如果将大模型视为一个知识丰富但记忆有限的专家,RAG系统则是为其配备了一个能够实时检索和提供准确信息的辅助工具。
而关于如何低门槛搭建一个RAG系统系统,很多朋友可能会纠结究竟选择N8N 还是Dify。
如何用Dify+Milvus搭建一个RAG系统,可以参考我们此前发布的教程:
本文,我们则将通过N8N和Milvus这两个实用工具来带大家手把手做一个RAG应用。
01
为什么我们选择N8N+Milvus组合?
N8N和Dify,分别代表了不同的工作流搭建思路,概括来说:N8N是通用工作流工具,可以连接几乎任何系统,处理各种自动化任务,不仅限于AI领域;而Dify是专注于AI应用的开发平台,专为生成式AI应用定制,内置了与各种LLM模型的连接能力。
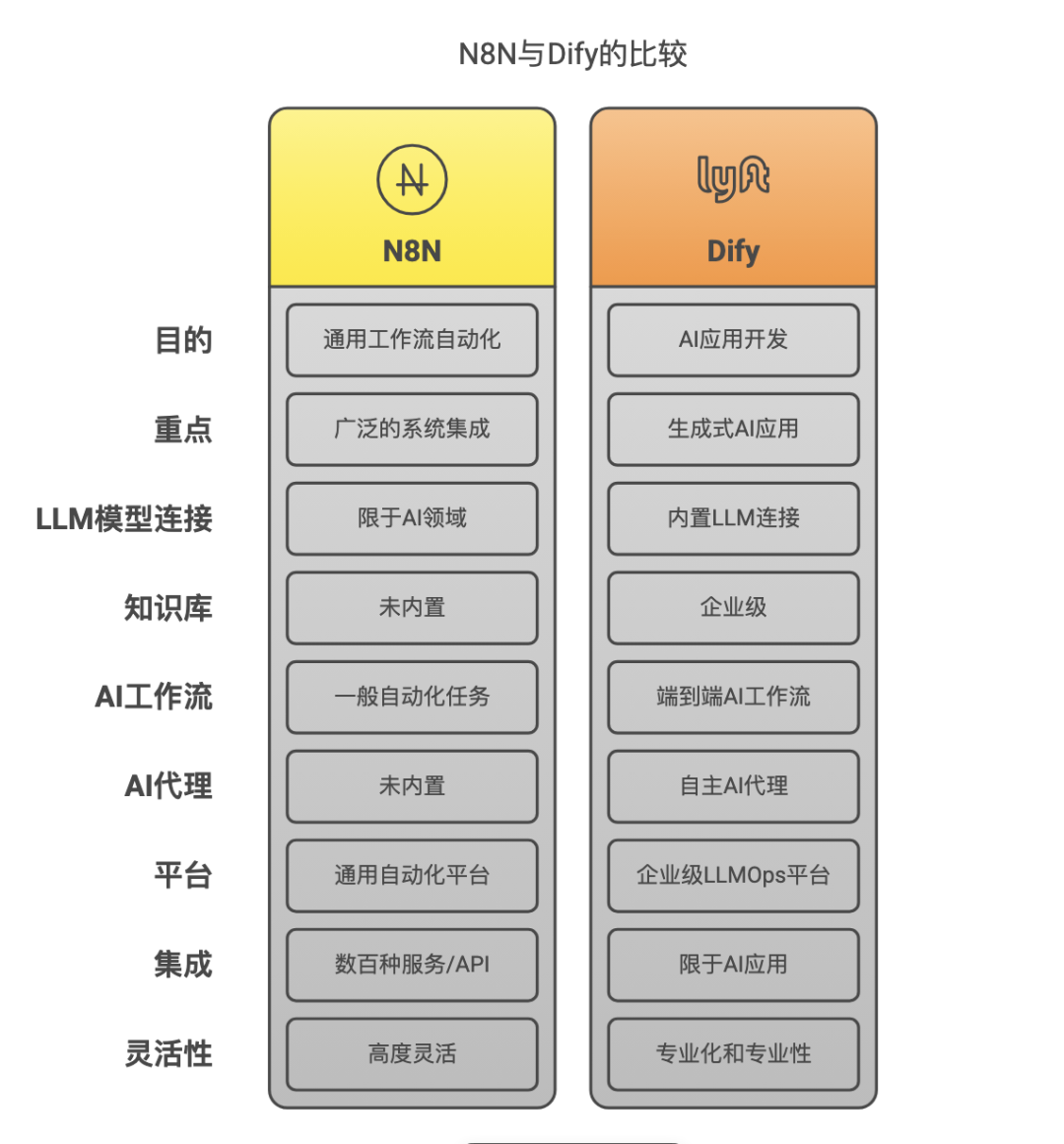
在本文中,我们选择N8N和Milvus的组合,是因为N8N可以连接数百种不同的服务和API,负责多系统集成和工作流编排,Milvus提供高效向量检索,二者结合既自由又高效,便于深入理解RAG系统。
相比一体化平台,这种“从零搭建”更具学习价值,但实际应用中专业平台如Dify部署更快、功能更全。
02
部署教程
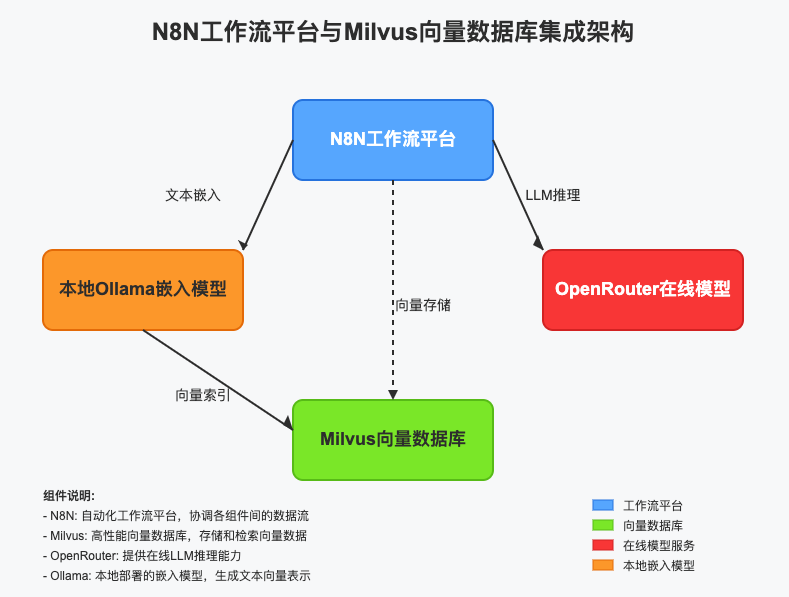
部署架构总览及说明
环境准备说明
