





本文字数:3555;估计阅读时间:9 分钟
作者:李龙 道旅科技 技术中心
Meetup活动
ClickHouse 杭州第二届 Meetup 讲师招募中,欢迎讲师在文末扫码报名!

道旅科技成立于2012年,是一家以科技驱动的全球旅游产品分销服务商,秉持数字原生基因,卓尔不凡。作为全球旅游技术的领导者,道旅科技掌握着尖端的开放平台技术,致力于为全球客户提供迅捷且高度灵活的优质旅游产品连接解决方案,涵盖酒店、机票以及用车、门票等碎片化产品领域。

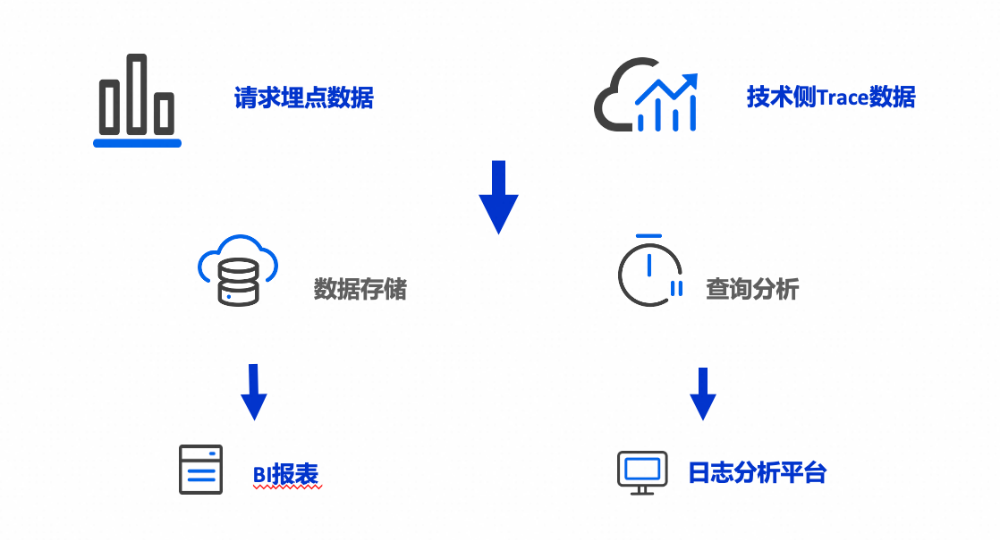
道旅科技的核心业务系统依赖于埋点数据的实时分析,其数据流经Kafka、Flink传输至数据仓库,支持数据分析与算法团队的运营策略调整。同时,技术侧的Trace数据用于开发调试与问题定位。业务需求对底层数据库提出以下核心要求:
批量数据写入性能高
每日产生数百TB的B端访问埋点数据,要底层的数据库具备较高的批量数据写入性能,避免数据积压。
批量查询速度快
为了更好的支持业务团队进行实时数据分析,做出运营决策,也为了提高算法团队的研发效能,要求日志分析平台能够提供秒/亚秒级的关键指标展示和复杂查询支持。
存储成本低
作为存储了所有业务中心上报的用户埋点行为数据和技术侧Trace数据的大数据平台,累计数据数千亿条,规模高达几百TB,要求底层的数据库产品能具备较高的存储压缩率和较低的存储成本。
道旅科技最初基于传统的分层数仓进行大数据平台的搭建,但随着业务的迅速发展,业务中心上报的请求埋点数据逐渐增多,在数仓方面的数据处理对于更新操作的依赖性很强,同时对查询性能和运维简单性的要求越来越高。在实际运行过程中,早期的数仓架构逐渐暴露出查询性能不足的问题,尤其是在面对海量数据的高并发查询需求时,单SQL资源占用上百核,执行时间需要15-20s,速度过慢,难以满足业务的实时分析和决策支持需求。此外,为了对数据进行深入分析并进行有效决策,需要在底层数据支撑平台留存更多的历史数据,增加了存储成本;层级复杂、表多,也会增加运维成本。
具体痛点如下:
1. 数据时效性差
数据从源头到应用需经过多层ETL加工,延迟高达数小时,难以满足实时分析需求。例如,用户行为数据需经过清洗、去重、聚合等步骤,导致最终分析结果滞后。
2. 响应速度慢
需求变更时需多层联动修改,如DWD层表结构调整需同步更新DWS层,开发周期长。复杂查询(如跨天的用户留存分析)需多表关联,执行时间长达15-20秒。
3. 开发运维成本高
层级复杂导致表数量超千张,维护成本高。数据分区策略不统一,部分表因分区过小导致查询性能下降。
因此,道旅科技决定对现有技术架构进行优化和升级,在尽量降低成本的同时提高数据更新处理能力和查询效率,从而更好地支持公司业务的持续增长和数据驱动的战略决策,进而提升市场竞争力和客户满意度。
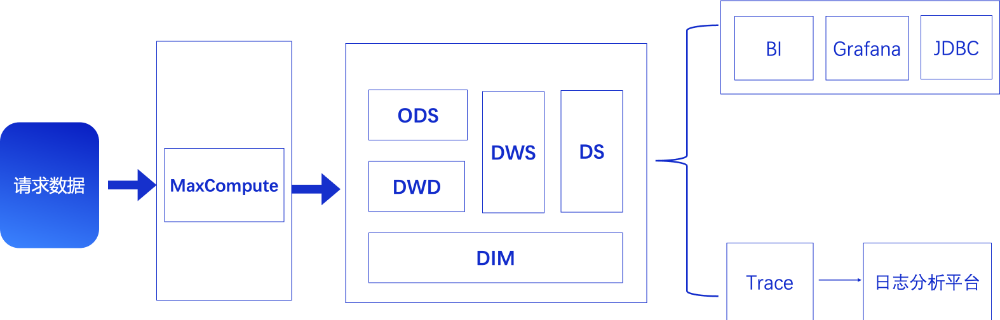
为了解决上述查询性能差、写入速度慢、成本高等问题,道旅科技决定将原有的大数据技术栈升级为ClickHouse,其核心优势在于极高的查询性能和资源效率,借助ClickHouse原生的物化视图能力和内置的多种存储压缩算法,不仅简化了业务逻辑,还实现了对实时分析业务性能和成本的进一步优化。架构图如下所示:

