




在SQL中支持行匹配模式的match_recognize写法, 是oracle 从12c开始推出的, 功能很强大,语法看起来有点复杂, 跟普通的SQL区别挺大.
oracle在介绍这个新写法的时候, 举了一个获取股票V型图(2个峰值一个谷值)的例子(网上有很多介绍,都是用的这个例子), 但是除了这个例子以为, 较少见到其他应用案例, 这里抛砖引玉, 介绍几个用match_recognize解决问题的方法 , 仅供参考.
示例(1) : 去除连续的重复状态, 只保留第一条, 如下图, 划红线的是需要去除的记录
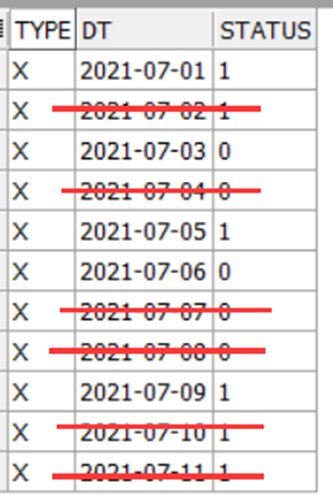
这个问题如果用分析函数实现起来也比较简单, 下面是用match_recognize实现的方法:
with d (type,dt,status)as
( select 'X' ,date '2021-7-1','1' from dual
union all select 'X' ,date '2021-7-2','1' from dual
union all select 'X' ,date '2021-7-3','0' from dual
union all select 'X' ,date '2021-7-4','0' from dual
union all select 'X' ,date '2021-7-5','1' from dual
union all select 'X' ,date '2021-7-6','0' from dual
union all select 'X' ,date '2021-7-7','0' from dual
union all select 'X' ,date '2021-7-8','0' from dual
union all select 'X' ,date '2021-7-9','1' from dual
union all select 'X' ,date '2021-7-10','1' from dual
union all select 'X' ,date '2021-7-11','1' from dual
)
SELECT *
FROM d
MATCH_RECOGNIZE (
PARTITION BY type
ORDER BY dt
measures
dt as dt,
status as status
one ROW PER MATCH
PATTERN ( A )
DEFINE
A as status<>prev(status) or prev(status) is null
);
还有其他写法, 也能得到相同结果, 下面是itpub开发版版主苏大师的写法:
with d (type,dt,status)as
( select 'X' ,date '2021-7-1','1' from dual
union all select 'X' ,date '2021-7-2','1' from dual
union all select 'X' ,date '2021-7-3','0' from dual
union all select 'X' ,date '2021-7-4','0' from dual
union all select 'X' ,date '2021-7-5','1' from dual
union all select 'X' ,date '2021-7-6','0' from dual
union all select 'X' ,date '2021-7-7','0' from dual
union all select 'X' ,date '2021-7-8','0' from dual
union all select 'X' ,date '2021-7-9','1' from dual
union all select 'X' ,date '2021-7-10','1' from dual
union all select 'X' ,date '2021-7-11','1' from dual
)
SELECT *
FROM d
MATCH_RECOGNIZE (
PARTITION BY type
ORDER BY dt
ALL ROWS PER MATCH
PATTERN ( (A|{-B-})+ )
DEFINE
A as status<>last(status,1) or prev(status) is null
);
大家可以比较一下二者的区别.
示例(2): 得到后面记录值比当前记录值大的记录个数, 比如下面结果集
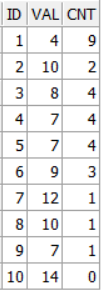
左边两列是原始记录, 最后一列是match_recognize后得到的结果. 第一条记录的val是4, 下面9条件记录当中, 都比4大, cnt就是9; 第二条val是10, 下面比10大的记录有12和14, cnt就是2, 以此类推.
