




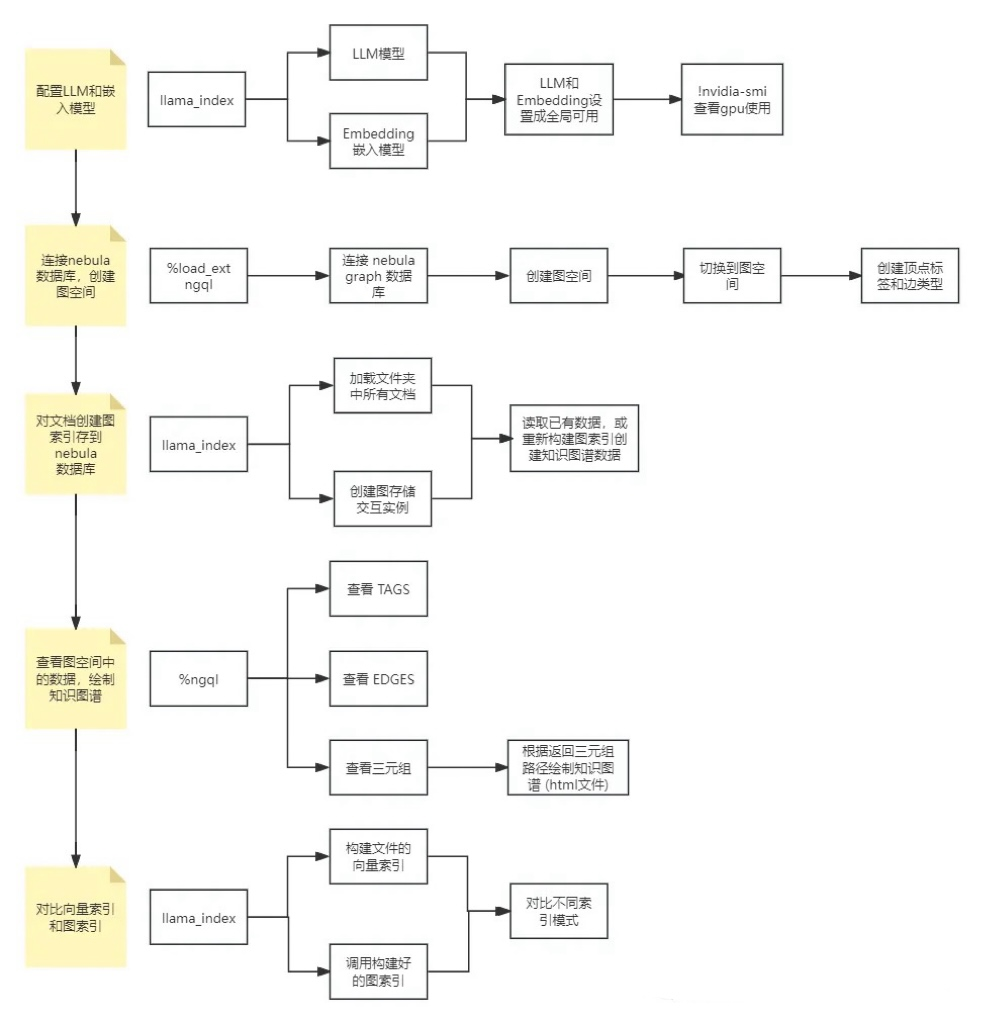
导读:
本地接入大模型和文本编码模型 利用模型对现有文件生成知识图谱数据 将知识图谱数据接入到 RAG 框架中提高回答准确性

配置本地大语言(LLM)模型和中文文本嵌入(Embedding)模型。 连接本地图数据库 NebulaGraph 并创建"wukong"图空间。 使用 LlamaIndex 加载本地文件夹中的文档,构建图索引并保存到 NebulaGraph 数据库的图空间。 查看保存到 NebulaGraph 的"wukong"的数据,并绘制知识图谱可视化的 html 格式文件。 对比常规向量语义查询的结果和知识图谱的查询结果。
# 导入 nest_asyncio 模块,该模块允许在同一进程中运行多个异步事件循环。
import nest_asyncio
# 应用 nest_asyncio,这将修补默认的 asyncio 事件循环策略,
# 使其支持在已经运行的事件循环中再创建新的事件循环。
nest_asyncio.apply()
# 从 vLLM 模块中导入 Vllm 类,vLLM 是一个高性能的推理引擎,专门用于大语言模型。
from llama_index.llms.vllm import Vllm
# 创建一个 Vllm 实例,初始化参数如下:
llm = Vllm(
# 模型路径,指定模型的具体位置。在这里,我的模型位于 home/iip/.cache/modelscope/hub/qwen/Qwen2-7B-Instruct-GPTQ-Int4,添加你自己的位置即可
model="/home/iip/.cache/modelscope/hub/qwen/Qwen2-7B-Instruct-GPTQ-Int4",
# 数据类型的设定,不同模型会有所不同。在这里,Qwen2-7B-Instruct-GPTQ-Int4 模型支持使用 float16 类型
dtype="float16",
# 张量并行的大小,用于在多个 GPU 上分割模型。在这里,设置为 1,表示不在多个 GPU 上分割模型
tensor_parallel_size=1,
# 温度参数,取值范围 0-1,用于控制生成文本的随机性。温度为 0 表示确定性生成,即每次生成相同的结果
temperature=0.1,
# 最大生成的新标记数,用于限制生成文本的最大长度
max_new_tokens=100,
# 传递给 vLLM 的额外关键字参数,用于进一步配置模型
vllm_kwargs={
# 交换空间大小,当 GPU 显存不足时,swap_space 允许将部分内存数据存储在 CPU 上,1 代表 1GB。
"swap_space": 1,
# GPU 内存利用率,用于控制 GPU 内存的使用比例。在这里,设置为 0.8,尤其是在多进程或多用户环境,在此为编码模型保留一部分可用显存
"gpu_memory_utilization": 0.8,
# 最大模型长度,用于限制输入序列的最大长度。在这里,设置为 8192
"max_model_len": 8192,
}
)
# 从 llama_index 的 embeddings 模块中导入 HuggingFaceEmbedding 类
# HuggingFaceEmbedding 类用于初始化和配置 Hugging Face 的嵌入模型
from llama_index.embeddings.huggingface import HuggingFaceEmbedding
# 定义嵌入模型的配置参数
embed_args = {
# 指定使用的预训练模型名称
'model_name': 'GanymedeNil/text2vec-large-chinese',
# 设置输入文本的最大长度为 512,超过这个长度的文本将会被截断。
'max_length': 512,
