




本文对芝加哥大学团队编写的2024 VLDB论文编写的论文《Saving Money for Analytical Workloads in the Cloud》进行解读,全文共8702字,预计阅读需要20至30分钟。
随着用户将分析工作负载迁移到云数据库,降低成本与优化查询运行时间变得同样重要。在云端,查询费用主要基于计算时间或处理数据量。分析查询可分为计算密集型和I/O密集型,且不同类型的查询在不同定价模式下执行成本会更低。本文提出跨定价模式构建更经济执行计划的方法,确保在用户定义的运行时间约束内完成任务。通过实现这些方法,本文生成的跨定价模式执行计划可使工作负载成本降低达56%,单个查询成本降幅最高达90%。同时,云厂商的定价策略也会影响成本优化空间,验证了不同云服务价格下,利用跨定价模式执行工作负载都能够优化成本。
1.1
云端分析工作负载节省成本的必要性
当分析工作负载这项工作迁移至云数据仓库时,用户对节省成本有极大的关注。即使单个工作负载节省少量成本,若频繁运行,长期累积也会产生显著效益。例如,在一个每天运行两次的分析工作负载中,如果每次更新推荐系统可节省140美元,一年即可节省10万美元。
尽管云提供商提供了许多优化数据库性能的工具,但缺乏直接节省成本的机制。因此,用户越来越多地采用特定于设置的解决方案来降低成本,与咨询团队合作,进行数据库调优、关闭未使用资源和优化资源分配。
1.2
云端数据库成本优化
本文旨在探索降低云端分析工作负载成本的机会。对于查询来说,主要消耗I/O和CPU资源,而云数据库的定价模式围绕I/O或CPU时间设计以简化计费。这为通过巧妙调度查询到更经济的定价模式中提供了成本优化空间。
云数据库目前主要有两种定价模式:按计算付费和按字节付费:
按计算付费:用户按计算时间付费(如AWS Redshift)。
按字节付费:用户按扫描数据量付费,与计算时间无关(如Google BigQuery)。
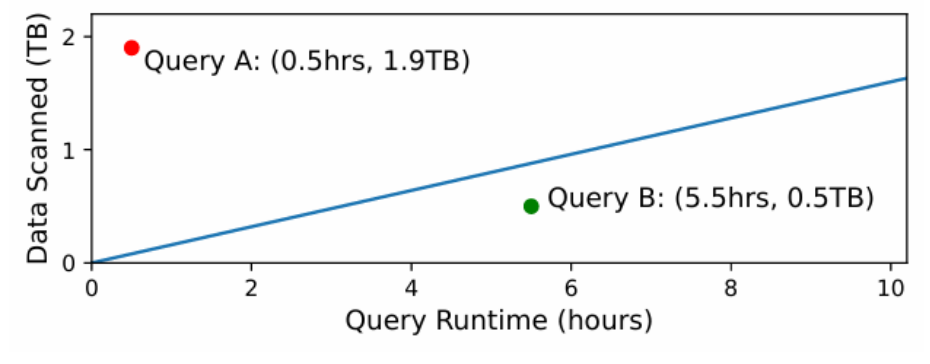
查询运行时间和扫描数据量的定价模式边界
一般来说计算密集型查询在按字节付费模式中执行成本更低,反之I/O密集型查询在按计算付费模式中更具成本优势。如图展示了在查询运行时间和扫描数据量的两种定价模式的成本边界。可以看出,查询A运行速度快但读取1.9TB数据,在按计算付费的数据库中成本更低,因此位于蓝线上方;查询B扫描0.5TB数据但运行较慢,在按字节付费的数据库中成本更低,位于蓝线下方。所有工作负载都有运行时间约束,应该将每个查询分配到最适合的定价模式中执行,使其成本低于在单一云数据库中。
本文对给定分析工作负载(一组查询和数据)和运行时间约束,提出了两种算法以利用上述成本优化机会:
1. 跨查询算法(O1):针对一组查询、数据、运行时间约束和云数据库集合,确定每个查询应在哪个数据库执行以节省成本。
2. 内查询算法(O2):针对单个查询、查询运行时间约束和目标云数据库集合,找到在各数据库中执行的子查询,以在约束内降低查询成本。
这两种互补技术的应用取决于工作负载特点,本文将分别对其进行研究。O1和O2均需处理数据移动、确保云数据库SQL语法兼容性,更重要的是管理数据移动成本,本文在用户与云之间实现了名为Arachne的中间件,该中间件接受工作负载和运行时间约束,执行O1-O2算法,迁移数据,并在约束下生成更经济的执行计划。实验使用Arachne研究运行时间约束下O1-O2对工作负载成本的影响,结果表明,两种计划都有巨大的成本优化空间:跨查询计划在运行时间延长近10小时的情况下,成本降低达57%;另一工作负载的跨查询计划在提速3小时的同时节省55%成本;通过内查询计划,单个查询成本降幅最高达90%。
