




目录
- SCN 的本质与定义
- SCN 的结构解析(Oracle 9i 及以后)
- SCN 的生成机制
- SCN 的存储位置
- SCN 在关键场景中的作用
- SCN 与高可用架构(RAC & Data Guard)
- SCN 相关的重要视图与函数
- SCN 健康监控与常见问题
- 最佳实践与管理建议
- 总结
SCN 的本质与定义
系统变更号 SCN(System Change Number) 是 Oracle 数据库内部使用的一种逻辑时间戳机制,用于标记和排序数据库中的变更事件。作为数据库的“全局时钟”,它以单调递增的方式生成,为所有数据变更和事务操作提供精确的时序标记和一致性锚点,确保事务的顺序性和一致性,是实现数据库 ACID 特性的重要手段。
其核心特性包括:
- 全局唯一性:整个数据库(包括 RAC 所有节点)任一时刻的 SCN 值唯一。
- 单调递增性:SCN 随时间推移严格递增(不一定是连续递增)。
- 关键作用:
- 保障数据一致性(Consistency)
- 实现崩溃恢复(Crash Recovery)
- 支持闪回技术(Flashback)
- 控制分布式事务
- 管理备份与恢复(RMAN)

简而言之,SCN 是 Oracle 保证数据一致性、事务顺序和恢复正确性的重要基础。
SCN 的结构解析(Oracle 9i 及以后)
在 Oracle 12.2 之前,SCN 是一个 6 字节(48bit)的数字,理论最大值为 2^48,即 281 万亿,在内部由两部分组成:
| 组件 | 字节数 | 数值范围 | 作用机制 |
|---|---|---|---|
| SCN_BASE | 4 字节(32bit) | 0 ~ 4,294,967,295 | 基础计数器,每秒可达数万次递增 |
| SCN_WRAP | 2 字节(16bit) | 0 ~ 65,535 | 当 SCN_BASE 溢出时 +1 |
SCN 计算公式:SCN = (SCN_WRAP × 4,294,967,296) + SCN_BASE
- SCN_BASE:低 32 位,每秒可递增 16M(16,777,216)次。
- SCN_WRAP:高 16 位。
- 每秒最大增量 ≈ 16M(受
_max_reasonable_scn_rate参数限制)。
可通过以下 SQL 查看拆分值:
-- 获取 SCN_BASE
SQL> select max(scn_bas) SCN_BASE,max(scn_wrp) SCN_WRAP from smon_scn_time;
SCN_BASE SCN_WRAP
---------- ----------
19591101 0

从 Oracle 12.2 版本开始 SCN 扩展至 8 字节,理论最大值为 2^63,约等于 922.33京 这提供了近乎无限的 SCN 增长空间。
SCN 的生成机制
- 事务提交时生成:当用户执行
COMMIT时,Oracle 分配一个新的 SCN 标记该事务的提交时间点。该 SCN 写入重做日志(Redo Log) 和回滚段头(Undo Header)。 - 检查点(Checkpoint)触发:发生增量检查点(Incremental Checkpoint)或完全检查点时,DBWn 进程将脏块写入数据文件,同时更新控制文件和数据文件头的 SCN。
- 其他场景:
- 表空间热备开始/结束;
ALTER SYSTEM SWITCH LOGFILE;- RAC 节点间通信;
SCN 的存储位置
SCN 在数据库中无处不在:
| 位置 | SCN 类型 | 作用 |
|---|---|---|
| 控制文件 | CHECKPOINT_CHANGE# |
记录最近完成的检查点 SCN |
| 数据文件头 | CHECKPOINT_CHANGE# |
记录该文件最后写入的检查点 SCN |
| 重做日志文件 (Redo Log) | FIRST_CHANGE# |
日志起始 SCN |
NEXT_CHANGE# |
日志结束 SCN | |
| 块头 (Block Header) | ITL 中的 SCN |
记录事务对该块的修改 SCN |
| 回滚段 (Undo Segment) | 事务槽中的 SCN | 标记事务提交状态 |
-- 控制文件
SQL> SELECT checkpoint_change# FROM v$database;
CHECKPOINT_CHANGE#
------------------
19576849
-- 数据文件头,这里用 v$datafile_header,不同于 v$datafile,后者是控制文件里的信息
SQL> SELECT file#, checkpoint_change# FROM v$datafile_header;
FILE# CHECKPOINT_CHANGE#
---------- ------------------
1 19576849
2 19576849
3 19576849
4 19576849
5 19576849
7 19576849
-- 重做日志文件
GROUP# FIRST_CHANGE# NEXT_CHANGE#
---------- ------------- ------------
1 18658076 18851288
2 18851288 18952817
3 18548980 18658076
4 18952817 19136256
5 19136256 19246277
...
