





功能介绍
# 下载x86镜像,并运行容器docker pull emqx/neuronex:3.5.1-aidocker run -d --name neuronex -p 8085:8085 --log-opt max-size=100m --privileged=true emqx/neuronex:3.5.1-ai# 下载arm64镜像,并运行容器docker pull emqx/neuronex:3.5.1-ai-amd64docker run -d --name neuronex -p 8085:8085 --log-opt max-size=100m --privileged=true emqx/neuronex:3.5.1-ai-amd64
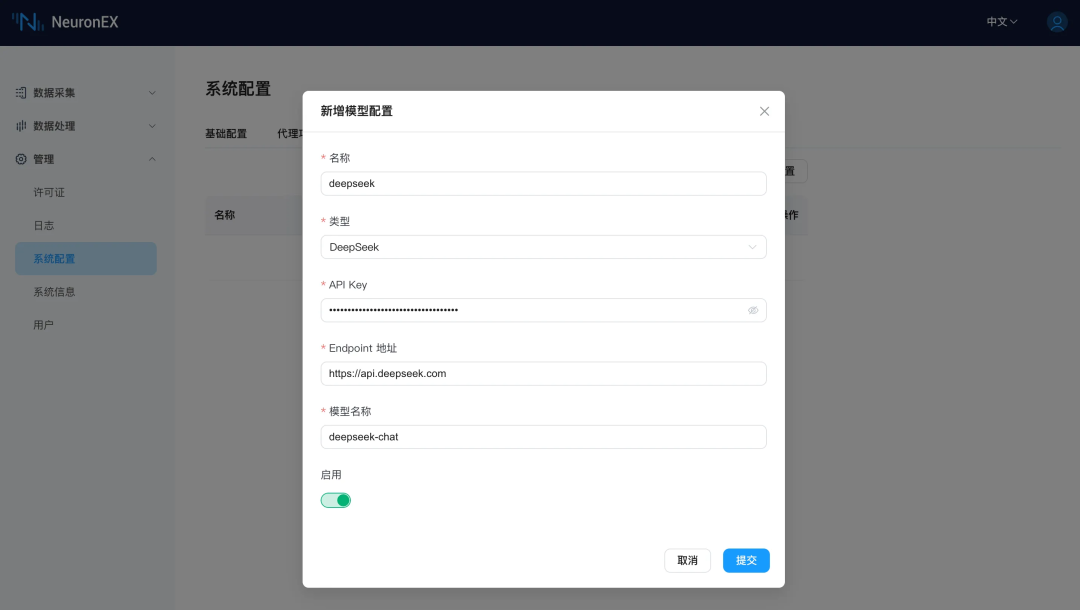
