Size Chunking, 简称FSC),另外一种基于内容的分块(Content-Defined Chunking,简称CDC)。
FSC是最简单的数据分块算法,简单到几乎不需要计算。以逻辑卷为例,逻辑卷被划分为大小相等的数据块(比如ZFS中的数据块为128KB)。如下图所示,假设在逻辑卷中数据块A与数据块E内容相同,此时在持久化层只有一个物理空间被使用。同理,数据块C与数据块Z也是如此处理,而数据块B和数据块D与任何数据不一样,因此需要分别存储。最终,我们可以看到在持久化存储设备上只存储了4个数据块实体。
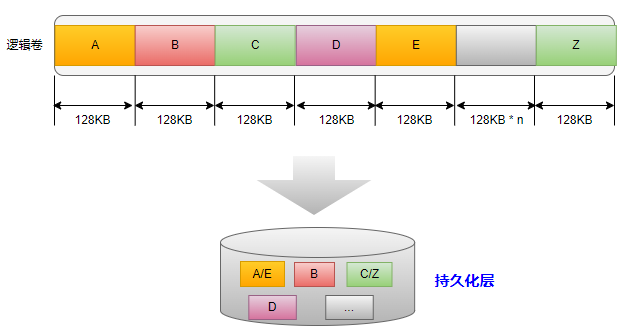
固定数据分块
FSC虽然简单,但是其缺点也是很明显的,那就是在数据块前面插入数据或者删除数据的情况下将导致分块数据指纹发生变化,从而无法实现重复数据删除。我们举一个具体的例子,假设数据块C和数据块D对应一个文件的数据。如果在文件的头部插入的一小块数据,此时文件的数据块C将会整体往后移动。具体如下图所示,假设插入的数据为数据块C1,原有数据块C的数据则是C2和C3。由于采用FSC方法,所以此时数据块C的内容为C1和C2的内容,该内容的指纹可能无法与已有数据块Z构成重复数据。
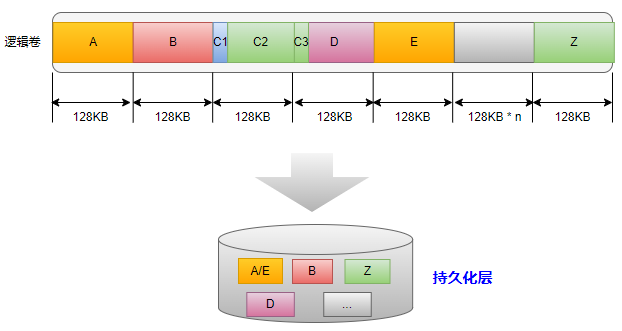
固定数据分块的缺点
上面我们的举例是只有两个数据块的小文件。如果是比较大的文件的话,这种插入操作将影响其后的所有数据块,进而严重降低数据的去重率。所以,有没有一种方法在插入数据的情况下尽量小的影响后面的数据呢?
为了解决上述FSC方法的缺点,发明了CDC算法。CDC算法是一种非固定分块的技术,也称基于内容的数据分块技术。基于CDC的算法可以增加一个偏移量计算数据的指纹,从而尽量找到重复的数据。虽然基于CDC方法可以在一定程度上增加数据去重的比例,但是相较于FSC需要更大的计算量。

如何判断在一个存储系统中是否已经有一个相同的数据块?最简单的方法是将当前数据块与系统中的所有数据块进行对比,如果两个数据块内容完全一样,那么就说明是相同的数据块。这种方法虽然简单,但是却不是一个可行的方案。上述方案不可行的原因是查找效率太低了,特别是对于在线去重,所造成的IO延时是不可接受的。
所以,可行方案的必要条件是能够快速判定两个数据块是否完全一样。直接可以想到的方法是在内存中存储所有数据块的特征值(也就是指纹),这个特征值的大小要比原始数据小的多。当有新的写请求时,我们按照相同的粒度计算特征值,如果特征值相同则认为两个数据块是一样的。
在计算机领域,数据特征值的计算通常使用哈希算法(Hash Algorithm)得到,哈希算法也成为散列算法。哈希算法的功能是将任意长度的数据映射为一个固定长度的数据,比如SHA-256可以将任意数据映射为256位的数据,而MD5则可以将任意数据映射为128位的数据。
