




提问:作为DBA运维的你是否遇到过这些烦恼
1、数据迁移时突发数据库告警,不知是什么原因引起的?
2、数据库计算节点突然出现 ERROR,如何快速分析处理?
心中有章,遇事不慌
作为DBA的你,遇到问题无从下手,除了在问题面前徘徊,还能如何选择?如果你一次或多次遇到该问题还是无法解决,又很懊恼,该如何排忧呢?关注公众号,关注《包拯断案》专栏,让小编为你排忧解难~
一整套故障排错及应对策略送给你,让你像包拯一样断案如神:
#首先
遇到此类问题后,我们要做到心中有章(章程),遇事不慌。一定要冷静,仔细了解故障现象(与研发/用户仔细沟通其反馈的问题,了解故障现象、操作流程、数据库架构等信息)
#其次
我们要根据故障现象进行初步分析。心中要想:是什么原因导致计算节点出现异常?例如:是磁盘被打满了,还是相关参数值设置有问题?
#然后
针对上述思考,我们需要逐步验证并排除,确定问题排查方向。
#接着
确定了问题方向,进行具体分析。通过现象得出部分结论,通过部分结论继续排查并论证。
#最后
针对问题有了具体分析后,再进行线下复现,最终梳理故障报告。
真刀实战,我们能赢
说了这么多理论,想必实战更让你心动。那我们就拿一个真实案例进行分析——某运营商项目有一套并行环境,由于对某张大表同一时刻分批次进行全量数据稽核,导致GreatDB数据库集群的一个计算节点出现 ERROR,这种问题该如何快速分析处理?
