




从存储到应用再到管理,以数据流动与价值为基础所构建的企业数据管理架构,已经成为驱动机构强大生产力与竞争力的核心。资产管理公司如何打破企业内不同业务系统壁垒,全局实时记录投资头寸、交易及资金流动,以应对快速变化的市场与风控需求,成为了一个命题。在 DolphinDB 新发布的 V3.00.3 中,我们尝试用 Orca 来回答这个问题。
除了新发布的企业级实时计算平台 Orca 之外,DolphinDB 在新版本中还针对 GPU 计算加速这一场景进行了优化与提升:基于 Shark 平台,用户可以更加方便快捷的在 GPU 平台使用自定义函数,同时引入「计算图」功能,大幅提升计算性能。
金融业务中间件方面,针对 FICC 新增了功能全面支持各类债券定价,包括浮息债、含权债、可转债及摊还债的精细化估值计算函数,满足复杂固收产品的定价与风险管理需求。同时新增多功能债券计算器(支持YTM/价格互算及风险指标),全面覆盖主流债券类型,支持灵活参数配置,适用于精准定价与风险管理。
此外,新版本在安全性方面有较大提升,流计算模块、数据分析能力也均得到增强。本文,将带领各位一览 DolphinDB V3.00.3 & 2.00.16 新版本的亮点功能与重要更新!
重点功能
1. 企业级实时计算平台 - Orca
在数字化转型加速的今天,企业对实时数据处理的需求日益增长。Orca 通过构建坚实的分布式、高可用架构与实时计算能力,助力企业实现数据驱动的敏捷与高效运营。
Orca 专为解决企业在数据计算与管理中的核心痛点而设计。它能够统一整合企业内各类数据(包括离线、实时、高频、低频等),确保跨部门数据的一致性和实时性,从而提升业务决策的效率和准确性。
核心价值:
全局数据视图:提供企业级数据目录,清晰展示数据分布、来源及用途,帮助业务部门快速定位和使用数据资源。
统一数据管理:集中管理企业全域数据,消除数据孤岛,确保各部门使用同一版本的数据,避免因数据不一致导致的业务偏差。
跨地域协同:支持跨集群数据查询与共享,无需重复迁移数据,实现多地数据的无缝协同。
高性能实时计算:支持毫秒级到秒级的实时计算响应,满足流计算、批处理等多种场景需求,确保及时响应业务需求。
高可用与自动化:基于声明式 API 自动调度计算任务,具备故障自愈能力,保障业务连续性和稳定性,大幅降低运维成本。
当前版本,Orca 初步实现了流计算子系统和全局数据目录。
5月28日,欢迎扫码报名参与直播,一同解构 Orca,看 Orca 如何重新定义企业级实时计算!
1.1 Orca - 流计算子系统
代码编写困难:现有系统中,用户需要编写流表的 schema,设计流计算并行逻辑、销毁不需要的流表和引擎,导致代码冗长且容易出错。此外,底层概念暴露较多, 需要关注实现细节(low-level),用户有一定的开发负担。
部署和运维困难:用户需要手动指定流计算任务运行的物理服务器,节点重启后需要重新搭建流计算 pipeline,重新执行代码来发布和订阅流表。
操作困难:查看流表、插入流表、引擎预热等操作需要用户连接到具体的 server 节点上执行,操作不够便捷。
流计算架构:
为了解决上述问题,我们对现有流计算系统进行了重构,设计了调度者和执行者,调度者负责接收用户的请求,并将任务分发至执行者中进行调度处理。将开发者从实现细节中解放出来。
Stream Master:无状态控制中心,负责全局状态管理、任务调度和 Checkpoint 协调。
Stream Worker:负责流引擎构建、运行和状态上报,通过内存维护任务信息并依赖 Checkpoint 实现容错。
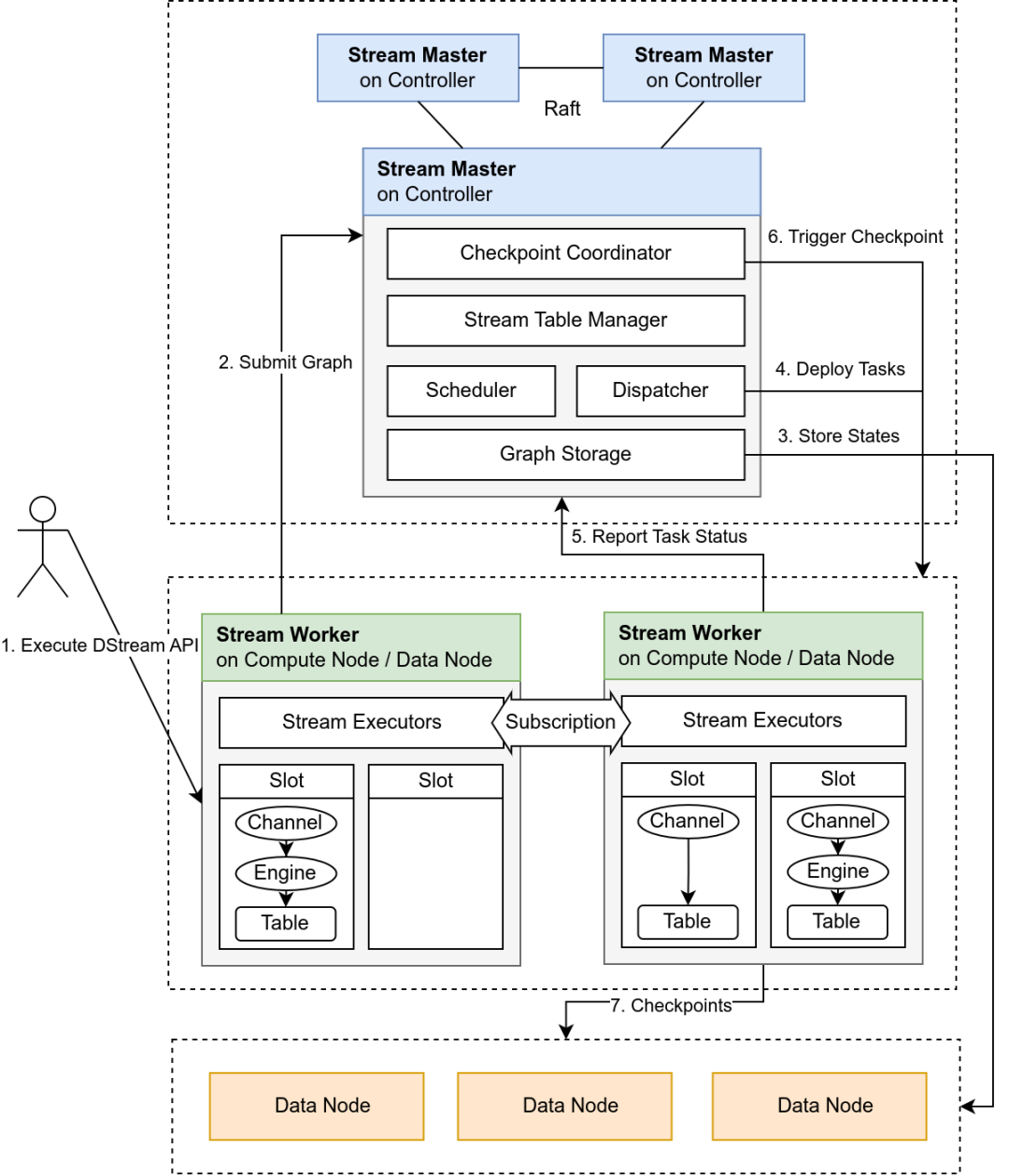
