




导读
innodb的相关结构已经整理得差不多了, 于是开始考虑ibd2sql的功能和性能了. 功能可以根据之前的需求和相关issue来做, 但性能的话就稍微麻烦点. 毕竟使用的是python, 再快能有多快呢?
优化前
我们先来看看优化前ibd2sql解析100W行数据(244MB) 要多久
环境: python3.6 + ibd2sql v1.10
time python3 main.py /data/mysql_3314/mysqldata/db2/sbtest1.ibd --sql > /tmp/t20250515_old.sql

耗时1分40秒, 速度还算行, 毕竟使用场景主要是灾备恢复, 这个时候更优先考虑能够恢复, 其次再考虑性能.
但, 既然功能已经差不多了, 那就该考虑性能了!
优化1(换py版本)
我们平时的运行环境主要是python3.6(centos 7.9自带的版本), 但这个版本已经非常老了. 我们可以稍微试下新一点点的版本, 比如python 3.10(不用考虑依赖问题, 都是python自带的包, 连lz4,aes都是手写的).
time python3 main.py /data/mysql_3314/mysqldata/db2/sbtest1.ibd --sql > /tmp/t20250515_py3.10.sql

耗时1分05秒, 提升巨大, 提升1.5倍. 虽然只是换了个版本, 但是提升已经非常大了. 可喜可贺. 但还是感觉慢了, 虽然100W行看起来很多, 但是其实也就244MB文件啊.
优化2(去掉debug)
既然还是觉得慢, 那就看下慢在哪. 我们可以使用Python自带的cProfile来分析. 还可以用那玩意生成火焰图呢!
python3 -m cProfile main.py /data/mysql_3314/mysqldata/db2/sbtest1.ibd --sql > /tmp/t20250515_py3.10.sql tail -n 474 /tmp/t20250515_py3.10.sql | sort -n -k 2 | tail -10 tail -n 474 /tmp/t20250515_py3.10.sql | sort -n -k 1 | tail -10
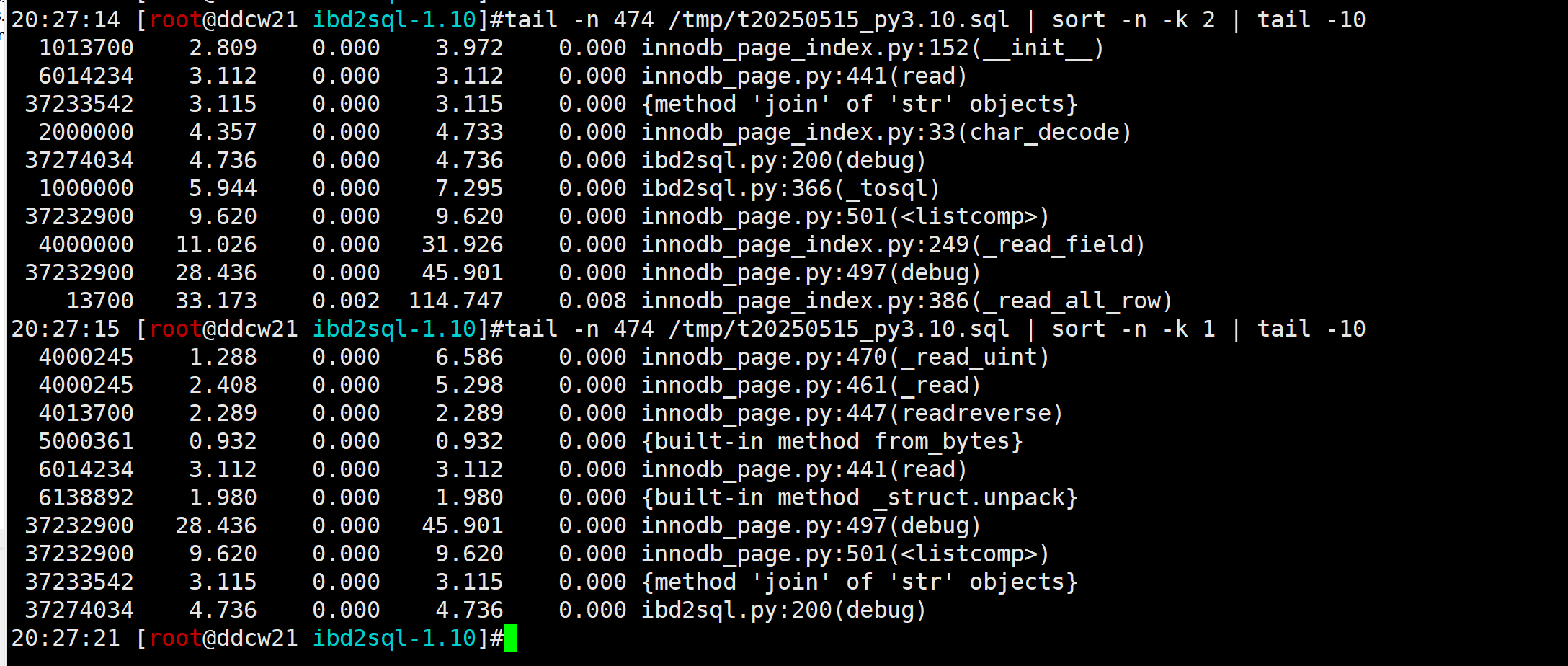
看起来最耗时的是debug… 当时为了方便调试加的debug功能现在却成了性能瓶颈.
