




Convolutional Neural Networks for Sentence Classification
由于下周一要考试了,本周一部分花在笔记整理和内容重新学习上面。因此本周的文献阅读就从简,选择了一篇实验4所提供的CNN解决文本分类的论文作为本周的文献阅读内容。同时也已经将4次实验的代码公布在GitHub上(https://github.com/Snake8859/deep_learning_homework),望大家批评指正。
研究背景
深度学习模型在计算机视觉和自然语言处理领域方面都超越传统的方法,取得巨大突破。在自然语言处理中,词嵌入学习和RNN是首选方法,他们在处理序列语言有先天的优势。在计算机视觉领域,CNN是首选方法,通过CNN提取图像的卷积特征,能够较好表征图像的信息。随着研究的深入,CNN被证实对NLP有效,于是不少NLP领域的学者试图将CNN引入来处理序列语言数据。本篇文献的作者就是基于这样思想,利用卷积神经网络构建文本分类模型(Text-CNN),然后在各项文本分类数据集上进行实验,最终实验结果表明CNN也能在文本分类任务中取得不错的成绩。
解决方案
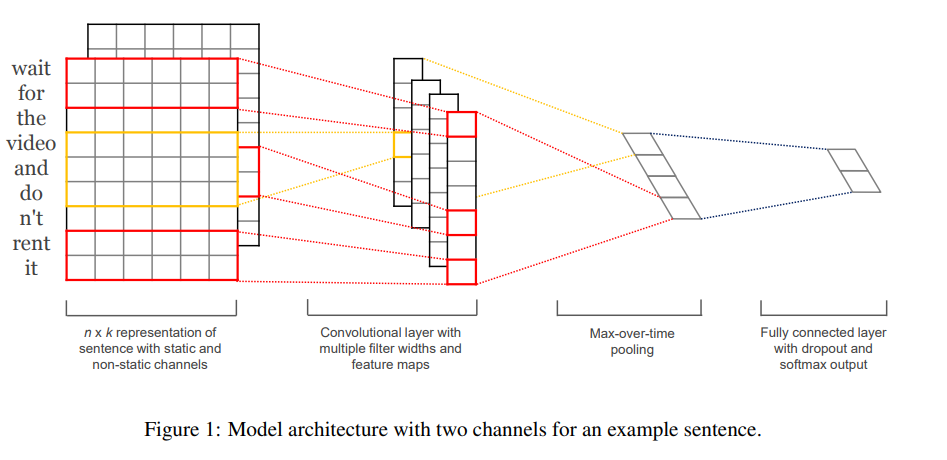
Text-CNN由四层结构组成,分别是词嵌入层、卷积层、池化层和全连接层。
词嵌入层:将输入文本的每个词语通过空间映射,转化为向量,进而可以使用低维的向量来表示每一个词语。将各个词语的向量表示连接起来便可以得到二维矩阵。
数学描述即为,假设假设代表在句子中第个词的词向量,一个句子长度为(必要时填充),那么可以表达为:
其中代表串联。通常可以表示为词的串联。
卷积层:利用卷积层提取词与词之间的卷积特征,即句子局部特征。卷积层的卷积核的宽度等于词向量的维度,卷积核的长度一般设置为3、4、5(论文实验配置)。可以设置多个卷积核提取文本的多层特征。
数学描述即为,一个卷积操作包含卷积核,即使用窗口大小为,(是词数量,是编码维度)来生成一个新特征。比如特征是由窗口内的词生成,即
其中是偏置项,是非线性函数。这个卷积核遍历整个句子的词用于生成特征图
其中。
池化层:一般采取 max pooling,池化大小与特征图一致,提取特征图取最大值,即每个特征图取最大值。
全连接层:采用Dropout防止过拟合,神经元个数由句子类别决定,使用softmax函数输出各个类别的概率。