在使用 AI 生成 Python 插件功能之前,您需要先在 NeuronEX 系统配置 -> AI 模型配置页面,添加一个 LLM 模型配置信息,包括 LLM 模型的类型、API Key、Endpoint 地址以及模型名称。目前 NeuronEX 已支持以下厂商的模型:
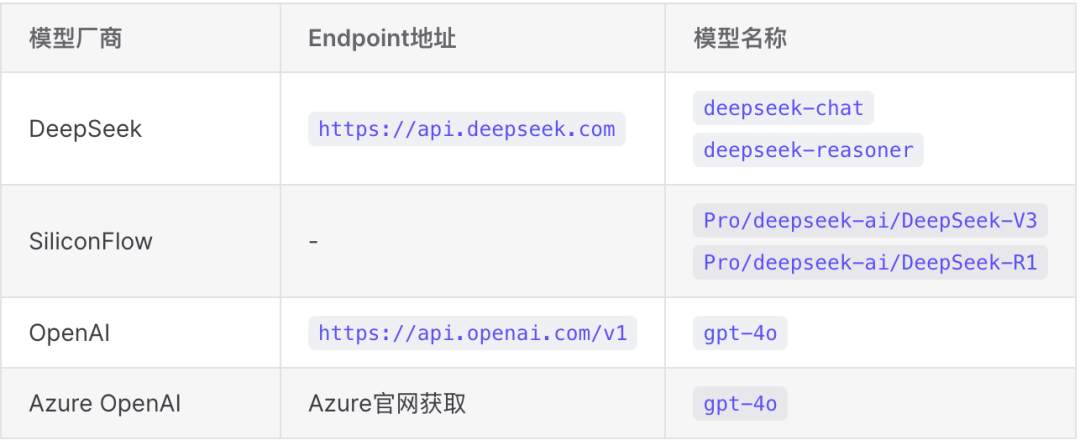
您可通过以上模型厂商的官方网站获取 API Key,并在 NeuronEX 页面添加模型配置并启用。可在页面中同时配置多个大模型,但只能启用一个模型进行使用。
请保证 NeuronEX 能正常联网,可访问大模型的 API。 小模型或者过于老旧的模型会影响生成 Python 插件的效果,上表中的模型为推荐使用模型,后续也可使用各厂商推出的新模型。
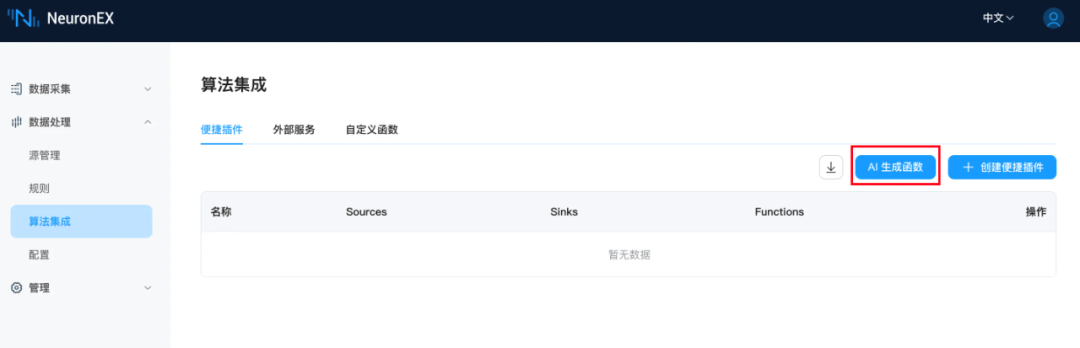
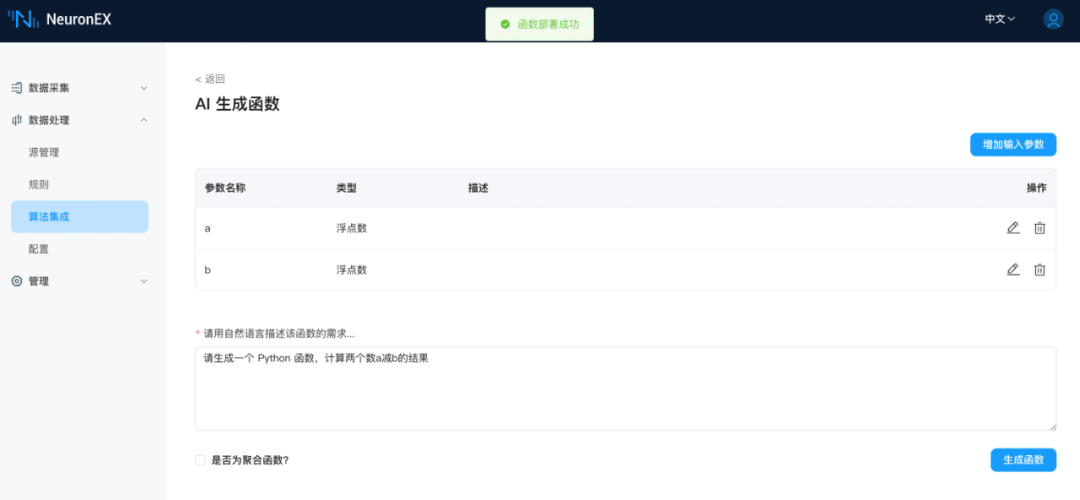
