





大家好,我叫朱洁,今天我演讲的题目是《大模型时代,基于数据平台实现数据AI ready》。
相信大家对大模型训练的方方面面都很感兴趣,今天我来讲一下,数据处理这一块是怎么做的,有什么挑战和解法。
在过去几年里面,我们在模型和AI 应用积累了非常多的经验。在这个过程中,我们有两个新的认识。
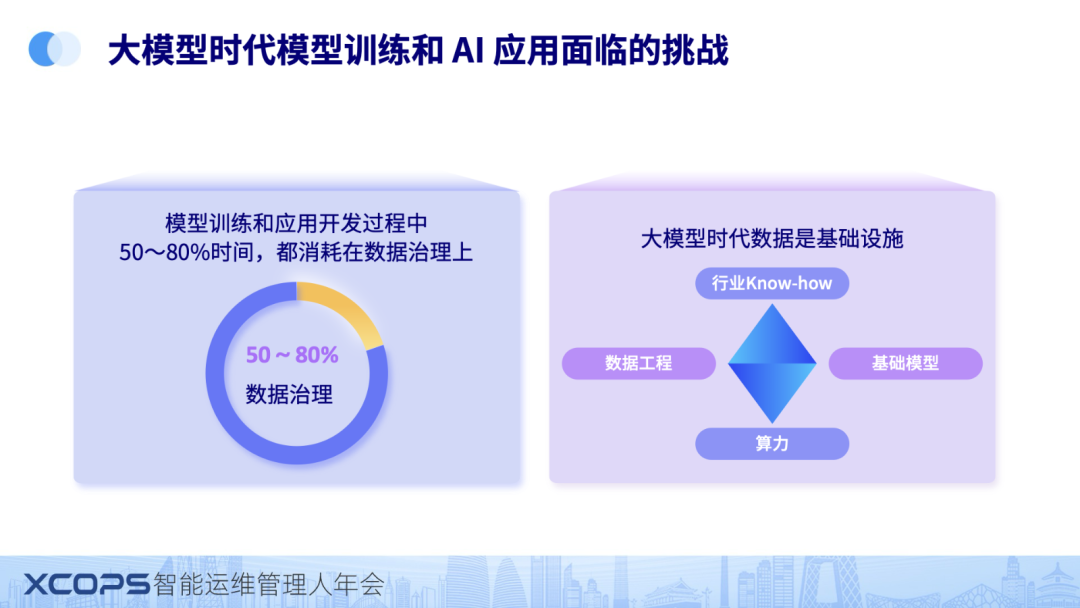
第一个:我们发现,不管是模型训练和应用开发的过程中,我们的工程师,50%~80% 的时间都消耗在数据治理上。这个和以往开发范式完全不相同。我们知道一个事情超过50%比例就相当高,可以说就成为关键瓶颈了。那之所以这么高的原因是什么呢,相信在座的各位一定非常好奇。
第二个:我们知道,在以往 CPU 时代,基础设施是最核心的两个东西是。以CPU为核心的算力基础设施和以数据库为核心的数据基础设施。在大模型时代,基础设施也发生非常大的变迁。今天大模型时代的基础设施,除了算力之外,从 CPU 变迁到 GPU。新增了模型基础,数据也从数据库变化为数据工程。
从这两个认识出发,不管是模型和应用开发诉求,还是基础设施视角,数据以及数据平台都变得异常重要。
接下来我分别讲下几个问题
1、为什么数据治理难,为什么消耗占比超过 50%。
2、以及什么是数据工程。
3、数据工程和数据平台是什么关系,以及为数据平台能解决哪些问题。
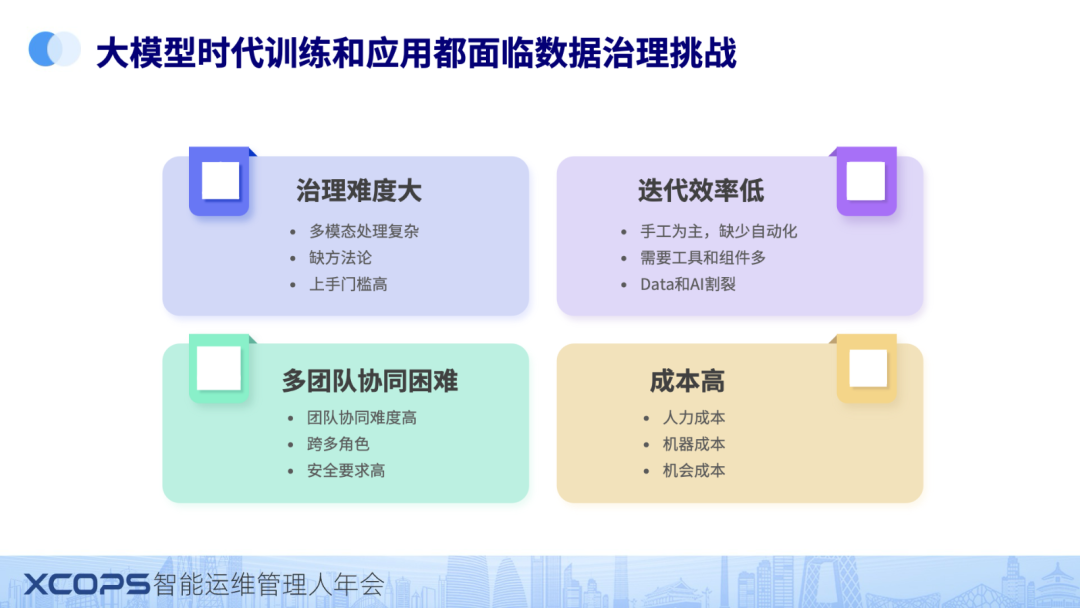
我们刚才提到了,大概有50%-80%的时间花在数据治理上。原因是什么呢?总结下来主要有以下四个大的原因。
1、首先是治理难度很大。这个难度体现在多方面,最主要的几个原因是数据从结构化变成了多模态,多模态的处理复杂度指数级增长,需要用到很多处理技术,技术栈也复杂,还涉及到开发的工作量,上手门槛很高。而且整个业界没有一个成熟的方法论,也不如结构化数据有成熟的团队。所以治理难度是非常大的。
2、其次是迭代效率低。模型训练和应用都需要不停的试错和迭代,但是当前数据处理需要用到大量的工具和组件,另外数据处理组件,又需要和模型管理平台进行协同,而这个过程是基本上是手工为主,缺少自动化,导致这个效率就非常低。