1.2 Ocra - 此版本核心特性
声明式 API:通过 DStream API 封装流表与引擎创建逻辑,用户通过链式调用构建逻辑流图,系统自动完成 schema 推导、环检测、私有流表插入等。
自动调度与负载均衡:根据节点资源(CPU、内存、磁盘)生成综合评分,结合贪心算法优先分配高复杂度任务。
状态驱动的高可用设计:流任务状态机涵盖多种状态,支持异常自动恢复与人工干预。
资源隔离与权限管控:通过计算组隔离任务调度,限制用户直接操作底层流对象,保障系统安全性。
为了大家能够更加直观的了解 Orca,下面以 k 线计算的场景进行说明。
在之前的版本中,假设开发者需要实现一个实时计算任务,计算分钟频因子,会经历以下步骤的代码工程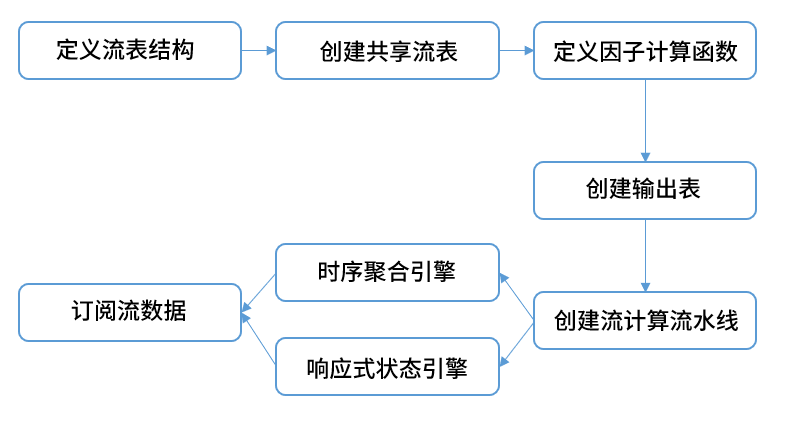
在新版本中,用户可以用以下脚本完成因子的实时计算任务:g = createStreamGraph("factor")baseStream = g.source("snapshot", 1024:0, defs.name, defs.typeString).parallelize(`symbol, 2).timeSeriesEngine(60*1000, 60*1000, agg_metrics, `timestamp, false, `symbol).reactiveStateEngine(factors, `symbol).sync().sink("basic_values")g.submit()
2. 引入计算图,加速复杂算子计算
新版本在 Shark 中新增计算图,使得用户可以更加便捷的在 GPU 上使用自定义函数进行计算。
在 GPU 计算中,计算图(Computational Graph)是一种用有向无环图(DAG),描述计算任务依赖关系的数据结构。通过计算图将多个 GPU 操作合并为整体任务提交,其核心价值在于高效并行化,解决了传统逐操作提交的 CPU-GPU 交互瓶颈,是加速复杂算子高效计算的关键技术。
Shark 会解析自定义函数中所使用的算子,并形成 GPU 中的计算图,从而加速用户脚本计算的执行。特别值得一提的是,计算图的执行过程始终在 GPU 中运行,避免了中间数据在 CPU-GPU 之间搬运的消耗。这对提升 GPU 运行的效率十分关键。
@gpudef myFunc(x){return min(mavg(x, 128), mavg(x, 64))}x=1..1000000res = myFunc(x)
用户只需要对自定义函数加上 @gpu 注解,就能在调用 GPU 进行计算。无需使用复杂的异构计算 API(如cuda,cuda 的门槛是比较高的,必须了解 GPU 的硬件结构及计算的细节)。 Shark 提供的计算图大大降低了用户使用 GPU 的门槛。
数据分析能力再提升
1. 流计算引擎
Order Book Engine
本次更新显著增强了 OrderBookSnapshotEngine 的功能完整性和场景适应性,主要围绕低频数据连续性、成交明细丰富度、即时成交修复能力和债券全品种支持四大方向进行优化,适用于更复杂的市场监控与微观结构分析场景。具体表现在:
新增强制输出机制:当某分组超过设定的 independentForceTriggerTime(毫秒)未更新时,系统会自动触发该分组的快照输出,确保长时间无数据的分组仍能定期生成快照,避免停滞。这一改进增强了数据的连续性和完整性,特别适用于低频更新证券的监控场景。