本文还模拟了不同云服务价格,研究跨云成本优化与运行时间-成本的权衡。结果显示,成本优化对价格变化具有鲁棒性,而异步传输费用可能促进或完全阻碍数据移动。
综上,本文贡献如下:
发现了分析工作负载可通过利用不同云定价模式实现成本优化。
设计了两种算法以挖掘优化机会。
在Arachne系统中实现算法,验证其在实际工作负载中的成本优化效果。
使用主流云数据库评估Arachne,并通过模拟分析市场价格对优化机会的影响。
2.1
云端分析工作负载执行
2.1.1 云数据仓库与定价模式
本文将基础设施即服务(IaaS)与平台即服务(PaaS)区分开来,在PaaS中又进一步区分按计算付费和按字节付费模式来进行比较:
IaaS vs PaaS:在IaaS中,OLAP数据库(如Trino或Apache Hive)需在虚拟机上手动部署和维护,按计算时间计费;而PaaS(如Google BigQuery等)为用户提供直接可用的数据库部署和维护服务,收费高于IaaS。
按计算付费vs按字节付费:两种最常见的PaaS定价模式中,按计算付费按计算资源的使用量和时长计费,按字节付费则按查询扫描的字节数计费,与运行时间无关。
2.1.2 云端成本构成
在云端加载数据并执行工作负载涉及以下成本:
对象存储成本:大多数云数据库从对象存储访问数据,存储数据需付费。
读写成本:对象存储系统对API调用收费。
加载成本:数据加载到机器时需消耗计算资源。
流出成本:数据迁出云端或跨区域传输需按字节付费。
查询处理成本:查询执行费用按字节或计算时间计费。
执行分析工作负载通常包括四个步骤:
1. 从数据源(如本地存储、传感器)收集数据并迁移至云端,产生数据传输和存储成本。
2. 将数据加载到云数据库,产生读写和加载成本。数据跨云迁移会增加成本,算法需考虑这部分开销。
3. 用户支付费用以在云数据库上执行查询。
4. 查询结果返回给用户用于下游任务,可能产生流出成本。
步骤1和4的成本主要取决于输入输出数据,对于特定工作负载基本固定。本文重点关注步骤2和3(涉及云数据库),尤其是降低步骤3成本,必要时考虑步骤2的数据移动成本。
2.2
成本优化机会与挑战
本文希望计算密集型或I/O密集型查询(或子查询),迁移至更经济的定价模式对应的分析系统,可实现成本优化。
Arachne需利用查询运行时间在约束内实现成本优化,但准确估计查询运行时间的方法有限。对于不同的定价模式,Arachne可跟踪使用情况并相应调整定价参数。此外,Arachne需跟踪云价格变化以保持分析准确性。因此,后续还需对Arachne进行优化。
2.3
问题陈述与方法
本文的目标为:给定工作负载查询集、表集、源执行后端和运行时间约束,利用一组执行后端(可能提供不同定价模式),通过跨查询和内查询计划(O1-O2)在约束内实现成本优化。用户可根据工作负载特点选择单独部署O1或O2。
为解决该问题,本文构建了概念验证系统Arachne,实现跨查询和内查询算法,验证通过跨云调度查询和子查询实现成本优化的可行性。Arachne无需修改现有设置(如数据存储位置),自动处理数据移动,并通过离线分析阶段收集查询计划、运行时间和成本数据以优化成本并满足运行时间约束。
3.1
算法设置与目标
首先,考虑包含表集、查询集和运行时间约束的分析工作负载,假设用户初始使用源执行后端,支付表集的存储成本和查询集的执行成本。在给定目标执行后端,算法需要选择查询子集在源后端执行,以在不突破运行时间约束的前提下降低总成本。在Xd执行查询时,需将查询扫描的表从源后端迁移至目标后端,因此算法需考虑迁移成本。
算法输入包括:
工作负载中的表集和查询集。
DEADLINE:可选的工作负载运行时间约束。
源后端和目标后端。
