




1 问题与现象
有一个刚搭建的Oracle DataGuard,主库值RAC环境,备库是单机,备库启动归档应用后,主库上一个节点上的更新的数据在备库上能查到,另一个节点上更新的数据在备库上很长时间都查不到。主库日志在备库上的接收和应用的情况可以从备库的告警日志中查到,这个备库告警日志的最后几行如下
Archived Log entry 14 added for thread 2 sequence 59 ID 0x66fe5842 dest 1:
Media Recovery Log +DATA/arch/2_59_1200175816.dbf
Media Recovery Log +DATA/arch/1_65_1200175816.dbf
Media Recovery Log +DATA/arch/1_66_1200175816.dbf
Media Recovery Waiting for thread 1 sequence 67 (in transit)
Recovery of Online Redo Log: Thread 1 Group 5 Seq 67 Reading mem 0
Mem# 0: +DATA/orcldg/onlinelog/group_5.264.1202137561
Media Recovery Waiting for thread 2 sequence 60
RFS[6]: Selected log 6 for thread 1 sequence 68 dbid 1727956549 branch 1200175816
Archived Log entry 15 added for thread 1 sequence 67 ID 0x66fe5842 dest 1:
Mon May 26 15:21:56 2025
RFS[6]: Selected log 5 for thread 1 sequence 69 dbid 1727956549 branch 1200175816
Mon May 26 15:21:56 2025
Archived Log entry 16 added for thread 1 sequence 68 ID 0x66fe5842 dest 1:
从这个告警日志可以看出,备库上接收到并应用了主库两个节点的归档日志,不同的是一个节点的日志应用处于real-time apply状态—Media Recovery Waiting for thread 1 sequence 67(in transit),另一个节点则不是—Media Recovery Waiting for thread 2 sequence 60,正常情况下主库两个节点(线程)这个状态应该是一致的。这个问题应该怎么分析呢?首先要了解一下Oracle DataGuard的原理,什么是real-time apply,real-time apply的前提或条件是什么。下面的分析过程就先从这几个方面着手。
2 分析过程
2.1 Oracle DataGuard的架构
理解Oracle DataGuard结构从它的架构图来着手比较直观,下面的架构图来自官网
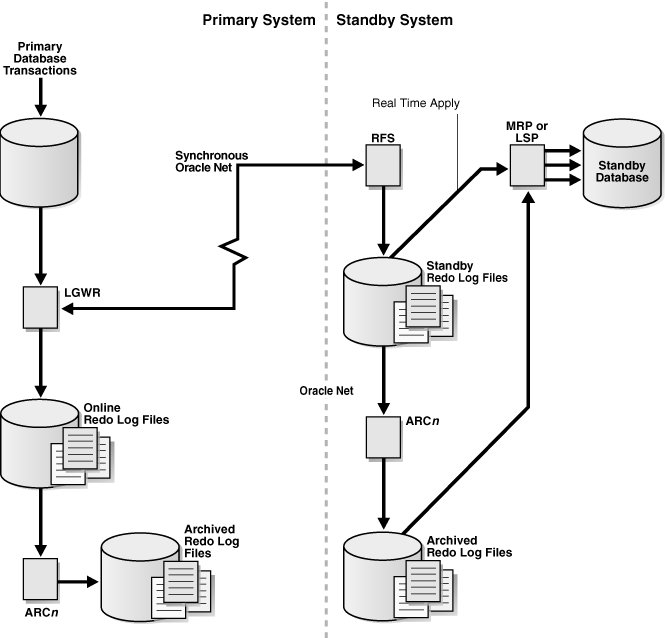
从架构图可以看出,Oracle DataGuard 是由主库(Primary Database)与一个或多个备库(Standby Database)组成的灾备架构。
主库处理事务并生成重做日志(Redo Log),备库接收并应用这些日志,确保数据同步。参与到这个过程的进程在主库上有LGWR(日志写)进程,LNS(Log Network进程),ARCH(归档进程),备库上有RFS(Remote File Server)进程,MRP(Managed Recovery Process)进程,ARCH(归档进程)。
DataGuard的日志传输过程的起点是主库生成重做日志(Redo Log)。当主库事务提交时,日志写入进程(LGWR)根据配置的传输模式(同步SYNC或异步ASYNC)将日志数据发送至备库:
- 同步模式(SYNC):LGWR通过LNS(Log Network Server)进程将日志实时传输至备库的RFS(Remote File Server)进程,并等待备库确认日志落盘后,主库事务才完成提交,确保零数据丢失。
- 异步模式(ASYNC):LGWR优先响应主库事务提交,通过LNS(Log Network Server)进程将日志实时传输至备库的RFS(Remote File Server)进程,传输延迟不会影响主库事务的提交。
备库端的RFS进程接收日志后,将其写入备用重做日志文件(Standby Redo Log, SRL),随后由MRP(Managed Recovery Process)进程按顺序解析并应用日志中的物理块变更,使备库数据与主库保持严格一致。整个过程通过Oracle Net Services实现网络通信,日志传输与应用遵循主库的SCN(系统变更号)顺序,保障数据完整性与恢复一致性。
2.2 real-time apply(redo实时应用)
在缺省情况下,应用服务(MRP进程)在备用重做日志归档后才在备库应用它包含的重做记录。有的不十分活跃的数据库可能要几个小时才切换一次归档,这时主库数据同步到备库也需要几个小时。也就是说,在长达几个小时的时间里,主库和备库的数据是不一致的,这在某些场景下(ADG备库常常用来分担主库的读负载)是不可接受的,这种情况下可以考虑启动redo实时应用。
在启动redo实时应用的情况下,应用服务在redo记录写入到当前备用重做日志文件后立即应用,不必等待当前备用日志文件归档后才应用。大幅度减少了主备库数据不一致的时间。redo实时应用要求备库开启日志归档并且配置了备用重做日志。从oracle 11GR2之后,开启redo实时应用在主库上不需要任何附加的操作(LOG_ARCHIVE_DEST_n的ARCH and LGWR已弃用),oracle 11G 在备库上使用下面的命令启动日志应用服务