新增买卖委托类型字段:用于记录每笔成交对应的买方和卖方订单类型(如限价单、市价单等)。该功能使得成交数据能够关联原始委托类型,便于分析市场交易行为(例如市价单成交比例),从而增强订单簿快照的微观分析能力。
新增即时成交检测功能:当检测到成交记录缺少对应委托(委托序号不存在或成交时间早于委托)时,会自动补充一条市价单委托记录(orderType=1)。对于重复的即时成交,会合并更新委托记录的成交量和最新价格;若后续出现原始委托记录,则将其与即时成交记录合并,并停止对该委托的即时成交判定。该功能要求委托号全局有序且必须从股票第一条记录开始处理,以避免将正常委托误判为即时成交。通过补充这些"缺失"的委托记录,使订单簿数据更完整。
增加债券全品种支持功能:引擎将对 XSHEBOND/XSHGBOND 市场全部债券(不再限于原可转债代码前缀规则)进行快照合成,同时保持原有可转债模式的向下兼容性。该修改使债券订单簿监控范围从可转债扩展至全品种,满足债券市场全品类分析需求。
CEP Engine
LookupJoin Engine
拓展支持等值连接(内连接),该配置通过参数 isInnerJoin 进行控制。内连接场景下,每次数据注入左表时,系统会在右表中查找与连接列匹配的记录,只有匹配成功才会计算指标并输出,否则不进行计算和输出。
Daily Time Series Engine
针对期货夜盘等复杂交易场景,允许对同一交易日内不同交易时间段(session)间(如夜盘/日盘/午休)独立配置是否合并 K 线,满足客户对跨 session 合并的精细化需求。
Threshold Engine
新增一款基于阈值触发的流式聚合引擎,通过动态监测数据列(如成交量)的累计值(如每满300触发一次)实时生成计算结果,而非依赖固定时间窗口。它支持分组聚合、跨天连续累计,并可结合交易时段过滤数据,同时确保未达阈值的数据在时段结束时强制输出,适用于高频交易实时统计与事件驱动分析场景。
2. 业务函数
2.1 FICC
FICC 新增功能全面支持各类债券定价,包括浮息债、含权债、可转债及摊还债的精细化估值计算,满足复杂固收产品的定价与风险管理需求。同时新增多功能债券计算器,全面覆盖主流债券类型,支持灵活参数配置,适用于精准定价与风险管理。具体如下:
新增浮息债含息价格计算函数
floatingRateBondDirtyPrice
其票面利率随基准利率(如 LIBOR/SHIBOR)定期调整,计算方式为基准利率 + 固定利差(Spread)。该函数支持自定义付息频率(年/半年/季/月)、节假日调整规则(如 Following/ModifiedFollowing)和日计数基准(如 Actual/Actual、30/360),并基于现金流贴现模型,结合债券的结算日、发行日、到期日、赎回价及市场无风险利率,输出每 100 面值的债券价格(含应计利息),适用于金融市场的精准定价与风险管理。
新增含权固息债含息价格计算函数
callableFixedRateBondDirtyPrice
基于 Hull-White 利率模型对嵌入期权(Call/Put)进行估值,支持设定行权日期(Exercise Dates)和 行权价格(Exercise Prices),并考虑利率波动率(Volatility)和均值回归率(Reversion)的影响。该函数提供灵活的付息频率(年/季/月等)、节假日调整规则(如 Following/ModifiedFollowing)和日计数基准(如 Actual/365),结合债券的票面利率(Coupon)、无风险利率(Risk-Free Rate)及赎回条款,输出每 100 面值的含权债券价格(含应计利息),适用于含权债的精确定价与风险管理。