我们还可以使用flameprof来生成火焰图, 这样看起来更直观一些
pip3 install flameprof python3 -m cProfile -o /tmp/t20250515_py3.10.prof main.py /data/mysql_3314/mysqldata/db2/sbtest1.ibd --sql > /tmp/t20250515_py3.10.sql flameprof /tmp/t20250515_py3.10.prof> /tmp/t20250515_py3.10.svg


看起来debug占比比较多, 其它的也不少, 我们先去掉debug试下吧. 根据火焰图的提示, 主要是ibd2sql/innodb_page.py的497行的哪个函数, 我们将其去掉(直接改为pass)
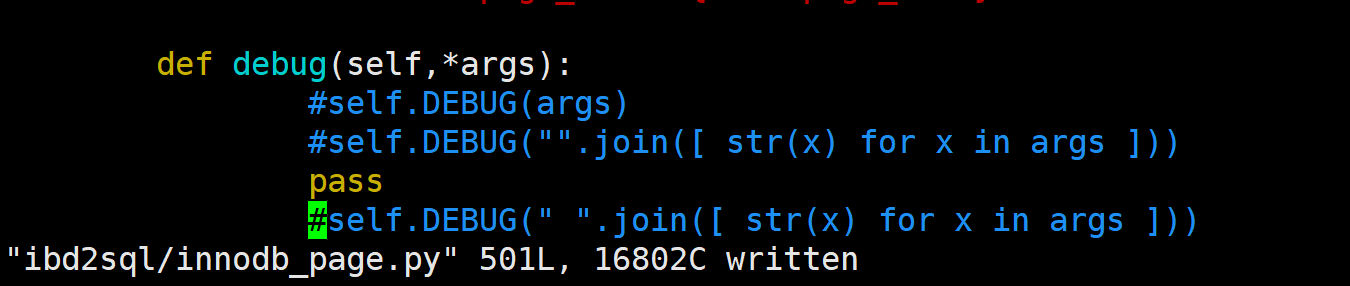
然后再来测试下速度,看如何

耗时46秒,
相比python3.6含debug提升了2倍,
相比python3.10含debug提升了1.4倍
也就是去掉DEBUG还能提升1.4倍. 进步可谓是非常之大.