本教程不含docker和docker-compose以及Ollama安装展示,请自行按照官方手册进行配置。
docker官网:https://www.docker.com/
Milvus官网:https://milvus.io/docs/prerequisite-docker.md
N8N官网:https://n8n.io/
Ollama官网:https://ollama.com

1.模型配置
本文采用Ollama运行嵌入模型并提供服务。
1.1下载并检查embedding模型
执行以下命令下载 nomic-embed-text:latest
模型:
[root@ollama ~]# ollama pull nomic-embed-text:latest下载完成后,使用以下命令检查模型是否成功拉取:
[root@ollama ~]# ollama list |grep nomic-embed-text:latest

1.2配置LLM大模型
说明:本文采用OpenRouter提供的在线免费模型进行演示。若使用其他收费在线模型,请注意其计费模式。
打开OpenRouter首页并登录
选中Models菜单
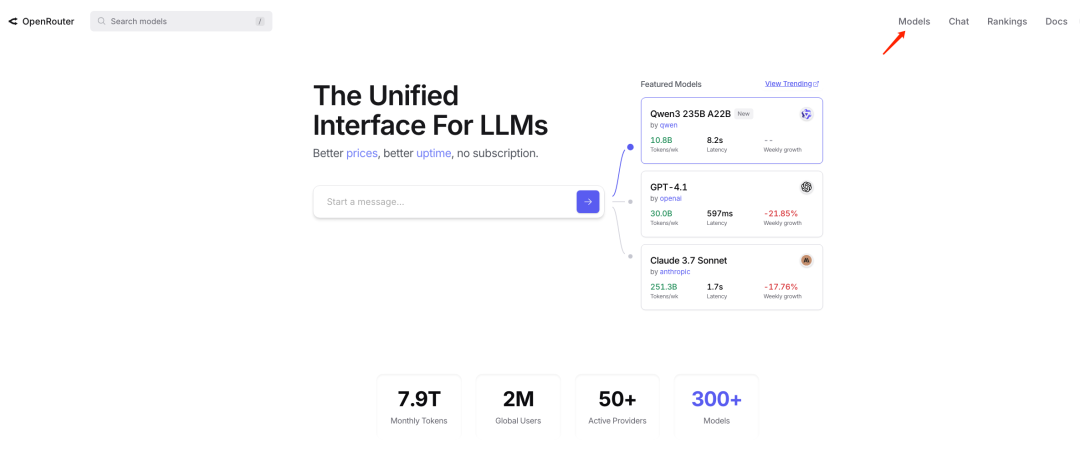
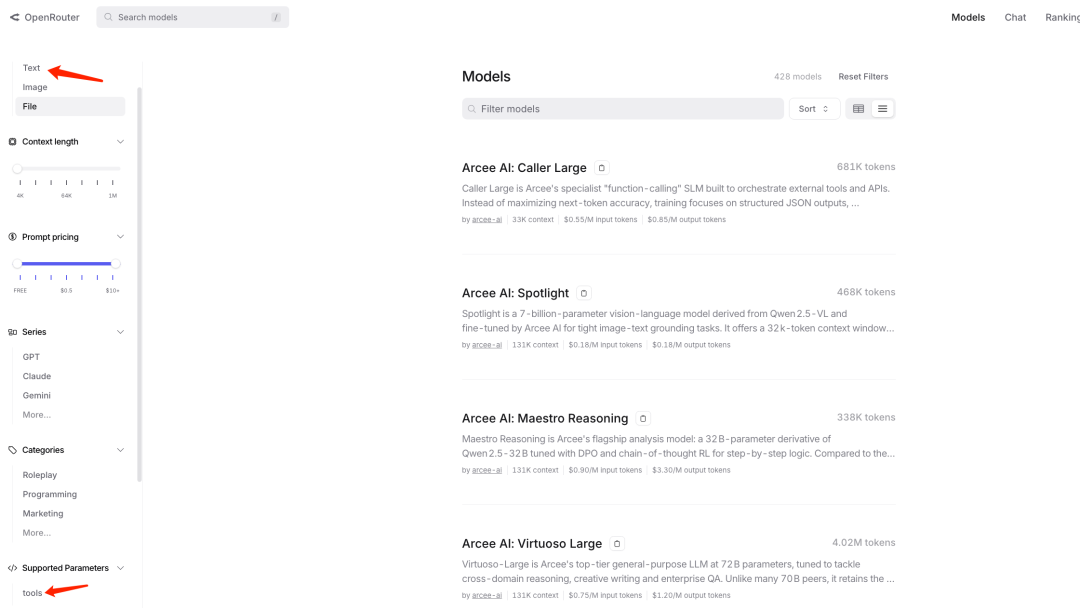
选择支持Tools的模型