新增固息可转债含息价格计算函数
convertibleFixedRateBondDirtyPrice
基于二叉树模型(Binomial Tree)对可转债的转股权(Conversion Option)及 赎回/回售权(Call/Put Options)进行估值,支持欧式/美式行权方式(European/American Style),并考虑股票现价(Spot Price)、转股价格(Conversion Price)、分红(Dividend Yield) 及利率波动率(Volatility)的影响。该函数提供灵活的付息频率(年/半年/季等)、节假日调整规则(如 ModifiedFollowing)和日计数基准(如 Actual/365),结合债券的票面利率(Coupon)、无风险利率(Risk-Free Rate)及赎回/回售条款,输出每 100 面值的可转债价格(含应计利息),适用于可转债的混合定价(债券+期权)与风险管理。
新增摊还本金固息债券含息价格计算函数
amortizingFixedRateBondDirtyPrice
该债券在存续期内按分期偿还本金(Notionals) 的方式逐步减少本金余额,利息基于剩余本金和固定票面利率(Coupon)计算。函数通过现金流贴现法,结合债券收益率(Yield)、付息频率(年/季/月等)、交易日历(如SSE)及日计数基准(如30/360),精确计算每100面值的债券价格(含应计利息),适用于房贷支持证券(MBS)等分期偿还型债券的定价与估值。
新增功能债券计算器
(对应 bondCalculator 函数)
支持固息债、贴现债、零息债三大债券类型,实现到期收益率(YTM)、净价(Clean Price)、全价(Dirty Price) 三者的互算,并可根据付息频率(到期一次/年/半年/季/月)、计息惯例(30/360、Actual/Actual等)精确计算应计利息,同时可选计算麦考利久期、修正久期、凸度、基点价值等风险指标,适用于中国银行间债券市场(CFETS 日历)的各类债券估值与风险管理需求。
2.2 插值与拟合
新版本丰富了拟合和插值方面函数库。通过引入 BVLS(带边界约束的最小二乘法)和 Kernel Ridge(核岭回归)增强拟合能力,通过 cubicHermiteSplineFit(三次埃尔米特插值)和 pchipInterpolateFit(分段三次埃尔米特插值)完善插值功能。适用于金融、物联网、科学研究等多种应用场景。
拟合:新增 BVLS 函数为用户提供了带边界约束的最小二乘法拟合功能,特别适用于需要在约束条件下进行回归分析的场景。新增 Kernel Ridge 函数通过核函数和岭回归技术,能够拟合复杂非线性关系,特别适合处理高维小样本数据。
插值:新增 cubicHermiteSplineFit 函数实现了三次埃尔米特插值,通过引入导数信息生成更平滑的插值曲线,适用于需要高精度插值的场景。新增 pchipInterpolateFit 函数实现了分段三次埃尔米特插值,保证插值曲线的单调性,特别适合处理数据波动较大的场景。
新版本还增强了数组向量的功能,拓展了空值填充函数,以及字典转成表场景下对数组向量列转换的支持。此外,时序与 SQL 计算能力也得到了增强,新增:
ARMA 模型:新增的 ARMA(自回归移动平均)模型结合了自回归(AR)和移动平均(MA)方法,适用于时间序列预测,能在保持良好拟合度的同时提供更简洁的模型结构,适合分析具有趋势和季节性的数据。
ARIMA 模型:扩展了ARMA模型,引入差分(I)处理非平稳时间序列,支持单变量分析,适用于更复杂的时间序列预测场景,如金融数据或经济指标建模。