...
-- 块头 (Block Header):ITL 中的 SCN
SQL> ALTER SYSTEM DUMP DATAFILE 5 BLOCK 376;
System altered.
SQL> select tracefile from v$process where addr=(select paddr from v$session where sid=(select distinct sid from v$mystat));
TRACEFILE
----------------------------------------------------------------------------------------------------
/u01/app/oracle/diag/rdbms/lucifer/lucifer/trace/lucifer_ora_3521.trc
-- 这里可以看到 0xc80dd2 是一个十六进制数,0x0000000000c80dd2 是一个补 0 后的 64位 的 SCN
SQL> !grep "scn:" /u01/app/oracle/diag/rdbms/lucifer/lucifer/trace/lucifer_ora_3521.trc
scn: 0xc80dd2 seq: 0x02 flg: 0x04 tail: 0x0dd22002
Format scn: 0x0000000000c80dd2
-- 转十进制
SQL> SELECT TO_NUMBER('80dd2', 'XXXXXX') AS dec_value FROM dual;
DEC_VALUE
----------
13110738
-- 回滚段 (Undo Segment):事务槽中的 SCN
SQL> SELECT segment_name, tablespace_name, status FROM dba_rollback_segs;
SQL> ALTER SYSTEM DUMP UNDO HEADER '_SYSSMU6_813816332$';
SQL> !grep "scn:" /u01/app/oracle/diag/rdbms/lucifer/lucifer/trace/lucifer_ora_3521.trc
scn: 0x12b1500 seq: 0x01 flg: 0x00 tail: 0x00000000
-- 转十进制
SQL> SELECT TO_NUMBER('12b1500', 'XXXXXXXX') AS dec_value FROM dual;
DEC_VALUE
----------
19600640
有一个脚本可以通过 scn 号获取对应 Timestamp 时间:
SQL> @scnfinder
Enter value for input_scn: 19600640
------------------------------------------------------------
SCN Finder on 04-JUN-2025 13:38:05
SCN=19600640(04-JUN-25 01.30.33.000000000 PM)
PL/SQL procedure successfully completed.
scnfinder 可以在 MOS 文档进行下载:
Script To Get The Timestamp For a SCN or V$DATABASE_BLOCK_CORRUPTION (Doc ID 2421844.1)