# 设置批量嵌入的批次大小。在这里,设置为 64,即一次处理 64 个文本样本
'embed_batch_size': 64,
from llama_index.core import Settings
# 把加载的模型添加到环境设置中,定义全局模型。Settings 类用于配置全局设置,可以用来保存和管理全局变量。
# 此处将刚刚设置的语言模型(LLM)和嵌入模型(Embedding Model)定义为全局可用。
Settings.llm = llm
Settings.embed_model = embed_model
命令查看当前 GPU 的使用情况,可以看到,加载了大语言模型和文本嵌入模型之后,12G 的显存已经占用了将近 10G:!nvidia-smi
NVIDIA-SMI 版本:
显示当前 NVIDIA-SMI 的版本、驱动程序版本和 CUDA 版本。
GPU 信息:
Name:显示 GPU 的型号。
Persistence-M:显示 GPU 的持久模式状态。
Bus-Id:显示 GPU 的 PCI Bus ID。
Disp.A:显示 GPU 是否被用作显示设备。
Volatile Uncorr. ECC:显示易失性未校正的 ECC 错误。
状态信息:
Fan:显示风扇转速百分比。
Temp:显示 GPU 温度。
Perf:显示性能状态。
Pwr:Usage/Cap:显示当前功耗和最大功耗。
Memory-Usage:显示当前 GPU 内存使用情况。
GPU-Util:显示 GPU 使用率。
Compute M.:显示当前计算模式。
MIG Mode:显示 MIG 模式状态。
进程信息:列出正在使用 GPU 的进程及其占用的 GPU 内存。
使用场景
检查 GPU 状态:在运行深度学习模型或任何 GPU 密集型任务之前,可以使用 nvidia-smi 来检查 GPU 的状态,确保 GPU 没有被其他进程占用。
监控 GPU 使用情况:在任务运行过程中,可以定期执行 nvidia-smi 命令来监控 GPU 的使用情况,确保资源得到有效利用。
在像 Jupyter Notebook 这样的环境中,魔法命令(magic commands)是一种内置的功能,用于执行一些特定的操作,例如运行系统命令、时间测量、配置等。这些命令通常以%开头(对于行魔法命令)或%%开头(对于单元格魔法命令)。
使用 Jupyter Notebook 的魔法命令加载 ngql 扩展
%load_ext ngql
# 使用 ngql 魔法命令连接到 NebulaGraph 数据库
# %ngql 告诉环境接下来的代码块应该被当作 nGQL 语句来执行
# 指定数据库的地址、端口、用户名和密码。默认情况下,身份认证功能是关闭的,只能使用已存在的用户名(默认为root)和任意密码登录。
%ngql --address 127.0.0.1 --port 9669 --user root --password nebula
Jupyter Notebook 默认只认识标准的编程语言语法(如 Python)。如果不加载扩展,它无法识别 nGQL 语句。
加载扩展%load_ext ngql的作用是告诉 Jupyter Notebook,接下来我要使用一个名为 nGQL 的新功能,这个功能就是%ngql魔法命令。通俗解释魔法命令。
加载扩展之后,Jupyter Notebook 就能够识别%ngql并正确地处理它,允许你在 Jupyter Notebook 中执行 nGQL 语句。
如果 "wukong" 图空间(知识图谱)不存在,则使用 nGQL 魔法命令创建一个名为 "wukong" 的图空间
# 指定顶点 ID (vertex ID) 的类型为长度为 256 的固定字符串
# 设置分区数量为 1
# 设置副本因子为 1,即只保留一个副本
%ngql CREATE SPACE IF NOT EXISTS wukong(vid_type=FIXED_STRING(256), partition_num=1, replica_factor=1);
