





点击蓝字 关注我们

Flink之DataSet迭代计算(十二)
01
迭代计算的分类及原理
迭代计算在批量数据处理过程中的应用非常广泛,如常用的机器学习算法Kmeans、逻辑回归以及图形计算等,都会用到迭代计算。DataSet API对迭代计算功能的支持相对比较完善,在性能上比较其他分布式计算框架也具有非常高的优势。目前Flink中的迭代计算种类有两种模式,分别是Bulk Iteration(全量迭代计算)和Delt Iteration(增量迭代计算)
什么是迭代运算?
所谓迭代运算,就是给定一个初值,用所给的算法公式计算初值得到一个中间结果,然后将中间结果作为输入参数进行反复计算,在满足一定条件的时候得到计算结果。

02
全量迭代计算
Bulk Iterate
这种迭代方式称为全量迭代,它会将整个数据输入,经过一定的迭代次数。
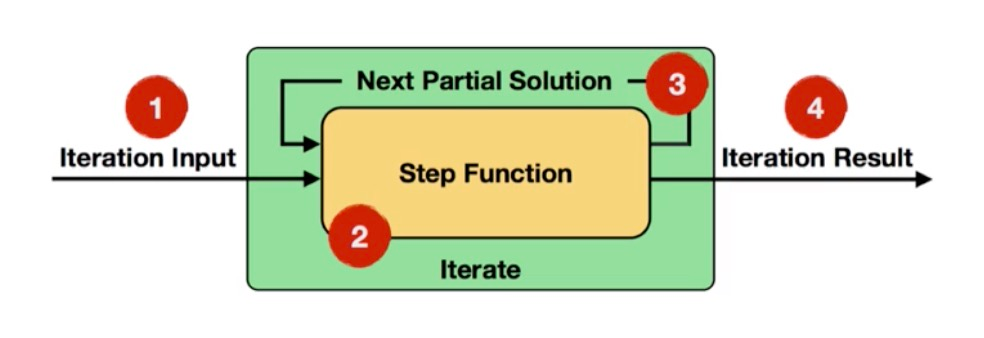
全量迭代计算,一共有几个步骤:
■ 首先初始化数据,可以通过从DataSource算子中获取,也可以从其他转化Operators中接入。
■ 其次定义Step Function,并在每一步迭代过程使用Step Function,结合数据集以及上一次迭代计算的Solution数据集,进行本次迭代计算。
■ 每一次迭代过程中Step Function输出的结果,被称为Next Partital Solution数据集,该结果会作为下一次迭代计算的输入数据集。
■ 最后一次迭代计算的结果输出,可以通过DataSink输出,或者接入到下一个Operators中。
迭代终止的条件有两种,分别为达到最大迭代次数或者符合自定义聚合器收敛条件:
■ 最大迭代次数:指定迭代的最大次数,当计算次数超过该设定值时,终止迭代。
■ 自定义收敛条件:用户自定义的聚合器和收敛条件,例如终止条件设定为当Sum统计结果小于零则终止,否则继续迭代。
03
全量迭代计算-实例分析
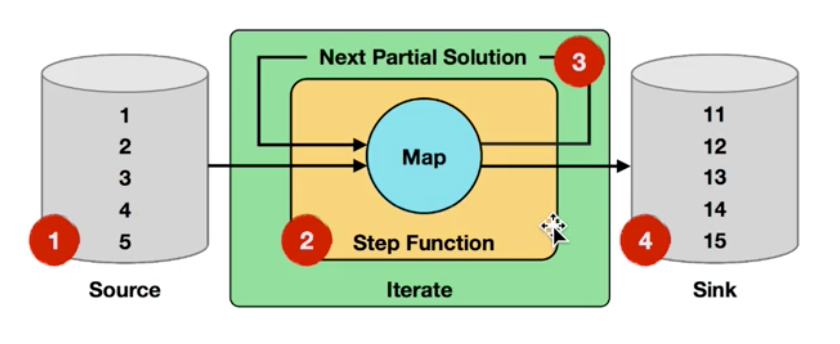
迭代输入:初始输入从1到5五个数字
Step函数: Map()函数对五个数字地迭代+ 1 (即i=i+1)
Solution:step函数的输出作为Map的输入
Sink:对每个数字迭代十次之后,结果为11, 12 , 13, 14, 15