配置好 LLM 模型后,在 NeuronEX 数据处理 -> 算法集成页面,点击 AI 生成函数,进入AI生成函数页面:
请生成一个 Python 函数,计算两个数a减b的结果
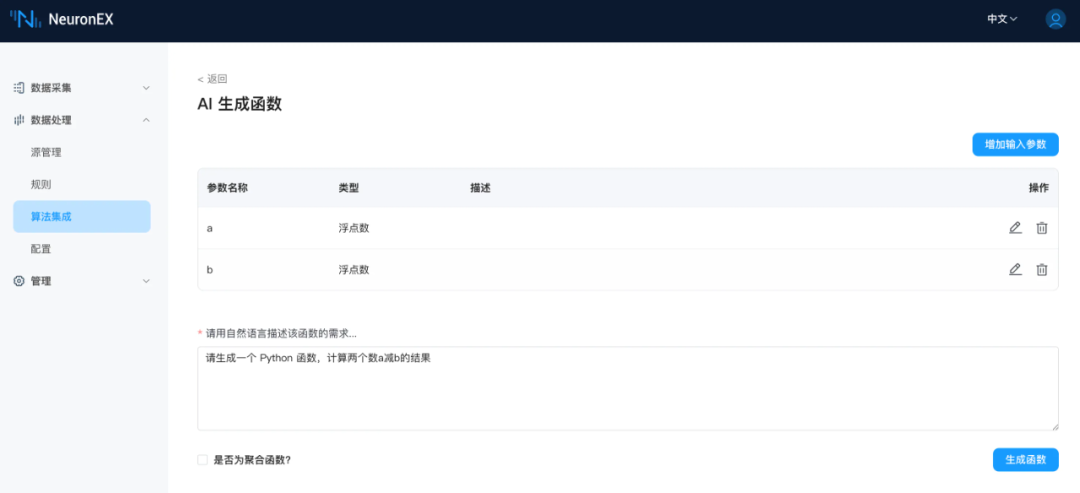
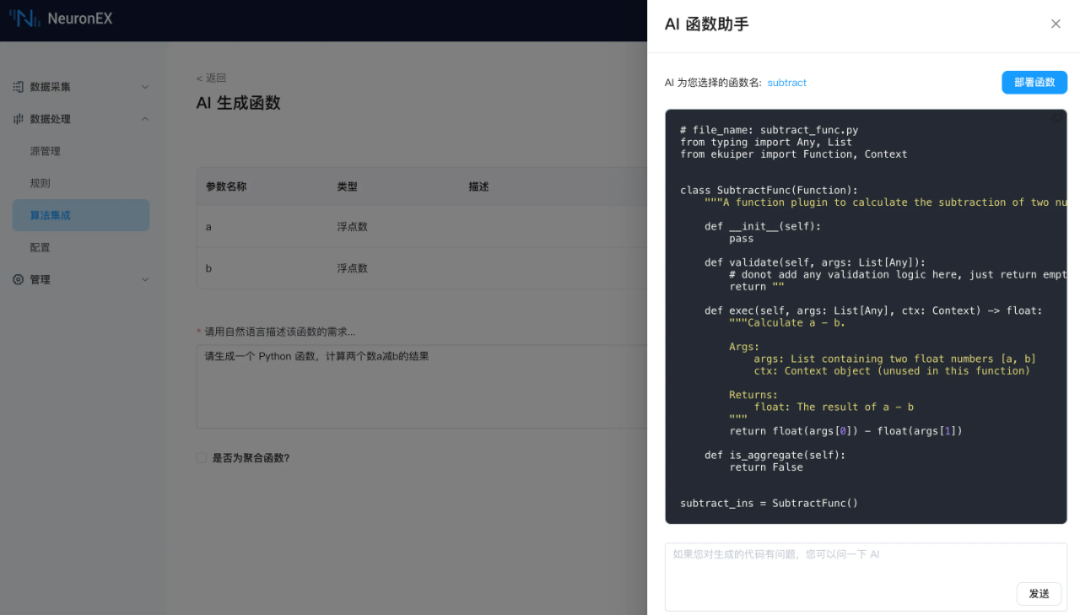
subtract:

TIP:
和 AI 对话并不能调整生成的函数代码逻辑,如果对生成的插件函数不满意,可再次输入并调整自然语言,重新生成。 如果 AI 生成的便捷插件与已有便捷插件名称重名,则原便捷插件会被覆盖。 如果 AI 生成的便捷插件与内置函数名称重名,则内置函数优先级更高,生成插件无效。
SELECTsubtract(a, b) as resultFROMneuronStream
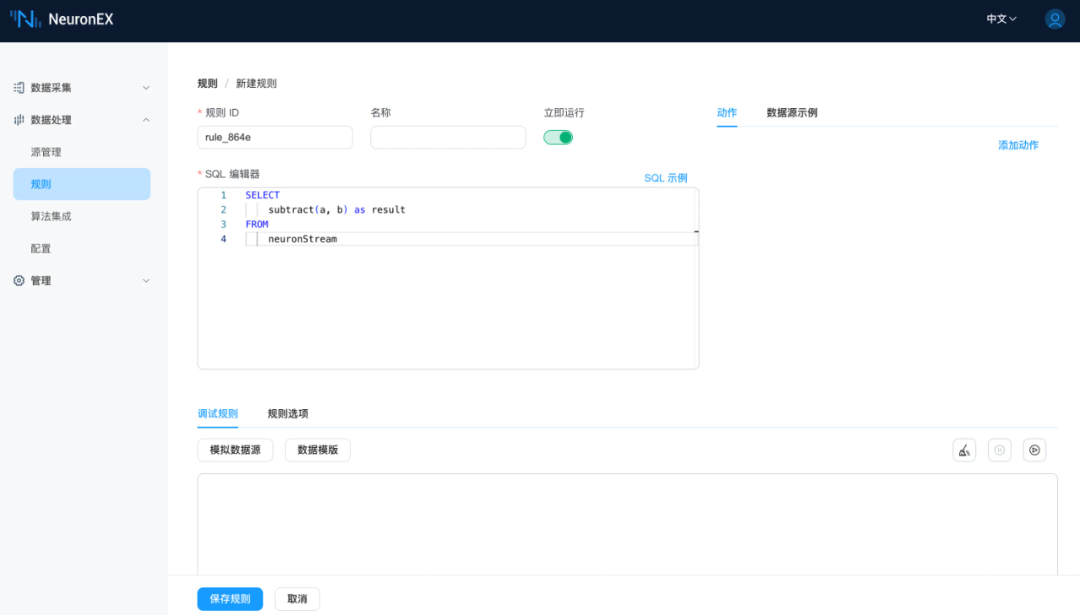
