




这里我们分析一下,redis是如何执行一条命令的,相比PostgreSQL,redis的命令执行流程要简单很多。redis服务端启动后会创建一个事件循环,事件循环会等待命令请求,在等待命令请求前,其实还有一个客户端建立连接请求的过程,客户端建立连接,并注册一个读处理函数,当有命令请求时,会调用对应的处理函数。处理函数直接执行命令,相当于执行器,无需经过优化器,没有生成执行计划的过程。
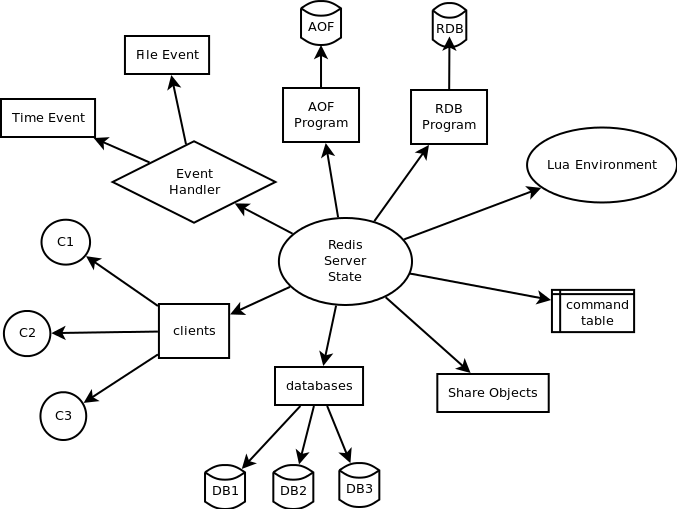
主流程
redis主流程如下,启动后会做一些初始化工作,创建监听,创建epoll,注册监听事件,然后进入事件循环,等待客户端发起连接。
main(int argc, char **argv)
--> spt_init(argc, argv); // 初始化进程标题,通过ps命令看到的进程名称
--> zmalloc_set_oom_handler(redisOutOfMemoryHandler); // 设置内存分配失败时的自定义处理函数
--> initServerConfig(); // 设置 Redis 的全局默认配置参数
--> ACLInit(); // ACL(访问控制列表)子系统的初始化
--> moduleInitModulesSystem(); // 初始化模块系统
--> initServer(); // 服务端初始化
--> createSharedObjects();
--> adjustOpenFilesLimit();
--> aeCreateEventLoop(server.maxclients+CONFIG_FDSET_INCR); // 事件循环初始化
--> aeApiCreate(eventLoop)
--> epoll_create(1024); // 创建 epoll 实例
--> listenToPort(server.port,&server.ipfd) // 创建监听套接字
--> anetTcpServer(server.neterr,port,addr,server.tcp_backlog);
--> _anetTcpServer(err, port, bindaddr, AF_INET, backlog)
--> socket(p->ai_family,p->ai_socktype,p->ai_protocol)
--> anetListen(err,s,p->ai_addr,p->ai_addrlen,backlog,0)
--> bind(s,sa,len)
--> listen(s, backlog)
--> anetNonBlock(NULL,sfd->fd[sfd->count])
--> 初始化默认的16个数据库
--> createSocketAcceptHandler(&server.ipfd, acceptTcpHandler) // 设置新客户端连接处理函数
--> aeCreateFileEvent(server.el, server.module_blocked_pipe[0], AE_READABLE,
moduleBlockedClientPipeReadable,NULL)
--> InitServerLast();
--> redisSetCpuAffinity(server.server_cpulist);
--> setOOMScoreAdj(-1);
--> aeMain(server.el);
while (!eventLoop->stop)
aeProcessEvents(eventLoop, AE_ALL_EVENTS | AE_CALL_BEFORE_SLEEP | AE_CALL_AFTER_SLEEP);
--> aeApiPoll(eventLoop, tvp)
--> aeDeleteEventLoop(server.el);
redis服务端会调用aeApiPoll函数等待事件,当事件发生时,会调用aeApiPoll函数,该函数会调用epoll_wait函数,该函数会阻塞当前线程,直到有事件发生。调用栈如下:
aeApiPoll(aeEventLoop * eventLoop, struct timeval * tvp) (redis\src\ae_epoll.c:93)
aeProcessEvents(int flags, aeEventLoop * eventLoop) (redis\src\ae.c:398)
aeMain(aeEventLoop * eventLoop) (redis\src\ae.c:495)
main(int argc, char ** argv) (redis\src\server.c:7553)
当有新连接到达时,会调用acceptTcpHandler函数,该函数会创建一个新的客户端连接,创建一个客户端对象client,该对象会保存该客户端的相关信息,比如连接信息,客户端ID号,当前数据库,收到的命令缓冲区,发送缓冲区等等,基本所有与客户端相关的信息都保存在client对象中。并注册一个读处理函数,当有命令请求时,会调用对应的处理函数。调用栈如下:
acceptTcpHandler(aeEventLoop *el, int fd, void *privdata, int mask)
--> anetTcpAccept(server.neterr, fd, cip, sizeof(cip), &cport)
--> anetGenericAccept(err,s,(struct sockaddr*)&sa,&salen)
--> accept(s,sa,len)
--> acceptCommonHandler(connCreateAcceptedSocket(cfd),0,cip);
--> createClient(conn)
--> connNonBlock(conn);
--> connSetReadHandler(conn, readQueryFromClient); // 设置了读处理函数
--> connSetPrivateData(conn, c);
--> selectDb(c,0); // 默认使用0号数据库