云服务价格:包括对象存储单价、读写操作单价、按计算付费单价和按字节付费单价。
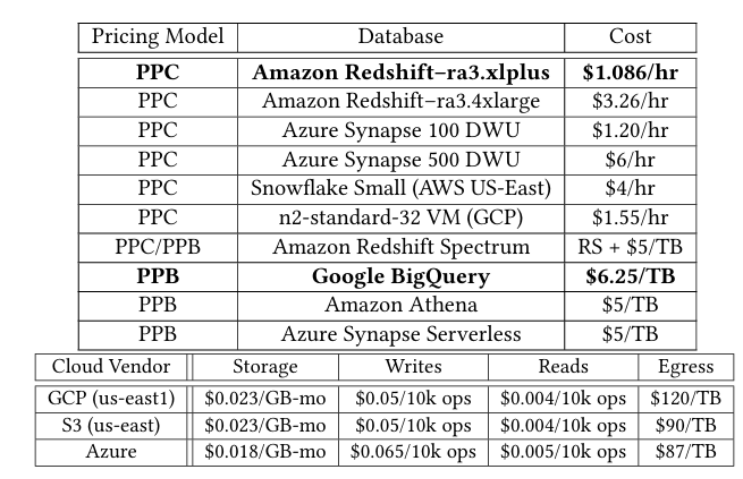
按计算付费(PPC)、按字节付费(PPB)、存储和流出的成本。
e:从源后端到目标后端的数据流出成本。
函数s:用于返回表t的大小(通过云存储API获取)。
函数:分别返回查询q在后端的执行成本和运行时间。
构建二分图模型:
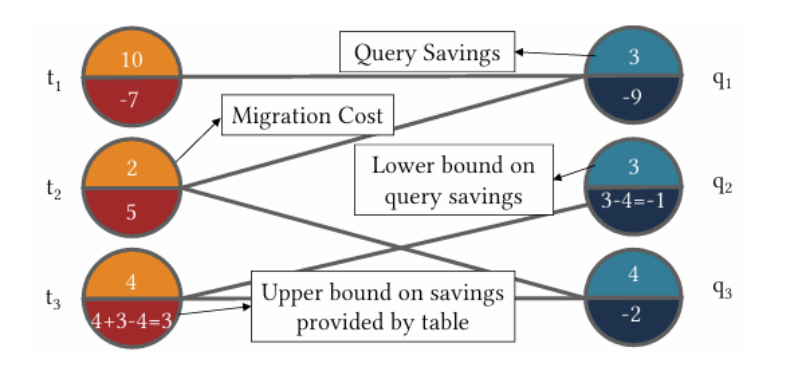
一个包含三个表和三个查询的二分图模型示例
3.2
跨查询算法
3.2.1 贪心策略思路
贪心算法的核心思路是:在每一次迭代中计算迁移每个表到目标后端可实现的最大成本节省(上界),移除节省上界最低的表,并记录当前执行计划的成本和运行时间。若没有表剩余,选择运行时间在约束内的最低成本计划。

跨查询中的贪心算法
3.2.2 跨查询算法解析
上述贪心算法首先调用ReducePlan函数修剪无效节点,记录每次迭代的计划成本和运行时间,最终选择约束DEADLINE内的最低成本计划。
3.2.3 最优算法与复杂度分析
为评估贪心算法的性能,本节:
提出基于最小割的最优跨查询算法。
对比其与贪心算法的运行时复杂度。
验证贪心算法在实际场景中的准确性。
最优解构建:该方法构建了一个容量函数和一个二分图,使用具有无限容量的边通过查询依赖关系连接表和查询。
复杂度分析和实际性能对比:实际应用中,当查询和表数量较大时,最优算法耗时显著高于贪心算法,且随着规模增大差距进一步扩大。
贪心算法准确性:通过72个1TB和2TB工作负载(含IaaS与PaaS场景)的测试,贪心算法在所有案例中均能找到最优解,验证了其在实际应用中的有效性。
4.1
算法设置与目标
内查询算法针对单个查询q和运行时间约束,通过在查询计划中选择切割点,将查询划分为在不同云后端执行的子查询,在考虑迁移成本的前提下降低总成本。查询计划可表示为有向无环图(DAG),其中叶子节点表示基表,边表示数据从上游表流向下游算子。
4.2
识别有效切割点
该算法通过计算每个节点的节省机会,筛选出候选节点,更新其他节点的节省机会下界,以逐步剪枝无效的候选切割点。
4.3
内查询算法

内查询算法
算法首先初始化所有节点的节省机会,筛选出候选节点。按降序迭代评估每个候选节点,计算实际运行时间并更新剩余节点的节省机会,移除无法满足成本约束DEADLINE的节点,最终选择约束内收益最大的切割点或基线方案。
复杂度与最优性:算法每次迭代至少移除一个候选节点,遍历所有潜在有效切割点,确保选择的切割点为约束内最优解,且不会生成成本高于基线的计划。
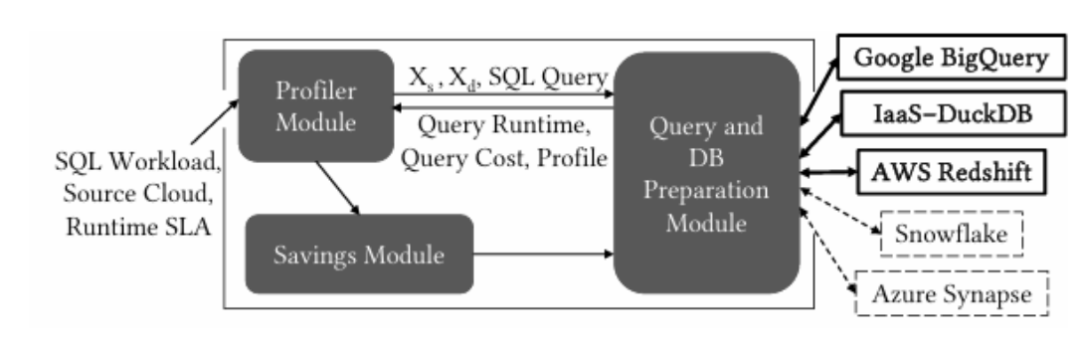
Arachne系统架构
5.1
系统架构概述
在Arachne的架构中,用户首先执行初始化操作,提交未修改的SQL工作负载、数据所在的源执行后端,以及可选的运行时约束。Arachne包括节省模块、分析器模块和准备模块:
1. 节省模块:实现了跨查询和内查询算法。
2. 分析器模块:收集查询成本和查询运行时输入函数,以便节省模块能够在满足运行时约束的前提下节省资金。
3. 准备模块:为目标后端准备查询,具体包括:
确保SQL查询符合执行后端的语法要求。
提交查询以执行。
将数据编排为可移植的开放格式Parquet文件。
在需要时在执行后端之间迁移这些Parquet文件。
执行后端:Arachne支持两个PaaS后端(AWS Redshift和Google BigQuery)因此可以研究按计算付费和按字节付费的定价模型。它还可以在IaaS上部署DuckDB。Arachne也可以轻松扩展以支持新的后端。
