




TiDB sqlparser源码阅读(一)
文件树结构
parser
ast
ast.go
ddl.go
dml.go
expression.go
flag.go
functions.go
misc.go
stats.go
auth
charset
format
goyacc
model
ddl.go
flags.go
model.go
mysql
opcode
terror
types
lexer.go
misc.go
parser.go
parser.y
yy_parser.go
模块说明
主要说明相关的ast和model部分的代码用途,并介绍主要的相关接口和类,相关的yacc部分和整体sql层整体框架可以参考TiDB 源码阅读系列文章(五)TiDB SQL Parser 的实现
parser.ast
抽象语法树(Abstract Syntax Tree,AST),或简称语法树(Syntax tree),是源代码语法结构的一种抽象表示。它以树状的形式表现编程语言的语法结构,树上的每个节点都表示源代码中的一种结构。
这部分是主要的语法解析部分,mysql sql语句主要包括以下几种:
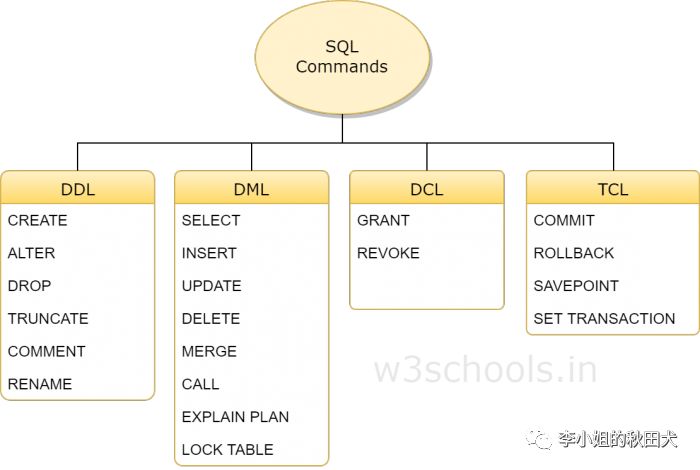
tidb主要的语法解析为ddl和dml
ddl
资料定义语言(Data Definition Language,DDL)是SQL语言集中负责资料结构定义与资料库物件定义的语言,由CREATE、ALTER与DROP三个语法所组成,最早是由Codasyl(Conference on Data Systems Languages)资料模型开始,现在被纳入SQL指令中作为其中一个子集。
dml
数据操纵语言(Data Manipulation Language, DML)是用于资料库操作,对资料库其中的物件和资料执行存取工作的编程语句,通常是资料库专用编程语言之中的一个子集,例如在资讯软体产业通行标准的SQL语言中,以INSERT、UPDATE、DELETE三种指令为核心,分别代表插入(意指新增或创建)、更新(修改)与删除(销毁)。在使用资料库的系统开发过程中,其中应用程式必然会使用的指令;而加上 SQL的SELECT语句,欧美地区的开发人员把这四种指令,以“CRUD”(分别为 Create, Read, Update, Delete英文四字首字母缩略的术语)来称呼;而亚洲地区使用汉语的开发人员,或可能以四个汉字:增 查 改 删 来略称。
主要接口
Node: ast中的一个抽象节点
// Node is the basic element of the AST.
// Interfaces embed Node should have 'Node' name suffix.
type Node interface {
// Restore returns the sql text from ast tree
Restore(ctx *RestoreCtx) error
// Accept accepts Visitor to visit itself.
// The returned node should replace original node.
// ok returns false to stop visiting.
//
// Implementation of this method should first call visitor.Enter,
// assign the returned node to its method receiver, if skipChildren returns true,
// children should be skipped. Otherwise, call its children in particular order that
// later elements depends on former elements. Finally, return visitor.Leave.
Accept(v Visitor) (node Node, ok bool)
// Text returns the original text of the element.
Text() string
// SetText sets original text to the Node.
SetText(text string)
}
StmtNode: ast中的语句节点(包括完整的语句和子语句),实现了Node接口
// StmtNode represents statement node.