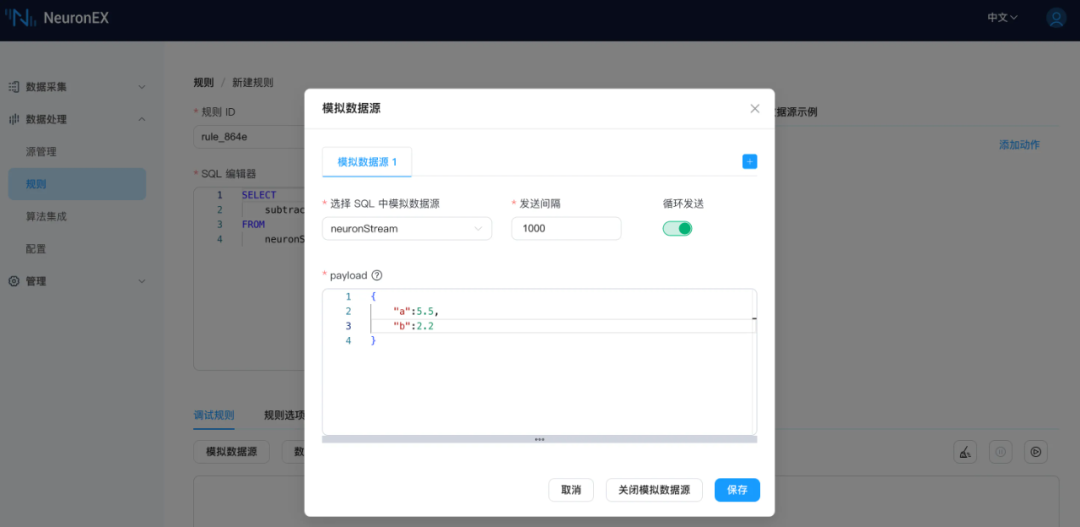
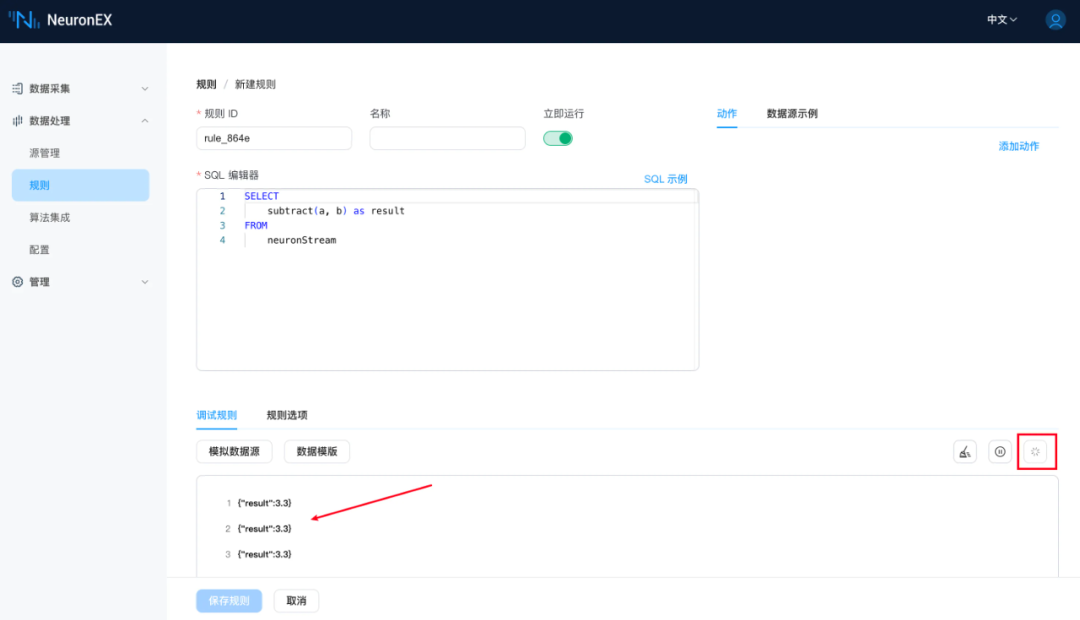
使用示例
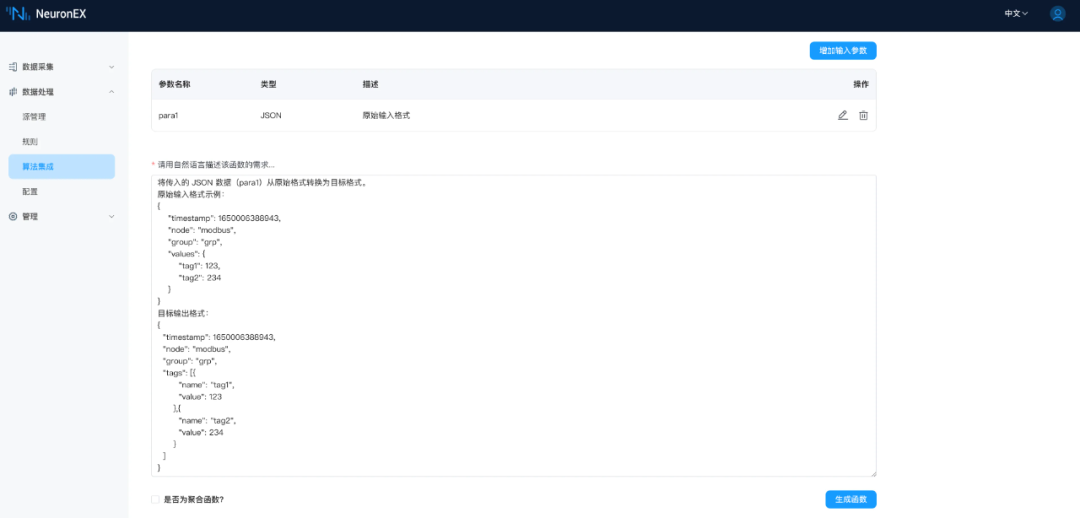
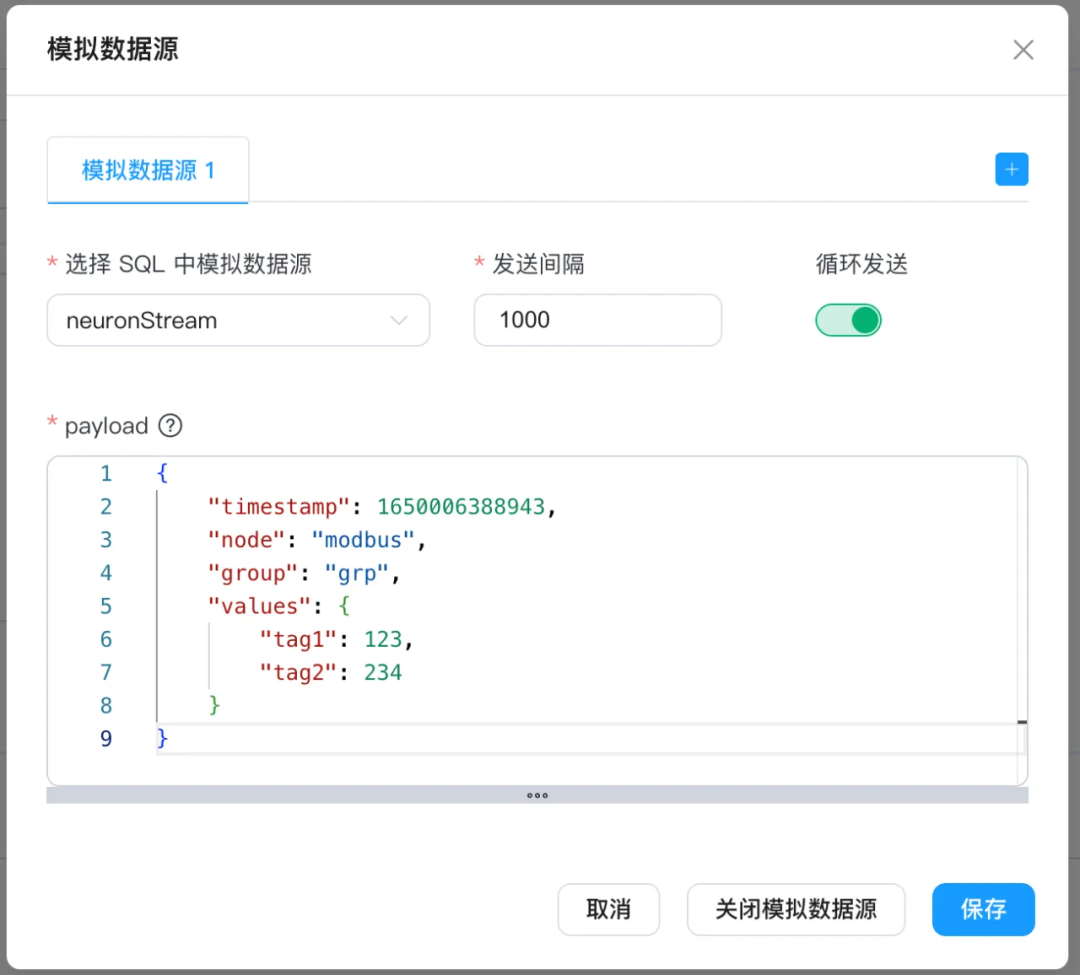
数据格式转换是工业场景中常见的数据处理需求,AI 生成Python插件功能,可根据下游 IoT 平台数据格式要求,将数据转换为对应格式。下面举例说明,将原始输入格式:
{"timestamp": 1650006388943,"node": "modbus","group": "grp","values": {"tag1": 123,"tag2": 234}}
转换为下游 IoT 平台要求的格式:
