






在企业的实际应用中,深分页是一种常见的高成本查询场景,通常指用户需要从海量数据结果集中获取靠后页码(如1000页之后)的数据,随之而来的是I/O开销激增、查询延迟显著上升等性能问题。比如在电商商品查找场景中,通常按销量、评分等排序,使用户能快速找到优质商品。为避免一次性加载过多数据导致卡顿,应用端常采用分页展示。
常规做法是按照所需列进行排序后利用 limit + offset 实现,这样的查询称为分页查询,其中 limit 为每页需要展示的数据条数,offset 为每页数据的起始偏移。若系统每页展示 100 条数据,那么查询第 1 页的 SQL 为:
SELECT * FROM t_order ORDER BY id LIMIT 0, 100
查询第 10001 页的 SQL 为:
SELECT * FROM t_order ORDER BY id LIMIT 1000000, 100
1.1 什么是深分页问题?
当请求的分页较深时,全局排序开销和频繁的回表开销会导致数据库性能急剧下降,这样的问题称为深分页问题,比如上面例子中查询第 10001 页的数据。
在云原生数据仓库AnalyticDB MySQL(以下简称ADB)这样的分布式数据库下会更复杂。为了减少不同节点间 shuffle 的数据量,往往每个 worker (存储数据的节点) 会先在本地做一次 TopN 计算,再由单节点对每个 worker 的执行结果进行聚合,排序后产生最终的结果集返回。
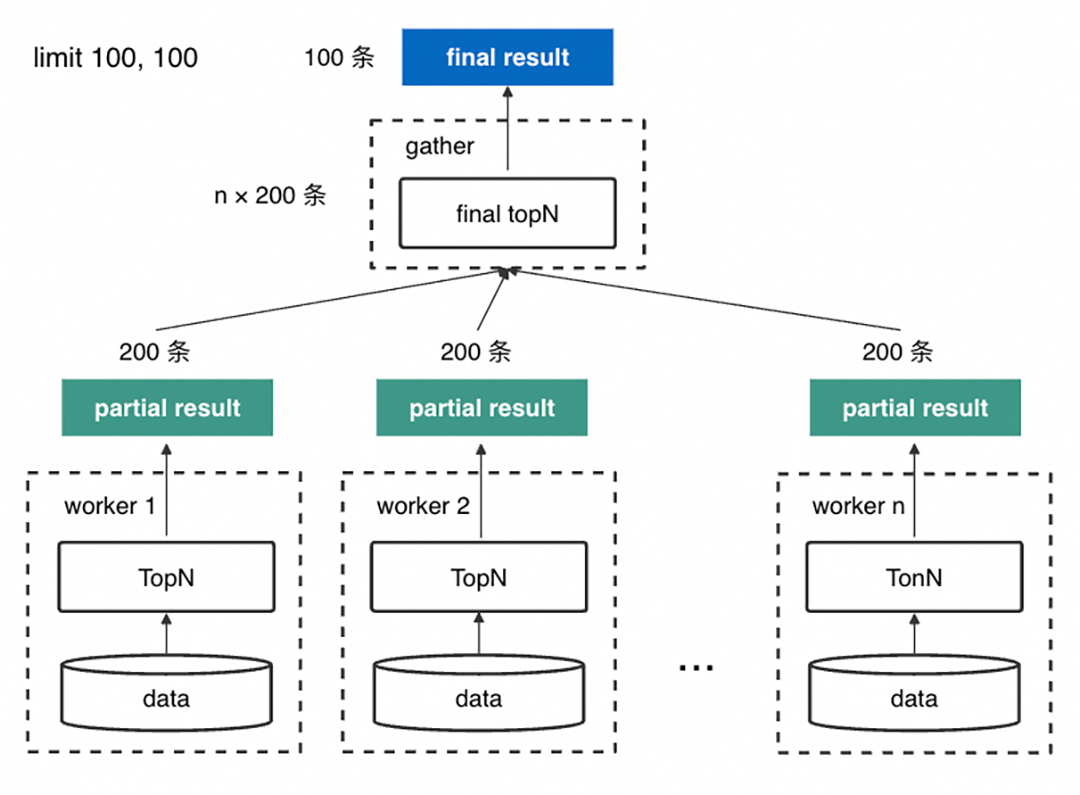
所以为了保证最终的正确性,需要对 SQL 语句进行改写交给每个 worker 执行。例如,查询第 10001 页,每个 worker 收到的查询为:
SELECT * FROM t_order ORDER BY id LIMIT 0, 1000100
原本只要 100 条数据,最后却要由单节点对 1000100 × worker数 条数据进行全局排序,排序的数据量随分页深度线性增长,性能也会急剧下降。同时不落盘的情况下排序完全基于内存进行,极大增加了 OOM 风险。
1.2 为什么在AnalyticDB使用深分页?