3、跨团队协同难。当前模型训练和AI应用都需要数据团队,AI团队,业务团队多个团队协同才能完成一个复杂的模型训练和应用。这就带来了跨角色的协同问题,在这个协同的过程中还要保证数据的安全性不出问题,人为拷贝数据分享是非常容易带来安全性问题的。跨团队,跨角色协同带来的复杂度再次加剧数据治理的难度。
4、成本高。这个相对比较容易理解。我重点强调一点,除了人力成本,算力成本是其中关键之外,更重要的是机会成本。大模型时代,谁有能力率先做好模型和应用,业务上可能就能取得先机。大模型时代的机会是非常难得的,对每个企业和个人机会也是相等的,利用好工具,善于用工具提高效率的企业和公司自然而然的站在更高的起跑线上。
我们有诸多的挑战,造成了我们现在多模态数据治理还处于农耕时代,我们急需要一个面向大模型时代的方法,把多模态数据管理带到工业时代,这就是数据工程。

我们简单来总结一下数据工程的概念。
数据工程是从数据源头,经过数据加工处理,得到高质量,一致性的数据,给下游使用,最终形成了Data+AI+APP数据闭环,实现数据到价值的交付。
数据工程并不是一个新鲜的事情。
数据工程追溯起来有超过 40 年的历史,以往主要解决的是商业智能等场景。大模型时代,我们观察到数据工程有非常大的变化。主要包含两方面
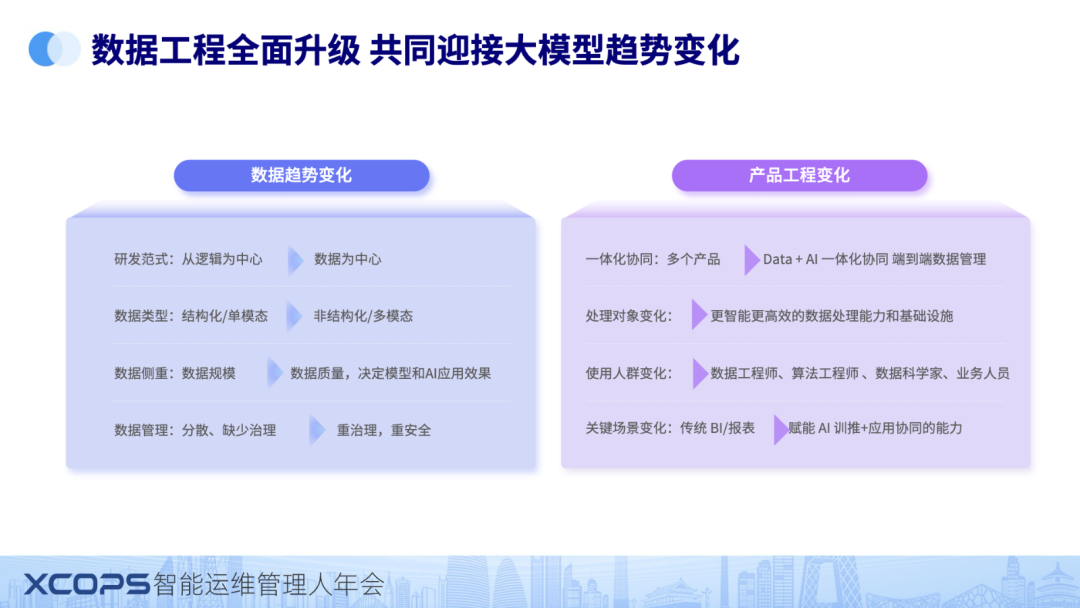
首先是从数据角度看,我们观察到四大关键变化,分别是
研发范式:从逻辑为中心到数据为中心,这个体现的数据的价值变得更重。
数据类型:结构化/单模态-》非结构化/多模态,这个体现的是大模型更强的数据处理能力以及能挖掘更多数据价值
数据侧重:数据规模->数据质量,决定模型和AI应用效果
数据管理:分散、缺少治理->重治理,重安全
上面两个体现的是更重的数据管理和数据质量的要求。
其次是从产品角度看,同样也有四个关键变化,分别是:
- 一体化协同:多个产品->Data + AI 一体化协同端到端数据管理,这个来源是客户对更易用产品的诉求。