说明:为保证一定能选到支持Tools的模型,请务必增加筛选条件。根据您的需求筛选并选择合适的模型。
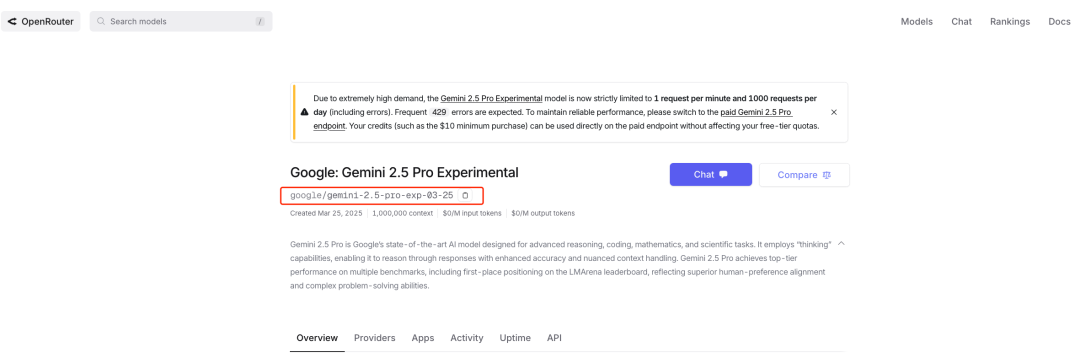
选择并确认模型的名称
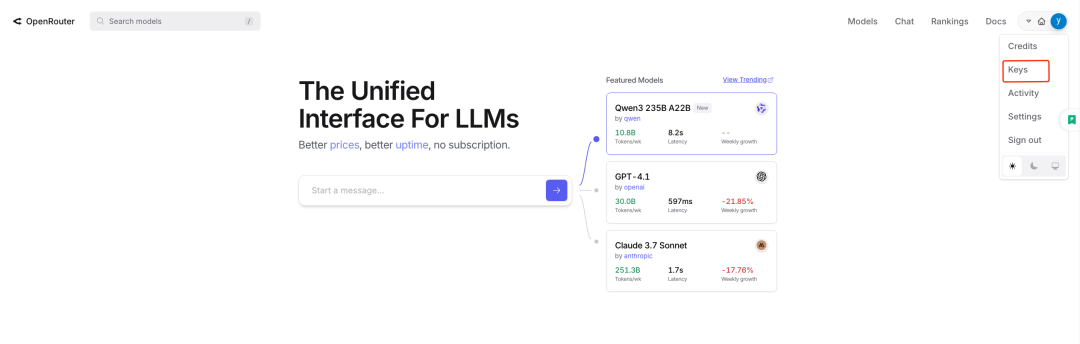
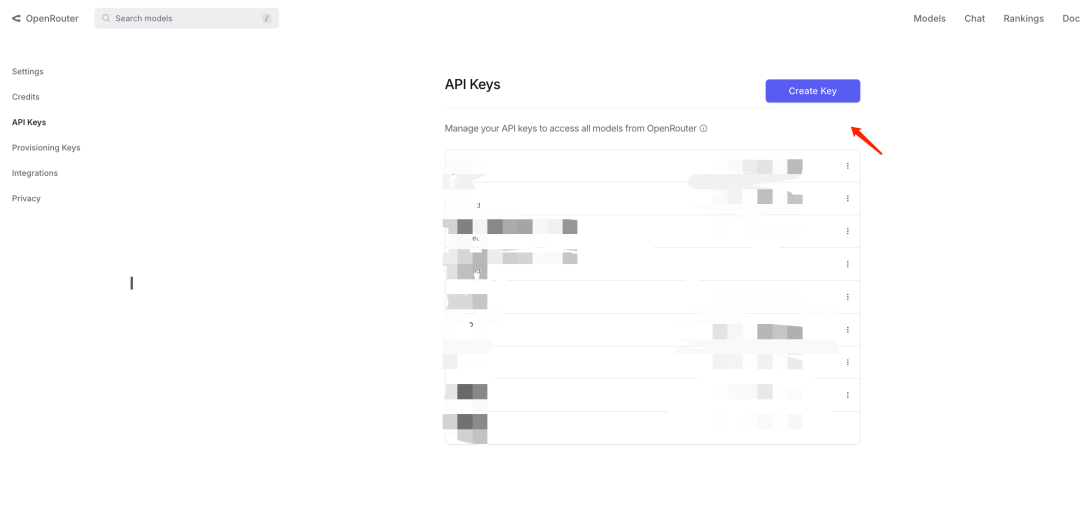
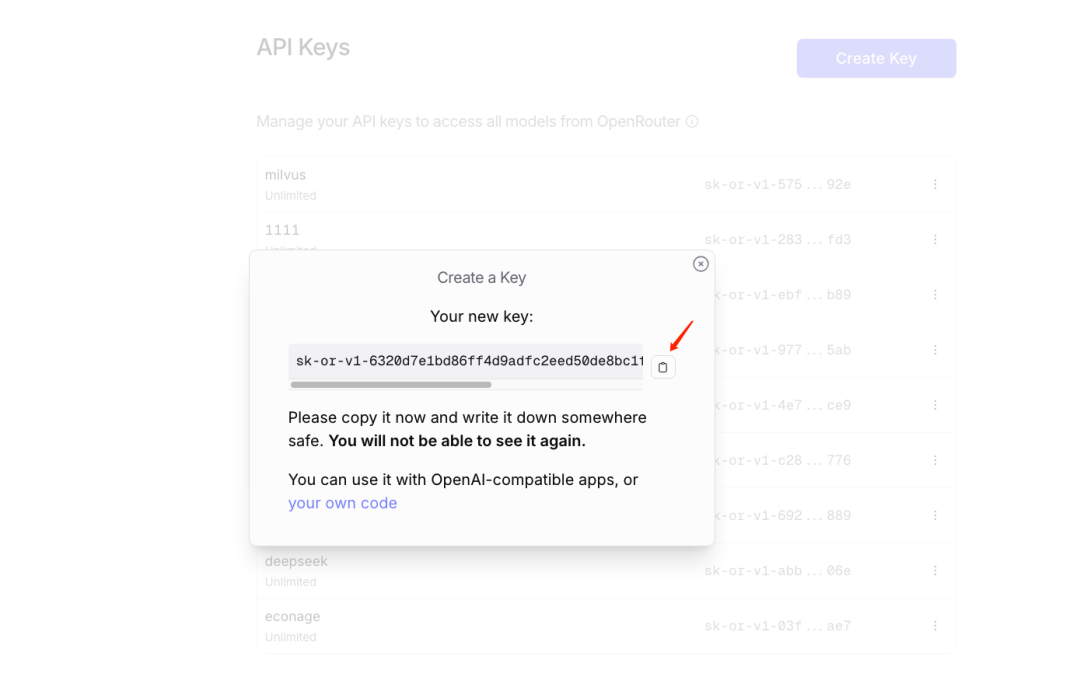
创建API-KEY
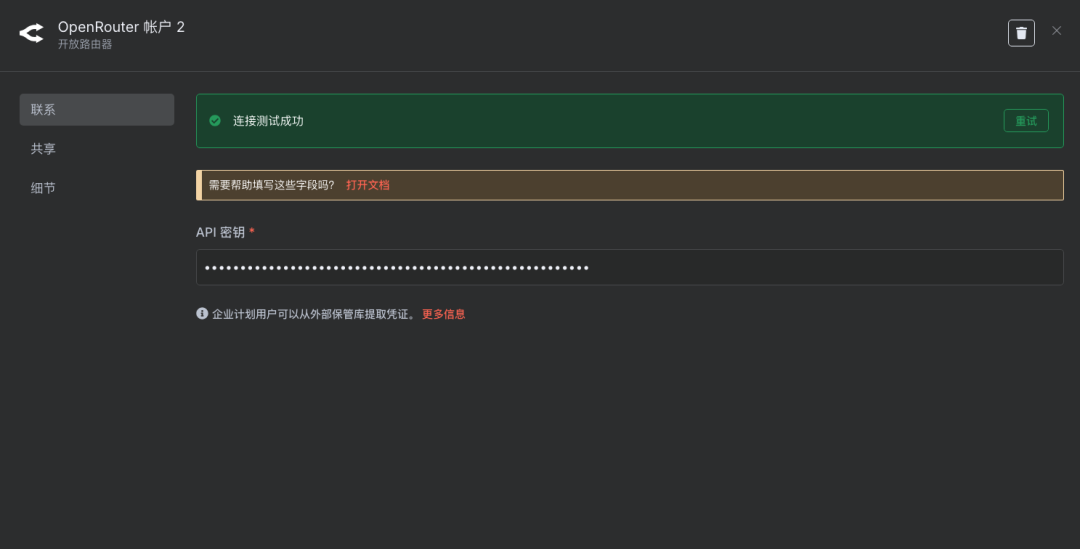
说明:在OpenRouter中为选定的模型创建一个API密钥(API-KEY),此密钥将用于后续的API调用。
2.Milvus 安装与配置
Milvus是由Zilliz开发的全球首款开源向量数据库产品,能够处理数百万乃至数十亿级的向量数据,在GitHub上获得了3.5W星标。基于开源Milvus,Zilliz还构建了商业化向量数据库产品Zilliz Cloud,这是一款全托管的向量数据库服务,通过采用云原生设计理念,在易用性、成本效益和安全性上实现了全面提升。
2.1 部署Milvus环境要求
必要条件:
软件要求:Docker、Docker Compose
CPU:8核
内存:至少16GB
硬盘:至少100GB
2.2 下载部署文件
执行以下命令下载Milvus独立部署所需的docker-compose.yml