with gen as
(select rownum as ID, round(dbms_random.value(3,15)) as val
from dual connect by level<=10
)
select * from gen
match_recognize(
order by id
measures
first(a.id) as id,
first(a.val) as val,
final count(b.*) as cnt
one row per match
after match skip to next row
pattern (a (b|c)* )
define
b as b.val>a.val,
c as c.val<=a.val
);
(实现这个功能的写法有多种, 这里只谈match_recognize的写法)
示例(3): 得到所有员工及全部下属的工资总和
select * from
(
select level lvl, ename, sal
from scott.emp
start with mgr is null
connect by mgr = prior empno
)
match_recognize
(
measures
a.lvl lvl, a.ename ename,a.sal sal,
sum(sal) as sum_sal
after match skip to next row
pattern(a b*)
define b as lvl > a.lvl
);
结果集:
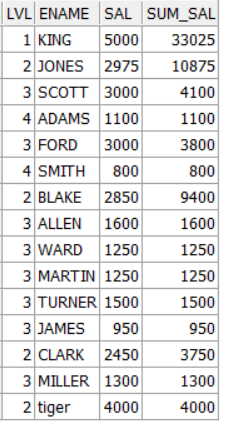
其中第一条记录 lvl=1, 下面所有记录的lvl都<1,sum_sal相当于整个公司的工资总和 ; 第二条记录lvl=2, 到下一个lvl=2前的所有记录之和=10875(2975+3000+1100+3000+800 ), 以此类推.
示例(4) : 合并连续区间
with tmp(id ,page) as
(select 1 ,3 from dual union all select 2,4 from dual union all
select 4,8 from dual union all select 3,5 from dual union all
select 5,9 from dual union all select 6,16 from dual union all
select 7,15 from dual union all select 8,18 from dual
)
SELECT *
FROM tmp
MATCH_RECOGNIZE
(
ORDER BY page
MEASURES
A.page as firstpage,
LAST(page) as lastpage,
COUNT(*) cnt
ONE ROW PER MATCH
AFTER MATCH SKIP PAST LAST ROW
PATTERN (A B*)
DEFINE B AS page = PREV(page)+1
);
结果集(左边是合并前):
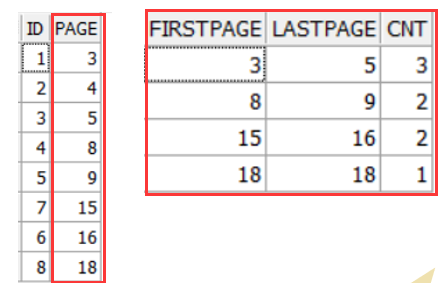
其中: 3~5是连续的3个值; 8~9 是连续的2个值...
示例(5) : 计算连续3天(第一条记录和第三条记录间隔不超过3天)的记录和
在公众号文章 73-找到业务高峰时段的sql示例(报表开发类)中, 我在留言部分分别补充了分析函数和model的写法, 这里再补充一个match_recognize的写法, 这个写法不需要补齐不存在的"天", 用模拟数据演示如下:
with gen (id, val) as
(select 1, 3 from dual union all select 2, 2 from dual union all select 3,5 from dual union all
select 5, 3 from dual union all select 8, 2 from dual union all select 9,5 from dual union all
select 10, 3 from dual union all select 12, 2 from dual union all select 13,5 from dual union all
select 14, 3 from dual union all select 15, 2 from dual union all select 16,5 from dual union all
select 20, 3 from dual union all select 21, 2 from dual union all select 23,5 from dual
)
select bid,bid+2 as eid,sum3 from gen
match_recognize(
order by id
measures
first (a.id) as bid,
sum(val) as sum3
one row per match
after match skip to next row
pattern (A B*)
define
B as b.id<=a.id+2
);
结果集(左边是原始数据, 右边是match_recognize后的结果):
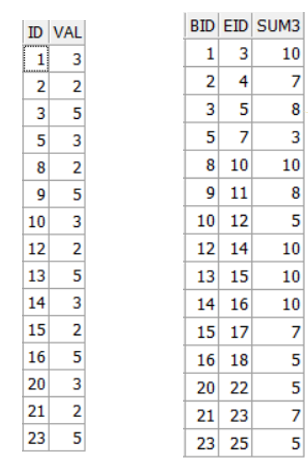
得到了右边的结果集后, 可以再做深入加工(比如再选出top 5等)
示例(6) : 来自itpub 苏大师的每周一题
http://www.itpub.net/thread-2117353-1-1.html
create table qz_game_log (
seq integer primary key
, log varchar2(10)
);
insert into qz_game_log values (117, 'GO');