ALTER DATABASE RECOVER MANAGED STANDBY DATABASE USING CURRENT LOGFILE DISCONNECT
在Oracle 19G中,使用下面命令即可
SQL> ALTER DATABASE RECOVER MANAGED STANDBY DATABASE DISCONNECT;
在备库启用了归档模式和并且配置了standby redo log的情况下,将自动激活redo实时应用。
2.3 问题原因分析
从备库的日志中可以看出只有主库节点2(线程2)上没有启用real-time apply,根据上面所列的启用条件,检查备库上是否有线程2的备用重做日志,运行下面语句查询备库备用重做日志```sql
SELECT THREAD#,GROUP#,BYTES/1024/1024 MBYTES FROM V$STANDBY_LOG;
THREAD# GROUP# MBYTES
1 1 1024
1 2 1024
1 3 1024
1 4 1024
2 5 1024
2 6 1024
2 7 1024
2 8 1024
检查主库的的redo日志配置如下
```sql
SELECT THREAD#,GROUP#,BYTES/1024/1024 MBYTES FROM V$STANDBY_LOG;
THREAD# GROUP# MBYTES
---------- ---------- ---------------
1 1 1024
1 2 1024
1 3 1024
2 4 1024
2 5 1024
2 6 1024
备库的standby redo log是符合要求的,主库的节点2上也应该启动redo实时应用,问题只能出在主库节点2的日志发送上,查询V$ARCHIVE_DEST_STATUS检查节点2上归档路径的状态
select DEST_ID,STATUS, ARCHIVE_DEST,SRL,ERROR from V$ARCHIVE_DEST_STATUS where DEST_ID=2;
ID STATUS ARCHIVE_DEST SRL ERROR
-- --------- -------------- ---------------- --------------------------------------
2 ERROR standby1 NO ERROR
ORA-16191: Primary log shipping client not logged on standby
这个节点的归档路径2的状态果然不对,报的错误也是比较常见的密码错误,将主库节点1的密码文件复制到节点2上改名后,关闭并重新启用路径后,备库取消日志应用再重新开启后,检查备库的告警日志信息如下
Mon May 26 15:47:48 2025
RFS[14]: Opened log for thread 2 sequence 73 dbid 1727956549 branch 1200175816
Archived Log entry 39 added for thread 2 sequence 73 rlc 1200175816 ID 0x66fe5842 dest 2:
Media Recovery Log +DATA/arch/2_73_1200175816.dbf
Media Recovery Log +DATA/arch/1_77_1200175816.dbf
Media Recovery Waiting for thread 2 sequence 74
RFS[14]: Opened log for thread 2 sequence 74 dbid 1727956549 branch 1200175816
Archived Log entry 40 added for thread 2 sequence 74 rlc 1200175816 ID 0x66fe5842 dest 2:
Media Recovery Log +DATA/arch/2_74_1200175816.dbf
Media Recovery Waiting for thread 1 sequence 78 (in transit)
Recovery of Online Redo Log: Thread 1 Group 5 Seq 78 Reading mem 0
Mem# 0: +DATA/orcldg/onlinelog/group_5.264.1202137561
Media Recovery Waiting for thread 2 sequence 75
-----省略多行
Mon May 26 16:15:25 2025
Archived Log entry 47 added for thread 2 sequence 77 ID 0x66fe5842 dest 1:
Media Recovery Log +DATA/arch/2_77_1200175816.dbf
Media Recovery Waiting for thread 2 sequence 78 (in transit)
Recovery of Online Redo Log: Thread 2 Group 8 Seq 78 Reading mem 0
Mem# 0: +DATA/orcldg/onlinelog/group_8.312.1202137561
从后面的输出来看,线程2上也启用实时redo应用了—Media Recovery Waiting for thread 2 sequence 78 (in transit),主库节点2上的更新备库也能马上看到了。
3 一点感想
这几天处理了几个这样类似的问题了,都是在密码或者配置文件上出现了问题,然后在排查和解决上耗费了大量的时间。看来,严谨仔细,一丝不苟缺省是DBA必备的素质,差之毫厘谬以千里,有时一点点的失误会造成后面大量的工作量。