最小化基础设施变更:Arachne旨在与现有ETL管道兼容,因此它会在运行时在源后端之间移动数据时产生成本,但对最终用户透明。因此,Arachne在每次工作负载执行时都会移动数据(产生成本),但不需要处理数据不一致问题。但是尽管Arachne最小化了基础设施变更,但它仍然需要配置变更,例如访问云账户。
合规性:从高层次上看,Arachne最好被视为源后端的替代接口。当数据(或查询)由于合规性要求无法在供应商之间移动时,此类数据可以从Arachne中排除,并使用通常的接口运行。
实现细节:Arachne使用Apache Calcite将SQL转换为查询计划并进行查询优化。Arachne使用Apache Arrow对表进行采样;使用Redshift-DataAPI来使用Redshift集群和S3;使用Google Cloud客户端来访问Storage和BigQuery。它在运行时迁移所有数据。
5.2
分析器模块
分析器模块为跨查询和内查询算法提供每个查询的准确运行时、成本和基数信息。此处考虑两种方法:预测和分析。
1. 为什么Arachne不使用预测:现有的估计操作基数、查询成本和查询运行时的方法存在噪声。查询优化器的基数估计仍然不准确。对于给定的查询计划,查询优化器产生的“成本”仅与其他计划的成本具有相对意义,而不涉及绝对的金钱或运行时成本,这使得查询优化器的成本很难作为估计运行时的代理。最后,给定查询计划,估计查询运行时的方法很少,现有的方法通常表现不佳。
2. 分析方法:分析器在每个执行后端执行每个查询,获取其运行时和成本。它还通过DuckDB中的查询分析收集每个查询操作符的输出基数,并为跨查询和内查询算法提供输入。分析比预测更准确,但成本更高。
3. 基于样本的分析:有一种可能是通过在工作负载样本上测量运行时、成本和操作符基数,然后外推到原始工作负载大小来降低分析成本,而不会引入重大误差。然而,分析成本主要存在于按字节付费的定价模型中,并且仅取决于数据大小。分析成本很快就会被工作负载节省所补偿,对于周期性工作负载,可以在工作负载迭代期间收集分析数据,以降低净分析成本。
4. 分配操作符基数:为了提供操作符基数,Arachne在DuckDB中分析查询,因为基数与执行后端无关。然而,DuckDB的物理计划可能与Arachne的内部查询计划不匹配,Arachne无法直接将DuckDB的操作符分析匹配到其查询计划中。因此Arachne将其查询计划写入 SQL,将所有操作符树作为嵌套子查询,因此 DuckDB 的物理计划与Arachne的完全匹配,Arachne可以将基数分配给其内部查询计划中的操作符。
5.3
成本相关实现细节
1. 云间数据传输: Arachne使用Blob存储API实现了一个简单的云传输工具。在GCP n2-standard-32 VM上的工具传输615GB数据集的成本为0.58美元;而在AWS DataSync中,该传输成本为7.69美元。
2. SQL兼容性:Arachne构建并应用文本规则,以确保Arachne生成的SQL与不同的后端语言规则兼容。
3. Calcite查询操作符:Arachne实现了自己的物理节点子类,并使用Calcite库执行启发式优化,如谓词下推、在查询计划中进行切割,并将分析期间收集的基数分配给查询操作符。
在实验中主要回答以下研究问题:
RQ1:跨查询算法是否能节省成本?(O1)
RQ2:内查询算法是否能节省成本?(O2)
RQ3:由云供应商设定的定价如何影响跨查询节省,以及运行时-成本权衡?
RQ4:分析器微基准测试:采样如何影响分析成本和准确性?分析成本多久能被补偿?使用过时的分析结果会减少节省吗?与分析结果相比,噪声运行时估计对节省有何影响?