{"timestamp": 1650006388943,"node": "modbus","group": "grp","tags": [{"name": "tag1","value": 123},{"name": "tag2","value": 234}]}
对话输入如下:
实现以下功能,将输入的 JSON 数据 (para1) 从原始格式转换为目标格式。## 原始输入格式{"timestamp": 1650006388943,"node": "modbus","group": "grp","values": {"tag1": 123,"tag2": 234}}## 目标输出格式{"timestamp": 1650006388943,"node": "modbus","group": "grp","tags": [{"name": "tag1","value": 123},{"name": "tag2","value": 234}]}
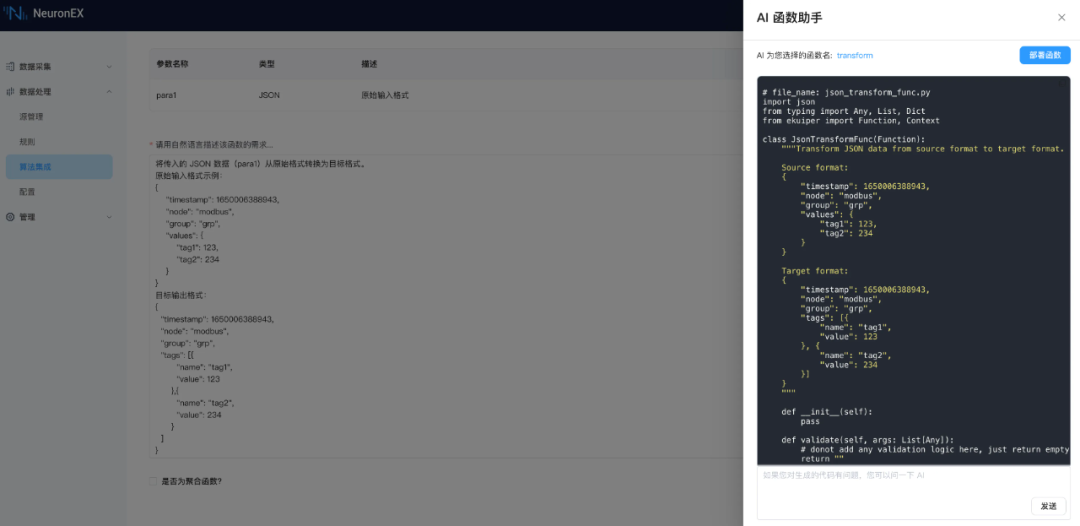
函数生成如下:
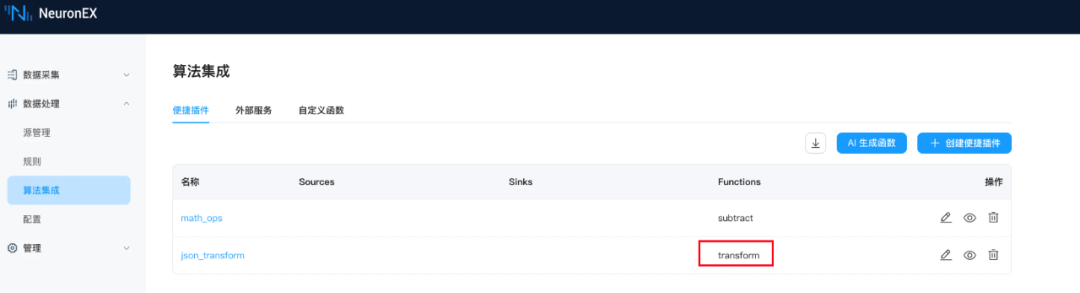
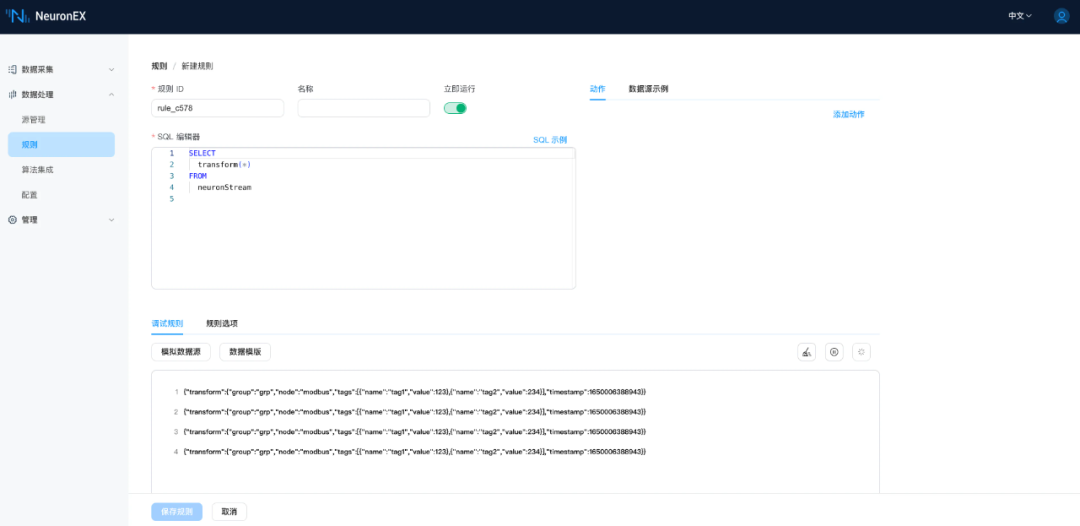
在规则中调用:
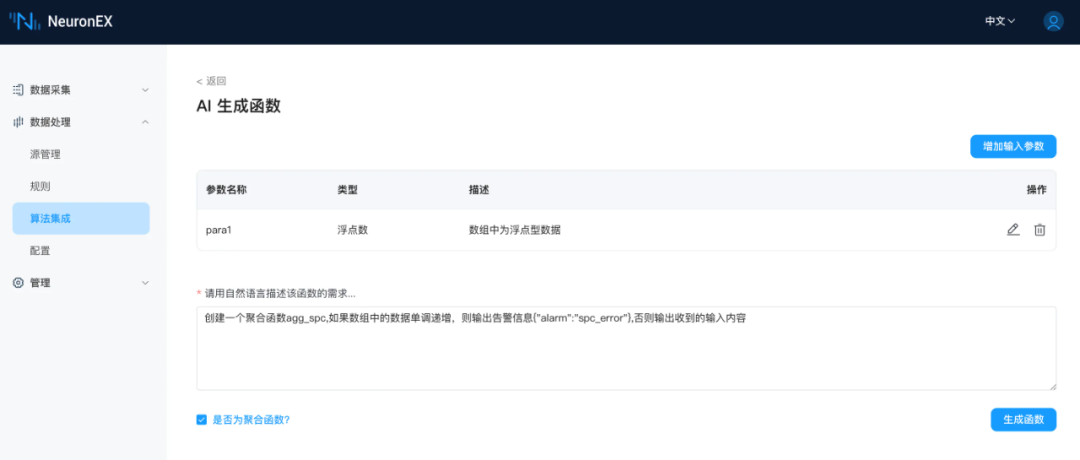
SPC(Statistical Process Control) 统计过程控制,是工业场景中常见的数据处理需求,AI 生成Python插件功能,可根据 SPC 规则要求,生成对应的聚合函数。下面举例说明,创建一个聚合函数 agg_spc,如果数组中的数据单调递增,则输出告警信息{"alarm":"spc_error"},否则输出收到的输入内容。
对话输入如下:
注意,需要勾选是否为聚合函数。
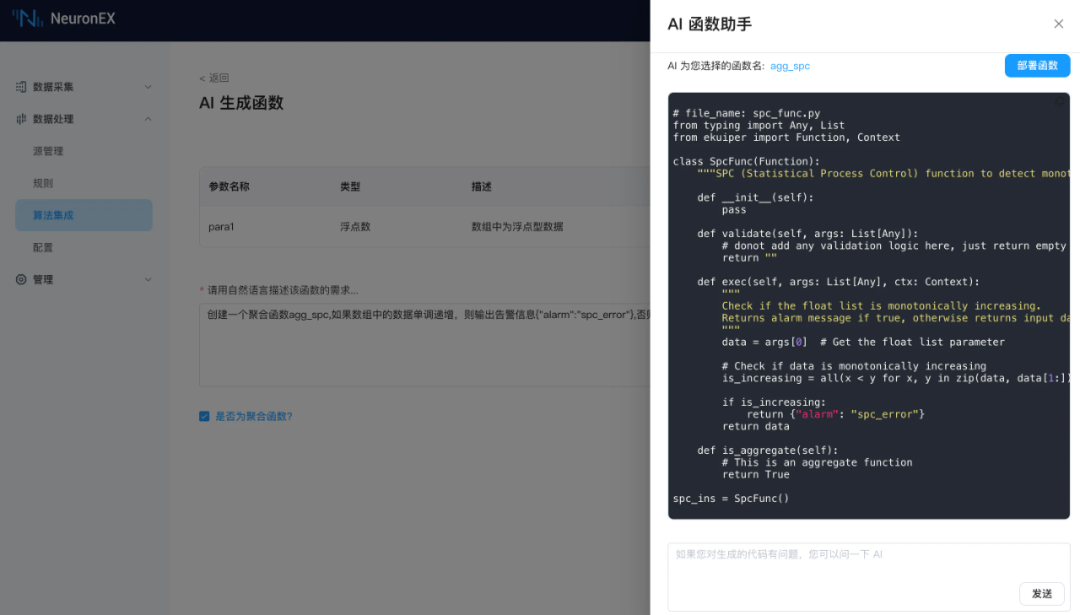