故障发生场景
某项目现场,万里数据库DBA刚完成了一套并行环境部署,该环境用于业务系统开展业务验证工作。部署完毕后,DBA在使用数据迁移工具执行迁移任务时,数据库集群突然触发【节点状态异常】告警。见状,DBA 迅速启动排查机制,全力排查异常原因,以保障数据迁移及业务验证任务的顺利进行。
故障排查分析
2.1 检查集群状态
(1)根据告警信息,DBA立即登录这个计算节点,查看集群状态,通过查看发现,这个计算节点下所有的节点状态都是不正常的。

(2)于是,DBA马上登录另外2个计算节点查看,发现其余计算节点状态正常。因此可以判断,只有这一个计算节点异常,业务系统目前能正常使用其余的2个计算节点。

(3)查看数据节点状态
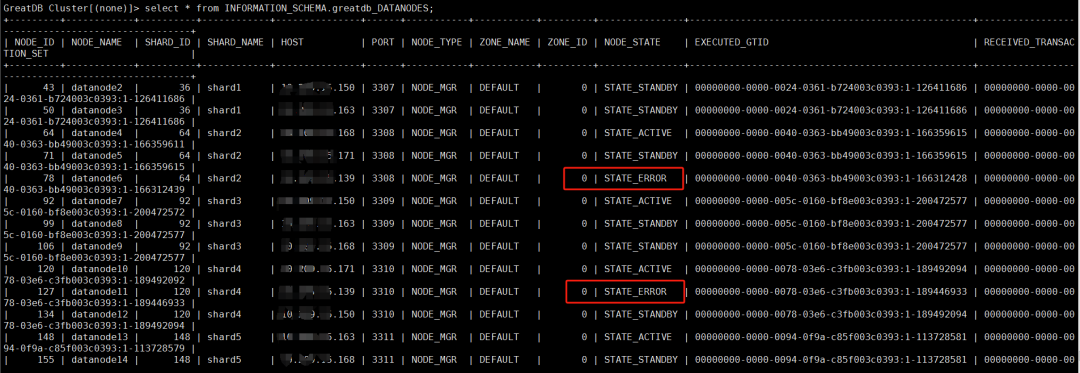
可以看到,同一台主机上的2个数据节点副本实例是ERROR状态。因此猜测:是这台主机的某些原因,导致部署在这台主机上的计算节点和数据节点出现异常。
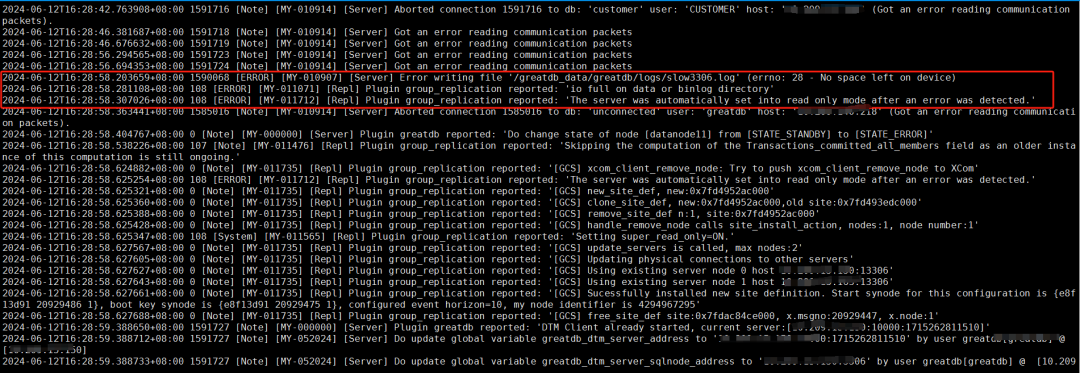
2.2 查看错误日志信息
计算节点日志情况如下:
数据节点日志