SCN 在关键场景中的作用
崩溃恢复(Crash Recovery)
- 起点:从控制文件中读取
CHECKPOINT_CHANGE#。 - 终点:重做日志中最后一条已写入但未应用的变更记录的 SCN。
- 重做(Redo)应用所有
SCN > CHECKPOINT_CHANGE#的变更,再回滚未提交事务(Undo)。
实例恢复(Instance Recovery)
在 RAC 环境中,存活节点通过重做日志为故障节点执行恢复,依赖 SCN 定位恢复起点。
分布式事务
协调器使用 SCN 确保所有参与节点提交/回滚的一致性(Two-Phase Commit)。
闪回查询(Flashback Query)
SELECT * FROM employees AS OF SCN 123456; -- 基于 SCN 闪回
SELECT * FROM employees AS OF TIMESTAMP ...; -- 内部转换为 SCN
备份与恢复 (RMAN)
BACKUP ... INCREMENTAL FROM SCN:基于 SCN 的增量备份。- 恢复时通过 SCN 确定需应用的归档日志范围。
SCN 与高可用架构(RAC & Data Guard)
RAC 中的 SCN 同步
- LMS 进程:负责在节点间传递 SCN(通过
GV$ 视图中的CURRENT_SCN可见全局一致性)。 - SCN 传播方式:
- 广播式(Broadcast on Commit):默认模式,事务提交时广播 SCN。
- 增量式(Lamport SCN):减少网络流量,按需同步。
Data Guard 中的 SCN
- Apply SCN:备库当前已应用的最大 SCN(
V$DATAGUARD_PROCESS)。 - 备库延迟计算:
(CURRENT_SCN - APPLIED_SCN) / 16M ≈ 延迟秒数。 - 闪回备库:需记录闪回点 SCN,便于快速重建。
SCN 相关的重要视图与函数
| 视图/函数 | 用途 |
|---|---|
V$DATABASE |
CURRENT_SCN(当前数据库 SCN) |
V$TRANSACTION |
START_SCN(事务开始的 SCN) |
DBMS_FLASHBACK.GET_SYSTEM_CHANGE_NUMBER |
获取当前 SCN |
SCN_TO_TIMESTAMP(scn) |
将 SCN 转为时间戳(依赖 SMON 维护映射) |
TIMESTAMP_TO_SCN(t) |
将时间戳转为近似 SCN |
SCN 健康监控与常见问题
SCN Headroom 检查
SCN 在很多情况下会增长,比如 Commit,Oracle 对这个增长进行控制。如果通过 DBLink 进行跨数据库访问,基于分布式一致性原理,Oracle 会将两个数据库的 SCN 时钟同步;通过 DBLink,SCN 低的被拉高,一旦超过数据库的允许限制,就会出错。如果数据库的 SCN 接近极限,则数据库就可能频繁出错,最坏的情况是事务都执行不了,数据库停顿。由于 SCN 不可以重置,严重情况甚至要重建数据库。
SCN 可用余量是指数据库当前使用的 SCN 与"不可突破"的上限值之间的差额。对于绝大多数 Oracle 数据库而言,这个余量每秒钟都在持续增长。
定义公式:
可用余量 = 当前 SCN 上限值 - 数据库已用 SCN 值
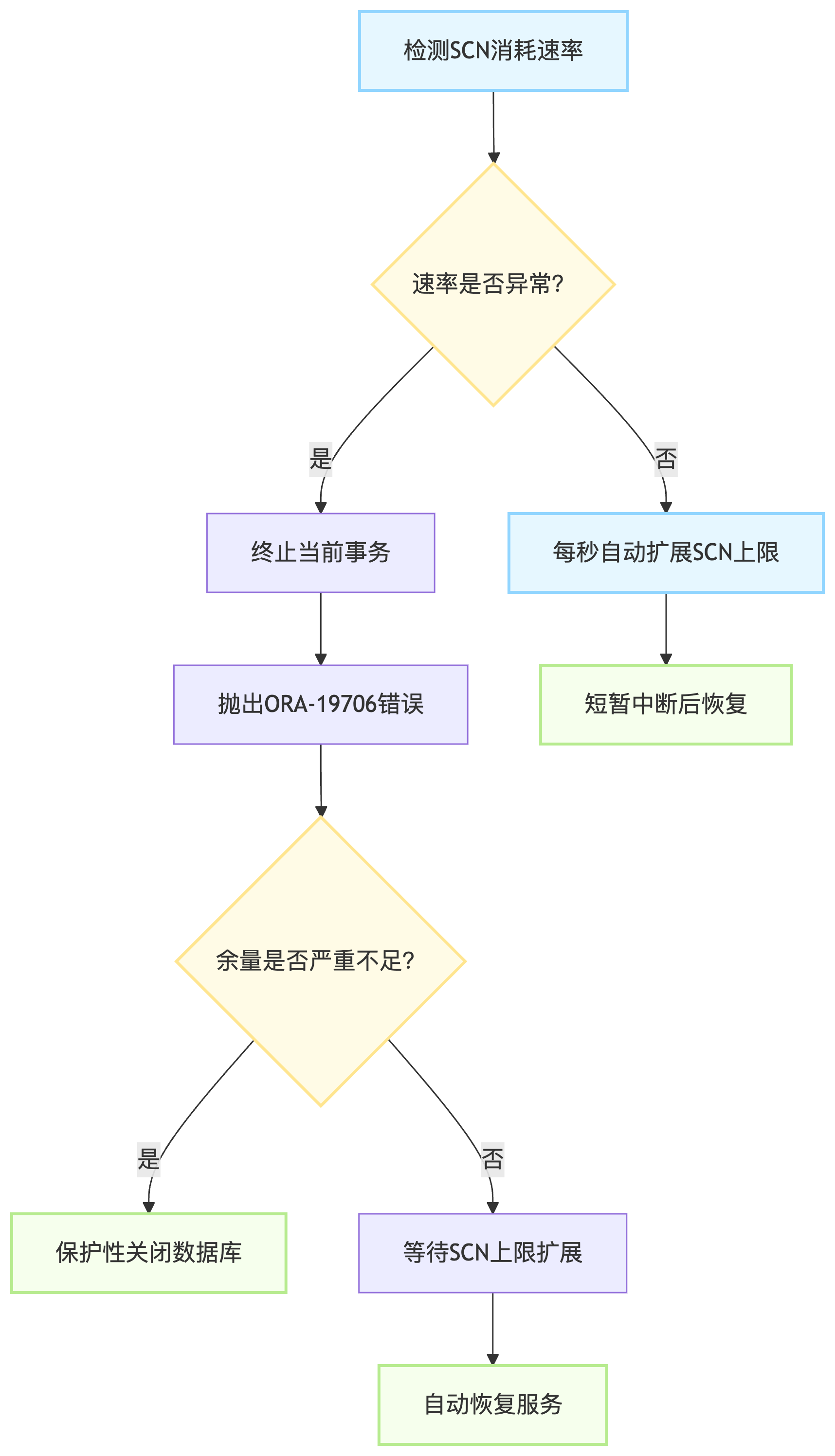
