





1.引言
近年来,大型语言模型(LLMs)的蓬勃发展引人注目。它们在理解和生成多领域、多任务的人类语言方面展现出前所未有的能力。然而,尽管进展迅速,LLM在实际部署中的主要瓶颈源于自回归解码机制导致的推理延迟——生成n个标记需要n次顺序执行,这一过程耗时且难以充分利用计算资源。1
为应对这一挑战,近期研究12 提出了推测解码加速方法。该方法通过草稿模型采样候选标记,再由目标模型并行验证。若某标记验证失败,其后续标记将被拒绝以保证输出分布无偏。因此,推测解码的性能与预测标记的接受率密切相关。

图表 1 不同的预测结构示意图
为提升接受率,多项研究探索了树状结构。图表1展示了基础方法。Spectr3 通过DraftSelection算法实现多候选采样(B);SpecInfer4 构建带可学习分支数的标记树;Medusa5 基于草稿模型概率构建树结构;Sequoia6 则通过动态规划优化树结构(C)。然而,这些方法的共同局限在于依赖固定的建树模式,导致树规模扩展时接受率下降,由此引出一个关键问题:如何为推测解码寻找近似最优的标记树结构?基于具有较高草稿概率的预测标记在统计上具有更高的接受率的假设,我们建立了接受率与草稿分布的关联。
初步实验验证了这一发现(图表2)。基于此,我们提出DySpec方法,通过贪心搜索策略动态扩展标记树以最大化预测序列期望长度。相较于固定结构,动态树可提升接受率与加速效果。
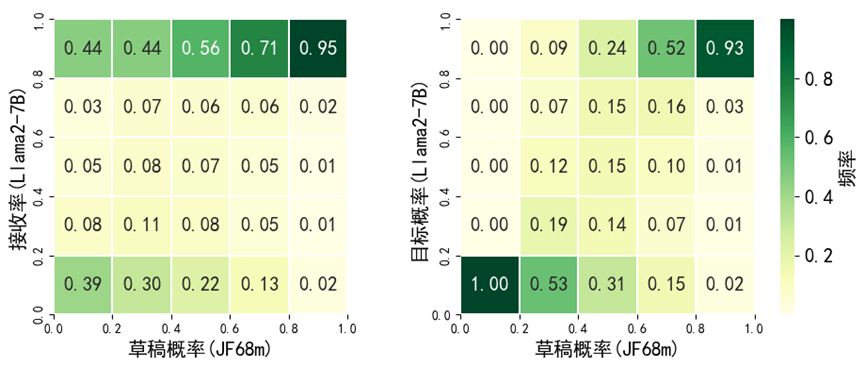
图表 2 草稿分布和目标分布/接收率之间的关系
2.连接草稿分布与接受率
在验证阶段,样本标记x的接受概率由给出。我们现推导草稿分布与接受率之间的关联如下:
由于草稿分布作为目标分布的近似,两个分布不应相距过"远"。不失一般性,我们假设草稿分布D与目标分布T的KL散度受常数c约束,即
为满足此约束,不应与显著偏离。然而,对于具有较大草稿概率的标记,不能过小,否则会对产生显著贡献。另一方面,低的标记对散度影响较小,允许更大波动。上述分析表明:统计意义上,具有较高草稿概率的预测标记对应更高的目标概率和接受率。
我们通过初步实验进一步验证假设。如图标2(右)所示,实际场景中草稿分布与目标分布呈现强相关性。更重要的是,图标2 (左)显示,在相同草稿概率下,接受率分布呈现二项分布特征。当草稿概率增大时,预测标记被接受的可能性显著提升。这些观察为前述论断提供了有力的实证支持。这启发我们设计动态标记树构建算法——优先探索具有更高草稿概率的子树,因其在后续验证阶段更可能被接受。
3.方法
在固定推测预算(即每次验证的令牌数量)下,最优令牌树能产生最高的接受率。实际上,在验证前目标分布未知的情况下,寻找最优树是不可行的。然而根据假设,我们可以将原始问题转化为以下子问题。
给定推测令牌树结构、采样方式、草稿模型输出分布和对应目标模型输出分布,我们可以计算推测解码验证次数的期望值。对于令牌树中的每个节点t_i,其草稿分布记为,相关目标分布记为。