升级后的架构分为三层:
数据接入层:Kafka接收埋点数据,Flink进行实时清洗。
计算存储层:ClickHouse作为核心分析引擎,通过物化视图和Projection优化查询性能。
应用层:BI工具(如Grafana)与算法平台直接对接ClickHouse,实现秒级响应。
技术细节
物化视图(Materialized View)
ClickHouse内置实时物化视图,实时预聚合数据,减少查询时计算开销,大幅提升数据分析处理能力,查询速度提高9~15倍。
投影(Projection)
ClickHouse通过重新排序数据(如按时间、用户ID排序),加速大规模的数据查询性能。
跳数索引(Skip Index)
ClickHouse通过稀疏索引跳过无关数据块,加速范围查询。

成本降低
传统数仓因层级复杂、数据冗余度高导致存储成本居高不下。ClickHouse的列式存储与高压缩算法(如LZ4/ZSTD)使存储成本降低70%。例如,某日志表压缩后节省了存储资源,同时MergeTree引擎的分区管理优化了I/O效率,进一步降低存储成本。
查询性能大幅提升
升级前,复杂查询响应时间常达15-20秒,难以满足实时分析需求。ClickHouse通过物化视图、Projection和跳数索引等技术,查询响应时间缩短至秒级,性能提升超15倍。例如,用户行为分析查询耗时从18秒降至1.2秒,日志过滤查询效率提升30%,显著支撑了实时运营决策。
开发运维效率提升
通过物化视图替代多层ETL逻辑,开发周期从数周缩短至数天;Projection技术无需修改应用即可优化查询性能。运维方面,自动分区管理和轻量级索引维护减少人工干预,故障排查效率提升50%。例如,大规模数据清洗任务执行时间从数小时压缩至分钟级,系统负载显著降低。
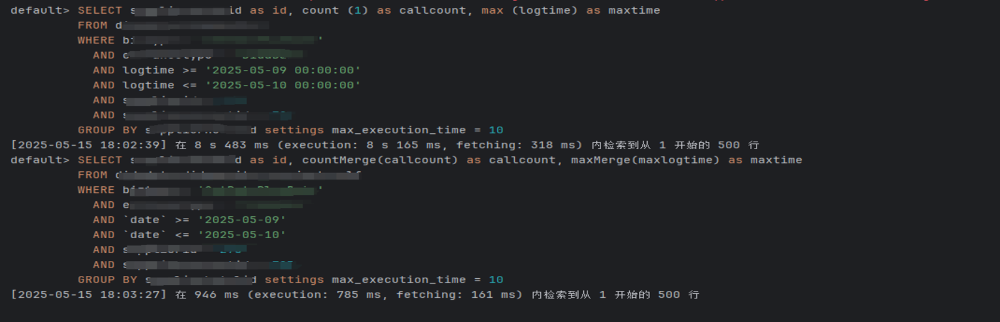
ClickHouse慢查询的一些优化技巧
例如,SQL语句Select * from table where 查询较慢,对此语句的优化流程为:
确定SQL是否可以复现,排除CPU/磁盘波动干扰。
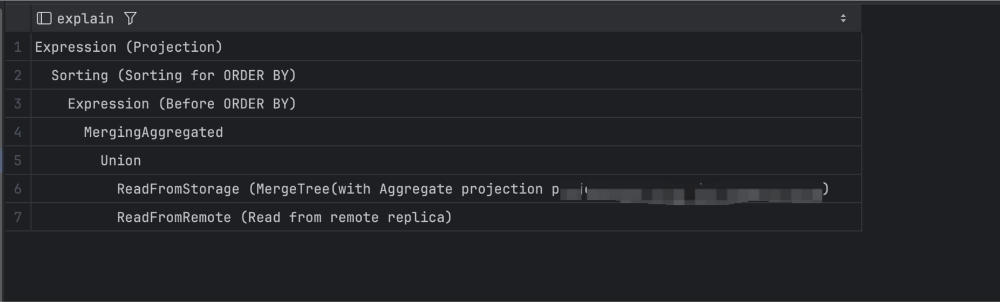
如果可以稳定复现,则使用 EXPLAIN查看查询计划。
从querylog中找到这一条语句的记录,找到对应的ProfileEvents属性。
关注ReadBufferFromFileDescriptorReadBytes 和 DiskReadElapsedMicroseconds等关键属性。
ClickHouse物化视图
物化视图只有在插入时运行。无法感知合并、分区删除或mutation等操作。如果更改了源表,必须手动更新关联的物化视图。