与客户端建立连接完成后,当客户端向redis发送命令时,即当有数据可读时,会调用readQueryFromClient函数,首先是读取客户端发送的命令(字符串),然后根据RESP协议对命令进行解析,最后根据解析后的命令调用相应的命令处理函数。因RESP协议非常简单,通常就是命令+参数,并且已经定义了分隔符,所以解析过程也非常简单,无需像PostgreSQL那样需要完整的词法分析,语法解析,无需flex,bison等工具。
readQueryFromClient(connection *conn)
--> connRead(c->conn, c->querybuf+qblen, readlen) // 从套接字读取数据到缓冲区
--> conn->type->read(conn, buf, buf_len);
--> processInputBuffer(c); // 解析redis协议,将命令存入客户端的argv数组
--> processInlineBuffer(c) // 处理内联命令,并创建参数对象
--> sdsfreesplitres(argv,argc);
--> processMultibulkBuffer(c) // 将 c->querybuf 中的协议内容转换成 c->argv 中的参数对象
--> processCommandAndResetClient(c) // 执行命令,并返回结果
--> processCommand(c)
--> call(c,CMD_CALL_FULL);
--> c->cmd->proc(c); // 执行具体的命令
比如set命令:
setCommand(client *c)
--> setGenericCommand(c,flags,c->argv[1],c->argv[2],expire,unit,NULL,NULL)
--> genericSetKey(c,c->db,key, val,flags & OBJ_KEEPTTL,1);
--> dbAdd(db,key,val);
--> dictAdd(db->dict, copy, val); // 添加一个元素到目标哈希表中
--> dictAddRaw(d,key,NULL);
--> dictSetVal(d, entry, val);
RESP协议
相比PostgreSQL数据库,客户端与redis的交互是通过命令的形式进行的,相比SQL语法,redis的命令命令语法比较简单,就是命令 + 参数的形式,核心原因是redis其实是一个键值数据库,它不是关系型数据库。redis最核心的需求是快,那就要简化设计,那么RESP协议设计的出发点,就是简单,解析速度快,简单到不需要词法分析,语法分析,只需要简单的字符串解析即可。另一点,还需要考虑AOF持久化机制,AOF持久化机制需要将命令写入文件,所以命令的格式需要简单,便于解析。
redis中所有的客户端输入命令,基本可以认为是一个字符串数组,比如:set name zhangsan,redis会解析成如下形式:*3\r\n$3\r\nset\r\n$4\r\nname\r\n$8\r\nzhangsan\r\n。这样设计的好处是容易解析,易理解。
下面我们简单说一下RESP协议的内容。客户端与redis之间的交互,通常以以下方式将RESP用作请求-响应协议
- 客户端将命令作为数组发送给Redis服务器,数组只包含批量字符串。数组中的第一个(有时也是第二个)批量字符串是命令的名称。数组的后续元素是命令的参数。
- 服务器以RESP类型回复。回复的类型由命令的实现以及可能的客户端协议版本决定。
具体如下:
第一个字节标识类型,后续字节构成该类型的内容。
| 数据类型 | 第一个字节 |
|---|---|
| 简单字符串 | + |
| 简单错误 | - |
| 整数 | : |
| 批量字符串 | $ |
| 数组 | * |
\r\n (CRLF) 是协议的终结符,它始终分隔协议的各个部分。
简单字符串编码为加号(+),后跟一个字符串。该字符串不得包含CR(\r)或LF(\n) 字符,并以CRLF(即\r\n)终止。例如redis回复命令执行成功的响应:+OK\r\n。
整数编码为冒号(:),后跟一个整数, 编码方式为::[<+|->]<value>\r\n。该整数必须是一个有符号的64位十进制整数。可选的加号(+)或减号(-)作为符号。例如::1000\r\n。
批量字符串是最频繁使用的编码方式,表示单个二进制字符串, 编码方式为:$<length>\r\n<data>\r\n。它以 $ 开头,后跟一个整数,表示字符串长度,然后是分隔符\r\n,然后是字符串,最后以\r\n结束。例如:$6\r\nfoobar\r\n。
数组编码为星号(*),编码格式为*<number-of-elements>\r\n<element-1>...<element-n>。后跟一个整数,表示数组中的元素数量,然后是分隔符\r\n,然后是数组中的元素,每个元素都是RESP编码。例如:*2\r\n$3\r\nfoo\r\n$3\r\nbar\r\n。
其他数据类型可参考官方文档Redis 序列化协议规范,这里不再赘述。
我们知道,一般客户端与服务端建立连接后,往往要进行身份验证或者协议协商,在redis中,可通过HELLO命令进行握手协商协议。
HELLO <protocol-version> optional-arguments
具体的可参考HELLO
总结
redis追求的是快,所以很多设计都是基于快来考虑的,比如redis的命令执行流程,没有经过优化器,没有生成执行计划的过程,直接执行命令,所以redis的命令执行流程非常简单,执行效率非常高。最重要的一点,redis的设计核心是围绕着内存进行的,也就是将所有数据都保存在内存中,这大大简化了redis的设计,这是redis性能高的核心。redis中很核心的一块是数据结构,什么样的数据结构足够快,同时节省内存。而PostgreSQL是围绕着磁盘进行设计的,即怎么在磁盘存储数据,查询数据更高效。随着硬件的变化,比如CXL、持久化内存等的发展,未来的数据库设计也会随着底层硬件基础设施的变化而变化。