监控 SCN 增长速率和剩余空间(避免耗尽):
SELECT
VERSION,
TO_CHAR(SYSDATE, 'YYYY/MM/DD HH24:MI:SS') AS DATE_TIME,
(
(
-- 从 1988 年起,估算当前时间理论 SCN 值(按每秒 16K SCN 增长)
(((TO_NUMBER(TO_CHAR(SYSDATE, 'YYYY')) - 1988) * 12 * 31 * 24 * 60 * 60) +
((TO_NUMBER(TO_CHAR(SYSDATE, 'MM')) - 1) * 31 * 24 * 60 * 60) +
((TO_NUMBER(TO_CHAR(SYSDATE, 'DD')) - 1) * 24 * 60 * 60) +
(TO_NUMBER(TO_CHAR(SYSDATE, 'HH24')) * 60 * 60) +
(TO_NUMBER(TO_CHAR(SYSDATE, 'MI')) * 60) +
TO_NUMBER(TO_CHAR(SYSDATE, 'SS'))
) * (16 * 1024) -- 16000 SCNs/sec
)
- DBMS_FLASHBACK.GET_SYSTEM_CHANGE_NUMBER
) / (16 * 1024 * 60 * 60 * 24) AS INDICATOR -- 剩余天数
FROM
V$INSTANCE;
VERSION DATE_TIME INDICATOR
----------------- ------------------- ----------
19.0.0.0.0 2025/06/04 13:51:09 13922.5633
⚠️ 关键指标:若
headroom接近当前 SCN,需紧急处理(如打补丁或联系 Oracle 支持)。
常见故障场景
- SCN 耗尽:64 位 SCN 虽极大但仍可能因 Bug 或恶意攻击耗尽(如 2012 年 “SCN 漏洞”)。
- SCN 跳跃(Leap):非常规操作(如
ALTER SYSTEM SET SCN)导致 SCN 异常增长,破坏一致性。 _allow_resetlogs_corruption误用:强制OPEN RESETLOGS可能造成 SCN 不一致。
最佳实践与管理建议
- 定期监控 SCN 增长率:
SELECT current_scn, systimestamp FROM v$database; -- 间隔采样计算速率 - 避免手动修改 SCN:
ALTER SYSTEM SET SCN仅限 Oracle 支持人员操作。 - 及时安装补丁:修复 SCN 相关漏洞(如 CVE-2012-0082)。
- Data Guard 环境:确保主备库 SCN 兼容性(使用相同位数 SCN)。
总结
SCN 是 Oracle 数据库维持事务一致性、实现高可用架构的核心基石。深入理解其生成逻辑、存储机制和应用场景,对数据库故障恢复、性能优化及架构设计至关重要。DBA 应掌握 SCN 监控方法,警惕潜在风险,确保数据库稳健运行。
参考 MOS 文章:
📚 推荐阅读:DBA 学习之路
如果这篇文章对你有帮助,推荐访问我的 Oracle DBA 系统学习站点,涵盖 100 天完整学习路线:
- 🔧 Oracle 安装部署 · RMAN 备份恢复 · Data Pump 数据迁移
- 🏗️ RAC 高可用 · DataGuard 容灾 · 多租户架构
- 🔍 故障排查 · 升级迁移 · GoldenGate 数据同步