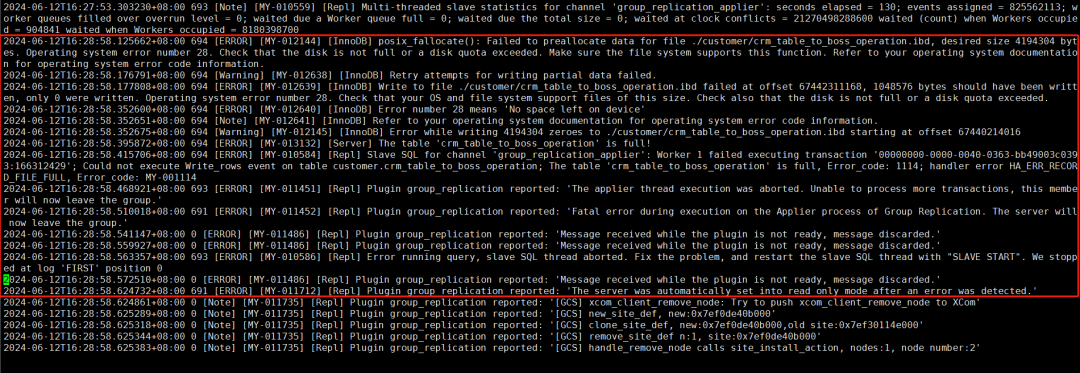
从上面2个实例日志中可以看出,是主机磁盘空间满了导致计算节点和数据节点异常,退出集群。
2.3 检查磁盘容量

当前磁盘容量正常,数据库日志中显示错误时,磁盘可能确实已满,但在查看时磁盘空间已被释放;继续检查磁盘IO,查看是否有大量磁盘写入。
2.4 检查磁盘IO情况
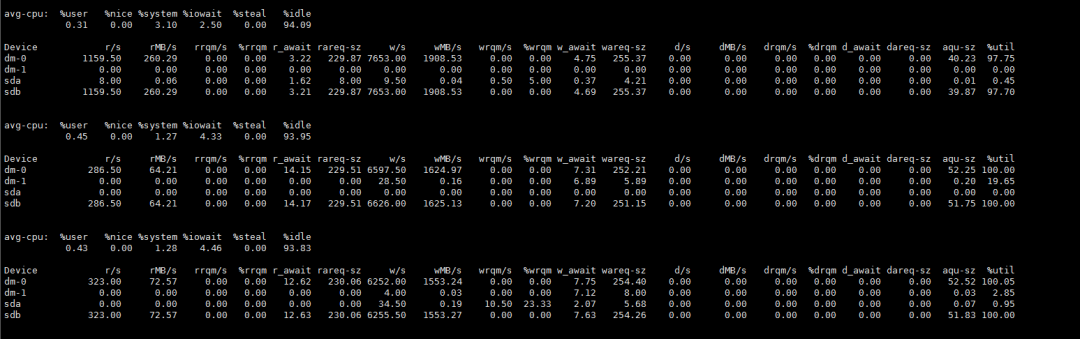
可以看到此时磁盘IO是被打满的状态。
2.5 查看是哪个线程占用磁盘IO
pidstat -t -p 19506 -d -1
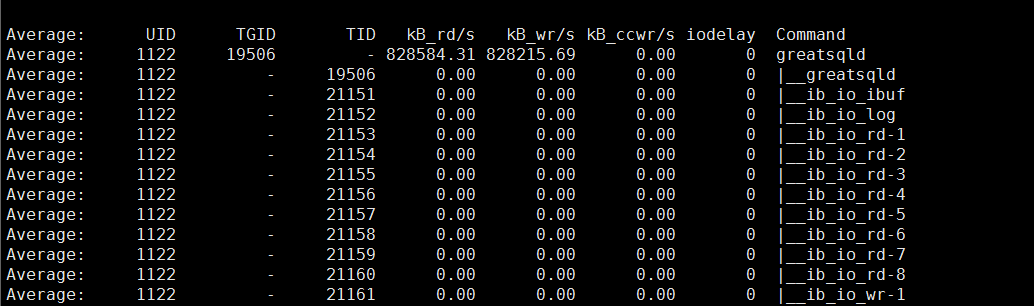
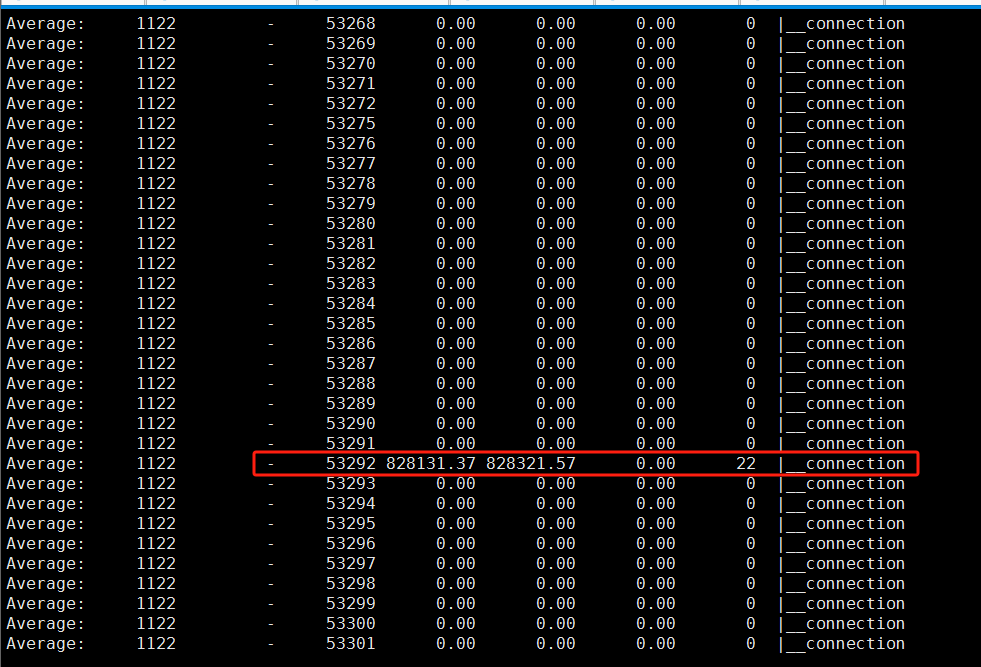
可以看到当前计算节点,53292线程正在大量进行读写操作。
2.6 查看哪个SQL语句导致磁盘IO飙升
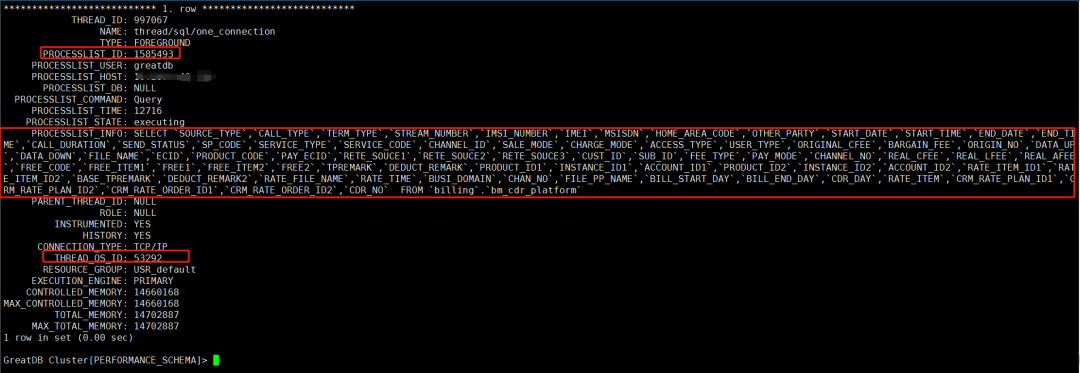
根据上面的操作系统线程ID 53292,通过查看performance_schema.threads 表可以得知,由于这条SQL语句导致磁盘IO被打满,且SQL语句没有显示完整,继续通过 information_schema.processlist 表查看完整SQL。
