





简介
本文将介绍如何根据小说内容进行相似度计算
01
代码实现-基于小说内容推荐
(1)准备小说数据

(2)代码实现
import com.java.similarty.IKUtilsimport org.apache.spark.ml.feature.{HashingTF, IDF, Tokenizer}import org.apache.spark.mllib.linalg.Vectorsimport org.apache.spark.mllib.linalg.distributed.{CoordinateMatrix, IndexedRow, IndexedRowMatrix}import org.apache.spark.sql.types.{DoubleType, LongType, StringType, StructField, StructType}import org.apache.spark.sql.{Row, SparkSession}object NovelDFSimilar {def main(args: Array[String]): Unit = {Logger.getLogger("org.apache.spark").setLevel(Level.WARN)Logger.getLogger("org.apache.eclipse.jetty.server").setLevel(Level.OFF)val spark = SparkSession.builder().master("local[5]").appName(this.getClass.getName).getOrCreate()val sc = spark.sparkContextval fileRdd = sc.wholeTextFiles("/Users/zhangjingyu/Desktop/ES/novel_doc/")val structFieldNovel = Array(StructField("novelName",StringType ,true),StructField("novelContent", StringType,true))val structTypeNovel = StructType(structFieldNovel)val ikwordRdd = fileRdd.map(eachNovel => {val novelName = eachNovel._1.split("/").last.replace(".txt","")val novelContent = IKUtils.ikAnalyzer(eachNovel._2)Row(novelName , novelContent)})val novelDF = spark.createDataFrame(ikwordRdd , structTypeNovel)val tokenizer = new Tokenizer().setInputCol("novelContent").setOutputCol("words")val wordsData = tokenizer.transform(novelDF)val hashModel = new HashingTF().setInputCol("words").setOutputCol("rawFeatures").setNumFeatures(Math.pow(2,20).toInt)val featurizedData = hashModel.transform(wordsData)val idf = new IDF().setInputCol("rawFeatures").setOutputCol("features")val idfModel = idf.fit(featurizedData)val tfidfData = idfModel.transform(featurizedData).select("novelName","features")//这里使用.zipWithIndex自动生成序号(从0开始)val colSimilar : CoordinateMatrix = new IndexedRowMatrix(tfidfData.rdd.map{case Row(_,v : org.apache.spark.ml.linalg.Vector) => (Vectors.fromML(v))}.zipWithIndex.map{case (v , i ) => IndexedRow(i , v)}).toCoordinateMatrix().transpose().toRowMatrix().columnSimilarities()val colSimlilarRow = colSimilar.entries.map(line => Row(line.i , line.j , line.value))val structFieldDF = Array(StructField("id", LongType,true),StructField("similar_id", LongType,true),StructField("score", DoubleType,true))val structType = StructType(structFieldDF)val result = spark.createDataFrame(colSimlilarRow , structType)result.sort(result("score").desc).show(false)result.write.format("jdbc").option("url","jdbc:mysql://bigdata-pro-m01.kfk.com:3306/db_novel").option("dbtable","novel_similar_df").option("user","root").option("password","12345678").option("driver","com.mysql.jdbc.Driver").save()}}
(3)打印结果:
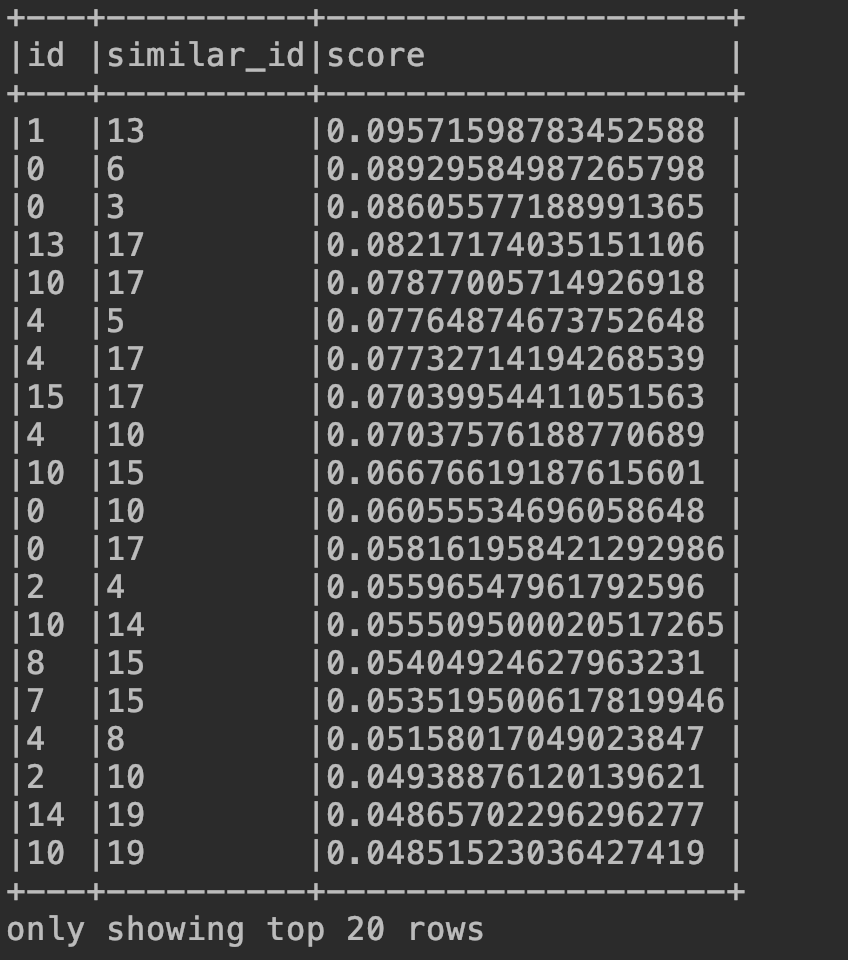
可以看到,score的分数越高,两本小说的内容相似度越接近。

扫描二维码 关注我们
微信号 : BIGDT_IN
文章转载自数据信息化,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