文件:
[root@Milvus ~]# wget https://github.com/milvus-io/milvus/releases/download/v2.5.4/milvus-standalone-docker-compose.yml -O docker-compose.yml
2.3 启动Milvus
使用下载的docker-compose.yml
文件启动Milvus服务:
[root@Milvus ~]# docker-compose up -d检查Milvus容器是否成功启动:
[root@Milvus ~]# docker ps -a

2.4 启用Attu管理面板
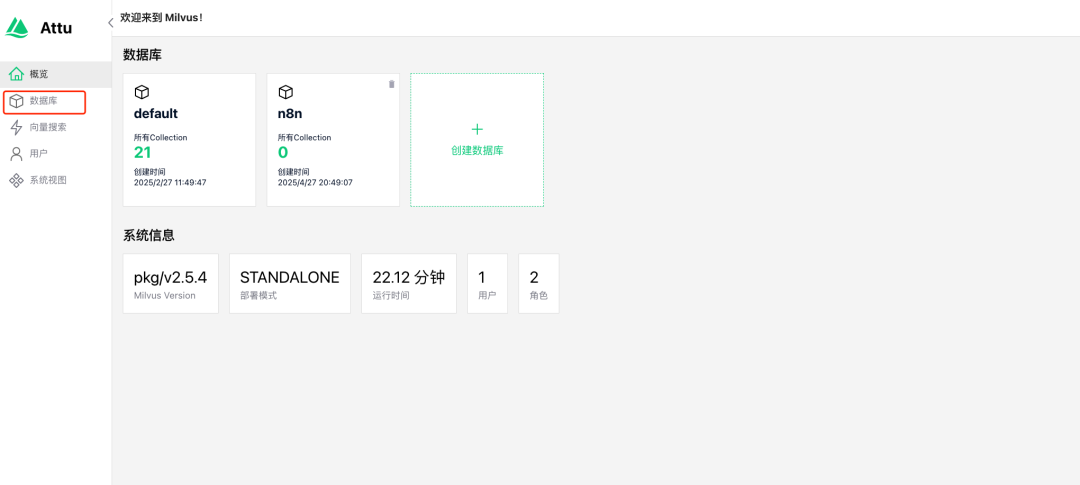
说明:N8N需要指明使用的向量数据库Collection,因此需要预先创建好备用。MILVUS_URL
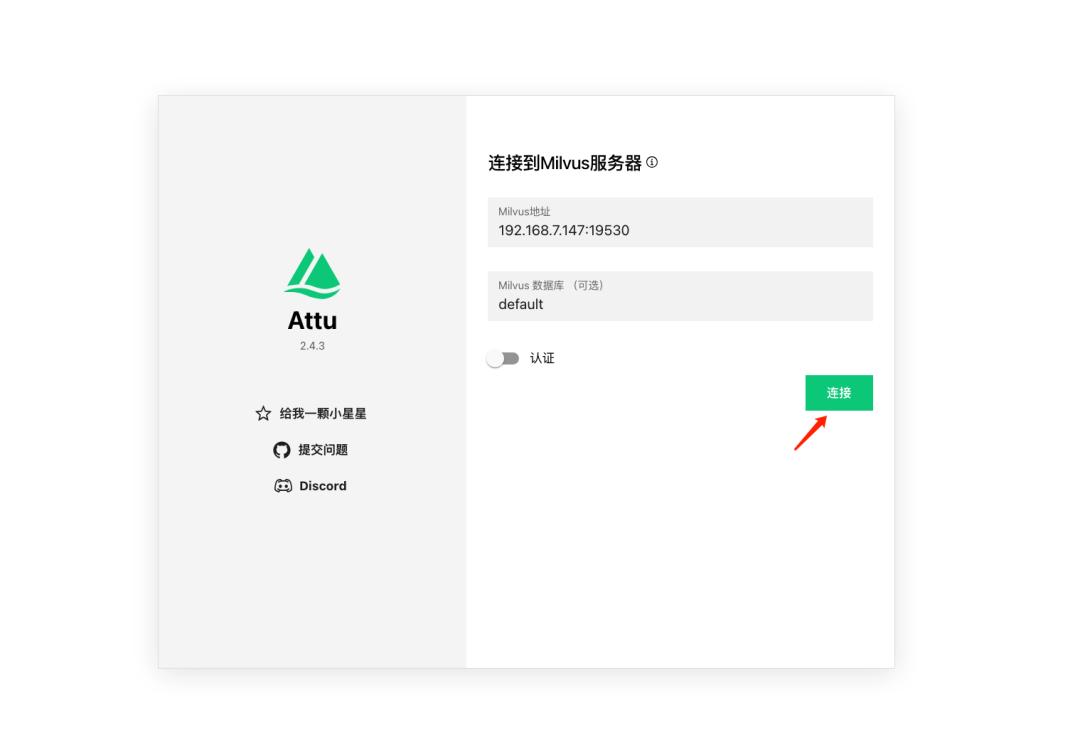
应填写Milvus服务所在的服务器IP地址及端口。 Attu是Milvus的图形化管理界面。使用以下命令启动Attu:
docker run -d -p 8000:3000 -e MILVUS_URL=192.168.7.147:19530 registry.cn-hangzhou.aliyuncs.com/xy-zy/attu:v2.5Attu面板将运行在 服务器IP:8000 。
