




Densely Connected Convolutional Networks
研究背景
卷积神经网络(CNN)已经成为视觉对象识别的主要方法,虽然它早在上世纪90年代就被提出,但是受限于当时的计算硬件和数据规模,直到这几年,随着计算硬件、数据集成和网络改进的发展,CNN才成为了可能。深度是神经网络的关键属性,最早的LetNet-5仅有5层,后来VGG和GoogLeNet发展到20层左右。但是随着CNN越来越深,一些问题也逐渐浮现,主要是梯度消失和网络退化,许多研究已经提出相关的方法解决这些问题,例如ResNet和Hightway Network,它们都通过在层与层之间添加跳线连接,使得网络达到100层以上。该篇文献基于连接的思想,为了最大化网络中各层之间的信息交互,提出了密集连接方式,即每个层与其前面的所有层连接,并采用特征重用的方式综合前面层的特征,用密集连接方式构建的网络称为DenseNet。DenseNet在四个分类的数据集上(CIFAR-10,CIFAR-100,SVHN和ImageNet)都取得超过其他先进的方法。
问题描述
ResNet的提出,让我们了解到如果在卷积神经网络的层与层之间添加跳线连接,那么卷积神经网络的深度可以不断增加,从而提高准确度并易于训练。在近期的研究中,一种名为Stochastic depth训练方式被提出,它在训练期间使用随机丢弃层来改善深度ResNet,这表明不是所有层都有必要存在,深度网络中存在大量冗余的层。基于这点的思想,DenseNet与ResNet不同之处在于其不是通过更深或更宽的架构来提高网络的学习能力,而是通过密集连接加强特征交互和特征重用的方式来挖掘网络的潜力,构建易于训练和少参数的网络模型。
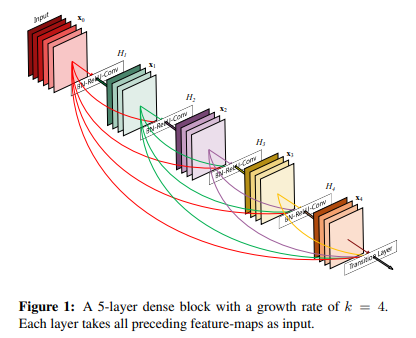
解决方案
DenseNet组成
密集连接
假设一个卷积网络包含层,每层都实现了一个非线性变换,其中表示层的索引。可以是诸如批量归一化(BN)、线性整流单元(ReLU)、池化(Pooling)或卷积(Conv)等操作的复合函数。网络的输入为图像,第层输出表示为。
ResNet:对于ResNet采用的跳线连接,可表示为:
ResNet的跳线连接利用前一层的信息,避免梯度消失和网络退化,但是采用求和方式,可能会阻碍网络中的信息流。
DenseNet:对于DenseNet采用密集连接方式,因此第层接收所有先前图层的特征图,即,作为输入,可表示为:
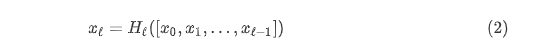
其中表示层输出的特征图的串联(concatenation)。在该篇文献中,对于采用先批量归一化(BN),然后线性整流单元(ReLU),最后接一个3×3的卷积(Conv)。