insert into qz_game_log values (118, 'LEFT');
insert into qz_game_log values (119, 'LEFT');
insert into qz_game_log values (120, 'RIGHT');
insert into qz_game_log values (121, 'LEFT');
insert into qz_game_log values (122, 'FINISH');
insert into qz_game_log values (123, 'GO');
insert into qz_game_log values (124, 'RIGHT');
insert into qz_game_log values (125, 'RIGHT');
insert into qz_game_log values (126, 'LEFT');
insert into qz_game_log values (127, 'CRASH');
insert into qz_game_log values (128, 'GO');
insert into qz_game_log values (129, 'RIGHT');
insert into qz_game_log values (130, 'LEFT');
insert into qz_game_log values (131, 'RIGHT');
insert into qz_game_log values (132, 'LEFT');
insert into qz_game_log values (133, 'RIGHT');
insert into qz_game_log values (134, 'FINISH');
commit;
每个游戏都是从GO开始,然后是一系列的LEFT或者RIGHT移动,然后以 FINISH 或者 CRASH 终止。
成功结束的游戏以FINISH而不是CRASH终止,我想要查看所有成功游戏的LEFT/RIGHT移动步骤,
从哪个SEQ开始到哪个SEQ截止,还想知道总共多少步,其中RIGHT几步,LEFT几步。
GO和FINISH不计算在游戏的移动步骤之内。
所要求的输出:
FROM_SEQ TO_SEQ MOVES RIGHTS LEFTS
---------- ---------- ---------- ---------- ----------
118 121 4 1 3
129 133 5 3 2
原作者给出的两个写法, 值得学习:
写法 1)
select min(seq) as from_seq
, max(seq) as to_seq
, count(*) as moves
, count(case cls when 'RIGHT' then 1 end) as rights
, count(case cls when 'LEFT' then 1 end) as lefts
from qz_game_log
match_recognize (
measures
match_number() as mno
, classifier() as cls
ALL ROWS PER MATCH
pattern ({-GO-} (LEFT|RIGHT)+ {-FINISH-})
define
GO as log = 'GO'
, LEFT as log = 'LEFT'
, RIGHT as log = 'RIGHT'
, FINISH as log = 'FINISH'
)
GROUP BY mno
order by from_seq;
写法 2)
select from_seq, to_seq, moves, rights, lefts
from qz_game_log
match_recognize (
measures
min(MOVE.seq) as from_seq
, max(MOVE.seq) as to_seq
, count(MOVE.seq) as moves
, count(RIGHT.seq) as rights
, count(LEFT.seq) as lefts
one row per match
pattern (GO (LEFT|RIGHT)+ FINISH)
SUBSET
MOVE = (LEFT, RIGHT)
define
GO as log = 'GO'
, LEFT as log = 'LEFT'
, RIGHT as log = 'RIGHT'
, FINISH as log = 'FINISH'
)
order by from_seq;
写法 3) 这是我尝试的一个写法(殊途同归,性能上应该没啥区别):
select * from qz_game_log
match_recognize(
order by seq
measures
least(first(l.seq) , first(r.seq) ) as from_seq,
greatest(last(l.seq) , last(r.seq) ) as to_seq,
count(l.*)+count(r.*) as moves,
count(r.*) as rights,
count(l.*) as lefts
one row per match
pattern
( strt (L|R)+ fini )
define
strt as log='GO',
L as log='LEFT',
R as log='RIGHT',
fini as log='FINISH'
);
用match_recognize实现行与行之间匹配的相关的案例还有很多, 也有一些实现复杂的业务逻辑. 这里列举一些简单的例子, 让大家对match_recognize的用法有一个大致的了解.
match_recognize在金融行业应该有较多的应用场景(比如股票分析和可疑交易分析), 开发人员在熟悉这个功能后, 就可以轻松的用SQL实现复杂的业务逻辑.

