




机器学习之路
支持向量机的图形意义(四)
首先来了解下scikit-learn算法选择图:

这张图包括了四大主流部分,分别为:
分类(classification):标识对象属于哪个类别
回归(regression):预测与对象关联的连续值属性
聚类(clustering):自动将相似对象归为一组
降维(dimensionality reduction):减少要考虑的随机变量的数量
本文主要讨论的为分类里的支持向量机算法,其他结构算法详情见官网:
https://scikit-learn.org/stable/index.html
首先导入部分包:
import numpy as npimport matplotlib.pyplot as pltfrom matplotlib import stylestyle.use('ggplot')from sklearn import svmimport warningswarnings.filterwarnings("ignore", category=FutureWarning, module="sklearn", lineno=193)
接着随机定义一些点,将他们贴上0和1的标签(数小的为0,数大点的为1):
X = np.array([[1,2],[3,4],[2,2.5],[2.4,4],[3.1,8.5],[4,7.8],[5.3,7.8],[7.8,9.5],[12.5,16.8],[7,9.8],[9.2,11.5]])y=[0,0,0,0,0,0,0,1,1,1,1] #贴标签
将训练数据喂给机器,并模拟点观察其分类标签是否正确:
black_box = svm.SVC(kernel='linear',C=1.0) #线性算法black_box.fit(X,y)print(black_box.predict([[3,5]]))

关于这里的算法为什么使用SVC(kernel='linear')而不使用LinearSVC()最大的区别:
LinearSVC() 使用 one-vs-rest 处理多类问题
SVC(kernel='linear') 使用 one-vs-one 处理多类问题
关于one-vs-rest和one-vs-one的详细解释请阅:
https://cloud.tencent.com/developer/article/1141393
还记得上文画过的那条浅蓝色的线吗,现在要求出它的方程。
写出垂直向量:
w = black_box.coef_[0]#求线性方程的垂直向量print(w)

写出线性方程表达式:
k = -w[0]/w[1] #斜率kxx = np.linspace(0,12)yy = k*xx-black_box.intercept_[0]/w[1] #线性方程表达
画出所有点以及线性方程:
H = plt.plot(xx,yy,'r-',label='Hyperplane') #贴上无权重的标签plt.scatter(X[:,0],X[:,1],c=y) #画出所有0,1结果的点plt.legend()plt.show()
打印结果:
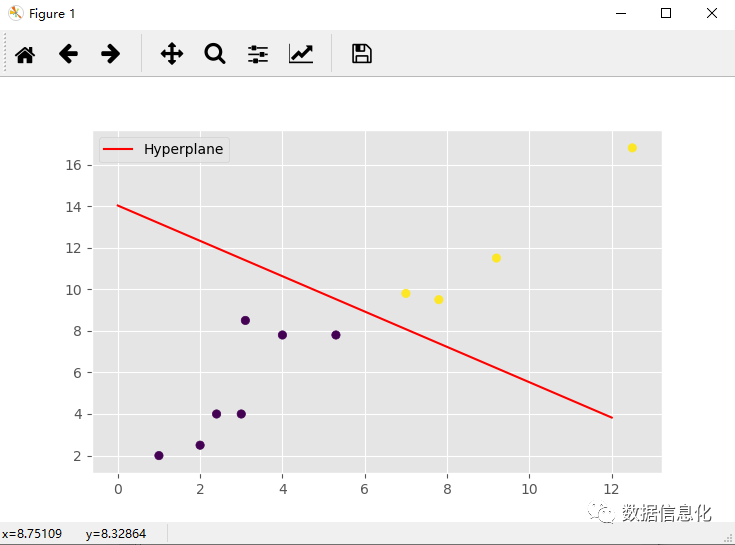
下面我们将对图线中的标线进行解释:

Hyperplane:将所有的数据集在一个二维平面上画出来,这时中间的那条线就是学习算法要学习出来的分割线。
Margin:SVM的思想是最大化边界,边界是分类的超平面和对应类别最近的样本点之间的距离。
Constrain Optimization:约束下最优化,将两边数据分开,使得Margin最大化。
下一章将介绍如何利用Python写入Kaggle中的真实数据进行预处理以及标准化操作。
下一章:【Python的机器学习】数据科学之Kaggle的数据处理(五)