参考:https://zhuanlan.zhihu.com/p/67311529
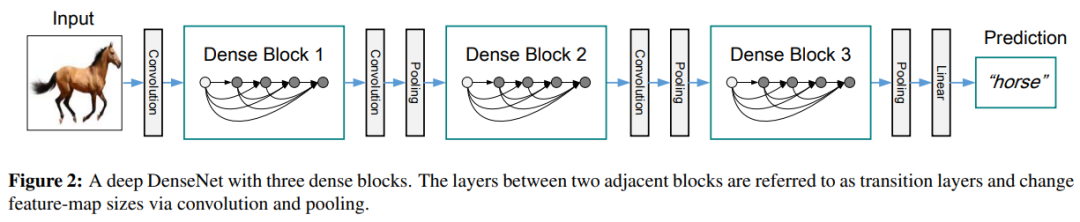
过渡层
作者将具有密集连接的单元称为Dense块,在这些块与块之间的层称为过渡块,它们进行卷积和池化,用于改变特征图尺寸和通道,减少后续计算量。如下图所示(一个有三个Dense块的DenseNet,两个相邻块之间的层被称为过渡层,并通过卷积和池化来改变特征图大小)
增长率
如果每个函数输出个特征图,那么第层有个输入特征图,其中是输入层的通道数。作者将超参数称为网络的增长率。
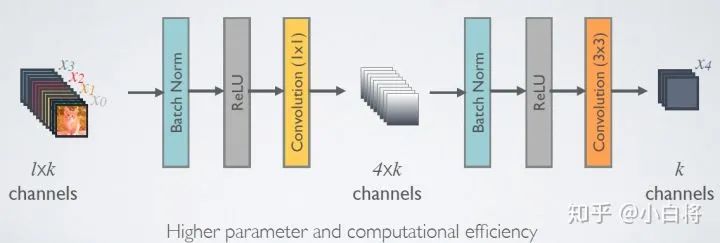
瓶颈层
尽管每层只产生个特征图,但是层数增加,特征图串联数量就越多,计算效率会不断降低。因此作者添加1×1的卷积层,放在3×3的卷积层之前起到减少特征数量的作用,以提高计算效率。作者将添加瓶颈层的网络称为DenseNet-B,其复合函数是这样的:BN-ReLU-Conv(1×1)-BN-ReLU-Conv(3×3),在实验中,让1×1卷积层输入个特征图。
参考:https://zhuanlan.zhihu.com/p/37189203
压缩
为了进一步提高模型的紧凑性,作者在过渡层中减少特征图的数量。如果密集块包含个特征图,那么让后续的过渡层输出个特征图,其中为压缩因子,且。当时,通过过渡层的特征图的数量保持不变。将的DenseNet称作DenseNet-C,在实验设置。同时使用瓶颈层和压缩的模型称为DenseNet-BC。
DenseNet网络结构
CIFAR和SVHN实验的DenseNet
对于CIFAR10和SVHN数据集,在实验过程中使用的DenseNet具有三个密集块,每个块具有相等层数。在进入第一个密集块之前,对输入图像进行卷积,输出16通道特征图。在两个连续的密集块之间,使用一个1×1的卷积层和一个2×2的瓶颈池化层作为过渡层。三个密集块输出的特征图尺寸分布是32×32,16×16和8×8。
实验中,基础版本的DenseNet超参数配置为:。DenseNet-BC的超参数配置为:。
ImageNet实验的DenseNet
对于ImageNet数据集,在实验过程中使用DenseNet-BC架构,包含4个密集块。在进入第一个密集块之前采用7×7和步长为2的卷积核进行卷积,输出特征图。其他层的特征图数量由超参数决定。具体的详情如下表所示。
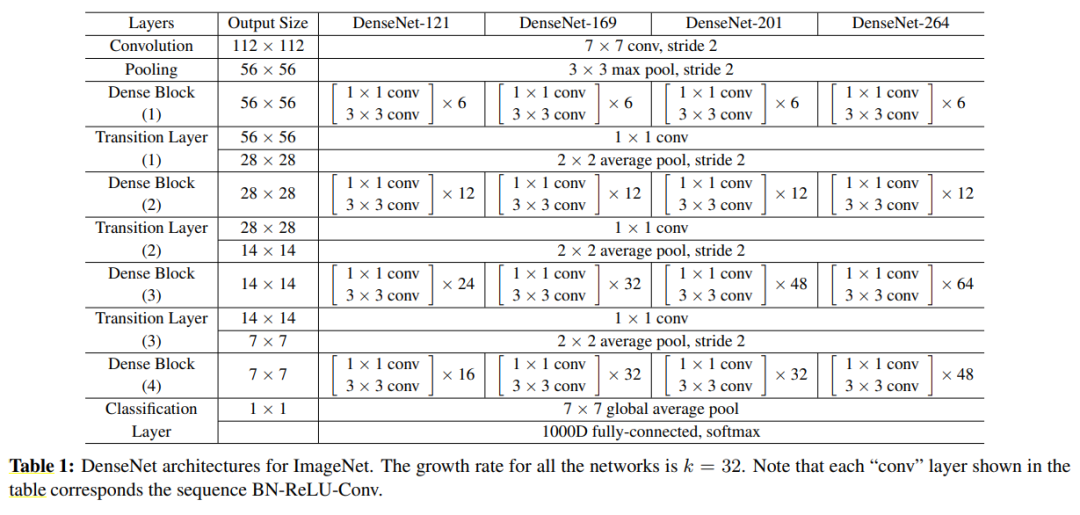
用于ImageNet的DenseNet网络架构。所有网络的增长率都是k=32。注意,表格中的Conv层表示BN-ReLU-Conv的组合
实验分析
数据集