- 处理对象变化:更智能更高效的数据处理能力和基础设施,这个主要是大模型算力从 CPU 变迁到 GPU。
- 使用人群变化:数据工程师、算法工程师 、数据科学家、业务人员。产品只有更易用,才能赋能更多的人群。
- 关键场景变化:传统 BI/报表->赋能 AI 训推+应用协同的能力。数据平台需要赋能更多的场景。
不管是从数据还是产品角度,数据工程都需要进行全面的升级,共同迎接大模型趋势变化

数据工程包括方法论和数据平台两部分。
数据工程需要把数据从源头治理到业务需要的数据,实现数据到价值的交付。承载这些最终实现是数据平台。
数据平台核心的能力是将散落到各处的数据统一管理和治理,实现数据变现,提升业务决策效率。
我们在内部模型训练和 AI 应用也碰到了前面说的各种问题。
因此我们发现需要有一个多模态数据平台解决这些问题,因此经过1年多内部打磨,我们将原来内部打磨的产品,在4月份武汉AI开发者大会进行了发布,这个平台的名字叫一站式数据智能平台 databuilder。
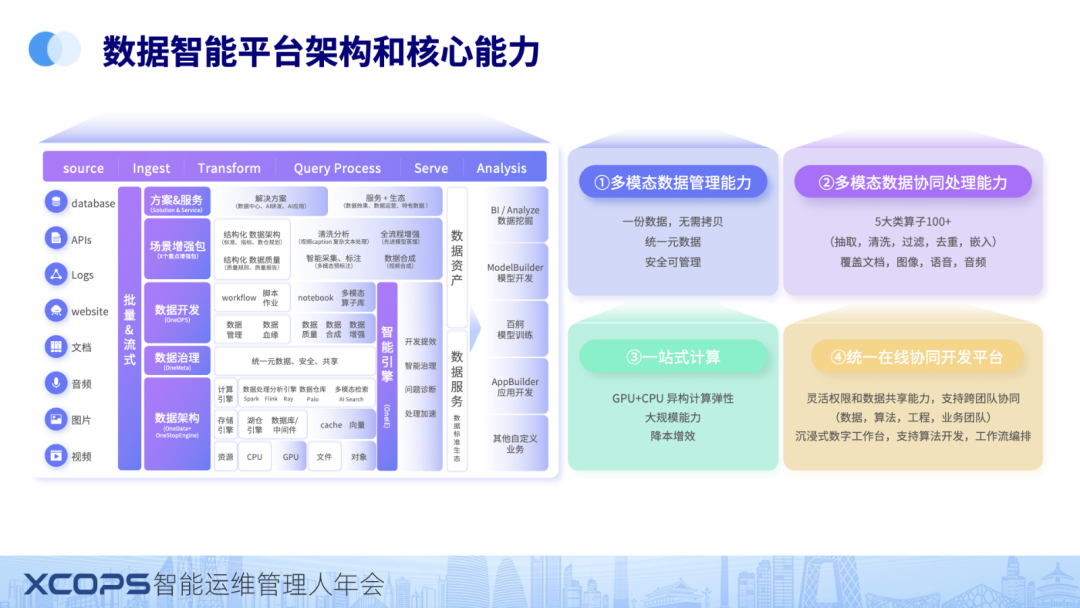
左边这个图是我们的整个架构图,整个 databuilder 是覆盖数据处理的全生命周期,是由平台+解决方案+服务的综合的一站式智能数据平台。
databuilder 为了应对当前数据治理的挑战,我们的 databuilder 有以下 4 大核心能力,分别是:
- 为了解决多模数据管理的问题,通过统一元数据的能力,数据存在统一智能湖仓平台上,实现一份数据,无需拷贝,数据使用全生命周期安全可靠。
- 多模态数据门槛高的核心原因是数据复杂,处理过程需要大量的高代码开发,通过我们平台内置的5 大类算子 100+(抽取,清洗,过滤,去重,嵌入),覆盖文档,图像,语音,音频所有模态,实现多模态数据处理全生命周期基础算子的覆盖。通过这个基础算子的覆盖,大部分场景下只需要通过少量的配置,既可以完成数据的处理。