2.5 登录Attu
2.6 选择数据库
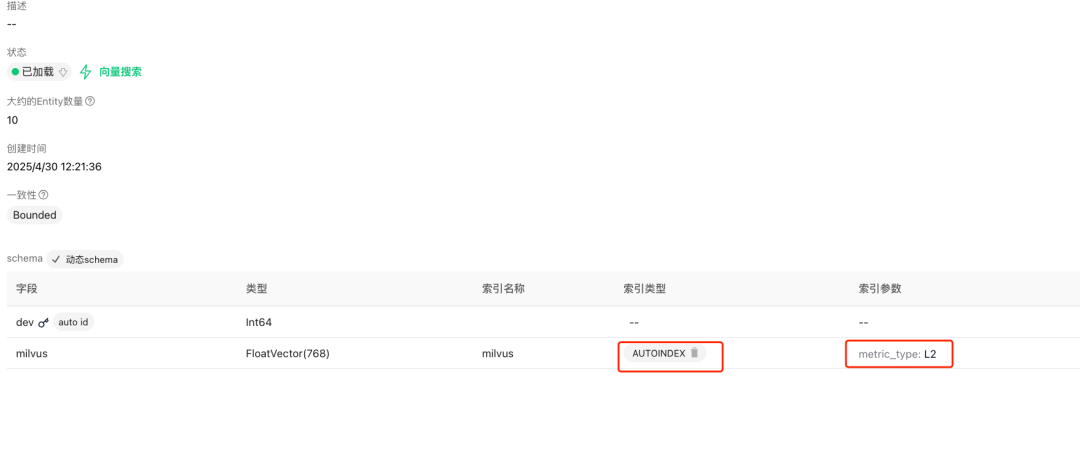
2.7 创建Collection
说明:在Attu中创建用于存储向量的Collection
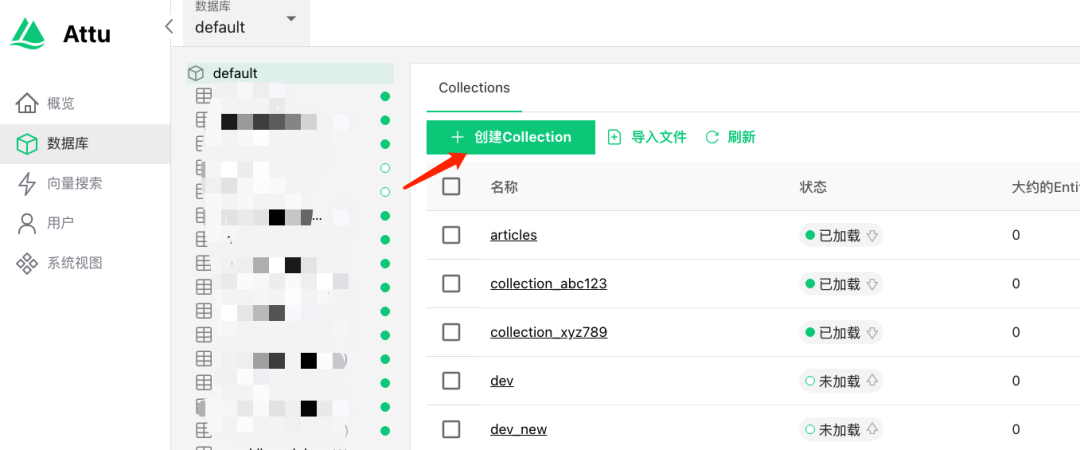
配置参数
参数说明:维度(Dimension)要和嵌入模型支持的大小相匹配,否则会导致嵌入失败。 根据您的嵌入模型输出向量的维度,正确配置Collection的维度参数。
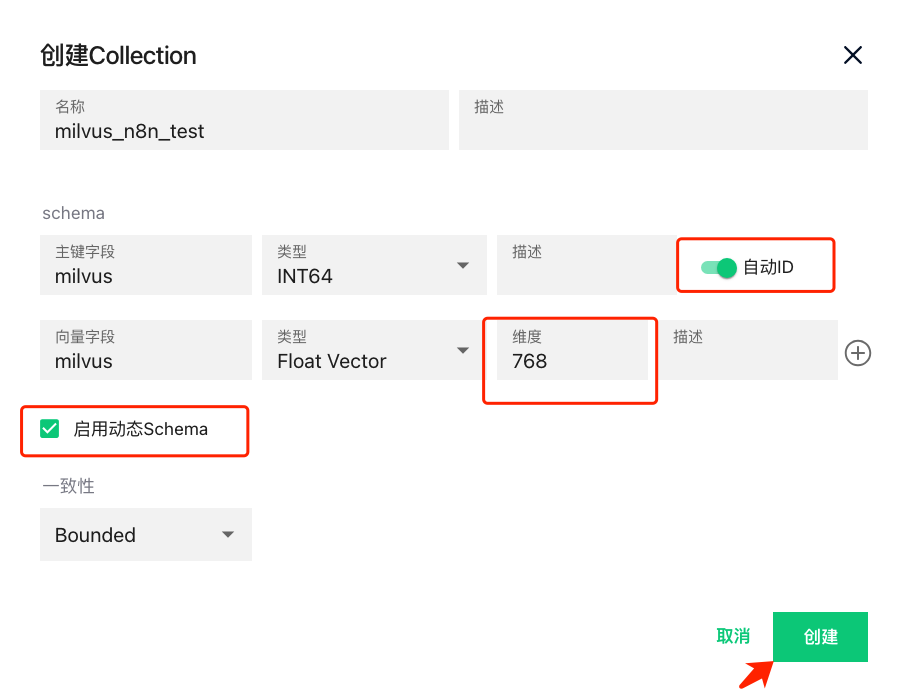
索引参数选择L2
参数说明:N8N封装的Milvus向量数据库组件默认支持的索引参数是 metric_type: L2
。如果创建的Collection配置的索引参数是 COSINE
,可能会导致插入失败。(关于是否支持COSINE
,请关注N8N官方更新)。 在创建Collection时,将索引的度量类型(Metric Type)选择为L2。
03
N8N 安装与初始化
N8N是一个强大的工作流自动化工具,我们将用它来编排整个RAG系统的流程。
1.1 使用Docker安装N8N(推荐)
可以通过以下Docker命令安装N8N:
特殊参数说明:
设置环境变量
N8N_HOST