假设节点t_i具有祖先节点和同层前序兄弟节点,则该节点被验证的概率可表示为。
在推测解码中,对于具有草稿概率和目标概率的令牌,其接受概率为(记为)。因此,节点被验证的概率为。该节点对总接受令牌数期望的贡献为。
推测令牌树的总接受令牌数期望为:
。
虽然可以通过期望接受率构建最优令牌树,但仍存在两个问题: 生成令牌树时无法预知目标概率来计算草稿令牌t_i采样自草稿分布,只能决定采样次数而无法选择具体令牌,否则会影响令牌树的保留概率
针对问题1,根据假设,我们使用草稿分布估计接受率。对于问题2,我们仅根据估计值决定是否采样。通过动态选择具有最大估计值的可扩展节点,DySpec能生成最优令牌树。
与常规方法不同,DySpec根据目标模型的验证结果动态决定采样次数。具体流程如下:
a. 使用最大堆维护可扩展节点(初始为前缀的根节点)
b. 每次选择估计值最高的节点进行采样
c. 根据采样结果更新令牌树:
若节点被拒绝,记录失败概率并更新兄弟节点估计值 若节点被接受,扩展子节点并更新后续采样估计值

算法 1 固定大小的构树
该过程通过算法1实现,时间复杂度为。图标3展示了令牌树扩展示例:当预测"A Wall"时,系统优先扩展接受概率更高的"Street"分支。
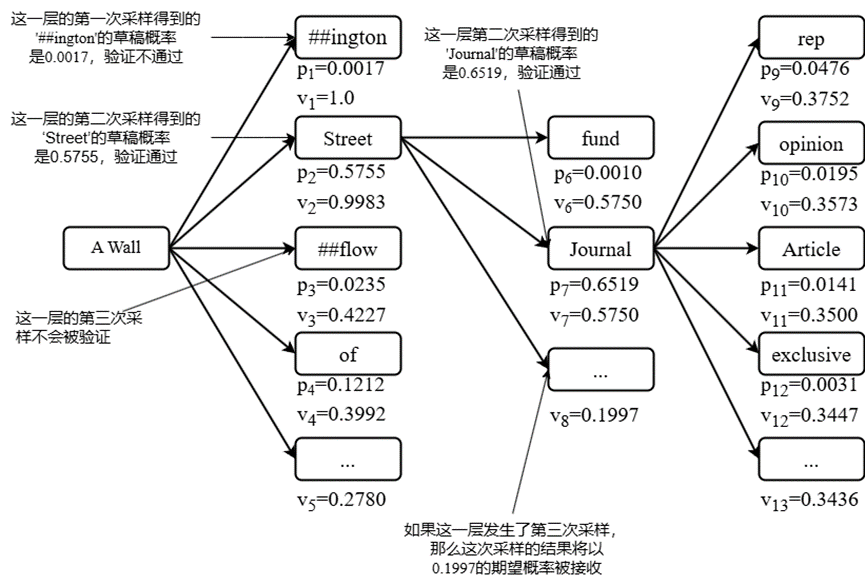
图表 3预测令牌树示例
设令牌树规模为N,深度为。贪心扩展法的时间复杂度为,其中和分别表示草稿模型和目标模型的推理延迟。生成单令牌的延迟为,其中为平均接受令牌数。
为降低延迟,我们引入阈值C进行层级式构建:预先确定阈值,选择估计值高于C的令牌构建层级式令牌树。该方法在略微影响接受率的情况下,将延迟优化为(典型场景)。伪代码见算法2,该方法通过减少草稿模型调用次数实现显著加速。

算法 2阈值控制的令牌树构建算法
4.实验
我们基于Llama模型实现了DySpec系统。使用JackFram/Llama68M(JF68M)和Llama2-7B作为草稿模型,Llama2-7B、Llama2-13B、Llama2-70B7 作为目标模型。我们在多个不同规模和特性的数据集上进行评估,包括C4(en)8 、OpenWebText9 、CNN DailyMail10 、GSM8k11 和MT-bench12 。
为公平比较,我们遵循Sequoia的设置,使用前128个token作为固定提示并生成128个token作为补全结果。在不同目标温度下评估方法,草稿模型温度设为0.6。所有实验在配备NVIDIA A100 40GB GPU和32核CPU的计算节点上进行。
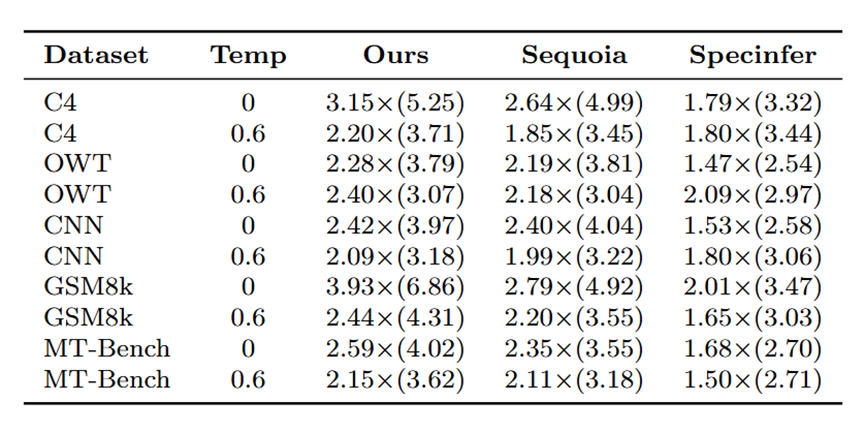
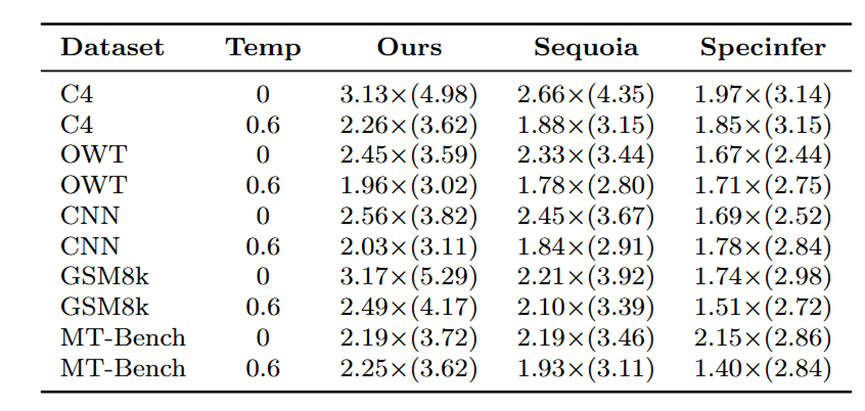
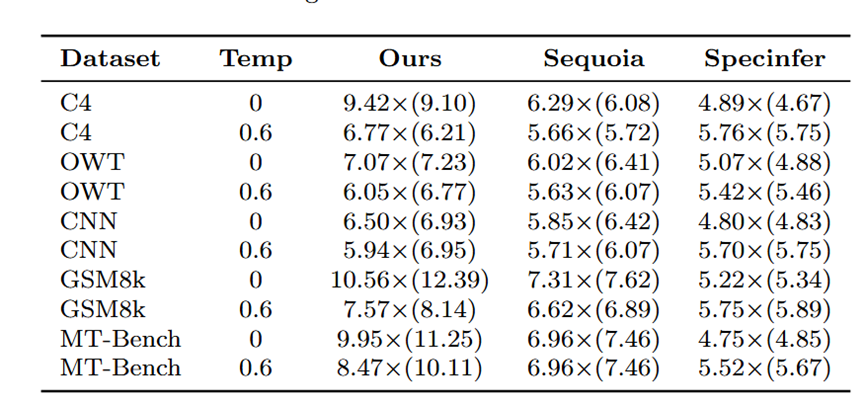