时间差计算函数:新增函数 temporalDeltas(datetimeDeltas)计算时间序列的连续差值,支持自然日("d")、工作日("B")和交易所交易日(如"XNYS")单位。该函数用于计算两个时间点之间的差值,适用于精确的时间间隔分析。
智能Join顺序优化:优化器动态评估表访问成本与行数,自动选择最优 Join 顺序(支持多表组合),同时保留外部联接的约束逻辑,显著降低查询开销。
内存不足重试机制:新增配置项 maxJoinTaskRetry,限制Join任务内存不足时的最大重试次数,避免无限重试导致系统卡死,支持自定义阈值或无限重试(默认)。
空安全 Join 开关:提供动态配置项 enableNullSafeJoin 及其管理接口,允许管理员灵活控制Join操作的NULL值处理策略,增强查询安全性。
安全性增强
1. 登陆安全性
新版本从身份认证、访问控制、会话管理、登录协议等多个维度提升了用户登录的安全性,同时通过权限控制和配置开关确保了登录安全策略的可管理性。
改进单点登录功能
增加过期时间参数,使生成的登录口令具有时效性,同时在登录口令中加入时间戳确保每次生成的口令都是随机的,有效防止了登录口令被重复利用的风险,并严格限制只有 admin 用户才能执行 generateUserTicket 函数。
新增 IP 访问控制机制,支持设置黑名单或白名单(二选一)
新增黑名单、白名单管理函数实现IP地址的管理;设置将在整个集群范围内生效并持久化保存,最多可管理65535个IP地址,为系统提供了网络层面的安全防护。
会话管理新增 session 过期设置
管理员可以通过 setSessionExpiredTime 函数动态配置 session 的有效期,用户可通过 getSessionExpiredTime 函数查询当前设置,提升会话的安全性。
登录流程优化
已登录用户再次登录时仍需校验密码,提高账户安全性;同时当用户登出或切换账户时,系统会自动清理变量,防止敏感信息残留。
引入 SCRAM 登录协议
新版本新增支持 SCRAM(Salted Challenge Response Authentication Mechanism)认证协议,通过高强度哈希算法和双向验证机制提升安全性,有效防范密码泄露、中间人攻击和重放攻击等风险。
2. 数据安全性
新版本从数据传输加密和数据存储加密两大维度全面提升系统安全性,确保数据在动态传输和静态存储中的机密性与完整性。
增强数据传输加密功能(动态安全)
新增 SSL/TLS 全链路加密支持,覆盖集群内部通信、分布式查询数据交换及跨集群访问等场景,包括集群内部 RPC 加密、跨集群 XDB 加密、主从复制加密等多种方式。
增强数据存储加密功能(静态安全)
引入透明数据加密(TDE),采用两级密钥机制(主密钥 + 表密钥),实现多模引擎存储层自动加密。同时在备份恢复场景下也新增支持数据加密,以确保离线数据安全。
新增数据脱敏功能
支持敏感列标记,管理员可针对特定列(如身份证、密码等)进行脱敏,普通用户在系统任何环节中仅能查看脱敏后的数据,保证关系信息的安全,防泄漏。
新版本还引入了参数化查询功能,通过占位符机制自动处理参数值并隔离执行环境,彻底解决SQL 拼接导致的注入风险,使开发者无需手动拼接SQL即可安全执行查询。此外,版本还新增支持结构化二进制格式的审计日志,增强日志防篡改能力。
数据库运维管理升级
本次更新在运维管理、性能优化、稳定性增强多个方面进行了全面升级,为用户带来更高效与更稳定的数据分析体验。
运维管理优化:全面监控与精准审计