为192.168.4.48
,这可能是用来指定应用监听的主机地址。设置环境变量
N8N_LISTEN_ADDRESS
为0.0.0.0
,表示应用程序将监听所有网络接口。镜像地址已隐藏,请前往Docker Hub进行下载。
docker run -d -it --rm --name n8n -p 5678:5678 -v n8n_data:/home/node/.n8n -e N8N_SECURE_COOKIE=false -e N8N_HOST=192.168.4.48 -e N8N_LISTEN_ADDRESS=0.0.0.0 registry.cn-hangzhou.aliyuncs.com/n8n:latest安装完成后,您可以通过浏览器访问 IP地址:5678来打开N8N主页。
1.2 初始化N8N账户信息
说明首次访问N8N时,请根据提示完成账户信息的初始化设置。
04
RAG工作流完整搭建
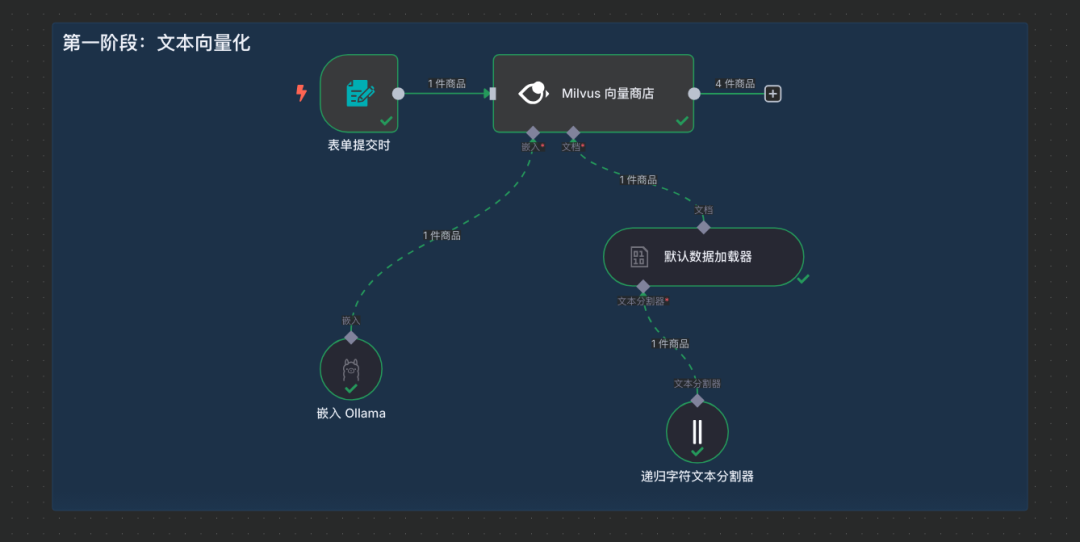
说明:本工作流共分为两个阶段。第一个阶段是文本向量化,第二个阶段是聊天对话检索向量。
第一阶段:文本向量化工作流搭建
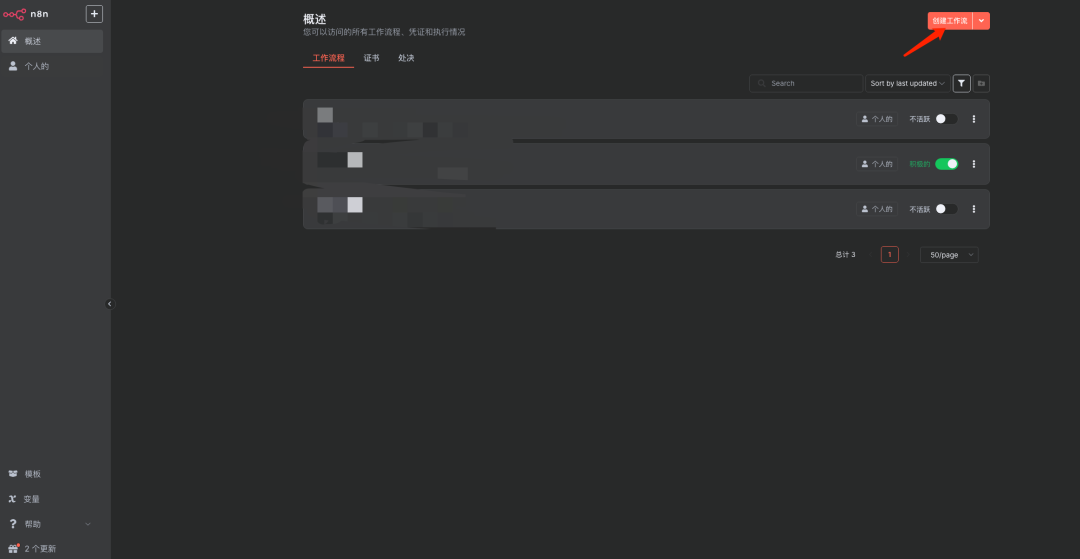
步骤1:创建工作流并配置手动触发
说明:在工作流编辑界面,点击“+”号,选择“Manual” (手动触发)作为工作流的起始节点。