- 大家知道,多模态数据处理需要用到很多算子,有些需要跑到 CPU,有些需要跑到 GPU 上。底层怎么支持这些算子的并发,以及异构调度,弹性的能力就变得非常关键。我们这次发布的版本默认自带弹性 AI 计算能力,通过支持 GPU+CPU 的异构计算,弹性能力很强,从很小的规模到大规模的处理都能很好的使用。在常见的场景下,相比客户自建的效率提升超过 600%。
- 虽然通过我们内置的算子,可以覆盖大部分场景,但是还是会有部分场景需要开发。一个跨平台,可以多人协同的开发平台就会非常重要,这个是托底能力。今天我们发布统一在线协同开发平台,这个在线开发平台和开发人员离线开发体验一致,符合开发人员的使用直觉。同时通过灵活权限和数据共享能力,支持数据,算法,工程,业务团队等团队进行跨团队协同,使得大规模开发变成可能,也极大的提升了数据开发效率
最后简单总结下,我们通过完善的多模态数据管理,高效的多模态数据处理,弹性的AI 计算能力以及统一在线协同开发平台等等能力,帮助我们的客户实现高效的数据治理的诉求。
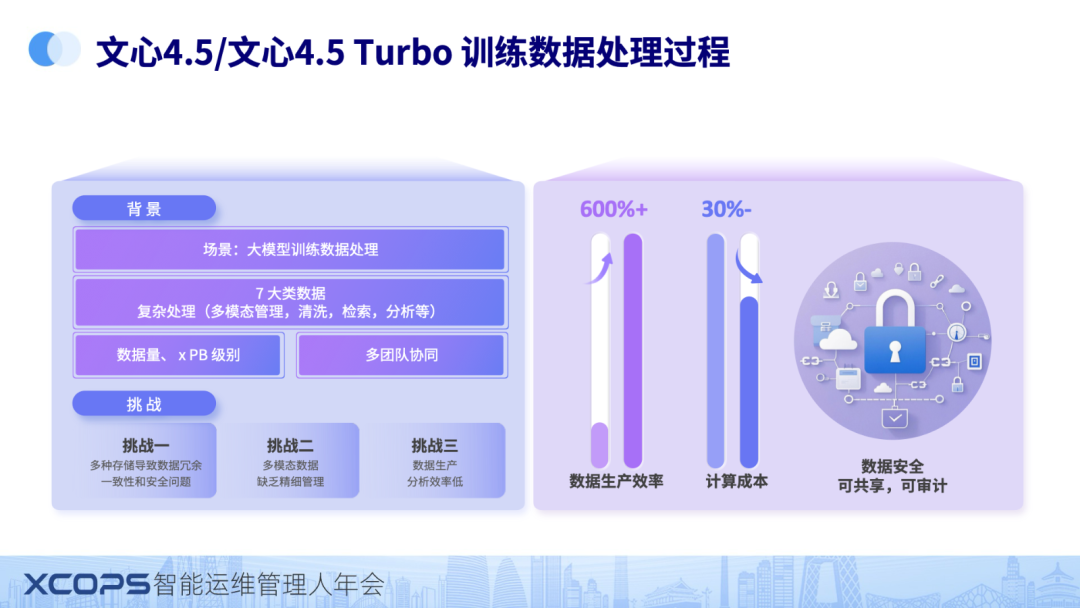
其实 databuilder 在我们内部早就成功应用起来了,这次是讲将内部的技术产品化出来。接下来讲一下我们 databuilder 一个成功的 case:DataBuilder 成功应用于文心 4.5/文心 4.5Turbo。
文心在训练大模型的时候,面临到他们的场景是复杂数据处理(多模态管理,清洗,检索,分析等),数据量在百 PB 以上,也涉及多个团队的共同协同。面临的主要困难是三大类困难,
- 挑战一,多种存储导致数据冗余,碰到一致性和安全问题
- 挑战二,多模态数据,缺乏精细管理
- 挑战三,数据生产分析效率低
通过使用databuilder 之后,整个数据生成效率提升 600%,同时计算成本下降 30%,整个训练的过程中,因为存在统一存储,良好的权限管理,数据安全,可以共享,可审计。
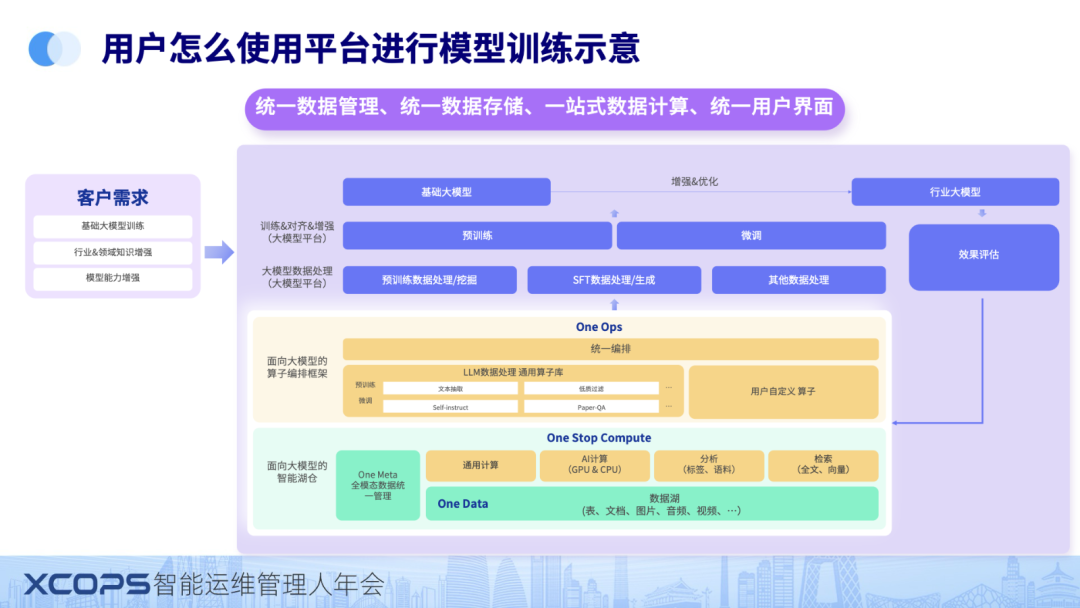
介绍几大能力之前,我先来介绍下我们和客户的分工,大家更好的理解我们这个平台的定位和价值。