以上过程整体描述为,对输入内容进行词嵌入编码,得到“词图像”,接着送入卷积层,提取词与词之间的卷积特征,然后经过最大池化,得到词特征,将这些特征拼接在一起形成列向量,最后使用全连接层用于分类,输出分类结果的概率分布。
实验分析
数据集
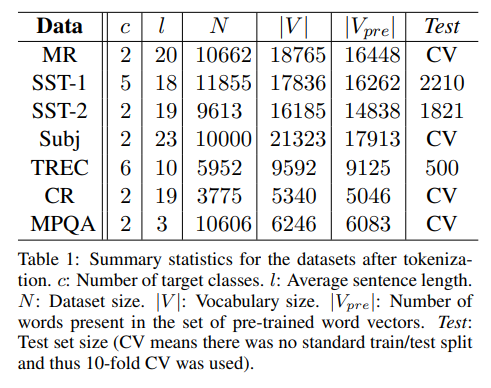
c是类别,l是长度,N是数量,V是字典大小,是预训练词向量,Test是测试集大小
MR:电影评论,分为正例和负例。 SST-1:斯坦福情绪树库,MR数据集的扩展。 SST-2:同SST-1,但是只有正例和负例。 Subj:主观性数据集,其中任务是将句子分类为主观或客观。 TREC:TREC问题数据集——任务涉及将一个问题分为6种问题类型(问题是关于人、位置、数字信息等)。 CR:客户对各种产品(相机、MP3 等)的评论。任务是预测正面/负面评论。 MPQA:两个文本类别的数据集。
预训练词向量
作者采用公开可用的word2vec向量,每个向量的维度为300,这些向量经过Google新闻的1000亿个单词的训练。不存在于预训练词向量中的词被随机初始化。
不同模型变种
CNN-rand:所有词向量随机初始化,从头开始训练模型。 CNN-static:使用预训练词向量,没有预训练词向量的词随机初始化,且不更新词向量。 CNN-non-static:同static,只是词向量更新。 CNN-multichannel:具有两组词向量的模型。每组向量都被视为一个“通道”,每个过滤器都应用于两个通道,但梯度仅通过其中一个通道进行反向传播。因此,该模型能够微调一组向量,同时保持另一组向量的静态。两个通道都用 word2vec 初始化。(没太明白)
实验结果
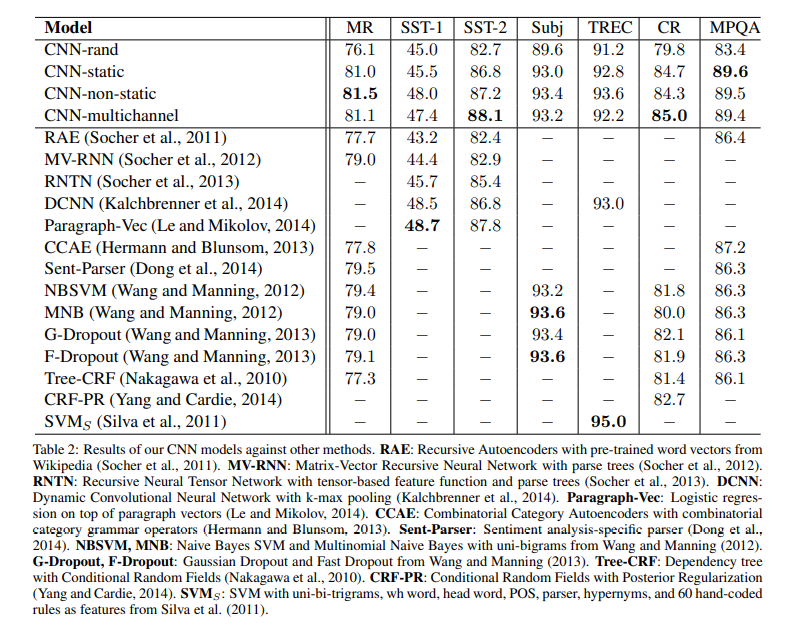
从实验结果中可以看到,随机初始化(CNN-rand)的模型表现一般,但是使用预训练词向量的模型(CNN-static)表现非常好,对预训练词向量模型(CNN-non-static)进行微调能进一步提高。
总结与展望
该篇文献基于word2vec构建的卷积神经网络较好解决了文本分类问题,证实了CNN能够被应用到NLP任务中。同时在较少参数调整下,也能取得出色的结果,也进一步证实了无监督的词向量预训练是 NLP 深度学习的重要组成部分。未来将继续研究各种CNN模型在NLP中的进一步应用。
论文:https://arxiv.org/abs/1408.5882
