




背景
客户实时采集任务在5月6日采集失败,而且最近业务并没有做任何变更,情况发生比较突然,需要介入排查原因。
环境调研
-
操作系统: ARM( 2核 48线程 96 cpus , 756G ) 麒麟V10 sp3
-
Oceanbase: 4.2.1 bp3 hotfix4
-
OceAnbase架构:5副本架构,租户均是 1-1-1 3副本,共计 10 个租户(sys租户为5副本)
-
业务系统:XXX系统(内部系统) 租户ID 1016
-
业务特性:典型跑批场景truncate + dml(原Oracle中使用的是临时表,OB上换成了实体表 +truncate)
问题排查
业务场景分析
在与客户沟通后,了解业务处理逻辑,正常情况下,任务在工作日早上9点至下午3点30分,从A系统(Oracle)将实时数据增量抽取至B系统(Oceanbase),B系统在接收到数据后,首先清理B库中间件表(TRUNCATE方式),数据处理后,最终入B系统。
开发已经排查A系统侧的采集任务,耗时正常,问题出在B系统数据处理逻辑上。
B系统数据处理逻辑拆分
B系统数据处理逻辑简化后,基本都是TRUNCATE+INSERT,没有其他比较复杂的逻辑,存在有并发处理,不过针对不同表。
利用obproxy的slow日志进行分析,正常阶段TRUNCATE和异常阶段TRUNCATE
正常阶段Truncate 耗时
注:正常truncate耗时在30s左右,虽说较长,但此时不影响程序调度
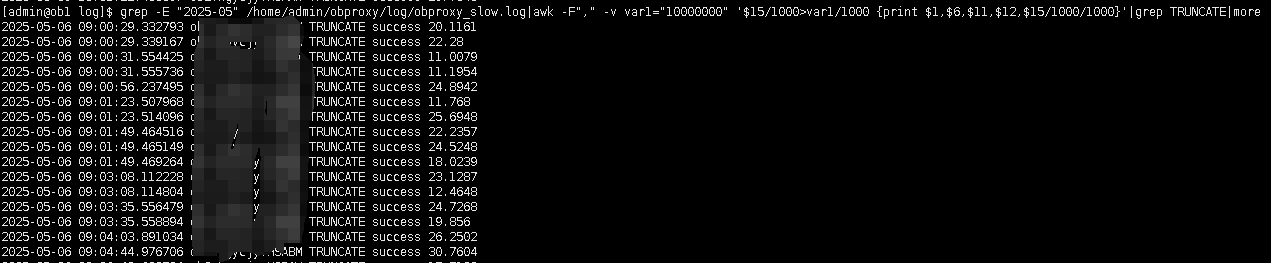
异常阶段Truncate 耗时
可以看到truncate达到了惊人的1000s。

TRUNCATE异常耗时分析
那么truncate为什么耗时这么久,而且最大耗时又那么精确在1000s,这里需要梳理下Oceanbase的DDL逻辑,为保证表结构元信息的正
确性,在执⾏DDL时,内部会对表结构元信息即 schema 信息进⾏full schema查询,插入等操作。
为了确认内部SQL的执行效率,排查observer.log和rootservice.log,是否有SQL超时记录。
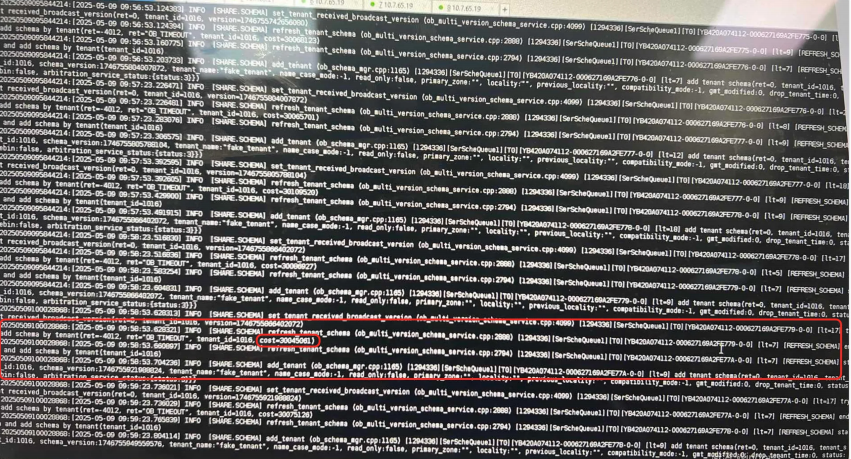
在observer.log中发现有OB_TIMEOUT的记录,耗时30s,根据tenant_id=1016,确认为异常系统B的租户ID,超时日志为刷新schema version符合DDL特征。
猜测,内部刷新schema version的SQL在30s超时后,可能会反复调用,直到校验通过。
内部SQL超时分析
正常的内部SQL,又为何会出现超时的情况?