这张图是我们和伙伴的分工示例,下面是平台部分,是 databuilder 来提供。上面是我们的伙伴帮助客户进行行业模型的训练。
客户或者伙伴接到需求,不管是基础大模型训练,行业&领域知识增强还是模型能力增强。可以利用我们的平台可以很快的进行二次开发,伙伴把数据放到数据智能平台里面处理,处理好的数据用于再拿到AI平台里面进行模型训练和增强,训练完成之后,模型上线。模型上线之后推理收集的数据可以再次回到平台进行进一步的加工,用于下一轮模型训练迭代。
前面我门讲到过去没有平台,这些数据处理都是需要用多个工具进行手搓。
今天通过数据智能平台,对数据进行统一管理,统一存储,一站式计算,统一用户界面。
数据平台很好的帮助用户:
1、屏蔽底层复杂的 GPU/CPU 基础设施
2、数据基础设施和大模型平台无缝打通,实现高效协同
3、符合用户直觉的开发平台,实现低门槛完成复杂数据处理工作,算法工程师就可以完成,不再需要专业的数据工程师。
通过帮助用户解决这些复杂问题,从而提升数据处理效率,提升模型端到端迭代效率。
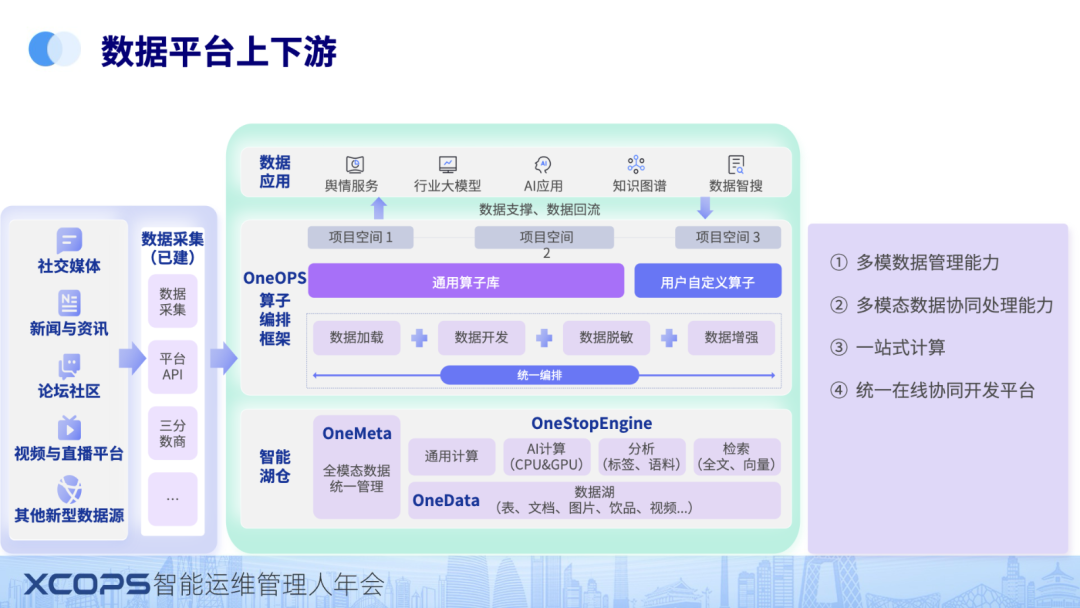
平台顺利运行,需要有一个很好的上下游,上游就是各种数据源,下游是数据应用,或者MLOPS平台等。
data builder是一个智能数据平台,解决从数据采集,到数据处理,到最后数据应用到全数据生命周期的所有诉求。
为了能做到这个生命周期的处理,以及解决多模态数据治理的4大挑战。我们核心通过三个关模块,分别是one Meta,one stop engine,one OPS,来提供4个能力
1、多模态的数据管理能力。
2、多模态数据协同处理能力
3、一站式计算:计算层面的优化,GPU+CPU混合调度,降本增效
4、在线开发平台:符合用户直觉的在线开发平台-
我后面会展开来讲这几大能力是怎么实现的,以及内部的一些关键技术。
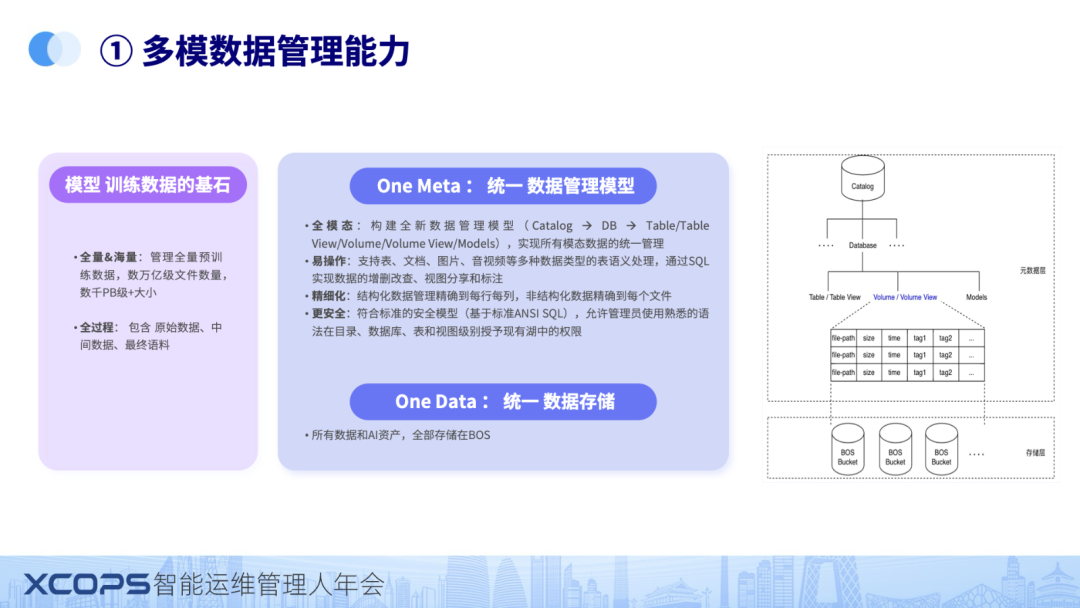
我们先来看data builder四大关键能力的第一个:多模态数据管理是怎么做的
基础模型训练的时候会用到大量的数据,这些数据怎么精细化管理是个难题。