除了可以将原始数据的大小变得非常小外,映射算法的另外一个特征是映射完的数据(哈希值)能一定程度上代表原始数据。换而言之,只要对比哈希值就能在一定程度上判定两个数据块是否为同样的数据。
大家需要注意上文的用词,作者使用了“一定程度上”,所以哈希值相等并不能保证原始数据就一定一样。其原因在于哈希值是存在碰撞的可能性的,也就是不同的数据可能会算出相同的哈希值。针对哈希碰撞问题不同的企业有不同的解决方案,有些企业采用二次确认的方式,也就是在哈希值相同的情况下再次比较原始数据;有些企业则采用两种不同的哈希算法,虽然仍然可能存在碰撞的问题,但已经是非常小概率了,可以认为不可能发生。

如前文所述,指纹存储在一个称为指纹库的地方,这个是作者给出的一个便于理解的概念,实际实现可能并非这样。指纹库中存储的信息并非只是指纹信息,还包括数据块物理地址等信息。只有这样,当存储引擎识别到相同的数据的时候才能将指针指向该数据块。
对于指纹索引,最简单的方式当然是通过哈希表的方式存储在内存当中了,这样当计算出指纹后,O(1)时间复杂度就可以判断是否有重复的数据存在。但是,理想很丰满,现实却很骨感。原因很简单,企业级存储系统的数据量通常是非常庞大的,很难将指纹全部存储在内存当中。假设我们使用SHA-256,存储的物理空间为1PB,数据块大小为128KB,那么所有的指纹信息将消耗256GB的内存空间。在存储系统中为重复数据删除特性单独预留256GB的内存几乎是不可能的,何况企业级存储系统的物理空间可能要比1PB多很多。
为了能够存储更多的指纹信息,通常企业级存储系统通常将指纹分级存储在不同的存储介质中,比如热点数据存储在内存中,非热点数据存储在持久化的设备上(如SSD),这种方式与存储引擎的数据分层计数类似。
虽然采用分级存储的方式可以保证能够容纳所有的指纹信息,但是对存储在SSD的指纹检索将严重影响存储系统的性能。缓存的作用只能保证热点数据可以快速的找到指纹信息,但对于冷数据依然需要遍历整个指纹库。为了提升性能,很多存储厂商对指纹检索进行了优化,比如通过布隆过滤器进行预先检测,在确定存在的情况下再从后端读哈希值。由于布隆过滤器可以验证指纹的存在性,如果指纹不存在,存储引擎就没有必要遍历整个指纹库了,从而降低对性能的影响。

前文我们介绍存储引擎的时候曾经介绍过逻辑卷数据的管理方式,知道逻辑卷的逻辑数据块与物理数据块之间是如何建立映射关系的。当增加重复数据删除的特性后,逻辑块与物理块之间的映射关系就会变得复杂。
如果不考虑存储空间的释放,我们只需要将多个逻辑空间指向相同的物理空间即可,不需要做其它额外的工作。但是逻辑卷总是有可能删除的,或者其它任何修改逻辑空间与物理空间关系的逻辑都会导致逻辑空间不再指向这个物理空间。问题的关键是,由于可能有其它逻辑空间指向这个物理空间,如何知道已经没有任何逻辑空间指向这个物理空间了呢?
