




摘要:2024年,一家跨国银行因为客户信用数据“乱作一团”,AI风控模型直接翻车,单季度坏帐就超过2.3亿美元;同年,某个省会城市的AI政务系统,因为数据标准对不上、部门之间“鸡同鸭讲”,导致系统完全跑不起来,老百姓办事排长队,服务延迟率飙到 47%……
这些血淋淋的教训说明了一个逐渐被企业意识到的事实:AI的上限,正由数据决定。
这并不是对大模型能力的否定,而是对现实的一种反映。过去几年,大模型在公众视野中风光无限,参数规模层层加码,从几十亿到千亿,文本生成、图像创作、写代码、讲笑话样样精通。
但当企业真正尝试把这些技术“搬”到业务里时,却发现事情没那么简单。
大模型可以很强,但落地很难。难点不在AI本身,而在企业内部的数据准备远远跟不上。
从“卷模型”到“卷数据”:企业AI的新主战场
麦肯锡的一项惊人统计数据表明,70%的企业AI项目卡在“数据质量不过关”。Gartner早就点破:未来企业AI竞争力的关键,不是用哪个大模型,而是有没有别人搞不到的数据。
也就是说,不是没模型、没算力,而是——数据质量不过关,数据源太杂,甚至连基本的可用性都无法保障。
如果说过去两年AI圈最“卷”的是模型,那接下来真正要“卷”的,可能是数据:
大模型能力差异不大,大家用的底座相似;
算力通过云服务可以买;
唯独企业内部的数据质量、结构和治理能力,是别人抄不走的护城河;
AI想用得准、用得稳、用得广,数据必须先打底。这也是为什么2024年以来,越来越多企业开始重视数据平台、数据治理和数据资产化能力的建设,而不仅仅盯着哪家模型更强。
“AI-Ready Data Platform”:不是再喂数据……
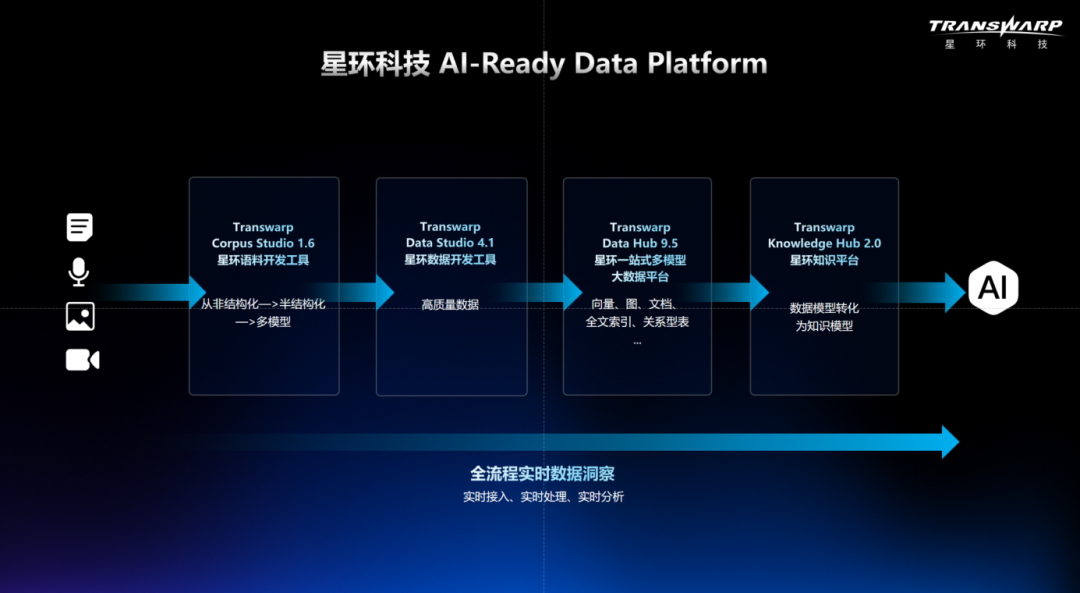
在5月27日的产品发布会上,星环科技首次提出“AI-Ready Data Platform”理念和技术架构,这不是给模型多喂点数据,而是为AI专门设计的数据底座。