CIFAR:两个CIFAR数据集都是由32×32像素的彩色图片组成的。CIFAR-10(C10)包含10个类别,CIFAR-100(C100)包含100个类别。训练和测试集分别包含50000和10000张图片,作者将5000张训练图片作为验证集。对于两个数据集进行标准数据增强(镜像/移位)。通过数据集名称末尾的“+”标记(例如,C10+)表示该数据增强方案。对于预处理,作者使用各通道的均值和标准偏差对数据进行归一化。
SVHN:街景数字(SVHN)数据集由32×32像素的彩色数字图片组成。训练集有73257张图片,测试集有26032张图片,以及531131张照片进行额外的训练。训练过程中使用所有的训练数据,没有任何数据增强,同时使用训练集中的6000张图片作为验证集。对于预处理,将像素值除以255,归一化到0-1之间。
ImageNet:ILSVRC 2012分类数据集包含1000个类,训练集120万张图片,验证集5万张图片。训练过程中使用数据增强方案来增加训练图片,并在测试过程中使用single-crop和10-crop。
训练细节
所有网络都使用随机梯度下降(SGD)进行训练。
在CIFAR和SVHN上,训练批量为64,分别训练300和40个周期。初始学习率设置为0.1,在训练周期数达到50%和75%时除以10。
在ImageNet上,训练批量为256,训练90个周期。学习速率最初设置为0.1,并在训练周期数达到30和60时除以10。由于GPU内存限制,最大的模型(DenseNet-161)以小批量128进行训练。为了补偿较小的批量,训练该模型的周期数调整为100。
对于没有数据增强的三个数据集,即C10,C100和SVHN,在每个卷积层之后(除第一个层之外)添加一个Dropout层,Dropout率为0.2。
CIFAR和SVHN的分类结果
CIFAR和SVHN的分类结果如下表所示。
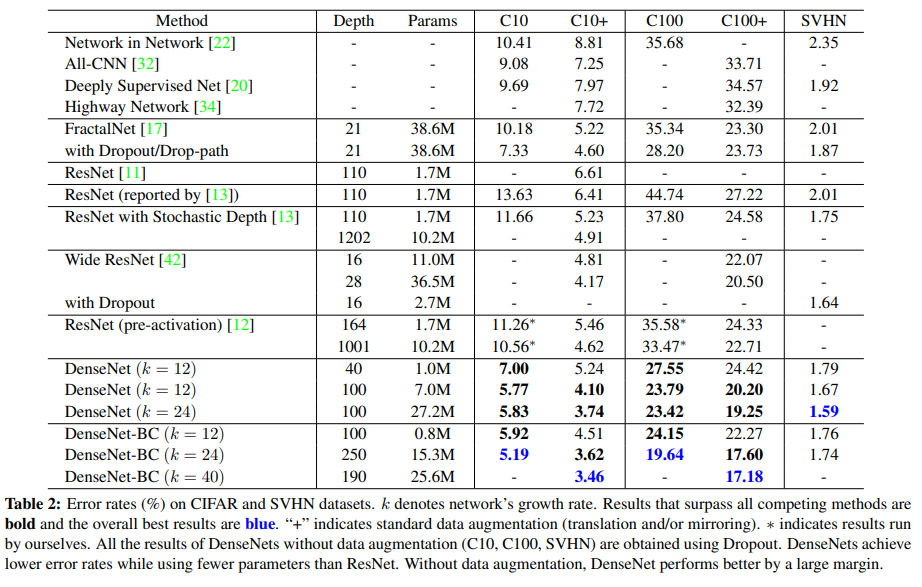
超越所有竞争方法的结果以粗体表示,整体最佳效果标记为蓝色。“+”表示标准数据增强(翻转和/或镜像)。“*”表示作者的运行结果。
准确率比较
在CIFAR数据集上,的DenseNet-BC表现优于其他目前先进的方法。它的C10+错误率为3.46%,C100+的错误率为17.18%。
在SVHN数据集上,在使用Dropout的情况下,的DenseNet表现也优于其他方法。它的错误率为1.59%。但是也可以发现层数的继续增加并没有进一步改善性能,这可能因为SVHN是简单的任务,极深的模型可能导致过拟合。
参数量比较