一张表上超过50个物化视图通常是过多的,会降低插入速度。 可能会引发 “Too many Parts”问题
物化视图的列和目标Aggregating/SummingMergeTree表上的列不匹配。目标表的ORDER BY子句必须与物化视图中的SELECT子句的GROUP BY一致。如果这两者不同,那些不一致列上的数据会被损坏。
ClickHouse Projection使用经验
注意事项
在非普通MergeTree, 例如在 AggregatingMergeTree、SummingMergeTree 中创建物化视图, 需要在建表ddl后添加 settings deduplicate_merge_projection_mode=’rebuild’。
Projection在merge时不会重新计算, 像AggregatingMergeTree、 SummingMergeTree 在Merge时行数会减少, 会导致Projection数据不一致。
deduplicate_merge_projection_mode=’rebuild’ 表示在merge时重建Projection。
匹配规则
返回的数据行小于基表总数。
查询覆盖的分区 part 超过一半。
Where 必须是 PROJECTION 定义中 GROUP BY 的子集。
GROUP BY 必须是 PROJECTION 定义中 GROUP BY 的子集。
SELECT 必须是 PROJECTION 定义中 SELECT 的子集。
匹配多个 PROJECTION 的时候,选取读取 part 最少的。
道旅科技通过引入ClickHouse,成功解决了海量数据下的查询性能、存储成本与开发效率问题。未来计划升级到ClickHouse 25.3版本,利用其原生的Json能力实现进一步的业务简化和性能提升,为道旅科技的全球旅游生态提供更高效的分析支撑。

我们正为杭州活动招募讲师,如果你有独特的技术见解、实践经验或 ClickHouse 使用故事,非常欢迎你加入我们,成为这次活动的讲师,与大家分享你的经验。

/END/
试用阿里云 ClickHouse企业版
轻松节省30%云资源成本?阿里云数据库ClickHouse 云原生架构全新升级,首次购买ClickHouse企业版计算和存储资源组合,首月消费不超过99.58元(包含最大16CCU+450G OSS用量)了解详情:https://t.aliyun.com/Kz5Z0q9G


征稿启示
面向社区长期正文,文章内容包括但不限于关于 ClickHouse 的技术研究、项目实践和创新做法等。建议行文风格干货输出&图文并茂。质量合格的文章将会发布在本公众号,优秀者也有机会推荐到 ClickHouse 官网。请将文章稿件的 WORD 版本发邮件至:Tracy.Wang@clickhouse.com


