




生成式对抗网络
研究背景
在深度学习研究领域中,目前大多数都是在判别模型取得突破性成就,这些模型一般都是将数据转换到高维、丰富的特征空间内,然后映射到相应的类标签,例如基于卷积神经网络的图像分类。这些判别模型有如此显著的效果,主要是基于反向传播算法、dropout算法和优秀的梯度优化等技巧。但是对于生成模型方面的研究就较少,由于这些算法和技巧对于深度生成模型影响较小,导致生成模型的发展缓慢。
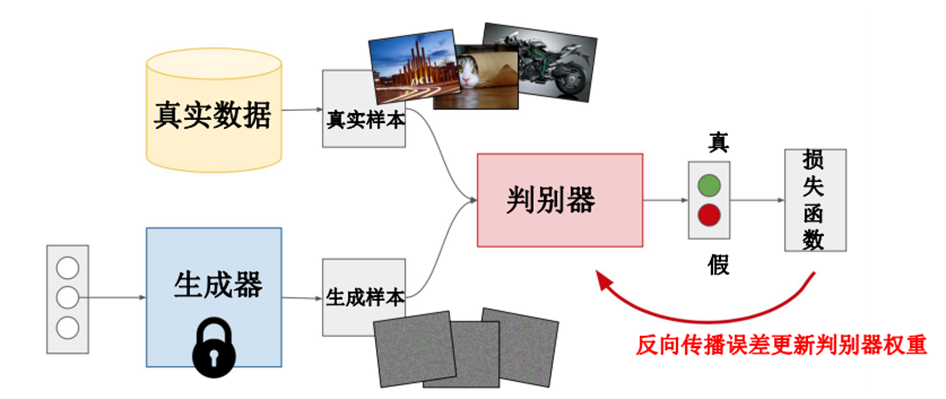
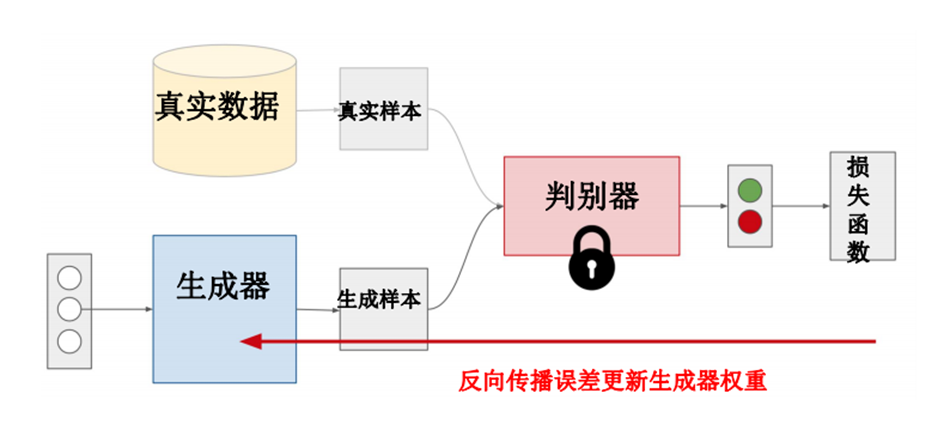
在这篇文献中,作者提出了一个新的框架,通过一个对抗的过程来训练生成模型。在这个过程内,定义两个模型:一个生成器和一个判别器。生成器用于估计数据的分布,判别器用于辅助生成器的训练。两者进行相互对抗学习,生成器学习生成一个生成数据,判别器来判别数据是来源于生成数据还是真实数据。
用作者原文中的所举例来理解就是,生成器可以被认为是假币伪造者,判别器是鉴别警察,试图发现假币。两者相互竞争,不断学习优化,直到判别器(警察)无法再辨别出数据(假币)是来源于真实的,还是生成的。
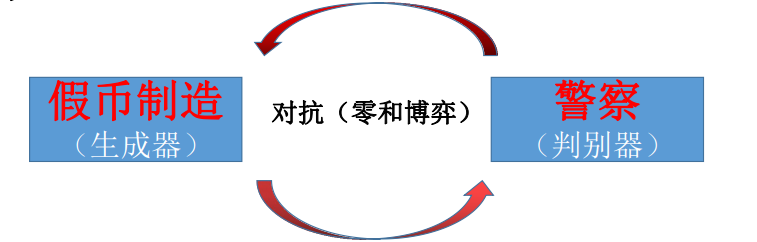
问题描述
在这篇文献的GAN框架提出之前,判别模型在计算机视觉领域占据主导地位,深度生成模型发展缓慢。主要是原因是在使用极大似然估计和相关策略中出现了许多难以解决的概率计算问题,这导致原先的优化技巧在深度生成模型上难以有较好的应用。
以极大似然估计解决深度生成模型为例,该方法可以看做是最小化真实数据分布和模型分布之间的KL散度(一般KL散度越小,两个模型越相似)。一般我们假设数据分布在某个指定的生成模型中,比如混合高斯模型,但是这样假设的模型不够去拟合一个真实的数据分布,所以需要深度神经网络这样的强大模型去拟合一个复杂的分布。
如下图,当我们给定深度神经网络的输入是某个复杂分布采样,我们希望它的输出是一个估计真实的分布。
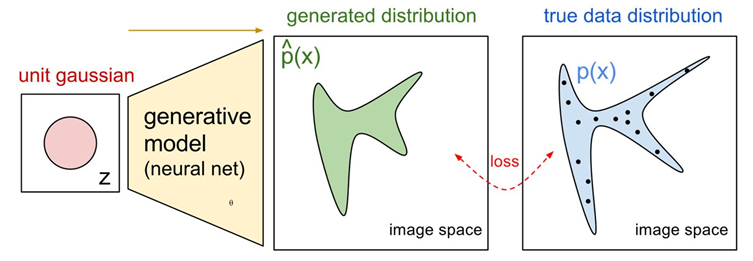
但是如果使用极大似然估计会存在问题,主要是深度神经网络的参数量太大,网络训练困难。
GAN框架的提出,避开这个问题,不直接计算相似,而是直接通过使用判别器和生成器的对抗过程,来训练生成器
传送门:https://zhuanlan.zhihu.com/p/30107433
解决方案
对抗网络的基本设计
作者通过设计一组生成器和判别器,利用对抗过程来估计生成模型。
其基本结构如下:
:生成模型的概率分布
:真实数据的概率分布
z (z):输入噪声变量
:一个参数为的多层感知器(生成器)
:一个参数为 的多层感知器(判别器)
对抗的过程是训练D,使得D能最大化判别所给定输入是真实数据还是生成数据;同时训练G,使得G能最小化所生成数据与真实数据的差异。
这种思想下,可以根据tow-player minimax game 来定义目标函数
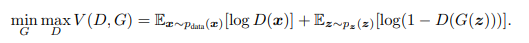
对抗网络训练过程描述
文献中给出一个直观的对抗网络训练过程
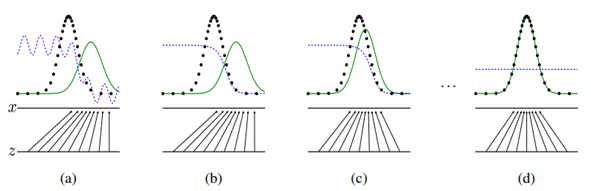
蓝色虚线代表判别器判别概率的分布;黑色点线代表真实数据分布;绿色实线代表生成数据分布;下方z是噪声,x是真实数据;z到x的箭头代表生成器到真实数据映射x=G(z)。
(a). 初始状态时,生成数据分布和真实数据分布具有一定差异,且判别器判别的状态不稳定,因此先训练判别器来更好地判别样本;
(b). 经过多次训练后,达到状态(b),判别器能有效区分生成样本和真实样本,接下来再对生成器进行训练;
(c). 训练生成器,使得生成数据的分布逼近真实数据的分布;
(d). 经过多次反复训练迭代后,达到理想状态(d),生成数据分布拟合真实数据分布,且判别器分辨不出数据是源于生成还是真实的。(判别概率均为0.5)
对抗网络训练的算法描述
网络是需要通过交替迭代的方式优化。首先在指定k步骤内优化判别器D,然后在1步骤内优化生成器D。

