





今天,越来越多的企业CIO发现,大模型驱动的NL2SQL距离企业级的ChatBI,中间还差100个人类数据分析师手工校验。
我们曾经写过“大模型能拿奥赛金牌,却搞不定小小SQL”的原因,简单来说,大模型NL2SQL和大模型写文章没什么本质区别,依然是“文字接龙”“猜猜下个token是什么”。
因此,幻觉不可避免。即使是今天最先进的大模型,在测试环境中仍然有1%左右的幻觉。
别小看这1%的幻觉率,在企业的数据分析场景,1%可能引发蝴蝶效应,导致数据结果全错。
因此,长期以来,许多团队都在探索既能发挥大模型优势、又能保障0幻觉不忽悠的NL2SQL技术路线。
01
NL2“X”2SQL:“妥协的艺术”
面对LLM直接生成SQL的不可靠性,业界普遍采用了一种折中方案——我们称为“NL2X2SQL”架构,即不让大模型直接生成SQL,而是在中间增加一个更加可控的“X”,就如同给车装一个“安全气囊”。
具体来看,这个“X”又有几种情况:
NL2DSL:DSL全称是Domain Specific Language,“领域特定语言”,简而言之就是一种结构化的语言,或者说对SQL的一层抽象,比如指标、维度、过滤条件等。大模型把用户的提问转化成DSL,系统再根据规则把DSL转化为SQL执行数据查询。BI厂商通常会采用这种技术路径。
NL2MQL:和NL2SQL类似,让大模型把用户的提问转化成指标平台抽象出来的语义层,再转化为SQL。一般指标平台厂商会采用这种技术路径。
NL2API:把其他工具的一些功能设计成API,用户的自然语言用大模型转换为对API的调用,生成SQL,取得数据结果。
下图展示了NL2X2SQL的大体流程:
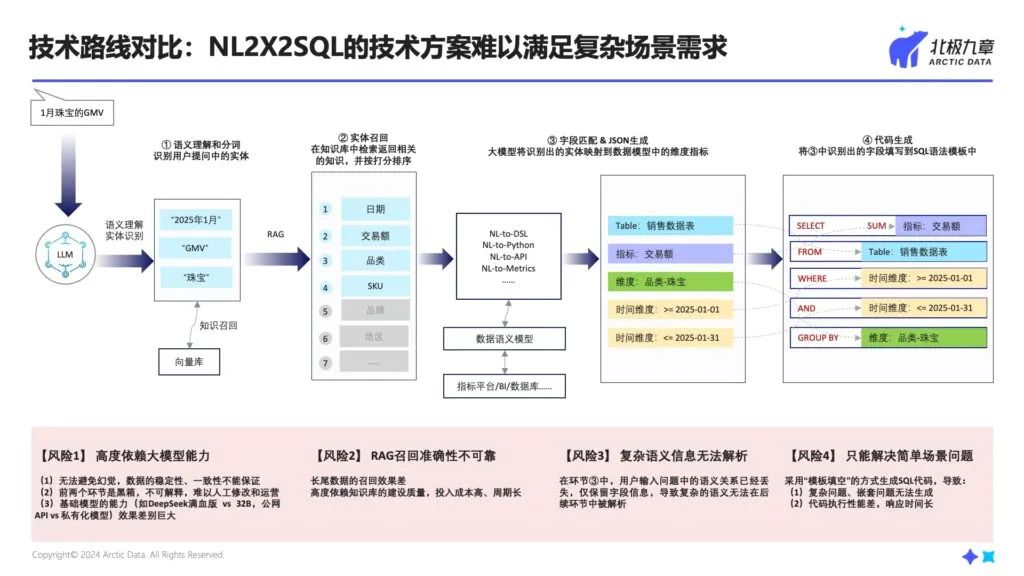
这种架构确实解决了部分问题,但本质上只是将幻觉问题从SQL层推到了中间层。就像把房间的灰尘扫到地毯下面——表面干净了,但问题依然存在。
具体表现为四个方面的风险:
第一,高度依赖大模型的能力,无法避免幻觉。
尽管通过模型调优、RAG等方法层层设防,但大模型在每一个环节的准确率可能都只有80%或90%,就像奶酪一样每一层都有孔洞。用户的提问有相当大的概率“穿过”每个漏洞,90%*90%*90%……*90%,最后准确率可能不到50%。
第二,RAG的召回准确率不可靠。
召回结果可能出现不准确、不完整等情况,影响后续环节。多种召回策略的效果差别大,并且依赖前期建设,投入成本高。
第三,复杂语义信息无法解析。
采用基于JSON“模板填空”的方式生成SQL代码,用户输入问题中的语义信息和修饰关系已经丢失,仅剩孤立的字段内容,导致复杂问题、嵌套问题无法在后续环节中被理解和呈现。
第四,只能解决简单场景问题。
用模板填空的方式生成SQL,无法解决复杂问题。且大模型在生成代码的时候不考虑可执行性,可能导致系统卡死。
02
如何打造真·0幻觉的ChatBI:大小模型协同架构
Gartner在一篇评论文章《何时不应使用生成式AI》中谈到:
如果您只有生成式AI这把“锤子”,
那么在您眼里,
一切看起来都像是生成式AI的“钉子”。
If all you have is a GenAI hammer,
everything looks like a GenAI use-case nail.