此外实验还评估了利用更便宜的IaaS对跨查询节省的影响。
6.1
工作负载设置
资源平衡工作负载(Resource Balance Workloads):基于TPC-DS和LDBC基准构建,包含CPU密集型(W-CPU,40%CPU-bound)、混合型(W-Mixed,30%CPU-bound)和I/O密集型(W-IO,20%CPU-bound)三类工作负载,分别包含46-49个查询,覆盖17张表。
读密集型工作负载(Read-Heavy Workloads):基于TPC-DS移除单张表生成24个工作负载(每张含约80个查询),以及LDBC社交网络基准查询,侧重I/O密集型场景。
6.2
实验配置
PaaS后端:Google BigQuery(G,按字节付费,6.25美元/TB)和AWS Redshift(A,按计算付费,1美元/小时,1/4/8节点集群,视为A1/A4/A8)。
数据格式与存储:使用Parquet格式存储数据,并利用Snappy压缩降低迁移成本,BigQuery通过外部表访问存储在S3的Parquet文件。
数据初始存储位置:对于资源平衡工作负载,实验考虑G→A4和A4→G。对于读密集型工作负载,仅考虑G→A1、G→A4、G→A8来评估O1,而评估O2时仅考虑存储在GCP中的数据在DuckDB和BigQuery上的表现。
执行模式:实验模拟批处理工作负载,使用Redshift Data API批量执行查询,确保成本与运行时间测量准确性。
指标:以美元衡量货币成本,以小时衡量运行时。通过检查云供应商账户中的费用明细来验证结果。
6.3
跨查询处理(RQ1)
6.3.1 资源平衡工作负载
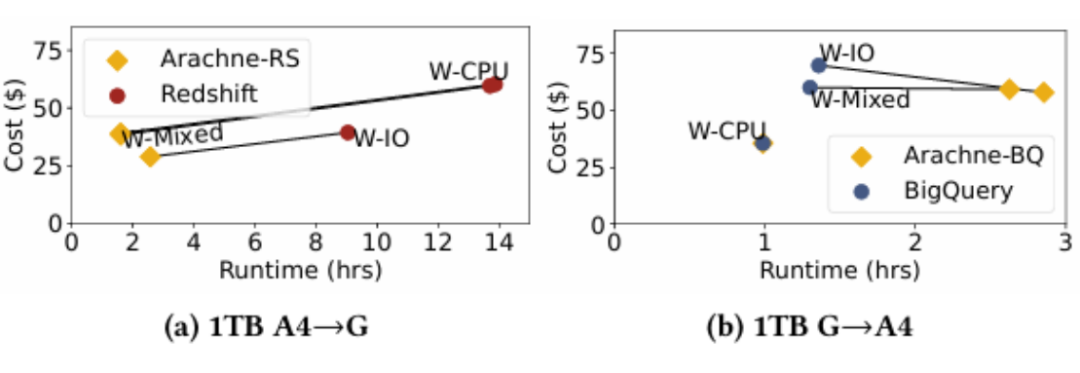
资源平衡工作负载下的成本与运行时间对比
1. 成本与运行时间对比:实验表明,在A4→G(数据从Redshift迁移至BigQuery)场景中,W-CPU、W-Mixed、W-IO 工作负载分别节省了35%、35%、27%成本,且运行时间均在约束内;在G→A4场景中,W-IO和W-Mixed分别节省17%和1.35%。体现了跨查询处理能够节约成本