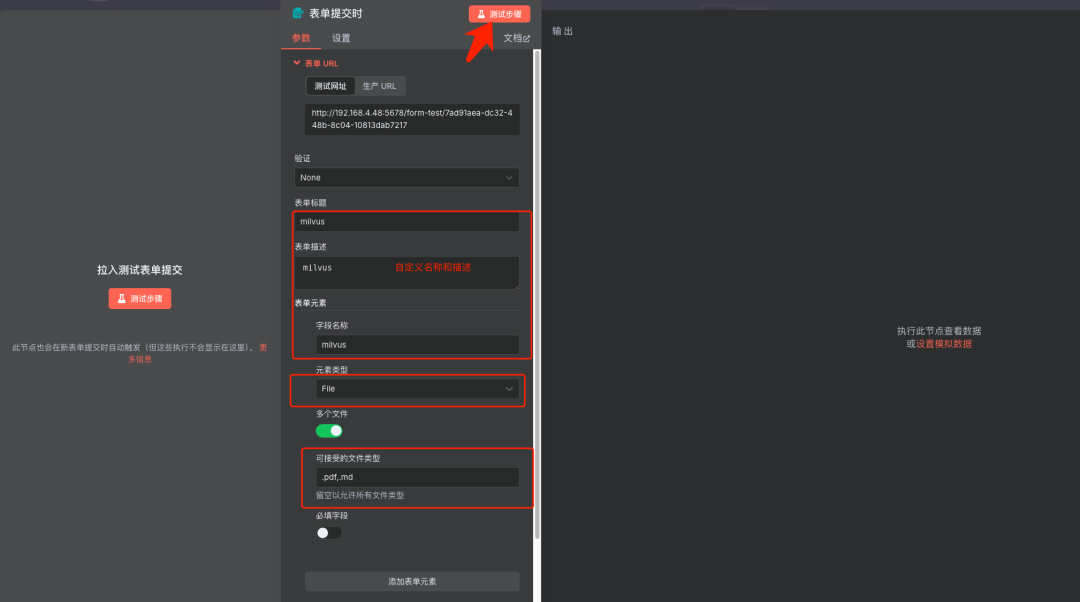
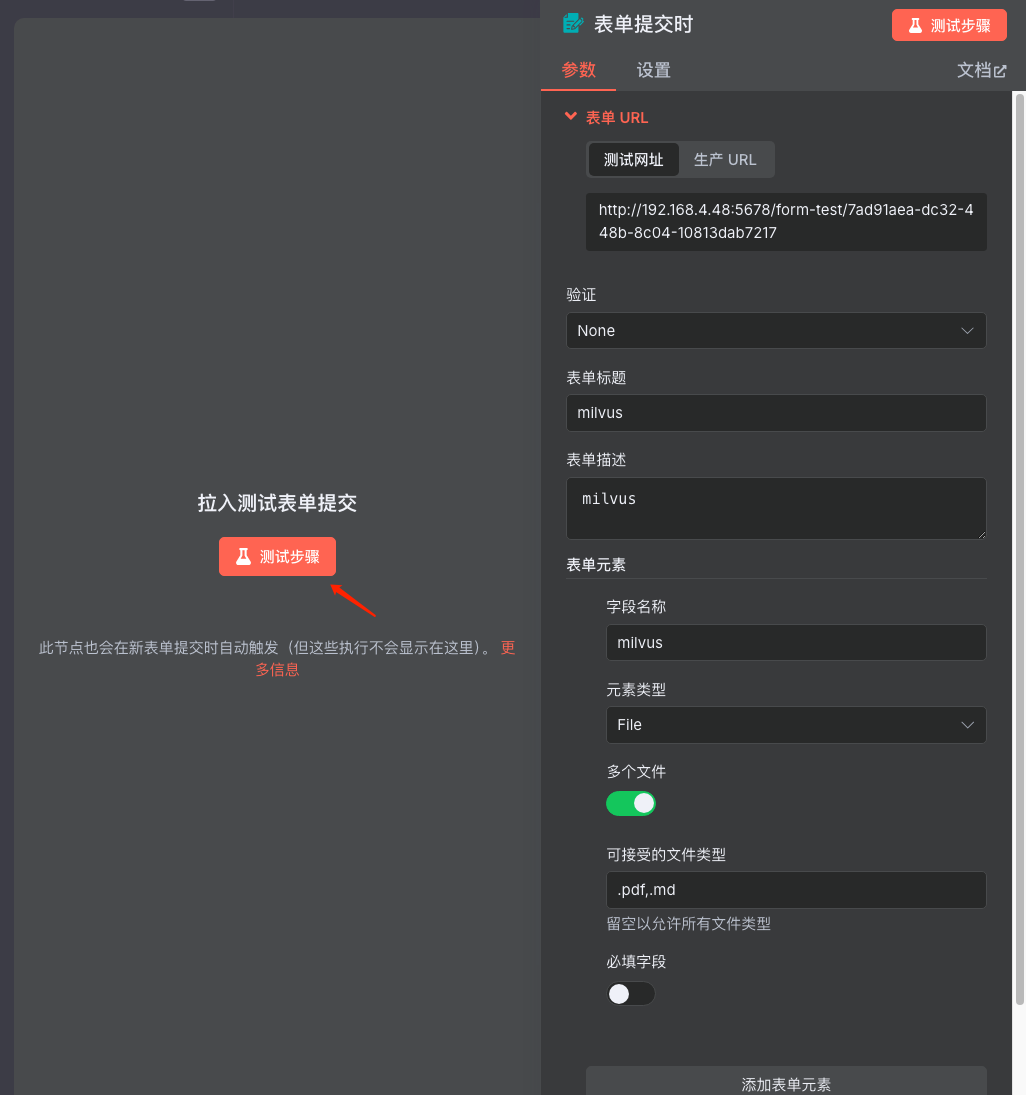
步骤2:配置表单提交参数
说明:上传文件的类型可支持多种格式,使用(.格式
, 分割的方式区分和添加)。 在手动触发节点中,配置表单参数以允许用户上传文件。
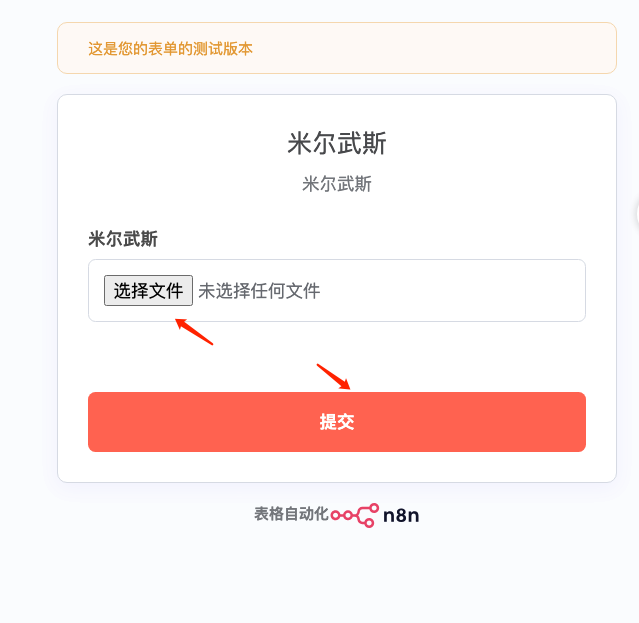
步骤3:点击测试上传文件
说明:配置完成后,可以测试文件上传功能,确保节点正常工作。
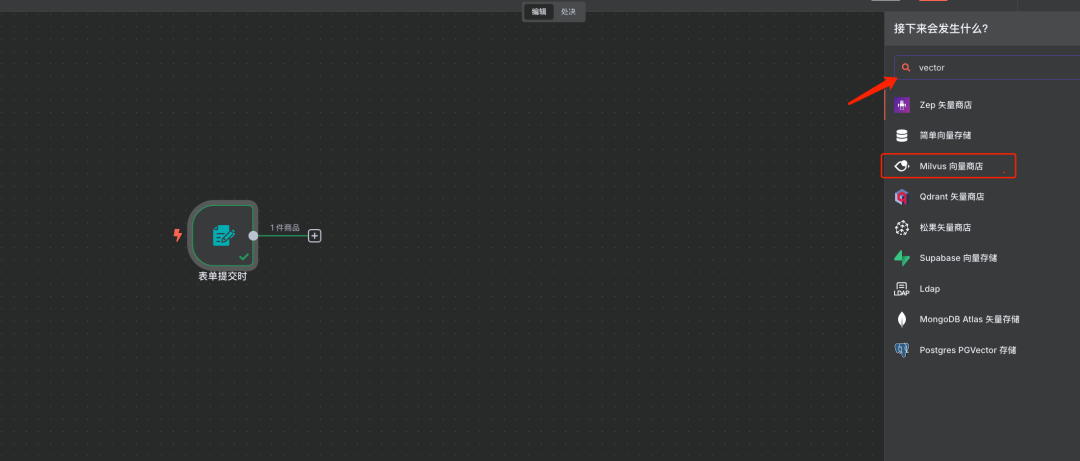
步骤4:添加Milvus组件
说明:输入“vector”关键字搜索,并选择Milvus相关的组件。
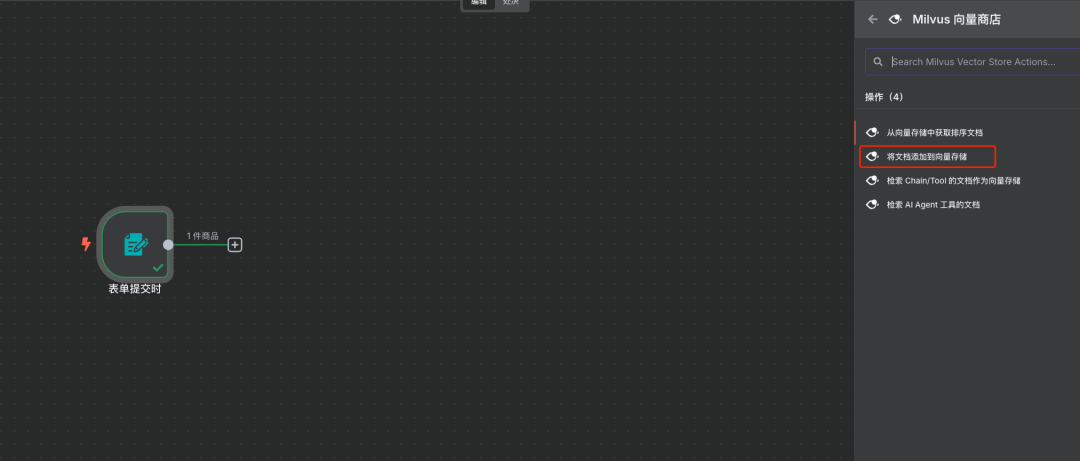
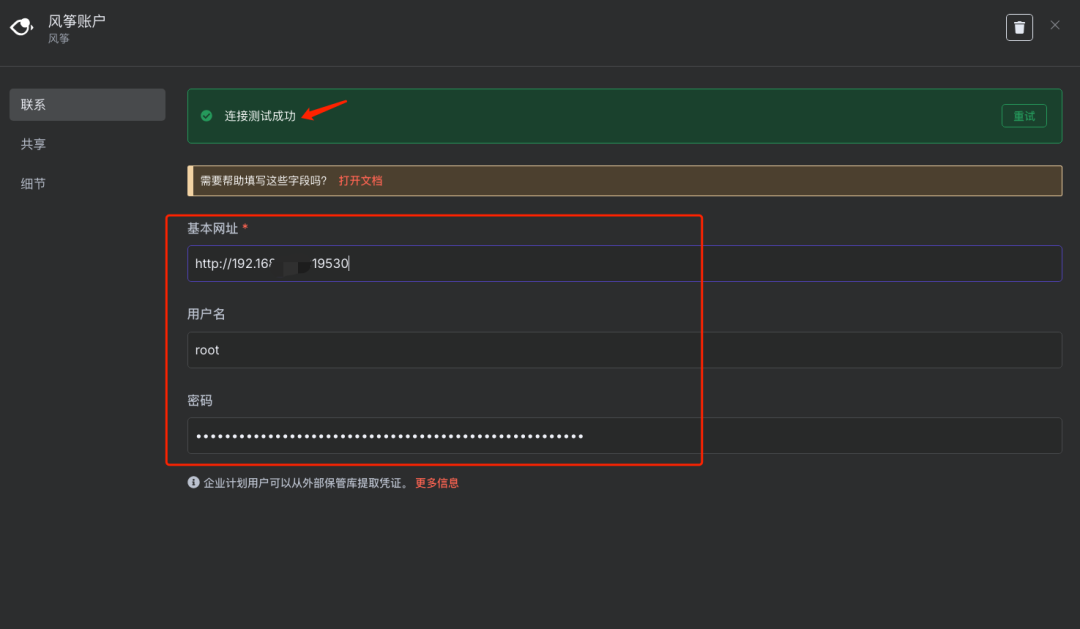
步骤5:配置Milvus连接与Collection
说明:在Milvus节点配置中,创建或选择已有的Milvus连接凭证,填入Milvus服务地址并选择创建好的Collection
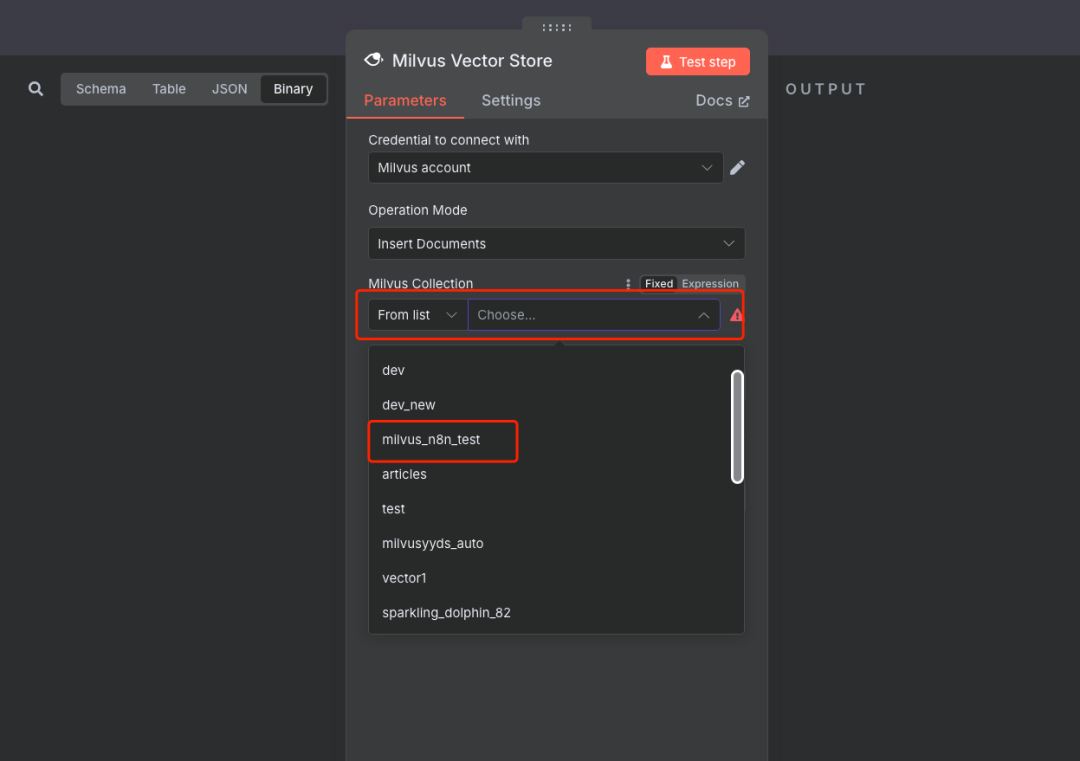
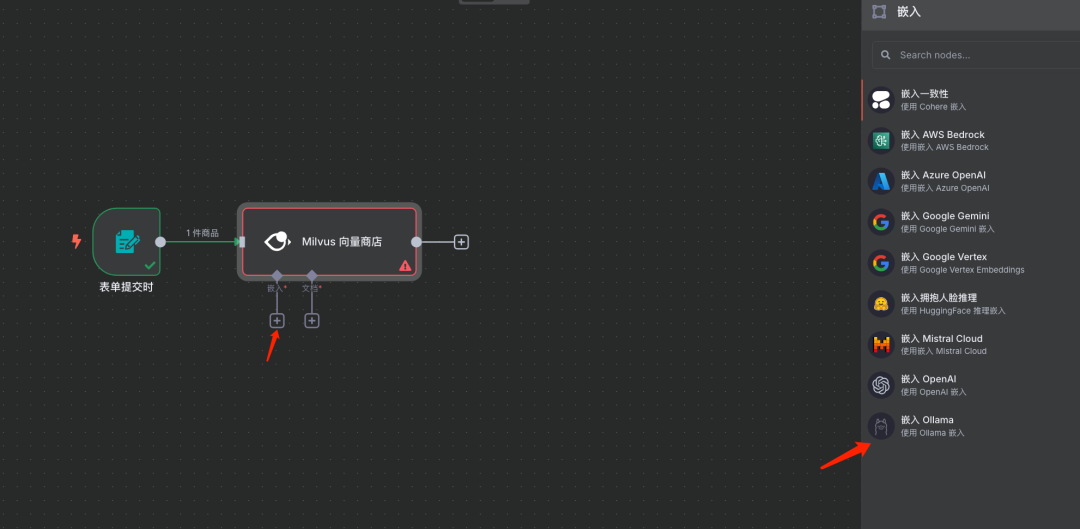
步骤6:添加嵌入模型(Ollama)