孙元浩对老鱼说:“我们服务的客户中,有做政府治理的,有做券商投研的,还有大型制造业。他们现在普遍面临一个问题:不是不能上AI,而是数据没法给AI用。”
那么,企业AI落地到底卡在哪里?总结起来,主要有四个“数据短板”:
1、系统割裂,数据孤岛严重
不同业务系统各自为政,没有统一标准和接口,数据难整合;
2、数据形态碎片化
图片、文本、结构化、IoT 等多模态数据分散存储,缺乏统一治理;
3、质量参差,信度不足
有数据但不敢用,用了怕出错,很多AI模型直接“吃坏肚子”;
4、找不着、批不下、用不起
数据分布不明晰、权限审批流程复杂,使用门槛高,效率低下。
星环提出的“AI-Ready Data Platform”,正是试图从根本上解决这些现实问题。
“AI×Data” vs “AI+Data”:从数据喂养,到深度耦合
起步阶段(Step 0):AI会生成内容,但不了解业务背景;
接入知识(Step 1):连接知识库,但依然无法主动参与流程;
辅助同事(Step 2):变成虚拟助手,能处理具体任务;
高效协同(Step 3):AI与数据平台深度融合,决策、预测与执行效率倍增。
这个变化可以简单理解成一个公式的进化:从“AI生成Data”,到“AI+Data”的组合,再到“AI×Data”的协同效应,最后走向 (AI×Data)ⁿ 的爆发式增长。
这里的重点是,AI不只是“用”数据,而是开始“管”数据、“改造”数据,甚至直接参与到数据采集、清洗、治理、分析的每一个环节。它从后台走向前台,成为驱动业务智能化的核心引擎。
在AI+Data的阶段,AI更像是个“查资料的工具人”,企业把数据准备好、整理好,然后交给AI去访问、提问、输出答案。
但到了AI×Data的阶段,AI的角色就不一样了——它不光是用数据,还开始“参与做数据”。从数据采集、清洗、治理,到最后分析出结果,AI全程都在场,直接插手整个数据链条。
这样一来,AI不再只是“看结果”,而是能接触到最原始的数据、亲自上手“加工”,自然也就能给出更准确、更贴近实际的问题答案。
星环科技正是基于这个判断,推出了“AI-Ready Data Platform”这个新平台,目标就是让AI从数据的“使用者”变成“参与者”,从数据源头开始,为AI落地提供真正的支撑。
“AI基础设施”不只是搞算力,数据平台是地基
星环本次发布的AI基础架构包括四个核心层级:

Resources Platform:统一调度算力资源;
AI-Ready Data Platform:治理多模态数据、提升数据可用性;
AI Platform:支持AI模型训练、推理与服务开发;
Knowledge Platform:将数据转化为可复用知识资产。
其中,第二层“AI-Ready Data Platform”被视为整个架构的“压舱石”。 其核心能力包括:

“你们之前也做Lakehouse、多模数据库,这次提出的AI-Ready Data Platform,到底有什么不一样?是换个皮?还是升级?”这是老鱼重点追问的一个问题。
孙元浩的回答是:是升级版。
“处理的数据类型从结构化数据延伸到非结构化数据,数据类型更多了。现在的AI-Ready Data Platform其实是包含了我们以往的数据库、湖仓集一体产品,但又有更多的能力。”
用得起来,落得下去吗?
当然,老鱼更关心这套架构有没有真实场景验证。有没有客户已经跑起来了?效果怎么样?“这不是纸上谈兵。已在多家金融客户成功落地。”孙元浩说。
比如某大型证券公司,基于该平台构建了AI Infra平台,实现了多GPU类型统一调度;完成数十个大小模型纳管与监控,搭配灵活的开发模式,降低模型管理周期的复杂难度,减少维护成本;应用部署门槛显著降低。
另一家股份制银行,已经通过该平台构建了智能知识工程,实现了复杂问答、多模数据接入、实时语义联动等能力,应用已深入多个业务部门。
客户反馈归纳为三个关键词:“落得下、用得起、扩得快”。
打不打通大模型生态?能不能开放?
在大模型百花齐放、开源生态逐渐走向成熟的当下,平台是否“闭源孤岛”将成为一张生死考卷。
一个真正“AI Ready”的数据平台,应该天然支持多模型接入、多开发框架适配,甚至能直接参与RAG、Agent式应用闭环。
这是老鱼在采访中关注的另一个关键点:
“我们已经支持接入多个主流大模型,如DeepSeek、通义千问等,也向企业开发者开放MCP接口和自然语言查询能力。”孙元浩表示,“平台本身是为多模型接入设计的,不会成为生态孤岛。”
换句话说,无论你选的是国产大模型还是自研小模型,这个平台都能接得住、喂得好。
国产数据基础设施,真的有机会吗?
AI浪潮下,国产数据技术厂商普遍面临“转身”的考验。是继续深挖数据管理价值,还是试图切入AI场景?
孙元浩说得很直接:“我们正处于近水楼台先得月的位置。”
“以前,客户部署我们的平台,是为了建报表、做数据分析;现在,客户天然就希望基于已有平台接AI、挂大模型,这样才省成本、少改动。”
“所以,我们不是数据库厂商,也不只是大数据平台厂商,我们是一个‘数据+AI’双平台并进的AI基础设施公司。”
写在最后:企业该如何看待这场转向?
如果说大模型是“引擎”,那数据就是“燃料”, 劣质燃料会导致引擎熄火。
对想要真正落地AI的企业来说,现在可能到了一个重要的转折点:
不再只是问:“我选哪个模型?”
而是要想:“我有没有让AI发挥价值的数据底座?”
这是一场关乎AI落地成败的转向,也是企业智能化转型中最容易被忽略但最根本的问题。
谁能先把数据这块地基打好,谁就更有可能在AI这场长期战役中走得更远。
- END -
延伸阅读


欢迎订阅老鱼笔记
✬如果你喜欢这篇文章,欢迎分享到朋友圈✬
原创不易,且行且珍惜