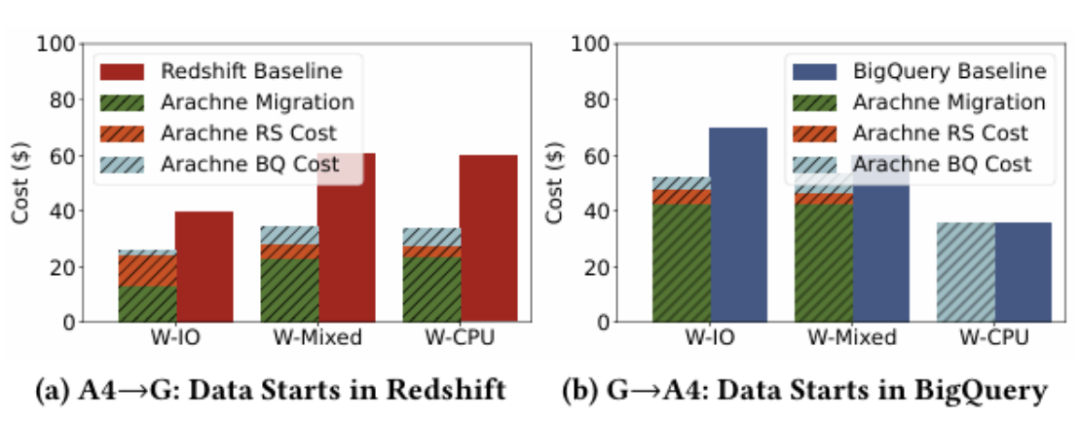
资源平衡工作负载下的成本构成分析
2. 成本构成分析:实验表明,迁移成本主要由流出费用(占90%)和加载成本(5-8%)构成,查询执行成本节省显著超过了迁移开销。
6.3.2 读密集型工作负载
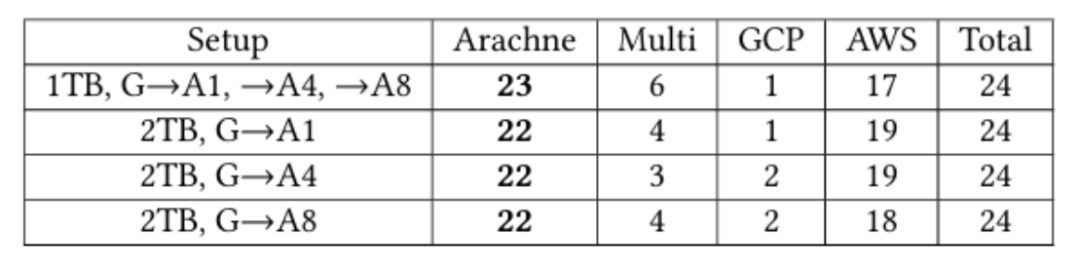
读密集型工作负载下Arachne按1TB和2TB设置查询计划类型
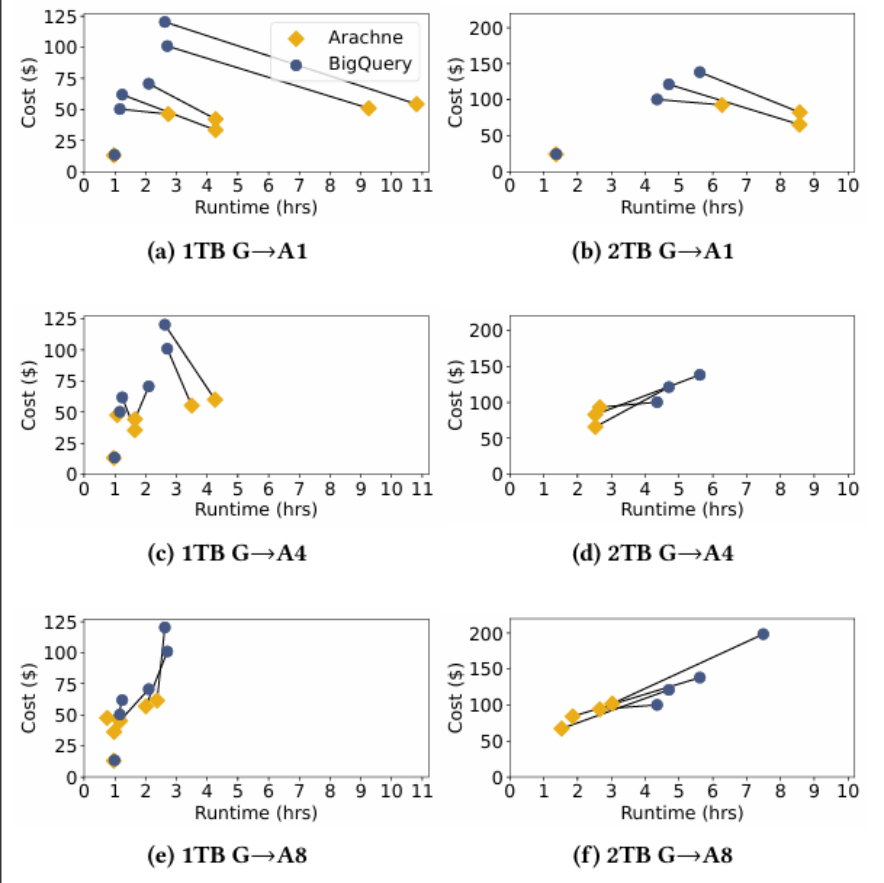
读密集型工作负载下在多云计划时的成本和运行时间结果
1. 多云计划效果:通过实验发现,在1TB和2TB场景下,多云计划在所有工作负载中仅有少数未实现成本优化,多数案例节省35%-50%,最高达57.4%。高流出成本会阻碍数据迁移,但仍有部分工作负载通过多云策略实现优化。同时,更大的Redshift集群可降低加载时间,使Arachne计划更高效。
2. BigQuery内部表:将数据加载到BigQuery是免费的,但会显著增加运行时。对于内部表的查询,BigQuery对每个扫描的表计费一次,即使查询中多次扫描同一表。对于外部表的查询,BigQuery对每个表扫描操作计费,即使多个操作扫描同一表。因此,同一查询使用内部存储时扫描的字节更少,成本更低。实验在G→A1、G→A4、G→A8设置中对内部存储数据运行查跨查询算法,每个设置中有3-5个多云工作负载节省3%-20%,2个节省可忽略不计。
6.3.3 IaaS场景扩展(IaaS+DuckDB)
实验通过在GCP虚拟机部署DuckDB(按计算付费)发现,Arachne在IO密集型工作负载中节省55%成本,验证了利用低成本IaaS的可行性,且无需用户额外部署维护。
6.4
内查询处理(RQ2)
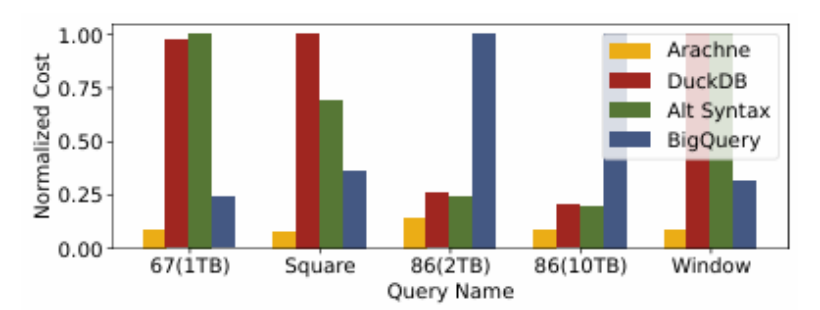
内查询处理的归一化成本
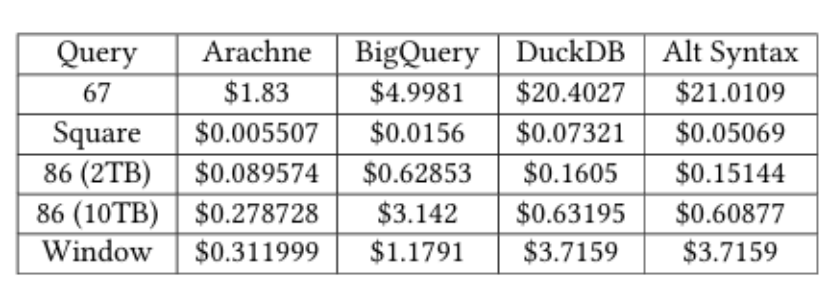
内查询处理的真实成本比较
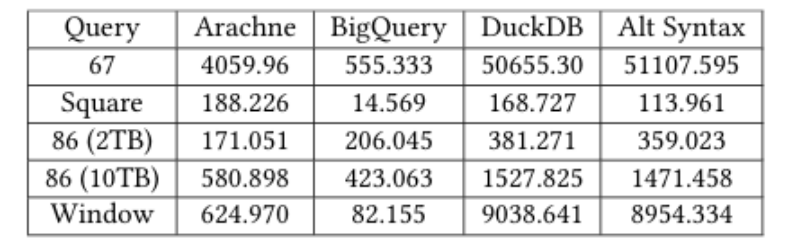