优化3(移除无关功能)
但是呢, 火焰图上面还有很多占资源的啊, 能否再去掉一部分呢? 能是能, 只是比较麻烦, 基本上得重写了-_-
那就重写个定制版的测试下速度吧. 我们就不再需要解析元数据信息了, 就当作已经知道元数据信息了. 简化代码之后如下:
#!/usr/bin/env python3
import struct
import os
import sys
filename = sys.argv[1]
FIRST_LEAF_PAGE = 5
GLOBAL_PAGE_ID = FIRST_LEAF_PAGE
f = open(filename,'rb')
f2 = open('/tmp/t20250515_02.sql','w')
F_FIL_HEADER = struct.Struct('>4LQHQL')
F_PAGE_HEADER = struct.Struct('>9HQHQ2LH2LH')
F_REC_HEADER = struct.Struct('>HBh')
F_UINT4 = struct.Struct('>L')
SQL_PREFIX = "INSERT INTO sbtest1 values("
SQL_END = ");\n"
while True:
f.seek(FIRST_LEAF_PAGE*16384,0)
data = f.read(16384)
if data == b'':
break
FIL_PAGE_SPACE_OR_CHECKSUM,FIL_PAGE_OFFSET,FIL_PAGE_PREV,FIL_PAGE_NEXT,FIL_PAGE_LSN,FIL_PAGE_TYPE,FIL_PAGE_FILE_FLUSH_LSN,FIL_PAGE_SPACE_ID = F_FIL_HEADER.unpack(data[:38])
FIRST_LEAF_PAGE = FIL_PAGE_NEXT
PAGE_HEADER = F_PAGE_HEADER.unpack(data[38:94])
offset = 99
x1,x2,next_offset = F_REC_HEADER.unpack(data[offset-5:offset])
next_offset += 99
for x in range(PAGE_HEADER[8]):
offset = next_offset
x1,x2,tnext_offset = F_REC_HEADER.unpack(data[offset-5:offset])
next_offset += tnext_offset
c1 = F_UINT4.unpack(data[offset:offset+4])[0]-2147483648
c2 = F_UINT4.unpack(data[offset+17:offset+21])[0]-2147483648
s2,s1 = struct.unpack('>BB',data[offset-5-2:offset-5])
c3 = data[offset+21:offset+21+s1].decode()
c4 = data[offset+21+s1:offset+21+s1+s2].decode()
f2.write(SQL_PREFIX+",".join([repr(y) for y in [c1,c2,c3,c4] ])+SQL_END)
f.close()
f2.close()
虽然也就40行代码, 但效率还是很高的. 我们直接开测.
time python3 mini_ibd2sql_for_sbtest1.py /data/mysql_3314/mysqldata/db2/sbtest1.ibd
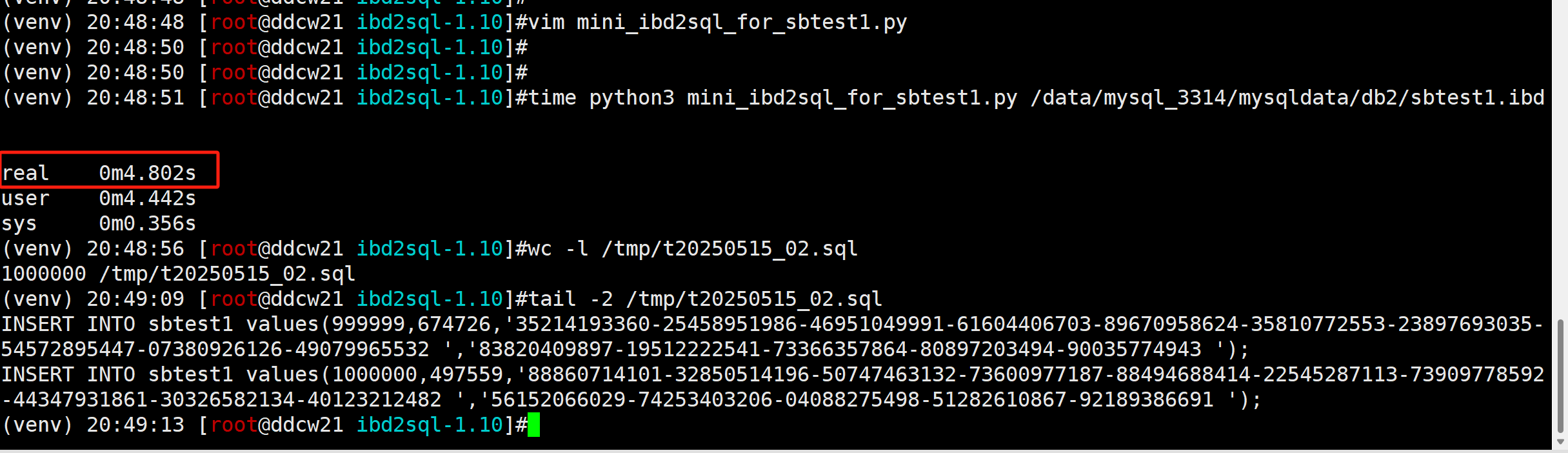
WC, 不到5秒. 这速度一下子提升了20倍!!!
也就是我们后续版本也可以使用py生成这种简洁的代码(虚拟机?字节码?)去执行, 这样速度嘎嘎快.