SQL执行超时无非2个原因,表数据量大或者执行计划波动。
在Oceanbase数据库中,进行DDL时,为了维护多个节点执行的一致性,会记录DDL的操作信息,为此排查Oceanbase的众多__xxx_history表。发现表__all_virtual_table_history数据量达到220万,租户1016的记录就达到150万。
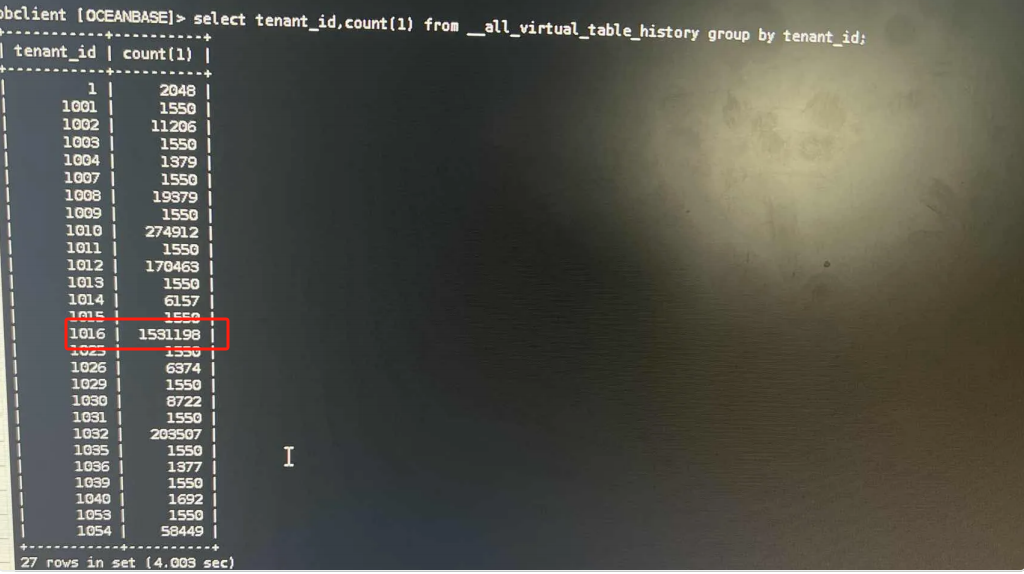
租户1016的DDL明细,其中有4个都在20万以上,与业务进行确认,这4个都是在采集任务中需要频繁TRUNCATE的表。
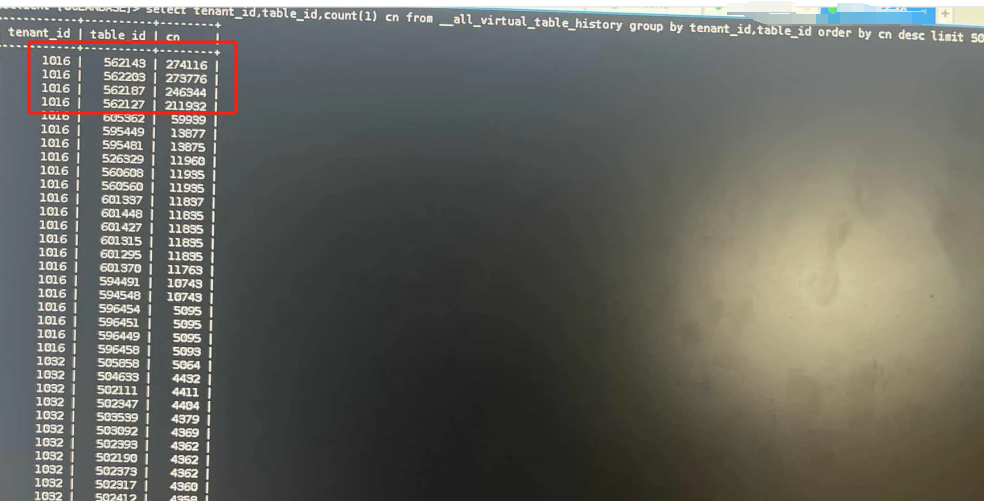
查询租户1016其中一张DDL表,发现从2024年7月至今的DDL记录一直都在,没有清理,所以__all_virtual_table_history积累这么大。
综合分析
经过以上的排查分析,基本已经确定TRUNCATE慢的原因:
1、租户1016采集任务频繁进行DDL,导致__all_virtual_table_history数据较大
2、__all_virtual_table_history数据积累到一定程度,内部SQL 30s超时,校验失败,可能存在反复调用校验
3、Truncate在1000s后结束,可能也触发内部超时参数。
针对 2、3的原因,排查相关参数,找到2个参数
internal_sql_execute_timeout OB内部SQL执行超时时间,默认30s
_ob_ddl_timeout OB DDL超时参数 默认1000s

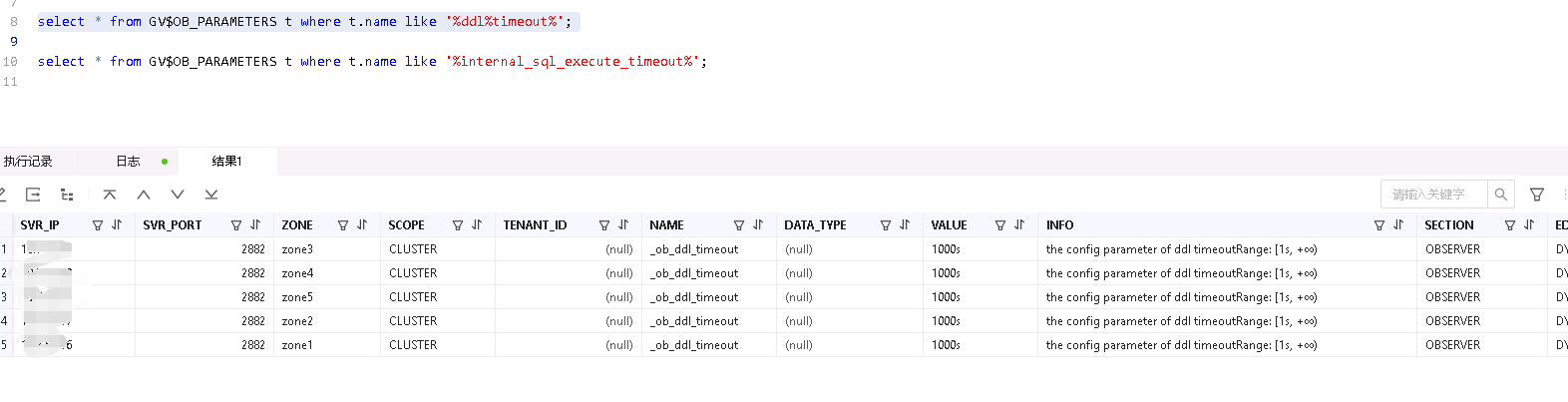
以上2个参数也再次验证了,日志记录的30s超时,和DDL1000s的现象
解决方案
临时解决–调整internal_sql_execute_timeout参数
在了解了内部SQL执行超时是30s后,调整超时时间为10分钟,这也是对业务影响比较小的调整。最终与客户沟通,采用此种方法进行临时解决。