首先对于DenseNet内部的参数量比较可以看到,随着和的增加,模型的参数量越大,但是其所带有模型增益也越大。从表2中C10+和C100+列可以看出,在C10+上,随着参数数量从1.0M,增加到7.0M,再到27.2M,误差从5.24%,下降到4.10%,最终降至3.74%。在C100 +上,也可以观察到类似的趋势。
其次对于DenseNet和其他网络比较可以看到,DenseNet使用更少的参数,但是在性能依然达到或超过其他模型。例如对于的DenseNet-BC只有15.3M的参数,但是其性能优于其他模型(具有超过30M个参数的FractalNet和Wide ResNet);对于的DenseNet和1001层的ResNet相比,在C10+和C100+上的性能差不多(对于C10+,错误率分别为4.62%和4.51%,而对于C100+,错误率分别为22.71%和22.27%),但是参数量仅有后者10%左右。
ImageNet的分类结果
ImageNet的分类结果如下表所示。
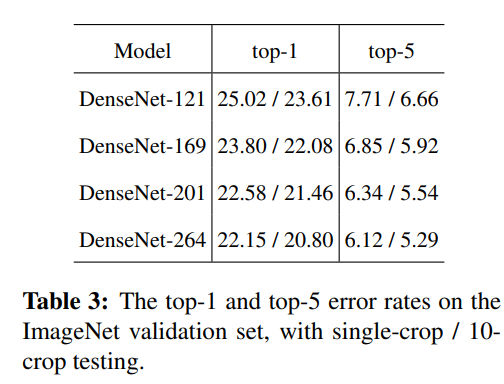
ImageNet验证集上的top-1和top-5错误率,测试分别使用了single-crop和10-crop
将DenseNet和ResNet的结果进行比较,如下图所示。
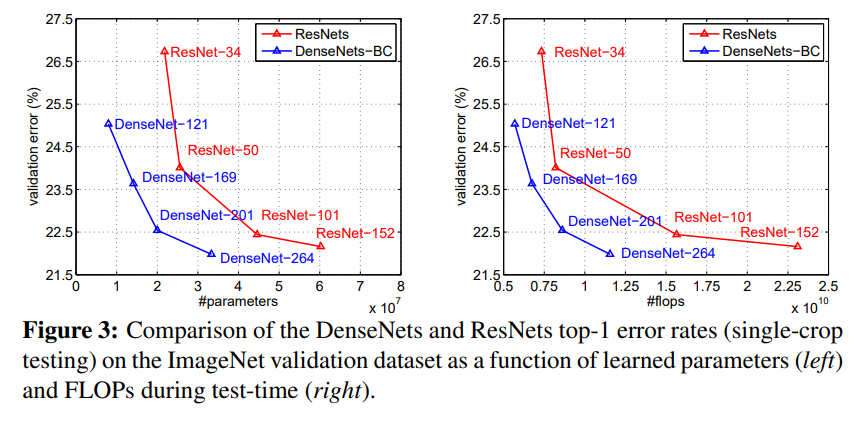
从图中的结果表明,在DenseNet和ResNet的验证误差相当的情况下,DensNet需要的参数数量和计算量明显减少。例如,上图左侧中具有20M个参数的DenseNet-201与具有超过40M个参数的101层ResNet验证误差接近;上图右侧中DenseNet只需要与ResNet-50相当的计算量,就能达到与ResNet-101接近的验证误差,而ResNet-101需要2倍的计算量。
讨论
该部分是对于密集连接和特征重用的可视化和解释的讨论,暂未细读理解,待未来补充。
总结与展望
该篇文献提出新的卷积网络架构,将其称为密集卷积网络(DenseNet),通过密集连接和特征重用,较好的改善了网络的性能。DenseNet可以轻易扩展到数百层,没有训练困难,同时随着模型扩大,其性能也不断的提升,没有下降和过拟合的趋势。此外DenseNet仅需要更少的参数和计算量就能达到和超越其他先进的方法。未来将会把DenseNet应用到其他计算机视觉任务中,研究DenseNet的这种方式对于其他视觉领域是否也具有相同的效果。
论文:Huang, G., Liu, Z., Van Der Maaten, L., & Weinberger, K. Q. (2017). Densely connected convolutional networks. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 4700-4708).