优化4(加并发)
但是呢, 还是不满足, 因为我TOP的时候看到CPU还是100%
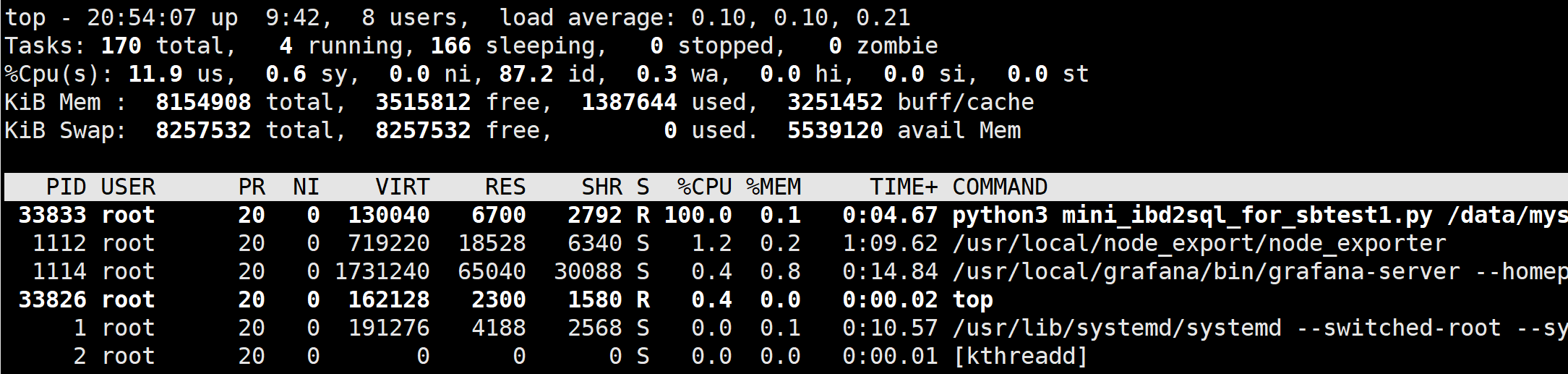
这不就表示IO还比较充足, 1个CPU忙不过来.
既然1个CPU忙不过来, 那就整个并发, 多来几个CPU吧. 于是我们稍微修改了下代码, 加上了并发功能. 如下:
#!/usr/bin/env python3
import struct
import os
import sys
from multiprocessing import Process,Lock,Value
filename = sys.argv[1]
FIRST_LEAF_PAGE = 5
PAGE_NO = Value('I',FIRST_LEAF_PAGE)
F_FIL_HEADER = struct.Struct('>4LQHQL')
F_PAGE_HEADER = struct.Struct('>9HQHQ2LH2LH')
F_REC_HEADER = struct.Struct('>HBh')
F_UINT4 = struct.Struct('>L')
F_BB = struct.Struct('>BB')
SQL_PREFIX = "INSERT INTO sbtest1 values("
SQL_END = ");\n"
def work(l,PGNO,p):
f = open(filename,'rb')
f2 = open(f'/tmp/t20250515_02.sql_{p}','w')
while True:
l.acquire()
f.seek(PGNO.value*16384,0)
data = f.read(16384)
if data == b'':
PGNO.value = -1
l.release()
break
FIL_PAGE_SPACE_OR_CHECKSUM,FIL_PAGE_OFFSET,FIL_PAGE_PREV,FIL_PAGE_NEXT,FIL_PAGE_LSN,FIL_PAGE_TYPE,FIL_PAGE_FILE_FLUSH_LSN,FIL_PAGE_SPACE_ID = F_FIL_HEADER.unpack(data[:38])
PGNO.value = FIL_PAGE_NEXT
l.release()
PAGE_HEADER = F_PAGE_HEADER.unpack(data[38:94])
offset = 99
x1,x2,next_offset = F_REC_HEADER.unpack(data[offset-5:offset])
next_offset += 99
for x in range(PAGE_HEADER[8]):
offset = next_offset