// Name of implementations should have 'Stmt' suffix.
type StmtNode interface {
Node
statement()
}
DDLNode: ast中的ddl节点,实现了Stmt接口
// DDLNode represents DDL statement node.
type DDLNode interface {
StmtNode
ddlStatement()
}
DMLNode: ast中的dml节点,实现了Stmt接口
// DMLNode represents DML statement node.
type DMLNode interface {
StmtNode
dmlStatement()
}
parser.ast.ddl
ddl主要处理包括与数据库、表结构约束schema相关的sql的处理 其中主要包括的是alter,create database,create index,drop,rename,truncate等相关的操作 其处理的相关语句根据ddl.go开始的声明可以看出
var (
_ DDLNode = &AlterTableStmt{}
_ DDLNode = &CreateDatabaseStmt{}
_ DDLNode = &CreateIndexStmt{}
_ DDLNode = &CreateTableStmt{}
_ DDLNode = &CreateViewStmt{}
_ DDLNode = &DropDatabaseStmt{}
_ DDLNode = &DropIndexStmt{}
_ DDLNode = &DropTableStmt{}
_ DDLNode = &RenameTableStmt{}
_ DDLNode = &TruncateTableStmt{}
_ Node = &AlterTableSpec{}
_ Node = &ColumnDef{}
_ Node = &ColumnOption{}
_ Node = &ColumnPosition{}
_ Node = &Constraint{}
_ Node = &IndexColName{}
_ Node = &ReferenceDef{}
)
该文件主要包含相关的Stmt处理和相应的各类Option
parser.ast.dml
dml主要处理CRUD相关的操作,包括delete,insert,union,update,select,show,以及相关的group by,join,limit,order by等操作 相关操作亦可从dml.go开头的声明处窥见
var (
_ DMLNode = &DeleteStmt{}
_ DMLNode = &InsertStmt{}
_ DMLNode = &UnionStmt{}
_ DMLNode = &UpdateStmt{}
_ DMLNode = &SelectStmt{}
_ DMLNode = &ShowStmt{}
_ DMLNode = &LoadDataStmt{}
_ DMLNode = &SplitRegionStmt{}
_ Node = &Assignment{}
_ Node = &ByItem{}
_ Node = &FieldList{}
_ Node = &GroupByClause{}
_ Node = &HavingClause{}
_ Node = &Join{}
_ Node = &Limit{}
_ Node = &OnCondition{}
_ Node = &OrderByClause{}
_ Node = &SelectField{}
_ Node = &TableName{}
_ Node = &TableRefsClause{}
_ Node = &TableSource{}
_ Node = &UnionSelectList{}
_ Node = &WildCardField{}
_ Node = &WindowSpec{}
_ Node = &PartitionByClause{}
_ Node = &FrameClause{}
_ Node = &FrameBound{}
)
dml中的部分主要类举例
SelectStmt: select语句相关处理类,实现了DMLNode
// SelectStmt represents the select query node.
// See https://dev.mysql.com/doc/refman/5.7/en/select.html
type SelectStmt struct {
dmlNode
resultSetNode
// SelectStmtOpts wraps around select hints and switches.
*SelectStmtOpts
// Distinct represents whether the select has distinct option.
Distinct bool
// From is the from clause of the query.
From *TableRefsClause
// Where is the where clause in select statement.
Where ExprNode
// Fields is the select expression list.
Fields *FieldList
// GroupBy is the group by expression list.
GroupBy *GroupByClause
// Having is the having condition.
Having *HavingClause
// WindowSpecs is the window specification list.
WindowSpecs []WindowSpec
// OrderBy is the ordering expression list.
OrderBy *OrderByClause
// Limit is the limit clause.
Limit *Limit
// LockTp is the lock type
LockTp SelectLockType
// TableHints represents the table level Optimizer Hint for join type
TableHints []*TableOptimizerHint
// IsAfterUnionDistinct indicates whether it's a stmt after "union distinct".
IsAfterUnionDistinct bool
// IsInBraces indicates whether it's a stmt in brace.
IsInBraces bool
}
UpdateStmt: update相关语句,实现了DMLNode
// UpdateStmt is a statement to update columns of existing rows in tables with new values.
// See https://dev.mysql.com/doc/refman/5.7/en/update.html
type UpdateStmt struct {
dmlNode
TableRefs *TableRefsClause
List []*Assignment
Where ExprNode
Order *OrderByClause
Limit *Limit
Priority mysql.PriorityEnum
IgnoreErr bool
MultipleTable bool
TableHints []*TableOptimizerHint
}
parse.model
model模块主要是相关的sql对应的数据结构定义和Job操作任务结构的定义
parse.model.model.go
model.go中主要包含相关schema的元信息描述结构,例如库信息DbInfo,表信息TableInfo,列信息ColumnInfo,视图信息ViewInfo,表锁信息LockInfo等。具体结构举例如下:
库信息DbInfo
// DBInfo provides meta data describing a DB.
type DBInfo struct {
ID int64 `json:"id"` // Database ID
Name CIStr `json:"db_name"` // DB name.