表格1和表格2分别展示了JF68M/Llama2-7B和JF68M/Llama2-13B组合的实验结果,其中最大令牌树尺寸设为64。草稿模型采用CUDA图技术捕获128至258区间内129种输入长度以加速推理。实验表明, DySpec在不同数据分布和生成温度下均优于Sequoia和Specinfer,单次解码接受token数更多。表中数值表示生成单token的平均耗时(秒),括号内为单次验证接受token数。
表格 1
表格 2
对于Llama2-70B等大型目标模型,我们采用CPU卸载策略。选择Llama2-7B作为草稿模型时,尽管存在CPU-GPU数据同步开销,原生实现的CPU卸载模型推理时间约15秒/步,采用权重加载优化(借鉴Sequoia)后仍需要约5秒/步。此时比约为。由于不同长度序列捕获的显存开销过大,本场景未使用CUDA图技术。
在最大令牌树尺寸64的设置下, DySpec相比自回归生成实现了最大单次推理接受9.1个令牌和最大9.4倍的推理加速,如表格3所示,其性能优于现有最优方法。
表格 3
5.结论
我们提出了DySpec,一种通过动态令牌树结构进行采样的快速推测解码算法。基于草稿概率与接受率之间的关联性,我们采用贪心策略动态扩展令牌树以最大化预测生成的预期长度。实证结果表明,DySpec在不同数据集和生成温度下均能稳定提升接受率,验证了其有效性和可扩展性。具体而言,在Llama2-70B模型(temperature=0)上,DySpec实现了最大单次推理接受9.1个令牌和最大9.4倍的推理加速。
参考文献
Chen, Charlie, et al. "Accelerating large language model decoding with speculative sampling." arXiv preprint arXiv:2302.01318 (2023).
Leviathan, Yaniv, Matan Kalman, and Yossi Matias. "Fast inference from transformers via speculative decoding." International Conference on Machine Learning. PMLR, 2023.
Sun, Ziteng, et al. "Spectr: Fast speculative decoding via optimal transport." Advances in Neural Information Processing Systems 36 (2023): 30222-30242.
Miao, Xupeng, et al. "Specinfer: Accelerating generative large language model serving with tree-based speculative inference and verification." arXiv preprint arXiv:2305.09781 (2023).