在 NebulaGraph 中,VID(Vertex ID)是用于唯一标识图中的每个顶点(节点)的标识符。在创建图空间时,VID 的类型可以通过 vid_type 参数指定,可以是 FIXED_STRING(<N>) 或 INT64。
vid_type=FIXED_STRING(256):这表示每个顶点的 ID 必须是一个定长字符串,长度为 256 字节。换句话说,所有的 VID 都会被存储为 256 字节的字符串。如果插入的字符串长度不足 256 字节,系统会自动用空字节填充。如果你有一个用户的唯一标识符是 "user123",在插入时,系统会将其存储为 "user123" 后面跟着空字节,一共占用256个字节。 vid_type=INT64:表示图空间中的点 ID(VID)将被定义为 64 位有符号整数。如果你使用整数作为 VID,可以直接插入一个数字。
分区(Partitioning)
提高并发处理能力:将数据切分成多个分区可以提高系统的并发处理能力。每个分区可以独立处理请求,从而提高整体的处理速度。 负载均衡:分区可以帮助负载均衡,避免数据集中在一个节点上导致性能瓶颈。 分区是分布式系统中常用的一种技术,用于将数据切分成多个部分,并将这些部分存储在不同的节点(通常是计算机)上。分区的主要目的是:
常见的分区数量范围
小规模数据:如果数据量较小(例如几百万顶点和边),可以选择较少的分区数量,通常 1 到 4 个分区就足够了。 中等规模数据:如果数据量中等(例如几千万顶点和边),可以选择较多的分区数量,通常 4 到 16 个分区是比较常见的。 大规模数据:如果数据量很大(例如数亿甚至数十亿顶点和边),可以选择更多的分区数量,通常 16 到 128 个分区是比较常见的。
副本(Replication)
提高可靠性:通过为每个分区创建多个副本,可以确保即使某个节点发生故障,数据仍然可以被访问。 容错能力:当一个节点失效时,可以从其他节点的副本中恢复数据,确保系统的持续可用性。比如为每个分区创建多个副本,每个副本存储在不同的节点上,一个节点坏了依然能正常运行。 副本是另一种分布式系统中常用的技术,用于提高数据的可靠性和容错能力。副本的主要目的是:
常见副本选择范围:
对于一般的数据,通常选择 replica_factor=3 已经足够。 如果资源有限,可以选择较低的副本数量,如 replica_factor=2。
# USE 语句用于切换到指定的图空间(知识图谱)
%ngql USE wukong;
# 创建名为 'entity' 的顶点标签,如果尚不存在的话
%ngql CREATE TAG IF NOT EXISTS entity(name string);
# 创建名为 'relationship' 的边类型,并定义一个字符串属性 'label',如果尚不存在的话
%ngql CREATE EDGE IF NOT EXISTS relationship(label string);
# 等待 10 秒,用于确保数据已经被正确创建完成
import time
time.sleep(10) # 暂停执行 10 秒
# 从 llama_index.core 模块中导入 SimpleDirectoryReader 类
# SimpleDirectoryReader 用于读取目录中的文档
from llama_index.core import SimpleDirectoryReader
# 加载本地数据
# 使用 SimpleDirectoryReader 读取指定目录中的所有文档
# load_data() 方法用于加载这些文档,本案例用的 txt 文件。除此之外,还可读取 csv, docx, epub, jpeg, mp3, pdf等文件。
documents = SimpleDirectoryReader("./data").load_data()