理论解释
证明是否为全局最佳以及算法1是否收敛。

以上所有证明过程,详见文献的Theoretical Results。
实验分析
作者以MNIST、多伦多面部数据库(TFD)和CIFAR-10作为数据集,来训练对抗网络。
其中生成器和判别器都定义为多层感知器或卷积神经网络,生成器的激活函数包括修正线性激活(ReLU)函数和sigmoid函数,判别器使用maxout激活函数。判别器训练过程中采用Dropout技巧防止过拟合。
经过训练后的对抗网络,获得其生成器,对生成器G生成的样本应用高斯Pazren窗口计算此分布下的对数似然,来估计测试集数据的概率。其结果如下表所示。

表1中的数字代表的是测试集上的平均对数似然以及在样本上计算的标准误差。
从表中结果显示,可得知,在MNIST数据集上,其平均对数似然最大,效果较好;在TFD数据集上仅次于 Stacked CAE。但该方法估计似然的方差较大且在高维空间表现不太好。

右侧四个图是生成器模型生成样本的可视化效果;最右侧的黄色框是列出相邻样本的最近训练示例(真实数据),以便证明模型没有记住训练集。
可以看到对于简单数字和人脸图像,a) MNIST和 b) TFD,其生成模型生成的数据已经逐渐逼近真实数据。但是c) d) CIFAR-10的复杂自然图像,还是存在缺少轮廓和纹理信息细节等。
总结和展望
优势
不再需要使用马尔可夫链,只需要使用反向传播算法来获得梯度,优化判别器和生成器。
学习过程中不需要近似推理,可以在模型中融入多种函数。
劣势
生成器的模型分布是隐式表示。
训练期间,D和G必须很好同步,不然会发生the Helvetica scenario,导致生成的图片虽然看起来像是真的,但是缺乏多样性。
GAN的目标函数在本质上可以等价于优化真实分布与生成分布的Jensen-Shanono散度,当两个分布互不重叠时,该值会趋向于一个常数,导致梯度消失。