目前业界普遍的做法是为物理空间增加一个引用计数,当引用计数减小到0的时候即认为该物理空间没有逻辑空间指向该物理空间,此时就可以释放该空间了。以ZFS的重复删除特性为例,为了实现重复删除的功能,其引入DDT(Data Dedup Table)的结构。该结构可以理解为上文所说的指纹库,在该结构中通过一个查询树维护所有指纹,便于快速查询。
ZFS相关的核心数据结构如下图所示,中间的数据结构为ddt_entry_t,表示一个DDT表中的一项,其中包含指纹信息ddt_key_t和物理数据块描述信息ddt_phy_t。物理块描述信息数据结构中包含物理数据的地址、引用计数和创建时间等信息。
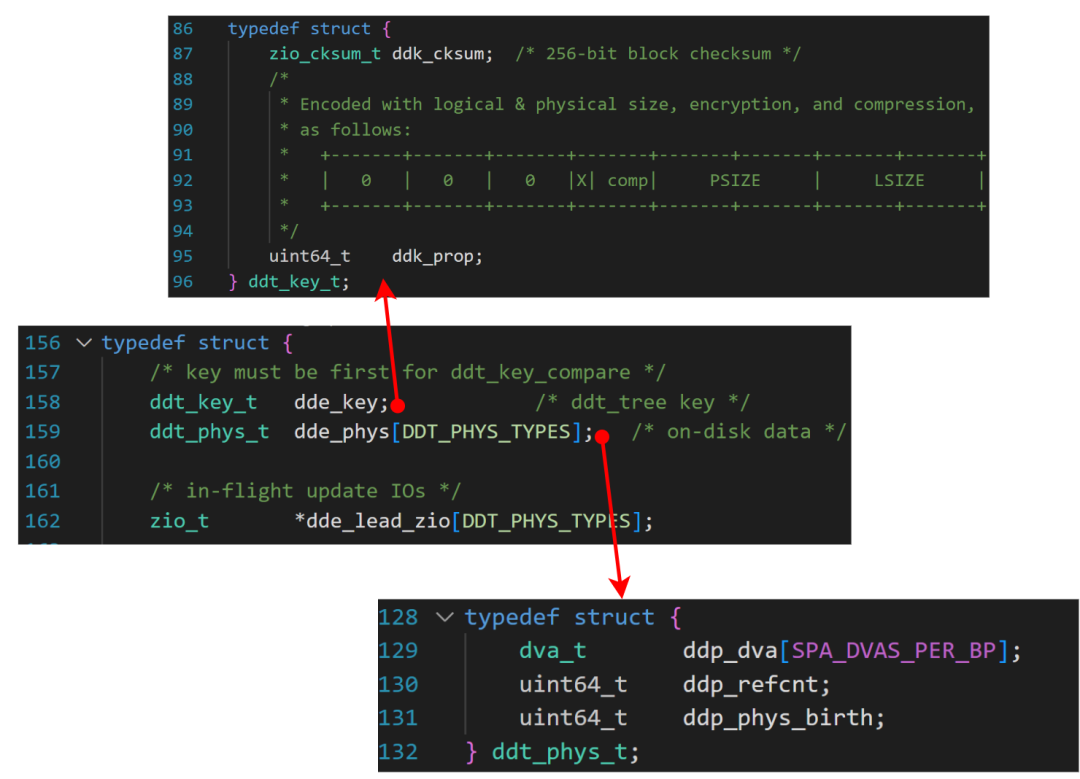
ZFS 数据去重核心数据结构
基于上述信息,当有重复数据时,相应的引用计数就会增加,当有逻辑卷或者快照删除时,对应的引用计数也会减少,从而维护物理数据引用的一致性。
本节我们大致介绍了重复数据删除的原理,并以ZFS为例介绍了部分实现细节。不同厂商的实现细节各不相同,但大致原理不会有太大的差异。接下来我们将继续介绍数据效率的另外一个重要的内容---数据压缩计数。

计算机数据存储简史,从纸到云的变迁 基于Fuse的最简单的文件系统 代码覆盖率测试,聊聊gcov和lcov SAN存储的概念与基于iSCSI的操作实战 全面了解SSD,SSD关键术语全面解析 分布式虚拟文件系统,数据编排小能手 高性能的基础RAID0,实操与代码实现解析 网络文件系统,年近五十岁,老当益壮 弹性空间之道,逻辑卷管理(LVM)技术 计算机数据存储简史,从纸到云的变迁 基于树莓派和硬盘柜搭建一个几十TB的家用NAS Linux存储软件栈到底有多复杂,存储软件栈全景概览 分布式存储的软件架构与案例解析 数万客户端NFS服务的困境,聊聊自动挂载技术 深入了解一下SSD的相关内容 什么是文件系统,以Linux中的Ext4为例细聊一下 对象存储,从单机到分布式的演进 为什么都说NFS读写性能差,如何进行优化?SPDK块设备抽象层bdev对多种后端模块(驱动)的支持 计算机的存储体系与性能金字塔 Linux是如何将硬盘展示给用户的,从物理设备到通用块层 聊聊ZFS文件系统,一个免费开源的存储引擎 云计算的出现与存储系统形态的改变 分布式数据路由的基石,聊聊一致性哈希算法 如何创建一个比物理空间大的卷 ,聊聊自动精简配置 介绍一款免费开源的企业级存储软件 企业级磁盘阵列软件架构与功能概述 高性能存储的基础,了解一下内存的方方面面 介绍几个学习存储通信协议的利器 从电商系统认识数据与数据的存储