from llama_index.graph_stores.nebula import NebulaGraphStore # 用于连接和操作 NebulaGraph 图数据库
# 设置环境变量以存储 NebulaGraph 的认证信息
# 当使用 Python 客户端工具连接到 NebulaGraph 数据库时,会使用这些信息进行身份验证
os.environ["NEBULA_USER"] = "root"# NebulaGraph 用户名
os.environ["NEBULA_PASSWORD"] = "nebula"# NebulaGraph 密码
os.environ["NEBULA_ADDRESS"] = "127.0.0.1:9669"# NebulaGraph 数据库的地址和端口号
# 配置 NebulaGraph 知识图谱的相关信息,如图空间名称、边类型、关系属性、节点标签
space_name = "wukong"# 知识图谱空间名称
edge_types = ["relationship"] # 定义图中关系的类型(边)
rel_prop_names = ["label"] # 关系属性名称
tags = ["entity"] # 定义图中实体的标签
# 创建一个 NebulaGraphStore 实例,负责与 NebulaGraph 图数据库进行交互
# 创建 StorageContext 实例,用于配置图存储上下文,包括持久化存储目录和图存储实例
from llama_index.core.storage.storage_context import StorageContext
storage_context = StorageContext.from_defaults(
graph_store=graph_store, # 使用上面定义的 NebulaGraphStore 作为图存储实例
)
from llama_index.core.storage.storage_context import StorageContext # 存储上下文管理
from llama_index.core import load_index_from_storage, SimpleDirectoryReader, KnowledgeGraphIndex # 加载索引、读取文档、知识图谱索引
import logging
try:
# 尝试从持久化目录加载已存在的索引
storage_context = StorageContext.from_defaults(
persist_dir="./storage_graph", # 持久化存储目录
graph_store=graph_store, # 使用前面创建的 NebulaGraph 存储
)
kg_index = load_index_from_storage(
storage_context=storage_context,
max_triplets_per_chunk=50, # 每个分块最多包含的三元组数量
space_name=space_name,
edge_types=edge_types,
rel_prop_names=rel_prop_names,
tags=tags,
verbose=True, # 输出详细信息
)
index_loaded = True
except Exception as e:
# 如果加载失败,打印错误并设置index_loaded 为 False
logging.error(f"索引加载失败: {e}")
index_loaded = False
# 使用 nGQL 魔法命令执行 nGQL 语句
# SHOW TAGS 语句用于列出图空间中的所有标签(顶点类型)
"""
使用场景
查看图空间结构:当你需要查看当前图空间中定义了哪些标签(顶点类型)时,可以使用 SHOW TAGS 命令。
调试和验证:在进行图数据库的操作时,查看图空间中的标签可以帮助你验证数据结构是否符合预期。
"""