我们用统一元数据进行管理,对数据进行了三层抽象,数据目录,数据库/数据模式,表/卷。
除了数据,还有各种模型,算子这些资产也统一管理起来。
通过这种管理,结构化数据管到行,列。非结构化数据管到目录,文件层级。
不管结构化数据还是非结构化数据都有也都有版本管理。
有了这么一套管理之后,数据的权限,数据的版本,数据的上下游就有了统一的管理。再和用户,资源对应起来,就实现了数据的分享,计算处理和安全管控等等能力。
另外我们用到存算分离架构,所有的数据和AI资产,也全部存储在对象存储上统一存储,只需要一份数据,不需要冗余,节约了资源。
同时数据分享变得非常容易,只需要更改元数据注册信息,而不需要挪动数据。
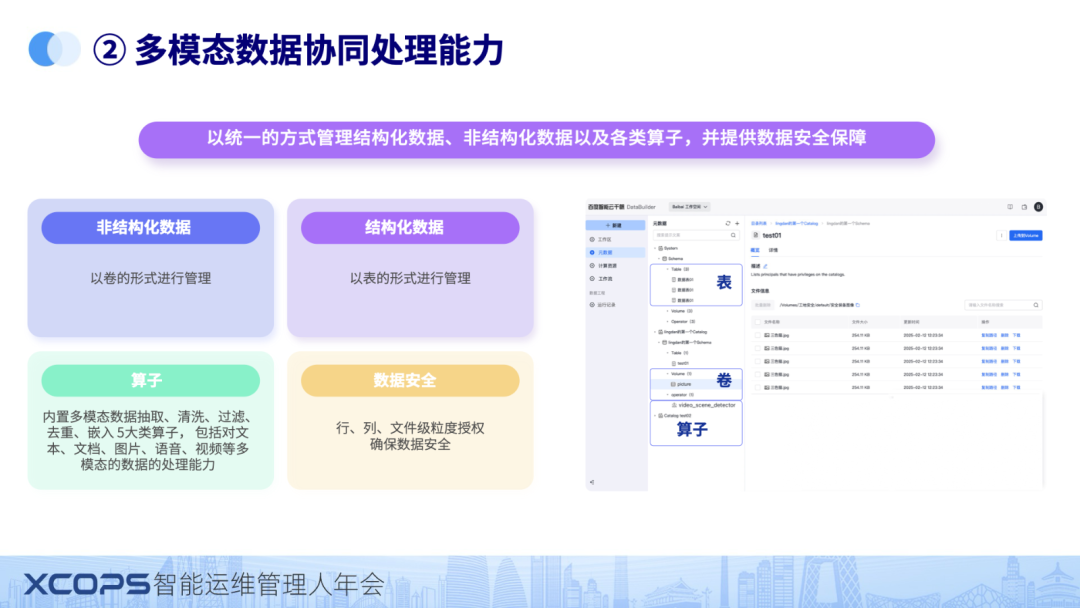
通过元数据实现了数据和资源的统一管理之后,马上就会遇到第二个问题:多团队协作数据处理问题。
- 一需要有协作能力
- 多团队协作的核心是数据,人,资源包括计算资源和存储资源的三者之间灵活管理和分享。
- 右边这张图是我们的产品截图。
- 前面讲到元数据将数据,算子等资产管理起来。另外大家可以在这个图上看到有一个叫“工作区”。工作区是我们产品上定义的一个概念,一个工作区是指一群用户,为了一个业务目标,一起共同工作,对一批数据进行操作和管理的一个虚拟空间。
- 系统管理员在空间里面创建需要的资源,以及定义可以操作空间的用户。在通过元数据管理的能力灵活的将需要处理的数据授权给对应的空间。这样就实现了资源,用户,数据三者在一个虚拟的空间里面一起工作。
- 如果一批数据,需要分享给另外一群人,或者实现另外的业务目标;就把这批数据绑定到另外的空间,就实现了这个能力。
- 所以通过这种虚拟的空间,灵活的元数据管理,就非常容易实现跨组织协同的能力。
- 二需要很好的处理能力
- 有了很好的管理之外,需要大量的处理算子,我们提供了5大类算子,基本覆盖了文本,文档,图片,语音,视频多模态的数据处理。
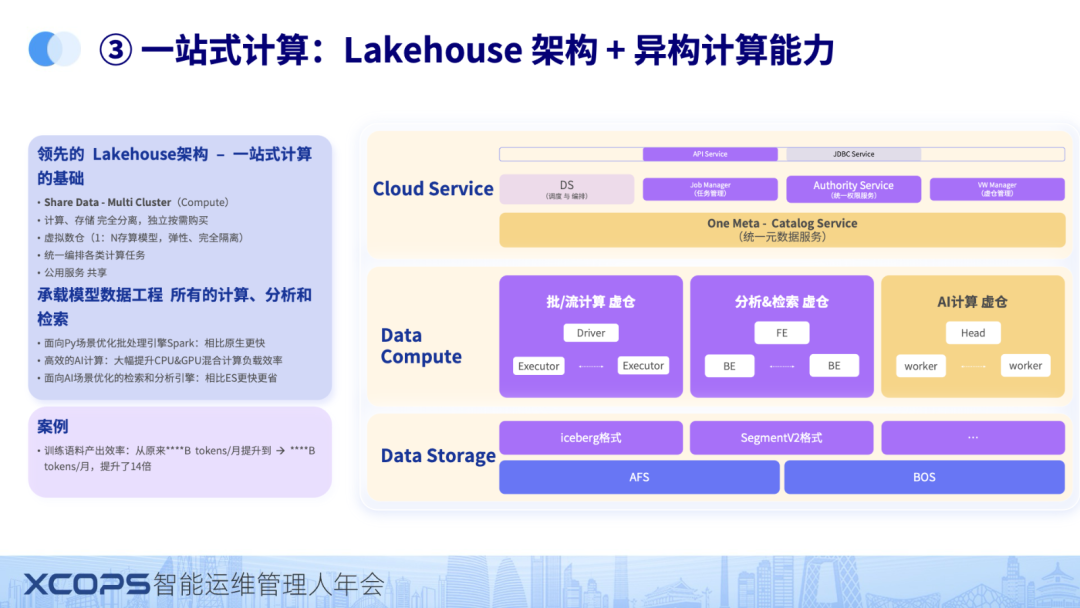