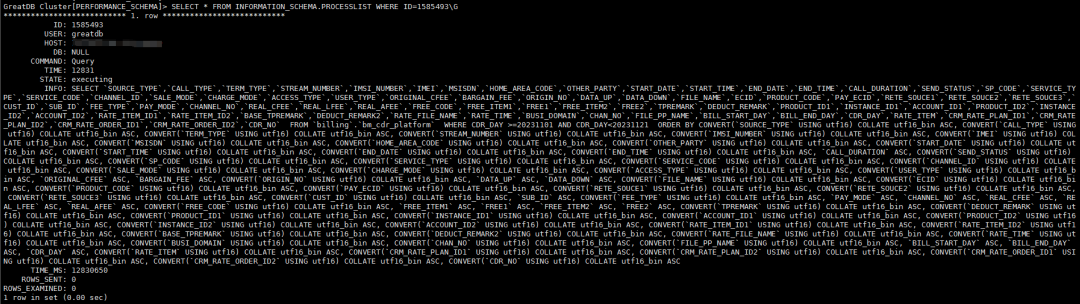
2.7 查看此SQL的执行计划
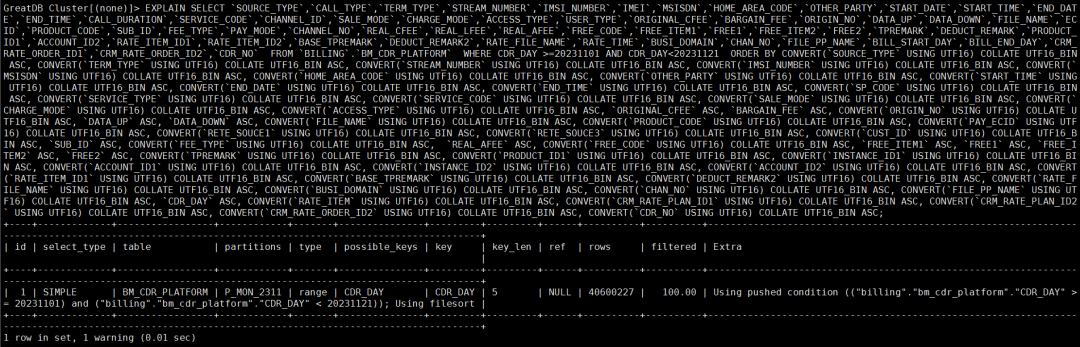
这条SQL是在进行全量数据稽核时执行的,会对表进行全量查询,并按全部字段进行排序,因此会产生大量的临时磁盘文件。
故障处理
3.1 kill此SQL
GREATDB> kill 1585493;
3.2 检查磁盘IO情况
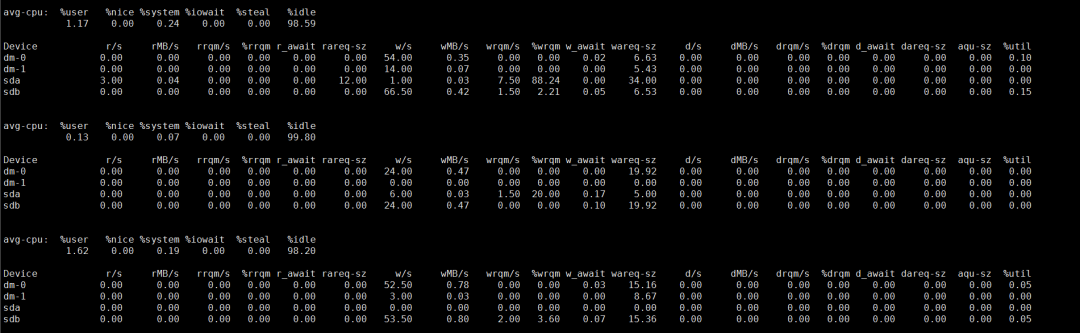
可以看到,kill掉这条SQL后,磁盘IO恢复正常。
3.3 恢复计算节点/数据节点
登录处于ERROR状态的节点,启动组复制,让节点自动加入集群。
GREATDB> start grouo_replication;
复盘总结
1.完善告警配置
需完善服务器监控告警配置,在磁盘IO负载过高时给予预警,以便DBA及时处理,避免因IO超载及磁盘空间不足时,影响集群的正常使用;
2.避免全表查询
在业务系统运行过程中,应避免出现对大表进行全表查询并产生临时文件的SQL,导致IO升高、磁盘空间不足等问题,影响其他业务正常进行。