Charset string `json:"charset"`
Collate string `json:"collate"`
Tables []*TableInfo `json:"-"` // Tables in the DB.
State SchemaState `json:"state"`
}
表信息TableInfo
// TableInfo provides meta data describing a DB table.
type TableInfo struct {
ID int64 `json:"id"`
Name CIStr `json:"name"`
Charset string `json:"charset"`
Collate string `json:"collate"`
// Columns are listed in the order in which they appear in the schema.
Columns []*ColumnInfo `json:"cols"`
Indices []*IndexInfo `json:"index_info"`
ForeignKeys []*FKInfo `json:"fk_info"`
State SchemaState `json:"state"`
PKIsHandle bool `json:"pk_is_handle"`
Comment string `json:"comment"`
AutoIncID int64 `json:"auto_inc_id"`
MaxColumnID int64 `json:"max_col_id"`
MaxIndexID int64 `json:"max_idx_id"`
// UpdateTS is used to record the timestamp of updating the table's schema information.
// These changing schema operations don't include 'truncate table' and 'rename table'.
UpdateTS uint64 `json:"update_timestamp"`
// OldSchemaID :
// Because auto increment ID has schemaID as prefix,
// We need to save original schemaID to keep autoID unchanged
// while renaming a table from one database to another.
// TODO: Remove it.
// Now it only uses for compatibility with the old version that already uses this field.
OldSchemaID int64 `json:"old_schema_id,omitempty"`
// ShardRowIDBits specify if the implicit row ID is sharded.
ShardRowIDBits uint64
// MaxShardRowIDBits uses to record the max ShardRowIDBits be used so far.
MaxShardRowIDBits uint64 `json:"max_shard_row_id_bits"`
// PreSplitRegions specify the pre-split region when create table.
// The pre-split region num is 2^(PreSplitRegions-1).
// And the PreSplitRegions should less than or equal to ShardRowIDBits.
PreSplitRegions uint64 `json:"pre_split_regions"`
Partition *PartitionInfo `json:"partition"`
Compression string `json:"compression"`
View *ViewInfo `json:"view"`
// Lock represent the table lock info.
Lock *TableLockInfo `json:"Lock"`
// Version means the version of the table info.
Version uint16 `json:"version"`
}
parser.model.ddl.go
ddl.go中主要包含了相关ddl语句所形成的逻辑job结构,这是从ddlsql形成第一步的job产生的逻辑操作集合,是sql和存储native api之间的连接桥梁。
由sql形成job序列,再经由逻辑优化和代价优化后会形成最后的job集合,按照job序列依次调用存储模块的接口并使用算子进行计算。其主要任务结构Job定义如下:
// Job is for a DDL operation.
type Job struct {
ID int64 `json:"id"`
Type ActionType `json:"type"`
SchemaID int64 `json:"schema_id"`
TableID int64 `json:"table_id"`
State JobState `json:"state"`
Error *terror.Error `json:"err"`
// ErrorCount will be increased, every time we meet an error when running job.
ErrorCount int64 `json:"err_count"`
// RowCount means the number of rows that are processed.
RowCount int64 `json:"row_count"`
Mu sync.Mutex `json:"-"`
Args []interface{} `json:"-"`
// RawArgs : We must use json raw message to delay parsing special args.
RawArgs json.RawMessage `json:"raw_args"`
SchemaState SchemaState `json:"schema_state"`
// SnapshotVer means snapshot version for this job.
SnapshotVer uint64 `json:"snapshot_ver"`
// StartTS uses timestamp allocated by TSO.
// Now it's the TS when we put the job to TiKV queue.
StartTS uint64 `json:"start_ts"`
// DependencyID is the job's ID that the current job depends on.
DependencyID int64 `json:"dependency_id"`
// Query string of the ddl job.
Query string `json:"query"`
BinlogInfo *HistoryInfo `json:"binlog"`
// Version indicates the DDL job version. For old jobs, it will be 0.
Version int64 `json:"version"`
// ReorgMeta is meta info of ddl reorganization.
// This field is depreciated.
ReorgMeta *DDLReorgMeta `json:"reorg_meta"`
// Priority is only used to set the operation priority of adding indices.
Priority int `json:"priority"`
}