# 刚刚已经切换到了名为 wukong 的图空间,并且需要查看该图空间中的所有标签(顶点类型)
%ngql SHOW TAGS
# 使用 nGQL 魔法命令执行 nGQL 语句
# SHOW EDGES 语句用于列出图空间中的所有边类型
"""
使用场景
查看图空间结构:当你需要查看当前图空间中定义了哪些边类型时,可以使用 SHOW EDGES 命令。
"""
%ngql SHOW EDGES
# 查询并返回图数据库中实体间的关系路径
# 本查询将匹配所有从一个节点(v)出发,通过任意类型关系(r)到达另一个节点(t)的路径。
# 对于每条匹配到的路径,返回源节点的名称(v.entity.name)作为`src`,
# 关系的标签(r.label)作为`relation`,目标节点的名称(t.entity.name)作为`dest`。
# 结果限制为最多1000条记录。
%ngql MATCH p=(v)-[r]->(t) RETURN v.entity.name AS src, r.label AS relation, t.entity.name AS dest LIMIT 1000;
# 查询图数据库中的路径并返回
# 本查询匹配从一个节点(v)出发,通过任意类型的关系(r)到达另一个节点(t)的所有路径。
# 使用`MATCH`子句定义了路径模式p=(v)-[r]->(t),其中v是起始节点,r是连接v和t的关系,t是目标节点。
# `RETURN p`表示返回整个路径p,包含了起始节点、关系以及目标节点的信息。
# `LIMIT 1000`限制了结果集的大小,确保最多返回1000条路径。
%ngql MATCH p=(v)-[r]->(t) RETURN p LIMIT 1000;
ng_draw魔法命令执行图形绘制功能,对"wukong"图空间中的三元组数据,生成能进行知识图谱可视化的 html 文件。此处将会根据查询返回的内容进行绘图,图片会以 html 格式的文件存储:
绘制图数据库中实体之间的关系图
# 本查询使用`ng_draw`魔法命令来可视化从一个类型为`entity`的节点出发,
# 通过任意`relationship`类型的关系到达另一个类型为`entity`的节点的所有路径。
# 查询将返回最多 1000 条这样的路径,并且这些路径将会被绘制出来。
%ng_draw MATCH p=(v:entity)-[r:relationship]->(t:entity) RETURN p LIMIT 1000;
# 导入 VectorStoreIndex 类,这是 llama_index 库中的一个核心组件,用于创建向量存储索引
from llama_index.core import VectorStoreIndex
# 创建一个 VectorStoreIndex 实例,该实例是从提供的文档集合 (documents) 构建的
# documents 是一个包含 Document 对象的列表,这些对象包含了索引所需的数据
vector_index = VectorStoreIndex.from_documents(documents)
from IPython.display import Markdown, display
# 创建一个查询引擎,用于执行基于向量的查询
# 查询引擎可以从向量索引中检索相关信息,并提供统一的查询接口
# 这样可以将查询逻辑与索引分离,提高代码的可读性和可维护性
vector_query_engine = vector_index.as_query_engine()
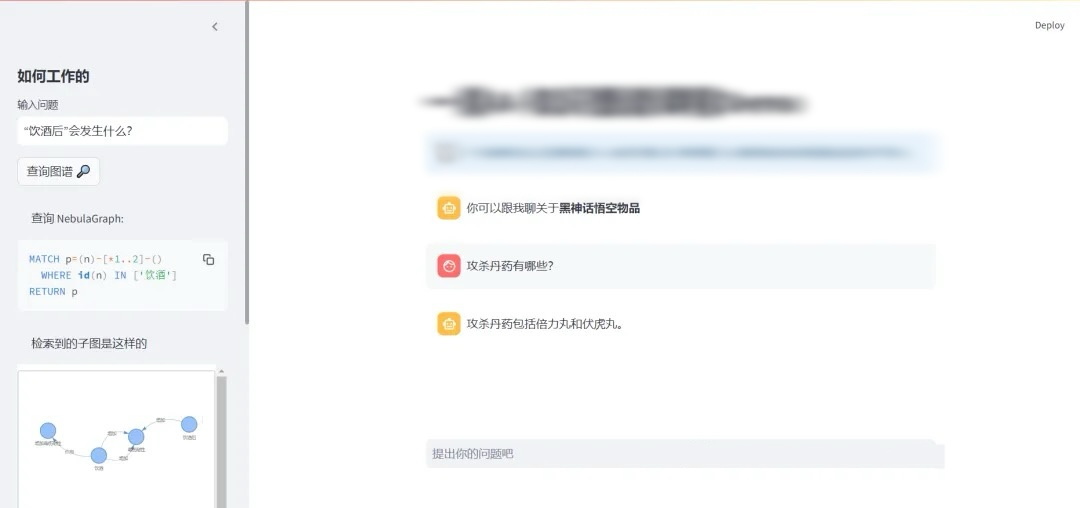
# 使用查询引擎执行一个查询:"攻杀丹药有哪些?"
# 查询引擎会将用户的查询转换为向量,并计算与向量索引中向量的相似度
# 返回与查询最相关的结果
vector_response = vector_query_engine.query("攻杀丹药有哪些?")