承载数据处理的是一站式计算的能力,这里最重要的一个工作是,以及怎么做到帮助客户节省成本。
不管模型训练还是AI应用都需要处理大量的数据,以及需要用到大量的算力。
整个平台分三层。上面是开发平台,包括统一元数据,调度等等。前面都讲过了。
下面两层是一站式计算和存储,存储是构建在对象存储上湖仓格式或者数仓的格式。
整个一站式引擎,提供多种功能能力,包括批流能力,分析数仓能力。这个对外提供统一的SQL能力,另外是CPU&GPU混合计算负载。
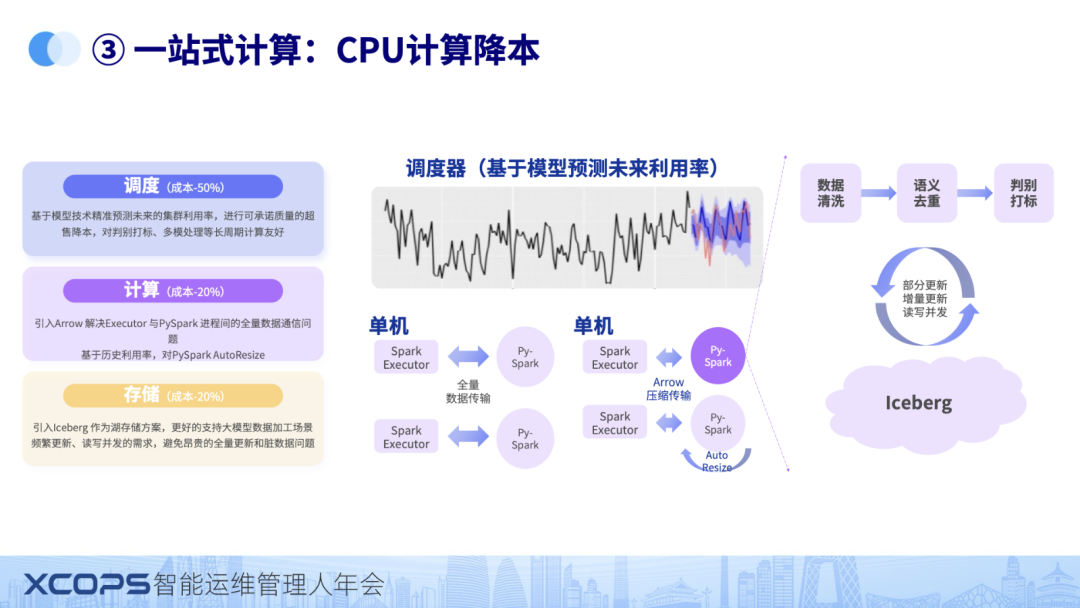
计算引擎这块做了不少的优化。
CPU计算我们主要用的是spark框架。算法同学一般只会写python,所以专门优化了PYSPARK。主要有三大块
1)调度上,用模型对集群利用率进行了预测,资源空闲自动调度任务,自动超售
2)计算上,引入 arrow,降低节点传输数据量。
3)存储,引入 iceberg,解决数据更新,读写并发的诉求。
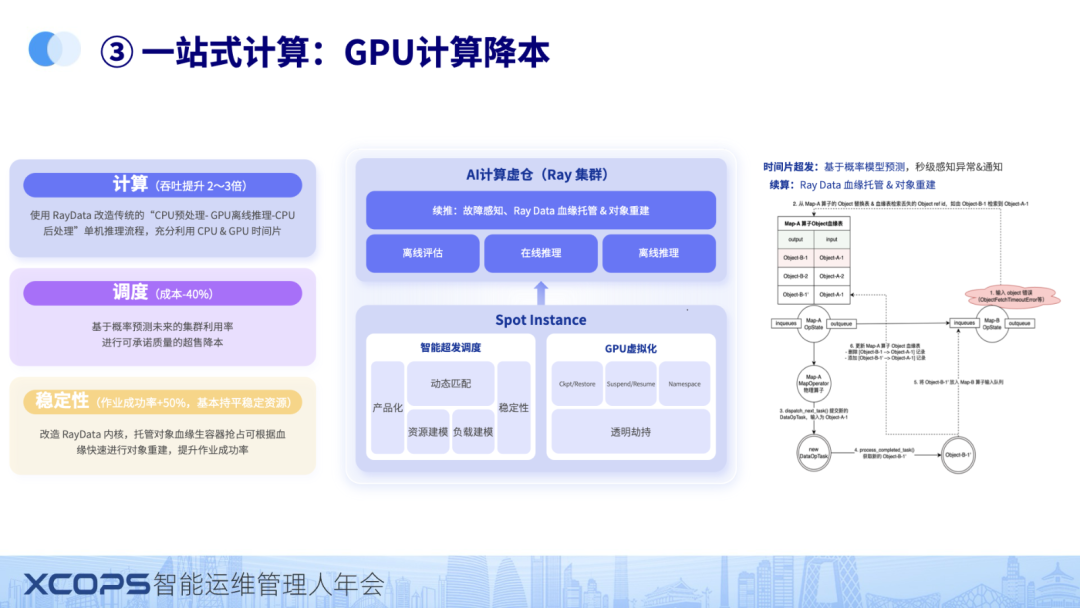
GPU 调度用的是 Ray 框架,Ray 比较好的调度机器学习的任务,先比传统的 k8s 吞吐直接提升了 2~3 倍。但是原生的 RAY 有很多问题,我们做了系列的优化。
主要是通过预测调度,降低了成本。另外RAYData 的对象重建,任务续推,提升RAY 的稳定性。
整个优化下来,离线吞吐提升 2~3 倍,成本降低 40%。
通过对 CPU 和 GPU 的算力的优化,实现GPU+CPU混合调度,并且相比用户自己的实现实现了成本,稳定性等大幅提升。

最后一个问题,我们在设计这个平台到时候就在想,大模型或者应用的数据处理到底是简单的还是复杂的的一个事情,应该是低代码还是高代码态的。经过内部外的调研,包括业界的一些先进的平台,最后我们决定这个平台应该是一个高代码态的。
虽然我们会内置大量的算子,模板,降低用户开发难度, 但是整个平台最终托底的应该还是高代码态的。高代码态的,肯定还是要符合开发者的开发习惯。
因此我们在设计这个开发平台的时候,就定了一个目标是符合用户直觉的在线开发平台。