Gartner提醒企业,在生成式AI的hype中,需要思考哪种AI才是你真正需要的。
事实上,大模型和生成式AI只是广袤的AI技术中的一部分,它不是万金油——至少在数据分析和代码生成这个场景中,幻觉是巨大的隐患。
所以,我们的解决方案借鉴了经典哲学道理——“用合适的工具做合适的事”。具体架构如下:
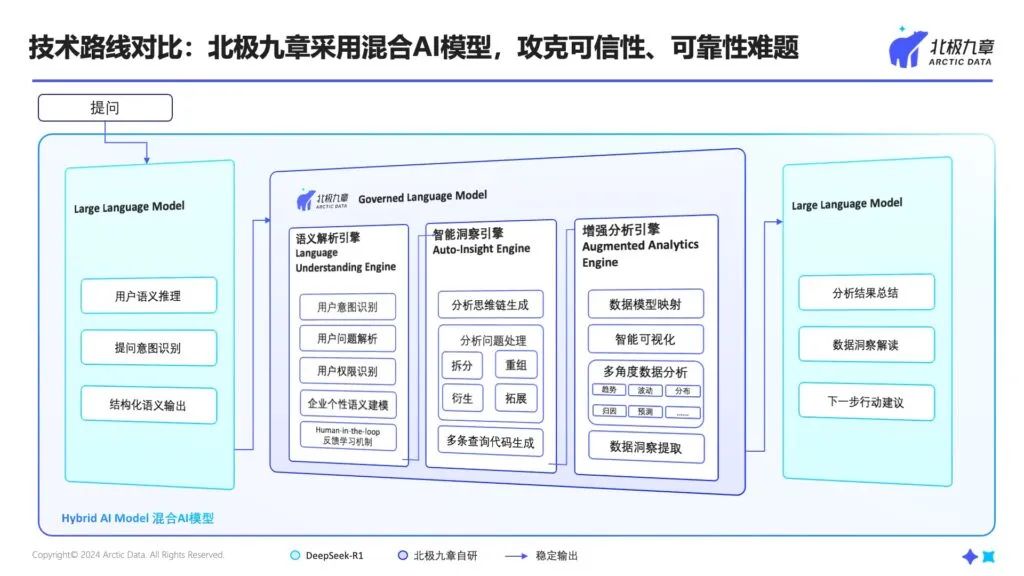
1. 大模型的前置角色:语义蒸馏器
与依赖大模型的技术方法不同,我们限制大模型只做它擅长的事——语义理解与意图识别。大模型首先能够判断用户的提问是否与数据分析相关,如果是数据分析问题,又是查询报告还是探索数据等。
大模型能够将用户灵活多变甚至模糊的提问转换为结构化自然语言,作为output输入给我们自主研发的小模型。
这种设计的关键在于:给大模型划定安全的创作边界。即使大模型在这个环节产生幻觉胡说八道,也只是相当于写了一个不好的prompt,而不会生成一段错误的代码或者错误的查询请求。
2. 基于小模型的NL2SQL:不只是NL2SQL
我们的自研小模型采用非Transformer架构,基于符号主义与机器学习方法,保障在NL2SQL的核心环节不受大模型幻觉影响。它执行如下几个关键功能:
(1)语义解析和问题解析:小模型自带语义解析引擎,会校验大模型理解的语义是否正确,作为双保险。同时,这个语义解析引擎能够理解语言的逻辑关系,并体现在后续的SQL生成中,避免了语义丢失的情况。在这一步,用户的问题被转化成一个标准的、合乎语法的、结构化的问题,作为生成SQL的基础。