函数生成:
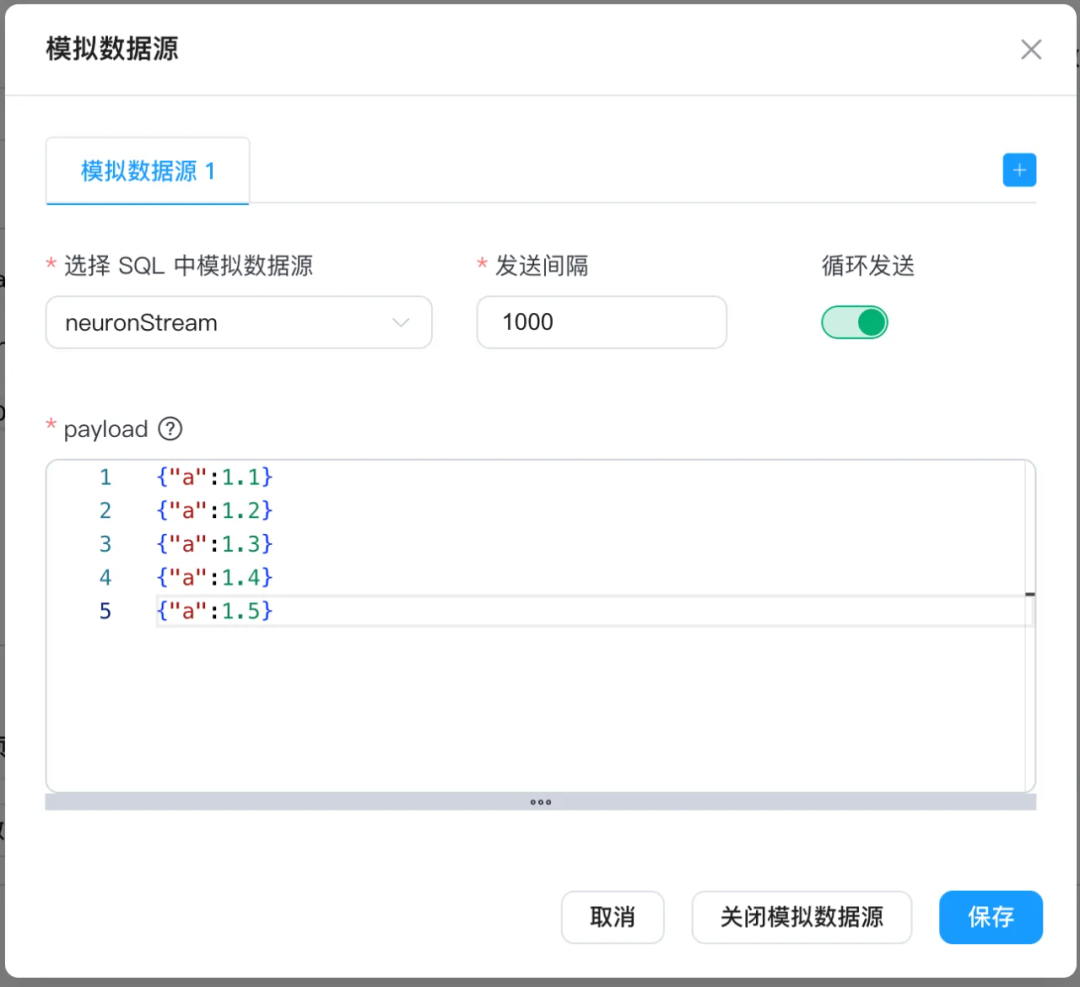
{"a":1.1}{"a":1.2}{"a":1.3}{"a":1.4}{"a":1.5}
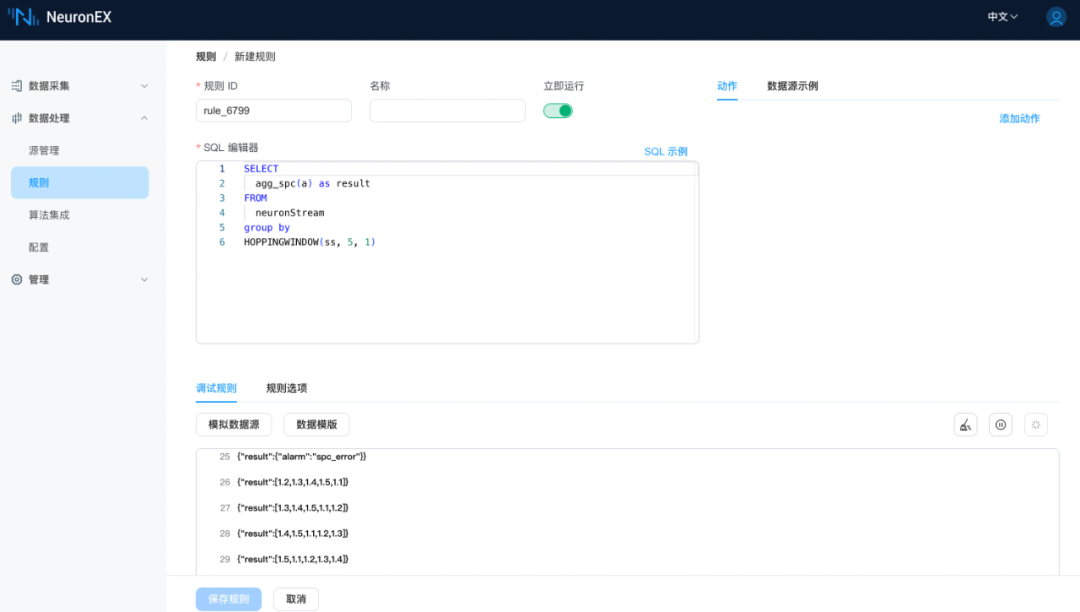
SELECTagg_spc(a) as resultFROMneuronStreamgroup byHOPPINGWINDOW(ss, 5, 1)
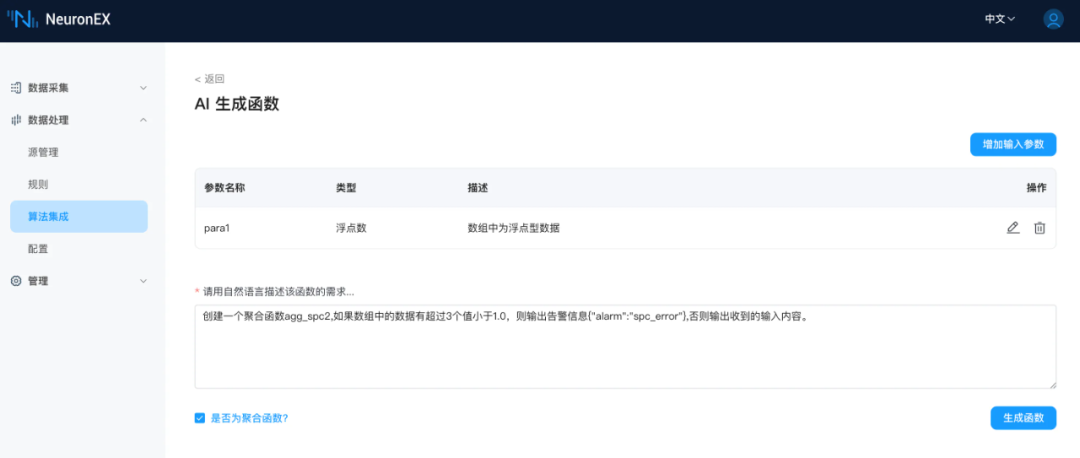
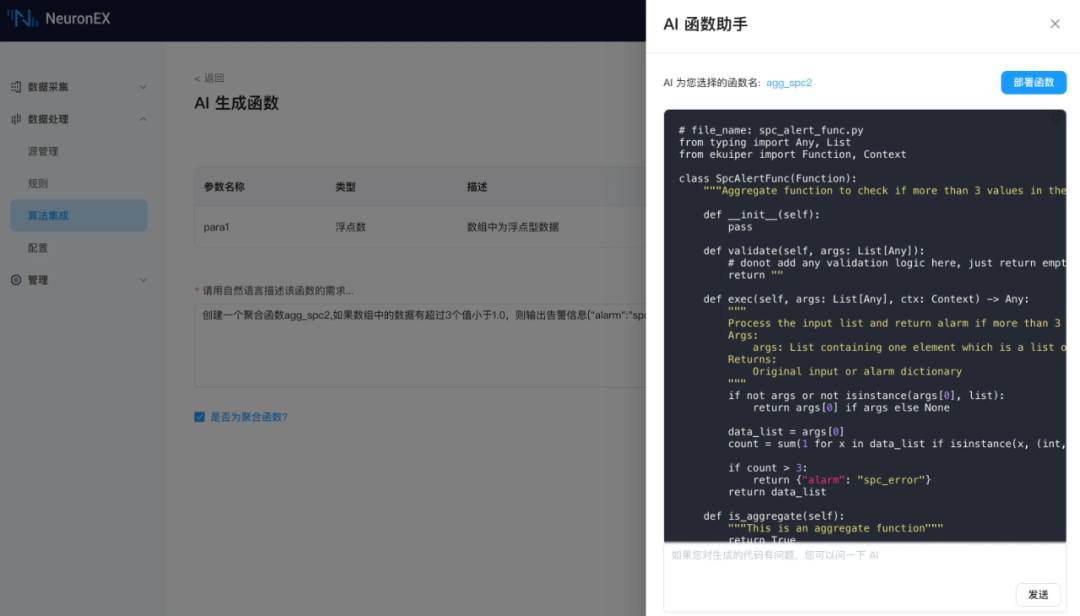
SPC(Statistical Process Control) 统计过程控制,是工业场景中常见的数据处理需求,AI 生成 Python 插件功能,可根据 SPC 规则要求,生成对应的聚合函数。