所以我们为这个开发平台,设计了文件系统,回收站,和用户的 Mac 上开发环境基本一致,让用户可以无缝的迁移到在线开发平台。
另外我们这个开发平台有两个核心能力。
第一个就是实现了 Data+AI 的无缝打通。
数据平台把数据准备好,和 AI 平台底层打通,另外通过完整的血缘的能力,具备上下游回溯的能力。
这个不管是对结构化和非结构化的数据治理都是非常有效果的。
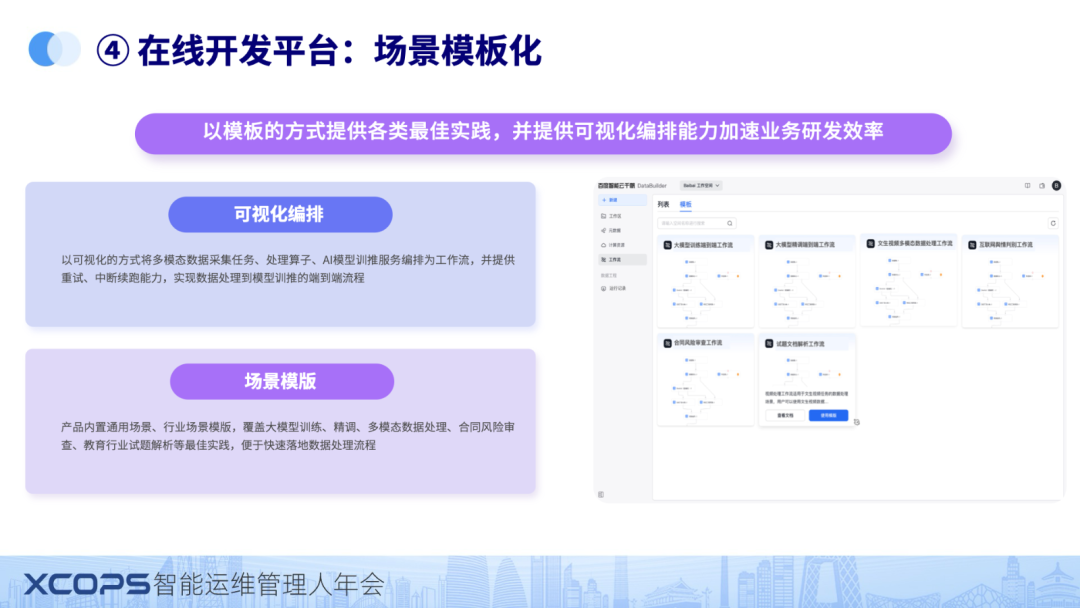
第二个核心的能力是提供了可视化的,编排,实现从数据采集,处理到 AI 训推的编排能力。
并且为了降低用户使用的门槛,内置了多种场景模板。
如果内置的模板符合用户的场景,那就可以直接复用,场景接近的可以经过少量的修改,大幅降低了用户开发的工作量,以及使用难度。
前面就是我们这次发布 databuilder 四大关键能力,简单回顾下。
1、多模态的数据管理能力,实现数据和各种资产的统一管理,版本管理,安全管理等等
2、多模态数据协同处理能力。通过虚拟空间实现底层资源,数据,和用户三者的灵活管理。
3、一站式计算,GPU+CPU混合调度效率,机器学习的算法预测空闲时间,从而整体降本增效。
4、符合用户直觉的在线开发平台,实现训推一体,内置算子和模板,减低使用门槛。
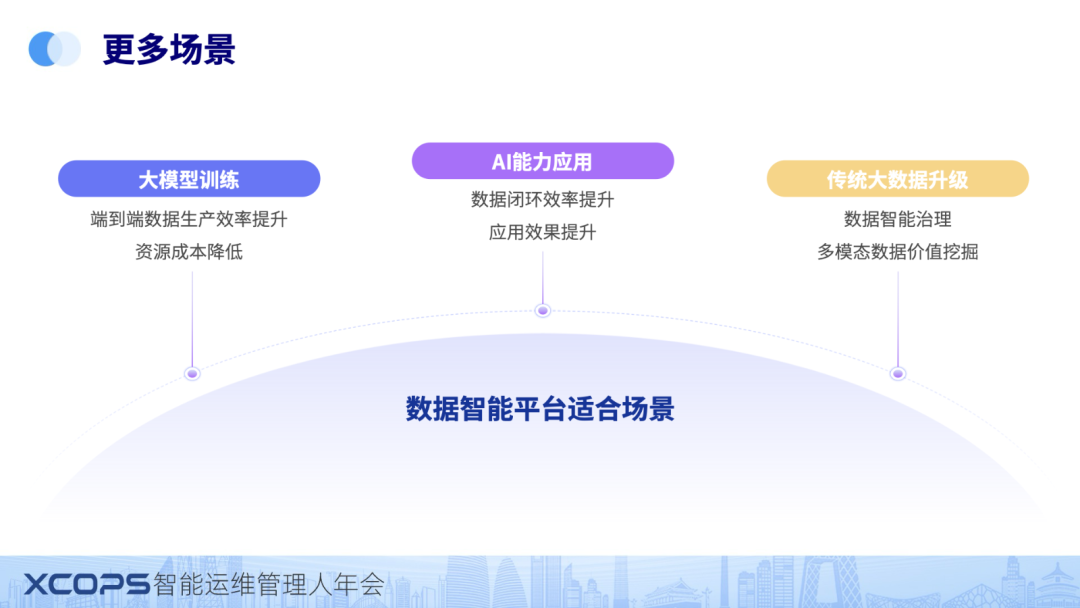
最后我们在简单总结下data builder应用的场景,databuilder 是面向新的大模型训练,AI 应用的新场景。
训练主要提升的是数据生产效率。
AI应用主要提升的是数据闭环效率提升和应用效果的提升。
最后相比传统大数据来说,也是升级,从结构化数据升级到多模态数据管理,相比传统大数据产品,可以挖掘更多价值。

最后我用Gartner 的预测来总结下今天的演讲。
到2028年,80%生成式应用将在企业现有数据管理平台上开发,从而将实施复杂性和交付时间缩短50%。
最后预祝大家会用工具,用好工具,做好模型训练和AI业务。抓住AI时代的机会。