x1,x2,tnext_offset = F_REC_HEADER.unpack(data[offset-5:offset])
next_offset += tnext_offset
c1 = F_UINT4.unpack(data[offset:offset+4])[0]-2147483648
c2 = F_UINT4.unpack(data[offset+17:offset+21])[0]-2147483648
s2,s1 = struct.unpack('>BB',data[offset-5-2:offset-5])
c3 = data[offset+21:offset+21+s1].decode()
c4 = data[offset+21+s1:offset+21+s1+s2].decode()
f2.write(SQL_PREFIX+",".join([repr(y) for y in [c1,c2,c3,c4] ])+SQL_END)
f.close()
f2.close()
PP = {}
lock = Lock()
for x in range(4):
PP[x] = Process(target=work,args=(lock,PAGE_NO,x))
for x in range(4):
PP[x].start()
for x in range(4):
PP[x].join()
然后我们再次测试:
time python3 mini_ibd2sql_for_sbtest1_parallel.py /data/mysql_3314/mysqldata/db2/sbtest1.ibd
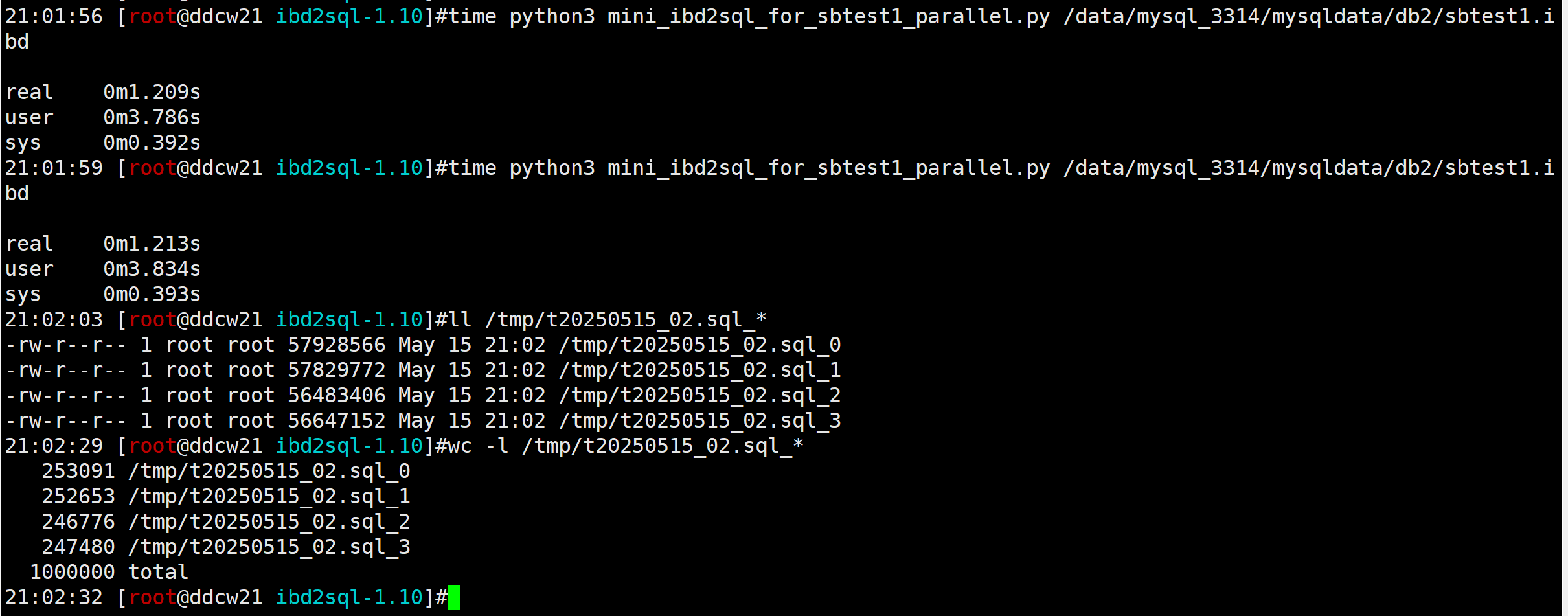
耗时1.2秒. 提升了83倍. 就问还TM有谁

总结
虽然我们理论上已经做到了83倍的速度提升, 但实际解析的时候还有很多情况要考虑, 所以保守估计100W,200MB数据需要耗时10秒. 实际能提升多少, 还得等我写完了来-_-
当然如果使用C之类的话, 速度应该还能提升. 但太复杂了(不要太贪心哦)
汇总测试结果如下: 数据行数:100W 数据文件大小:244MB
| 对象 | 执行时间(秒) |
|---|---|
| python3.6 + ibd2sql v1.10 | 100 |
| python3.10 + ibd2sql v1.10 | 65 |
| python3.10 + ibd2sql v1.10去掉DEBUG | 46 |
| python3.10 + ibdsql定制化 | 4.8 |
| python3.10 + ibdsql定制化+4并发 | 1.2 |
| python3.10 + ibdsql定制化+8并发 | 0.7 |
注: 上述代码是针对sbtest表做的优化, 不具备通用性!