# 将查询结果以加粗的 Markdown 格式显示在 Jupyter Notebook 中
# 这样可以以可读的格式展示查询结果,方便用户理解
display(Markdown(f"<b>{vector_response}</b>"))
# 打印引用的文本块数量
# len(vector_response.source_nodes) 计算引用的文本块数量
print(f"引用了 {len(vector_response.source_nodes)} 个文本块。")
# 提取所有引用节点的文本
# 使用列表推导式遍历 source_nodes 并获取每个节点的文本
source_texts = [node.node.get_text() for node in vector_response.source_nodes]
# 从知识图谱索引创建查询引擎
# 使用 as_query_engine 方法将 kg_index 转换为查询引擎,
# include_text=True 的作用是确保查询结果不仅返回知识图中的结构化数据(如节点和它们之间的关系),还包括与这些节点相关的原始文本内容。
kg_query_engine = kg_index.as_query_engine(include_text=True)
# 使用查询引擎执行查询
# 查询问题是 "攻杀丹药有哪些?"
# kg_response 存储查询结果
kg_response = kg_query_engine.query("攻杀丹药有哪些?")
# 显示查询结果
# 使用 Markdown 格式展示查询结果
display(Markdown(f"<b>{kg_response}</b>"))
import pandas as pd
# 定义查询问题
query_question = "攻杀丹药有哪些??"
# 常规查询引擎的查询质量
vector_query_engine = vector_index.as_query_engine()
vector_response = vector_query_engine.query(query_question)
vector_results = str(vector_response)
# 知识图谱的查询质量
kg_query_engine = kg_index.as_query_engine(include_text=True)
kg_response = kg_query_engine.query(query_question)
kg_results = str(kg_response)
import pandas as pd
# 定义查询问题
query_question = "攻杀丹药有哪些?"
# 常规查询引擎的质量
vector_query_engine = vector_index.as_query_engine()
vector_response = vector_query_engine.query(query_question)
vector_results = str(vector_response)
# 获取常规查询引擎的引用数据
vector_sources = []
vector_source_texts = []
if hasattr(vector_response, 'source_nodes'):
# 如果查询结果包含来源节点,则提取其文本
vector_sources = [node.node.get_text() for node in vector_response.source_nodes]
vector_source_texts = ', '.join(vector_sources)
else:
# 如果查询结果不包含来源节点,则设置默认提示
vector_source_texts = '无法获取来源'
# 接入知识图谱的查询结果
kg_query_engine = kg_index.as_query_engine(include_text=True)
kg_response = kg_query_engine.query(query_question)
kg_results = str(kg_response)
# 获取知识图谱查询引擎的节点信息
kg_retriever = kg_index.as_retriever(include_text=True)
kg_nodes = kg_retriever.retrieve(query_question)
kg_node_texts = ', '.join([node.text for node in kg_nodes])
# 创建DataFrame进行对比
comparison_df = pd.DataFrame({
'查询问题': [query_question, query_question],
'常规RAG回答': [vector_results, vector_source_texts],
'知识图谱回答': [kg_results, kg_node_texts]
})
NebulaGraph 邀你参加开源之夏🌟⬇️
✦
如果你觉得 NebulaGraph 能帮到你,或者你只是单纯支持开源精神,可以在 GitHub 上为 NebulaGraph 点个 Star!每一个 Star 都是对我们的支持和鼓励✨
https://github.com/vesoft-inc/nebula
✦
✦

扫码添加
可爱星云
技术交流
资料分享
NebulaGraph 用户案例
✦
风控场景:携程|Airwallex|众安保险|中国移动|Akulaku|邦盛科技|360数科|BOSS直聘|金蝶征信|快手|青藤云安全
平台建设:博睿数据|携程|众安科技|微信|OPPO|vivo|美团|百度爱番番|携程金融|普适智能|BIGO
✦
✦



文章转载自NebulaGraph 技术社区,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