04
全量迭代计算-实例分析
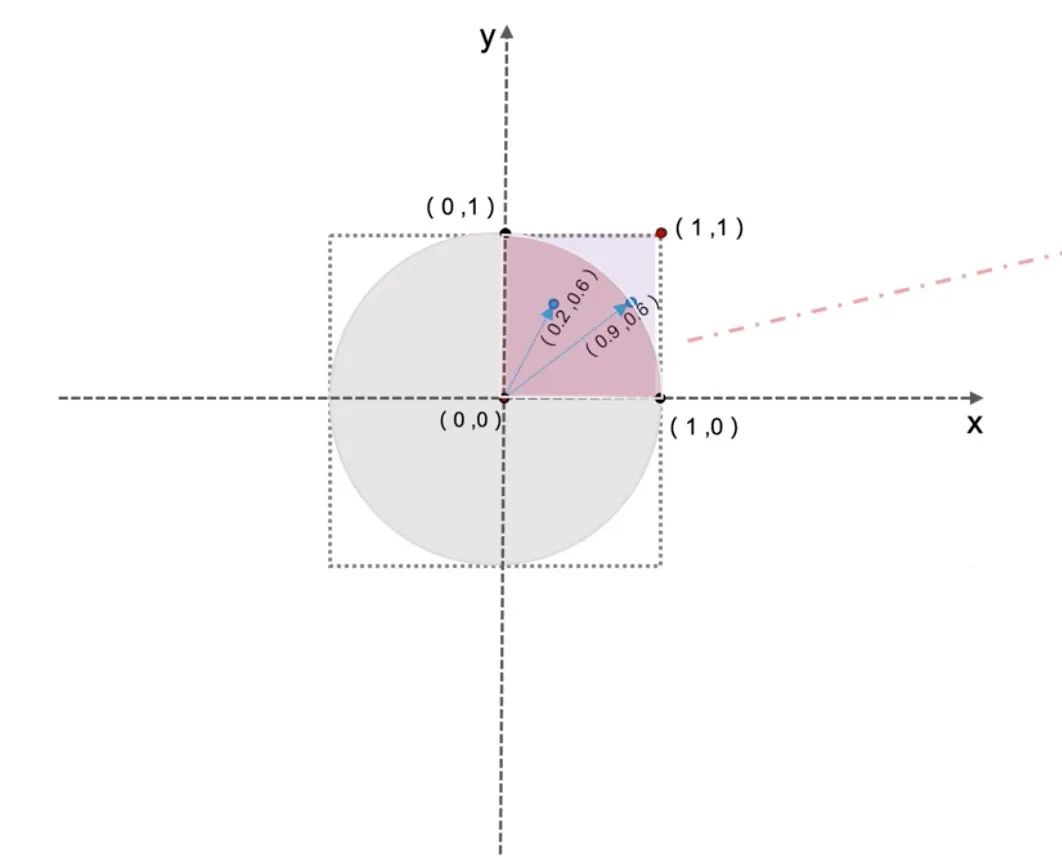
蒙洛卡特思想:求兀的值
■ 圆的面积S=πr^2,(r= 1),故S=π
■ 计算出圆的面积也就计算出圆周率
■ 在边长为1的正方形中计算出圆的四分之一扇形面积,最后乘以4就得到圆的面积
■ 计算扇形的面积,我们可根据概率的方法,计算出正方形中有多少个点落在了扇形中,其实这个很简单,我们只要计算√x^2+ y^2 <=1 (即点到圆心的距离)就可以了
■ 圆周率=扇形中的点数/迭代点数* 4
import org.apache.flink.api.common.functions.MapFunction;import org.apache.flink.api.java.DataSet;import org.apache.flink.api.java.ExecutionEnvironment;import org.apache.flink.api.java.operators.IterativeDataSet;public class Pi_BulkIteration {public static void main(String[] args) throws Exception {ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();IterativeDataSet<Integer> initial = env.fromElements(0).iterate(10000);DataSet<Integer> interation = initial.map(new MapFunction<Integer, Integer>() {@Overridepublic Integer map(Integer i) throws Exception {double x = Math.random();double y = Math.random();return i + ((x * x + y * y < 1) ? 1 : 0);}});DataSet<Integer> count = initial.closeWith(interation);count.map(new MapFunction<Integer, Double>() {@Overridepublic Double map(Integer count) throws Exception {return count / (double) 10000 * 4;}}).print();}}
05
增量迭代计算
增量迭代是通过部分计算取代全量计算,在计算过程中会将数据集分为热点数据和非热点数据集,每次迭代计算会针对热点数据展开,这种模式适合用于数据量比较大的计算场景,不需要对全部的数据集进行计算,所以在性能和速度上都会有很大的提升。

扫描二维码
关注我们
微信号 : BIGDT_IN