内查询处理的查询时间比较
实验证明,针对TPC-DS和LDBC的5个查询(包括Query67、Window等),内查询计划成本较基线降低2-5倍,显示了O2的成本节省潜力。尽管内查询有时比最快基线运行更慢,但如果查询在对延迟不敏感的周期性工作负载(如夜间分析工作负载)中运行,这种延迟是可接受的。
6.5
云价格模拟(RQ3)

资源平衡工作负载下的跨查询在价格变动的结果
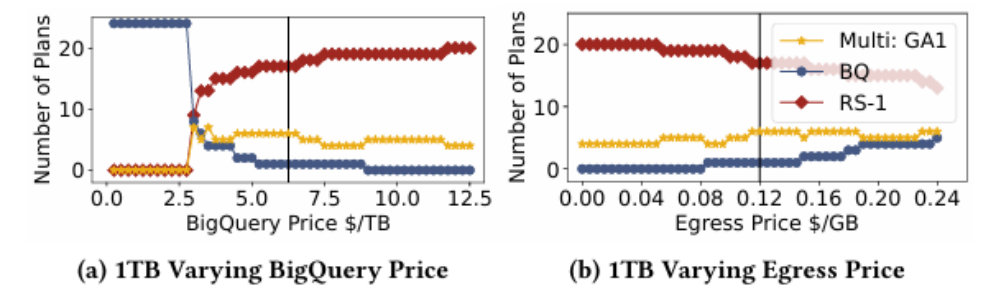
读密集型工作负载下的跨查询在价格变动的结果
1. 价格鲁棒性:实验通过调整BigQuery价格(±40%)和流出费用(±20%)发现,跨查询计划在多数场景下仍能保持30%以上节省,仅极端高流出费用会完全抑制数据迁移。
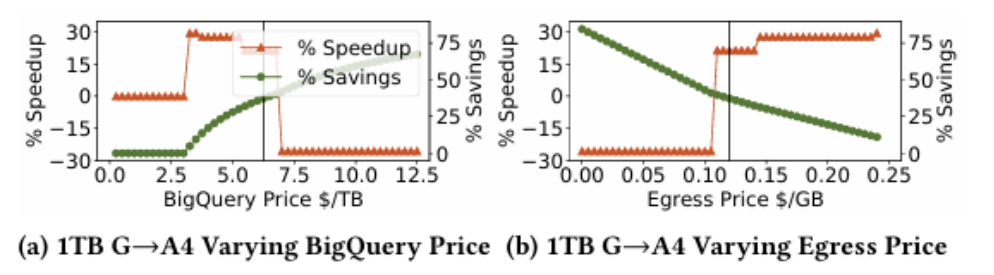
节省百分比和加速比与BigQuery和流出价格的关系
2. 成本-时间权衡:实验结果表明,降低BigQuery价格或流出费用促使更多查询迁移,可能增加运行时间,但同时提升成本节省,这表明云厂商定价策略直接影响用户优化空间。
6.6
分析器微基准测试(RQ4)
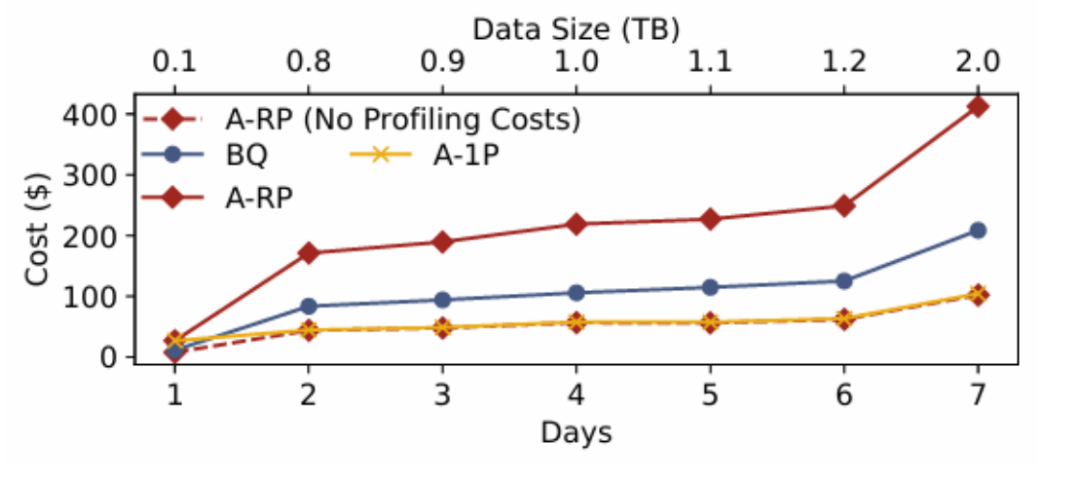
在G→A4下四种执行策略随数据变化的表现。BQ:仅使用BigQuery基线;A-1P:仅在第1天分析,后续使用该分析结果;A-RP:数据变化后立即重新分析,包含分析成本;A-RP(无分析成本):不包含分析成本的A-RP成本。
1. 使用过时的分析的影响:实验表明,使用首日分析数据(A-1P)与每日重新分析(A-RP)的成本差异小于2%,表明轻微数据变化对优化计划影响有限,重新分析仍可有效指导成本优化。
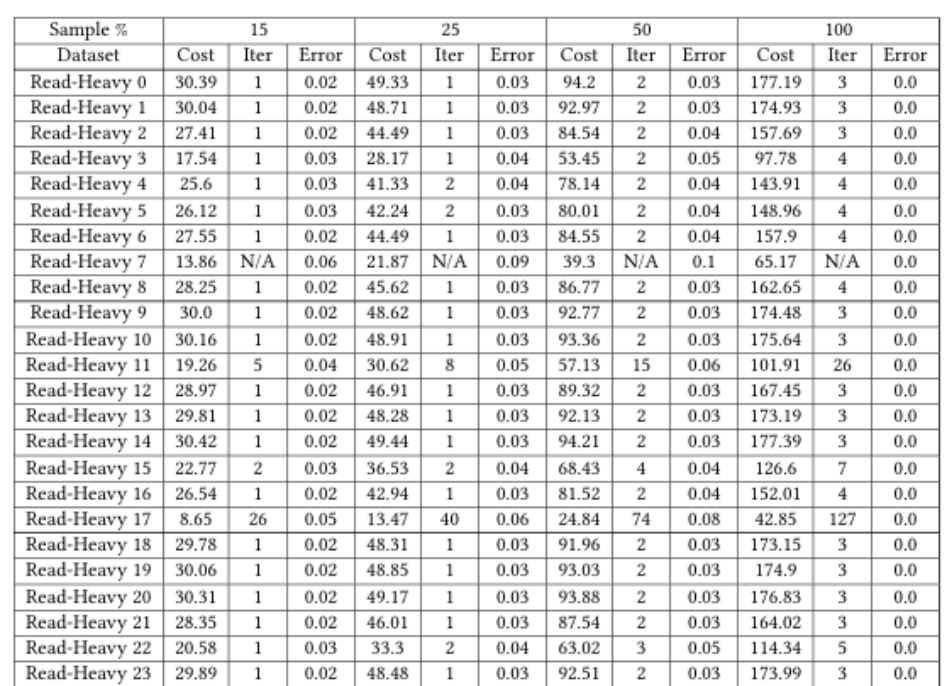
采样分析的效果
2. 采样分析效果:实验说明,15%数据采样的分析误差低于5%,且多数工作负载可在1-2次迭代内收回采样成本,验证了轻量级分析的可行性。