下面举例说明,创建一个聚合函数 agg_spc2,如果数组中的数据有超过 3 个值小于 1.0,则输出告警信息{"alarm":"spc_error"},否则输出收到的输入内容。
对话输入如下:
函数生成:
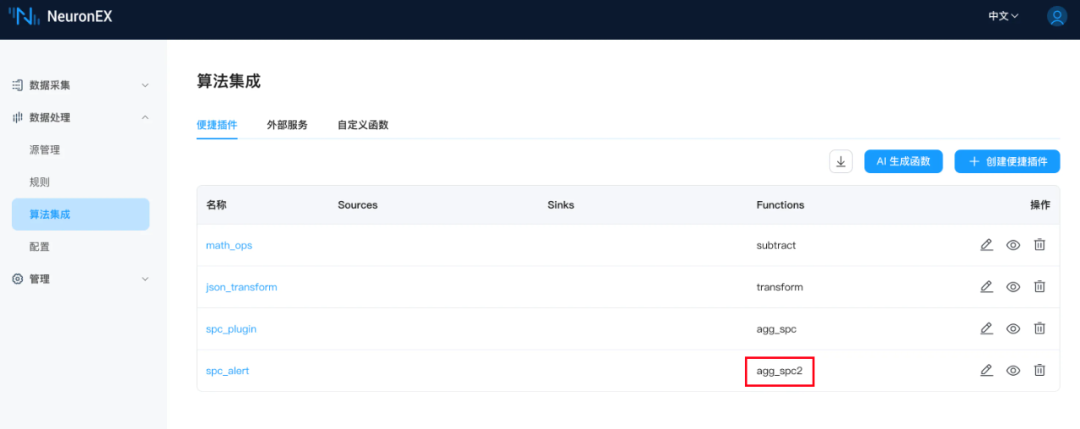
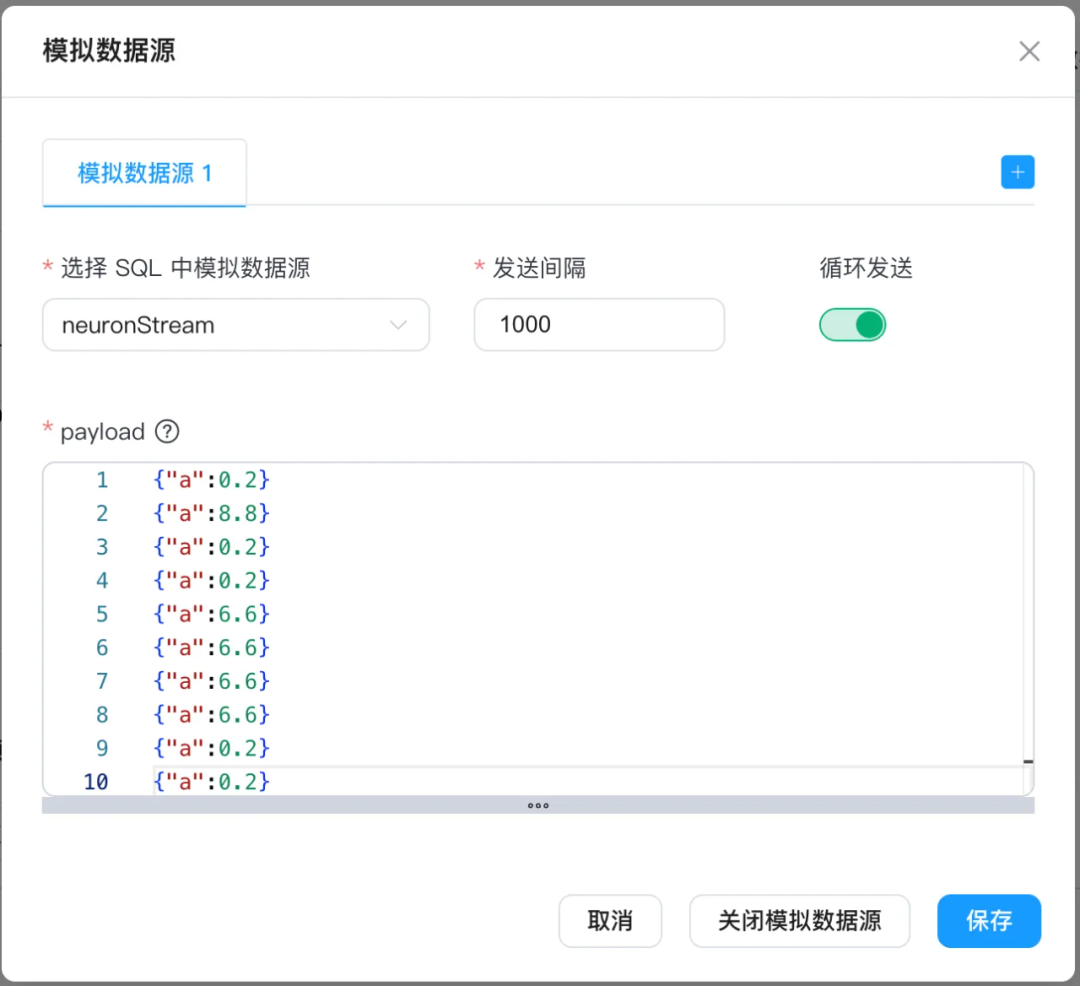
在规则中调用:
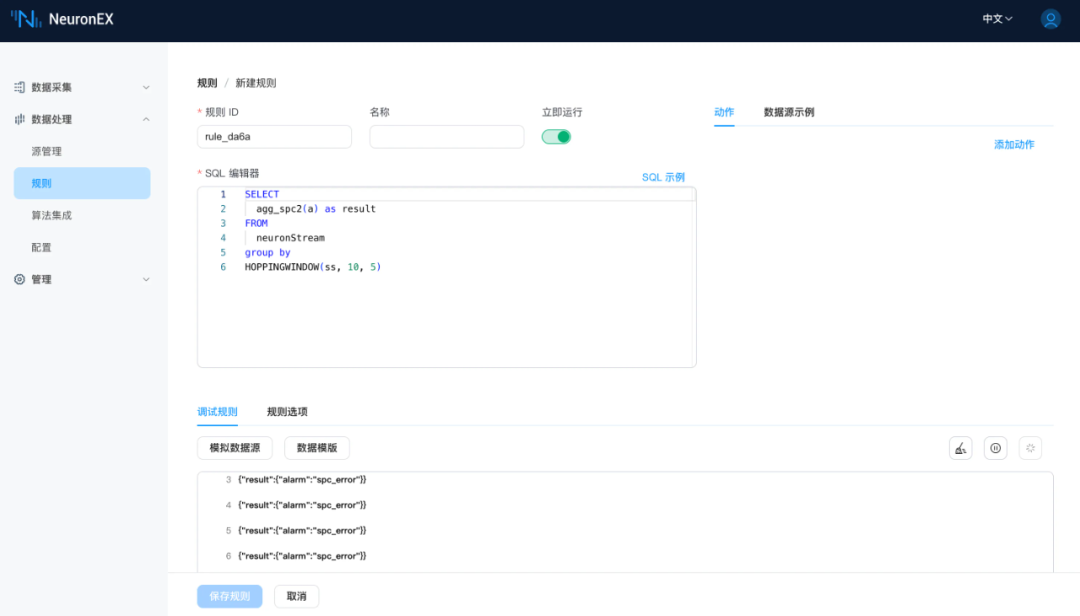
总结
通过以上示例,我们可以看到,AI 生成 Python 插件功能,可以快速生成满足特定需求的 Python 函数,并自动部署到 NeuronEX 中,方便在规则中调用。您可以参考以上示例,结合实际业务需求,生成对应的 Python 函数,充分发挥 NeuronEX 在工业边缘计算场景中的潜力。
点击阅读原文,了解更多产品内容


