





点击蓝字 关注我们

Flink应用场景及组建架构(二)
01
应用场景
实际生产的场景,如金融交易数据、互联网订单数据、GPS定位数据、传感器信号、启动终端生产的数据、通讯信号数据等,以及我们熟悉的网络流量监控、服务器产生的日志数据,这些数据最大的共同点就是实时从不同的数据源产生,然后在传输到下游的分析系统。针对这些数据类型主要包括:
* 实时智能推算
智能推算会根据用户历史的购买行为,通过推荐算法训练模型,预测用户未来可能会购买的物品。
* 复杂事件处理
对于复杂事件处理,比较常见的案例主要集中在工业领域,例如对车载传感器、机械设备等实时检测,这些业务类型通常数据量都非常大,且对数据处理的时效性要求非常高。通过利用Flink提供的CEP(复杂事件处理)进行事情模式的抽取,同时应用Flink的SQL进行事件数据的转换,在流式系统构建实时规则引擎,一旦事件触发报警规则,便立即将告警结果传输至下游通知系统,从而实现对设备故障快速预警监测,车辆状态监控等。
* 实时欺诈检测
在金融领域的业务中,常常出现各种类型的欺诈行为,例如信用卡欺诈、信贷申请欺诈等。我们可以运用Flink流式计算能够在毫秒内就完成对欺诈判断行为指标的计算,然后实时对交易流水进行规则判断或者模型预测,这样一旦检测出交易存在欺诈嫌疑,则直接对交易进行实时拦截。
* 实时数据仓库与ETL
结合离线数据仓库,通过利用流计算的优势,补充和优化离线数据仓库。通过有状态的流式计算,高效快速的处理企业需要的统计结果。
* 流数据分析
实时计算各类数据指标,并利用实时结果及时调整在线系统相关策略,在各类内容投放、无线智能推送领域有大量的应用。

02
Flink组件架构
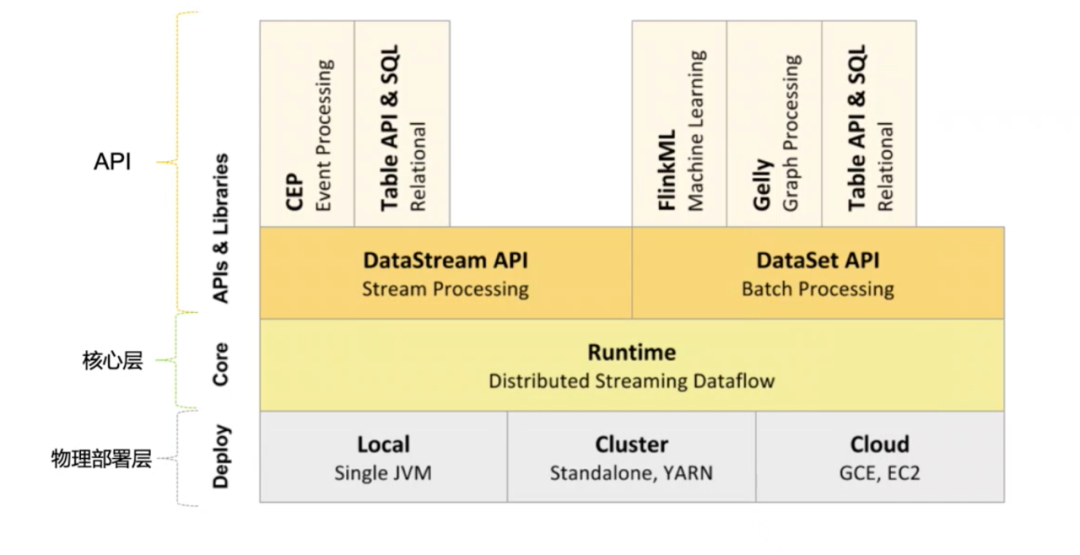
* API&Libraries层
作为分布式数据处理框架,Flink同时提供了支撑流计算和批计算的接口,同时在此基础上抽象出不同的应用类型的组件库,如基于流处理的CEP (复杂事件处理库)、 SQL&Table库和基于批处理的FlinkML (机器学习库)、Gelly (图形处理库)。API层包括构建流计算应用的DataStream API和批计算应用的DataSet API,两者都提供给用户丰富的数据处理高级API,例如Map、FlatMap操作等,同时也提供比较低级的ProcessFunction API,用户可以直接操作状态和时间等底层数据。
* 核心层
该层主要负责对上层不同接口提供基础服务,也是Flink分布式计算框架的核心实现层,支持分布式Stream作业的执行、JobGraph到ExecutionGraph的映射转换、任务调度等。将DataStream和DataSet转成统一的可执行的Task Operator,达到在流式引擎下同时处理批量计算和流式计算的目的。
* 物理部署层
目前Flink支持多种模式:本地、集群(Standalone/YARN) 、云(GCE谷歌/EC2亚马逊)、Kubenetes等。

扫描二维码
关注我们
微信号 : BIGDT_IN