(2)分析思维链(CoT)生成:在理解语义的基础上,我们的模型会对原始问题进行拆解、补充、改写、衍生,将一个问题拓展成与其相关联的多个问题,形成一系列分析的思路,主动帮助用户深入地洞察数据。这些思路也会同样转化成北极九章小模型擅长处理的结构化数据问题。
(3)SQL生成:基于上述步骤,我们已经正确理解了语义,并将发散的语言表达收敛为有限、可控的语言,因此在生成SQL环节,就能够确保0幻觉——只要理解了语义,就能稳定地生成准确的SQL。
03
效果对比:从“差不多”到“精确制导”
这样的技术路线效果如何?靠客户的实际反馈说话。
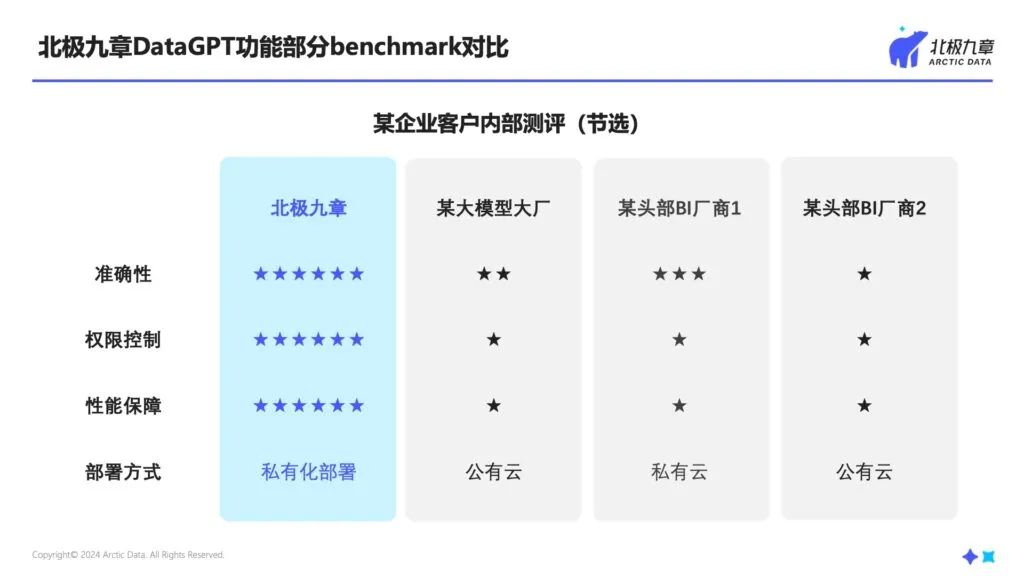
客户在测试过后跟我们反馈,没想到效果会相差这么多。这个也是企业在选型时经常遇到的困惑,为什么demo演示效果很好,在真实的数据场景、业务场景里就不行了?
这就是前面提到的数据库结构复杂、海量表和字段、复杂权限、分析逻辑复杂等带来的问题。很多并非仅靠大模型就能解决,还需要大量工程化的技巧。
结语
在AI时代重新思考“可靠”的定义
总的来说,我们坚持以下两条原则:
1. 责任边界原则:让LLM做它擅长的语义理解和文本生成,不让它做不靠谱的SQL生成;
2. 确定性优先:核心路径必须由确定性算法保障。
研发一款真正能落地应用的企业级应用,不在于盲目追随大模型的浪潮,而在于清醒认识各种技术的边界。
我们的实践表明:通过精心设计的模型协同架构,可以实现既保持自然语言交互的便利,又获得稳定可靠的NL2SQL系统,而这正是ChatBI、Data Agent等应用形态的基础。
正如计算机科学家Alan Kay所言:“预测未来的最好方式就是发明它。”我们相信,在企业级数据应用领域,真正的未来属于那些既拥抱AI潜力,又不放弃工程严谨性的务实创新者。