调整参数后,业务调度任务可以进行,采集时间较之前有所增加,但可以接受。
临时解决–清理__all_virtual_table_history表
__all_virtual_table_history表的清理逻辑为,当 table_id 发生变化后,系统表中的相关记录才会进行自动清理,否则不进行清理。4.x版本truncate不再采用3.x的drop+create重建逻辑。需要对表进行重建,或者将truncate的并行关闭,也会内部退化为 drop + create 逻辑。与3.x的区别是,3.x的drop + create 逻辑是异步执行,不会锁表,4.x会进行表锁。
所以需要将租户1016内,频繁truncate的表进行drop+create重建,__all_virtual_table_history表才会进行自动清理,对于一个稳定的系统来说,调整较大,业务暂不采用。
自动清理相关参数:
schema_history_recycle_interval 10m 自动清理任务调度时间间隔
schema_history_expire_time 7d 自动清理元数据失效时间(DROP后的天数)
永久解决–升级版本
在与OB厂商交流后,可升级至4.2.1bp10及以上,彻底解决此问题。
升级注意事项:
1、当前__all_virtual_table_history表数据量仍比较大,升级前建议对schema版本号过多的表进行重建,降低__all_virtual_table_history表数据量,以防止升级时升级任务超时异常。
2、先进行测试环境升级测试,待稳定运行且应用测试无问题后择机再进行生产环境升级
3、在建议在无业务或业务低峰期进行升级操作,建议可优先采用“停服升级”
4、升级期间禁止执行DDL 、合并,可在升级前进行合并操作
5、版本升级操作目前不支持回退操作,升级流程可采用先对主备租户解耦后升级主集群,待主集群升级成功且业务验证通过后,再进行备租户重建