2.1 整体方案介绍
从上述场景和用户痛点出发,ADB对深分页进行专项优化,解决深分页查询的性能问题。主要思想是基于快照缓存。首次查询时会生成并缓存查询去掉 limit offset 后的结果集的快照,在元数据表中维护缓存的相关信息,通过 id 标识,以下称为 paging_id。
后续每次分页请求会通过 SQL 计算出 paging_id,找到对应快照数据,批量拉取结果。使用深分页优化后并不保证缓存数据与原始数据的强一致性。
2.2 关键链路

2.3 优化来源分析

每次都需要在每个存储数据的节点上查询排在最前面的 offset + 100 条数据,然后由单节点负责收集,将节点数 × (offset + 100) 条数据聚合起来进行一次全局排序,取最终的从 offset 开始的 100 条数据。这个过程中每个worker都要对本地存储的数据进行多次排序计算【如上图红色虚线框所示】,且最后全局排序的数据量与offset线性相关【如上图红色实线框所示】。
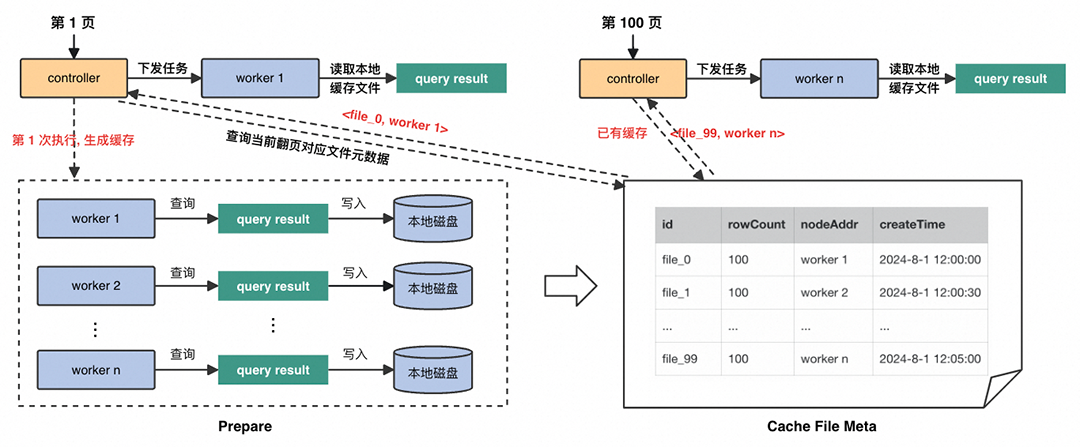
创建分页缓存阶段会在每个节点上查询分页SQL 去掉 limit offset 部分的所有数据,后续分页查询会根据 limit 和 offset 按一致的确定顺序读取缓存数据。【数据导出场景示意图如上所示】
相比普通分页查询,开启深分页优化后,对于数据导出场景,会优化掉不必要的 order by,执行效率和资源消耗会大幅降低;对于全量结果按需展示场景,也只存在一次全局排序,且每个分片只查询了一次。
基于TPCH 100G对数据导出场景的优化收益进行评估,测试集群包含6个worker,导出数据 100w 条,每页 10w 条数据。
-- 使用普通分页select * from lineitem order by l_orderkey,l_linenumber limit 0,100000-- 开启深分页优化/*paging_cache_enabled=true*/select * from lineitem limit 0,100000
普通分页查询各个指标都会随着分页深度的增加基本呈线性增长,因为存在一个全局排序,offset 越大,最后全局排序的数据量就越大。 开启深分页优化后,rt只有在缓存生成阶段会有明显延迟,延迟与单个文件大小相关;由于优化掉了 order by,最终的cpu使用率与峰值内存均较低。
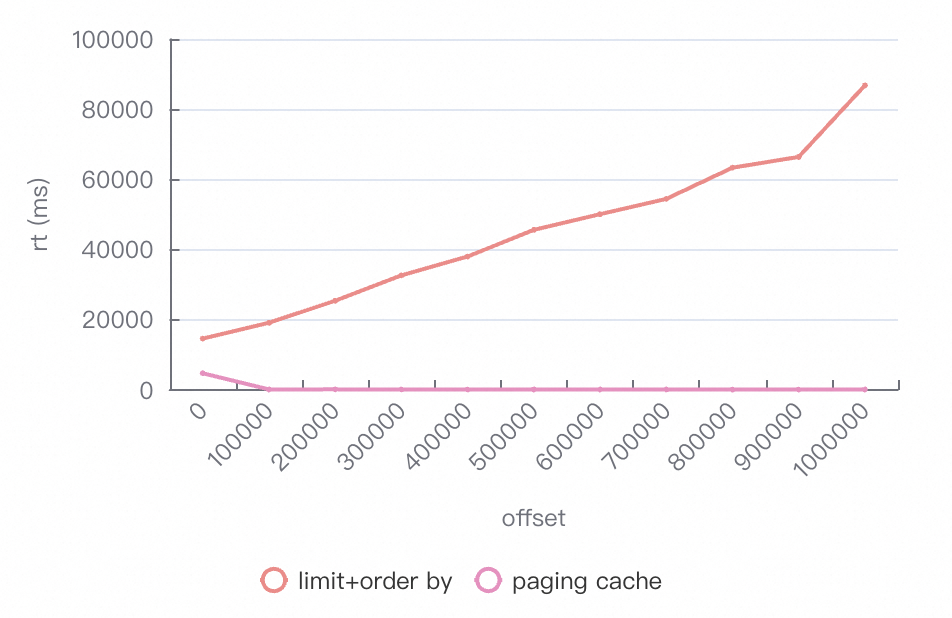
在数据导出场景下脱掉了不必要的order by,解决利用深分页导出时的 OOM 问题。 在分页展示场景下通过缓存快照,保证了只存在一次全局排序,且每个分片只查询了一次,提升查询性能。


点亮「星标」,关注我们不迷路

点击了解 AnalyticDB深分页产品化解决方案