新版本在运维管理方面进行了显著增强,特别是在审计功能和用户流量监控上。审计日志的完善使得系统能够记录数据库的所有关键操作,包括登录登出、权限修改、新建连接以及配置文件修改等,这些操作都被详细记录到单独的文件中。这一改进不仅有助于追踪潜在的安全问题,还能为系统管理员提供更全面的操作历史记录,便于问题排查和审计合规性检查。
用户流量监控功能的引入则解决了网络资源被过度占用的问题。通过提供流量监控工具,管理员可以快速定位那些执行高资源占用查询或脚本的用户,从而保障全局用户的正常使用体验。此外,资源追踪框架的更新,增加了发送和接收数据量的记录,使得系统能够更精准地监控网络资源的使用情况,进一步优化资源分配。
OLTP 数据库新增权限管理,为 DML/DDL 操作分别设置了详细的权限规则,使用方式与现有权限系统一致, 包括 DB_OWNER、 DB_MANAGE、DBOBJ_CREATE、DB_READ等。有效支撑生产环境的数据安全。
插件功能拓展:灵活性与可定制化提升
在插件功能方面,新版本引入了两个重要特性:setLogLevel 和 getLogLevel 函数,以及插件接口对 keyword 参数的支持。用户可以根据自己的需求更精细地控制插件的日志级别,而无需受到服务器日志级别的限制。同时,插件接口对 keyword 参数的支持,进一步丰富了插件的定义和调用方式。
性能与稳定性提升:优化与限制的双重保障
性能方面,新版本针对 delete 操作进行了优化,解决了分区剪枝优化(非 DATE 类型)和 TSDB delete from 操作过慢的问题,显著提升了数据删除操作的效率,减少了对集群其他任务的影响,提高整体系统性能表现。
稳定性方面,对 cache 刷盘 OOM 问题做了较大的改进:优化 cache 刷盘算法、引入了对单次事务大小的限制。需要说明的是,通常企业级用户不会有 cache 刷盘 OOM 的烦恼,这个更新会对社区版用户非常友好,DolphinDB 一直以来都是十分重视和倾听社区用户的心声。
新增查询超时机制,管理员可根据业务情况设置一个合理的超时阈值,避免不合理的查询持续地占用系统资源,保障平台级业务应用的稳定运行。
同时,还增加了用户级别的限制,如共享变量大小限制和最大分区数量限制等。这些限制措施不仅保障了系统的稳定运行,还提升了系统的可扩展性和可靠性。
功能改进:存算分离大幅优化
新版本在存算分离方面进行了多项重要更新,显著提升了在运维管理、性能分析和缓存管理方面的功能。
首先,新增了getComputeNodeCacheDetails 运维函数,支持以库、表、分区为单位查看计算节点缓存的详细构成,包括磁盘和内存占用情况,帮助管理员更精准地进行运维管理。其次,HINT_EXPLAIN 功能得到扩展,新增 partitionRoute 模块,可以清晰展示查询是直接使用计算节点缓存还是下推到数据节点,方便用户分析性能。
此外,新版本引入了计算组缓存预热功能,通过 warmupComputeNodeCache 和getComputeNodeCacheWarmupJobStatus 接口,支持库表级别的缓存预热,避免冷启动,让系统能更快进行良好的服务状态。同时,计算节点缓存支持LZ4压缩和校验和,采用多级缓存策略,优化内存和磁盘缓存管理,进一步节省存储空间。
最后,优化了缓存清理接口 clearComputeNodeCache 和 clearComputeNodeDiskCache,支持按库表、分区级别清理缓存,提升了缓存管理的灵活性和精准度。这些更新使得DolphinDB在存算分离场景下更加高效、灵活,能够更好地满足用户对大规模数据分析的需求。
Explore More