Cai, Tianle, et al. "Medusa: Simple llm inference acceleration framework with multiple decoding heads." arXiv preprint arXiv:2401.10774 (2024).
Chen, Zhuoming, et al. "Sequoia: Scalable, robust, and hardware-aware speculative decoding." arXiv preprint arXiv:2402.12374 (2024).
Touvron, Hugo, et al. "Llama: Open and efficient foundation language models." arXiv preprint arXiv:2302.13971 (2023).
Raffel, Colin, et al. "Exploring the limits of transfer learning with a unified text-to-text transformer." Journal of machine learning research 21.140 (2020): 1-67.
GOKASLAN A, COHEN V. OpenWebText Corpus[Z].http://Skylion007.github.io/OpenWebTextCorpus. 2019.
Nallapati, Ramesh, et al. "Abstractive text summarization using sequence-to-sequence rnns and beyond." arXiv preprint arXiv:1602.06023 (2016).
Cobbe, Karl, et al. "Training verifiers to solve math word problems." arXiv preprint arXiv:2110.14168 (2021).
Zheng, Lianmin, et al. "Judging llm-as-a-judge with mt-bench and chatbot arena." Advances in Neural Information Processing Systems 36 (2023): 46595-46623.


欢迎关注北京大学王选计算机研究所数据管理实验室微信公众号“图谱学苑“
实验室官网:https://mod.wict.pku.edu.cn/
微信社区群:请回复“社区”获取
gStore官网:https://www.gstore.cn/
GitHub:https://github.com/pkumod/gStore
Gitee:https://gitee.com/PKUMOD/gStore