3. 运行时间估计vs真实分析(噪声影响):实验使用1GB TPC-DS数据集创建了2842个训练查询,并在100GB和1TB数据集上运行部分查询以扩展运行时范围。在A1→G设置下,使用运行时估计的跨查询计划比使用分析结果的计划成本高66%;在G→A1设置下,当成本与基线相同时,误差导致成本增加13%。这说明噪声估计使Arachne降低节省幅度,表明运行时估计误差对跨查询节省有不利影响。
7.1
其他云数据库
许多其他云数据库和第三方数据库(如Snowflake、Azure Synapse、Trino)会扫描云存储。这些数据库使用按秒计费(Presto、Hive、SparkSQL)、按字节计费(Athena)或两者结合的定价模式。
7.2
云成本节省
先前关于成本节省的工作主要集中在调度算法、探索不同执行后端的成本来源,或使用S3 Select来加速查询并降低成本。Leis和Kuschewski为云工作负载建立了按秒计费的成本模型。最近的工作还侧重于使用抢占式实例实现节省、最小化网络出口成本,以及为云部署寻找更便宜的配置。
7.3
其他补充优化
其他先前的工作通过语义缓存和分布式查询优化技术、优化数据布局,以及数据仓库中的视图选择和物化来节省成本。这些工作在单一定价模型内节省成本,可以在跨多个定价模型进行分析之前应用于数据库,与本文的研究形成互补。
7.4
云无关查询执行
最近的研究强调需要构建云无关的数据基础设施。伯克利的Sky Computing概述了多云工作负载执行的机会。
7.5
联邦查询执行
一些先前的工作通过使用来自联邦源的元数据、改进联邦查询的查询计划或构建完整的联邦查询系统来提高联邦查询的性能。这些工作不旨在节省成本,并且考虑单个执行后端和多个存储端点,
本文提出并验证了两种云端分析工作负载成本优化方法:跨查询算法和内查询算法,实验通过Arachne系统实现跨定价模式执行计划生成,在真实工作负载中实现最高56%的整体成本节省和单个查询90%的成本优化,并且该优化对云厂商定价具有鲁棒性,且IaaS的引入进一步扩展了优化空间。本工作希望将促进云供应商之间的竞争,降低价格并让用户受益。
论文解读联系人:
刘思源
13691032906(微信同号)
liusiyuan@caict.ac.cn