说明:我们选择通过Ollama运行的本地嵌入模型
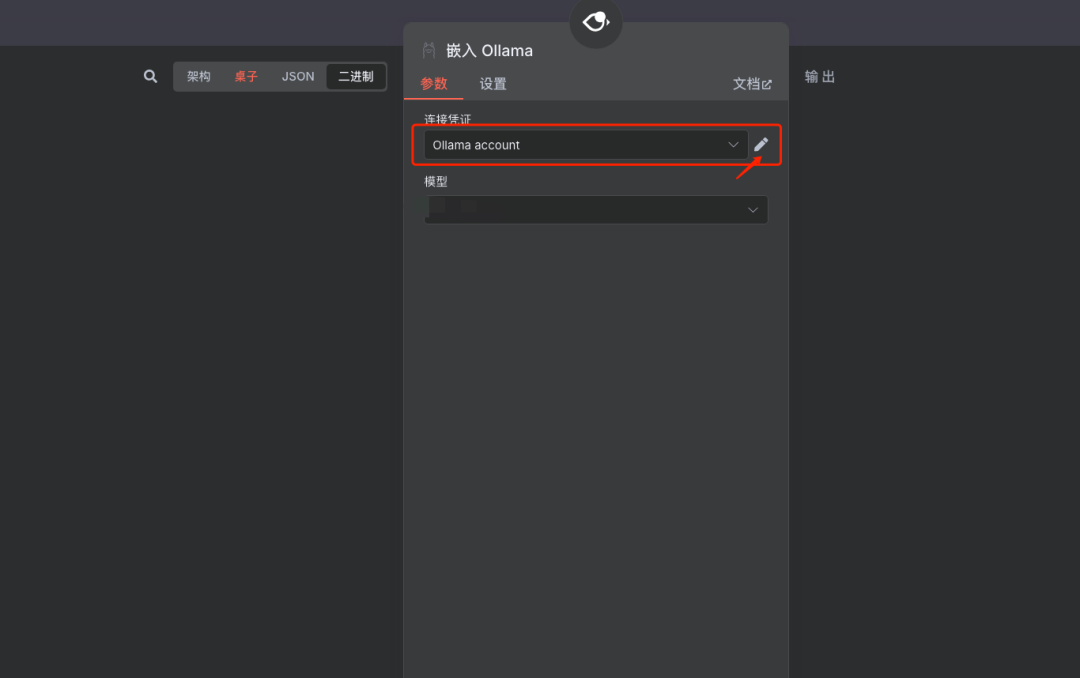
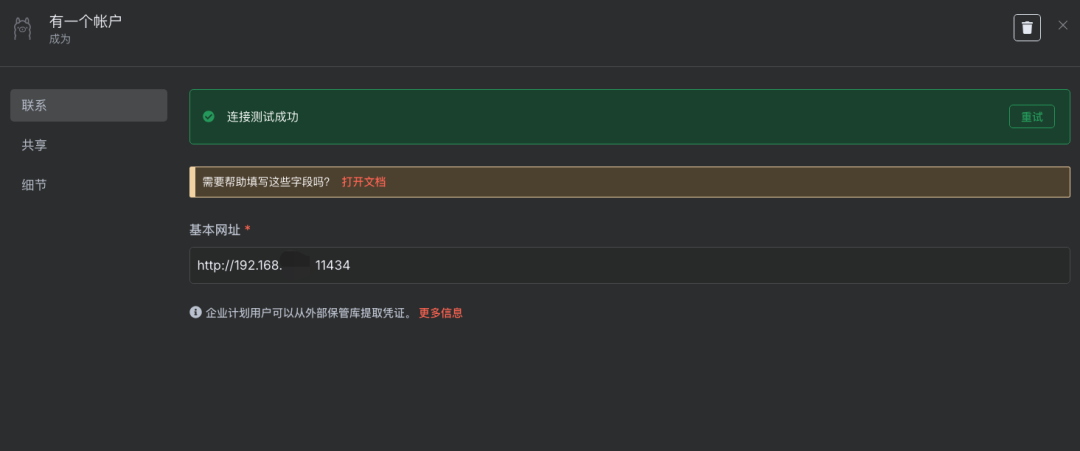
添加Ollama连接凭证
说明:如果使用Ollama服务,配置Ollama的连接凭证(如API地址)。
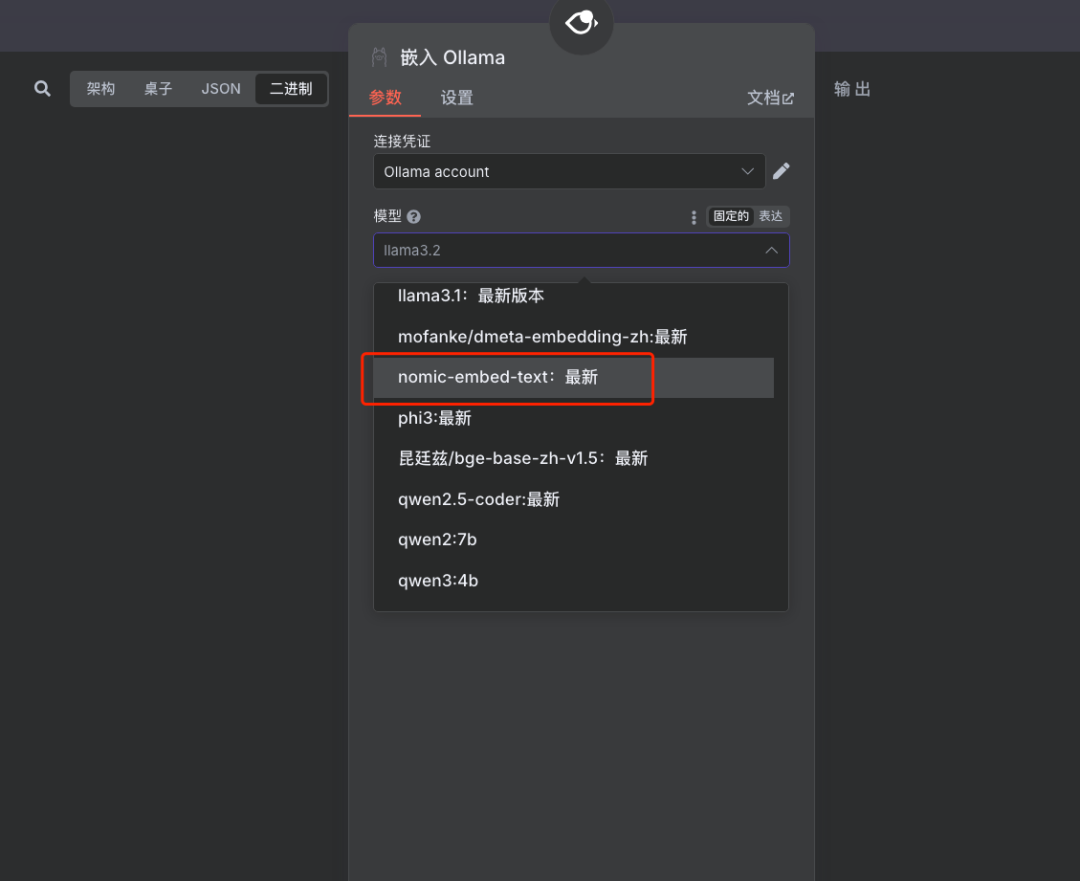
选择嵌入模型
说明:选择之前下载并配置好的嵌入模型(如 nomic-embed-text
)。
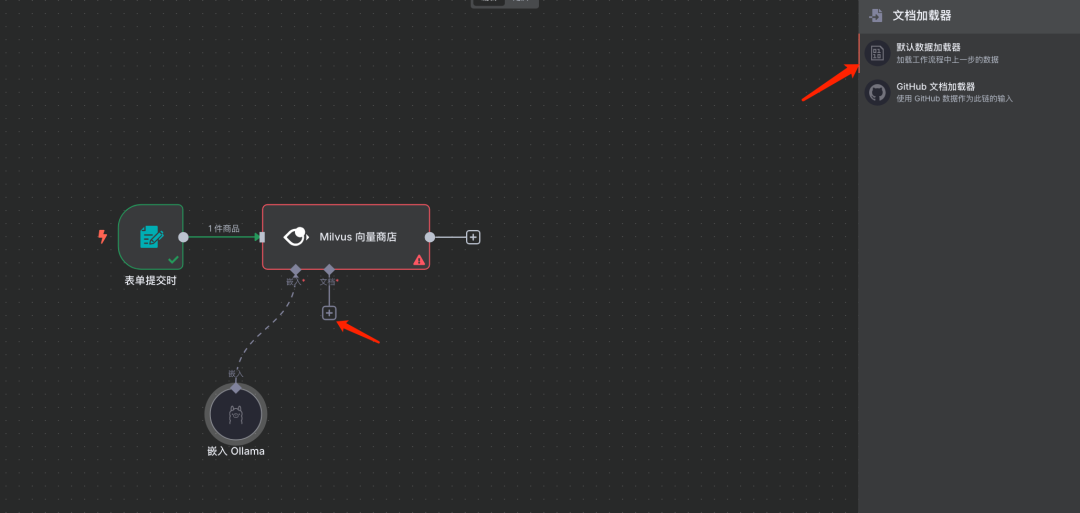
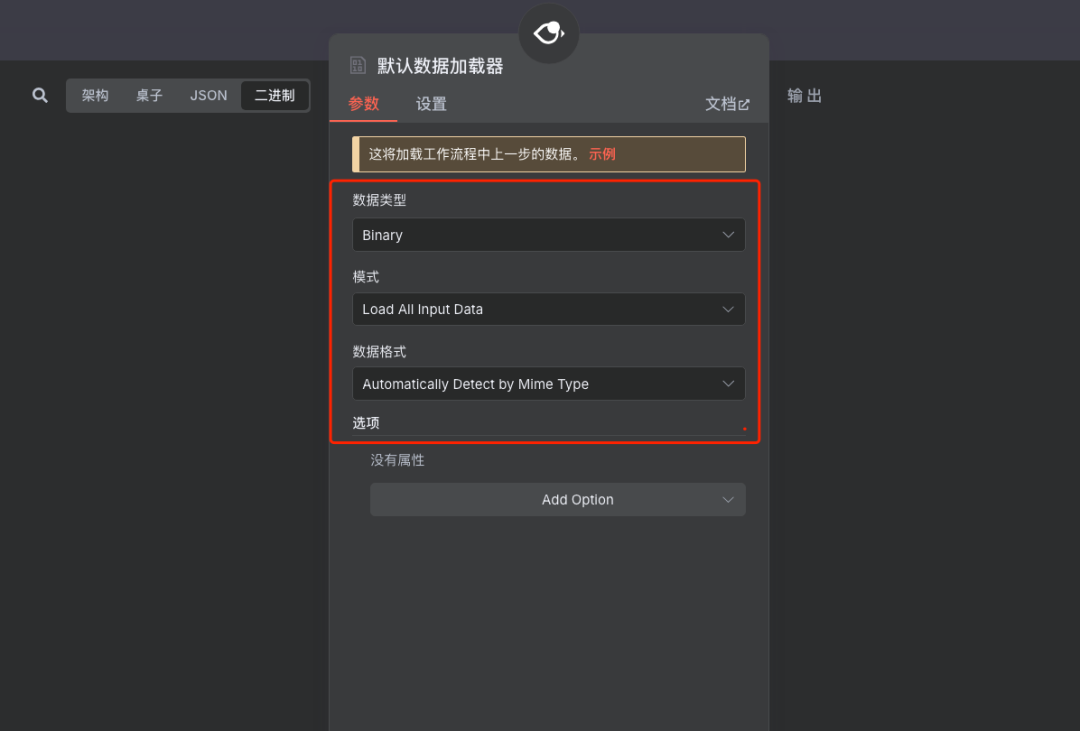
步骤7:添加文档加载器
参数说明:
类型选择:二进制 (Binary)
模式选择:加载所有输入数据 (Load all input data)
数据格式:自动选择 (Auto-select) 添加一个文档加载器节点,用于处理上传的文件数据。
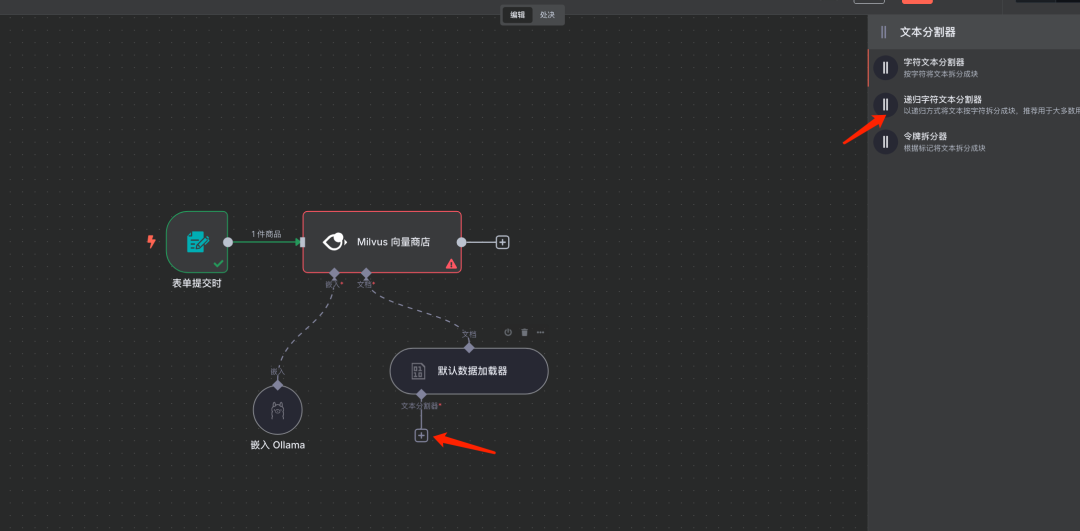
步骤8:添加文本分割器
说明:选择适用于大部分场景的递归方式 (Recursive Character Text Splitter)。 在文档加载器之后添加文本分割器节点,将文档内容分割成小块以便进行向量化。
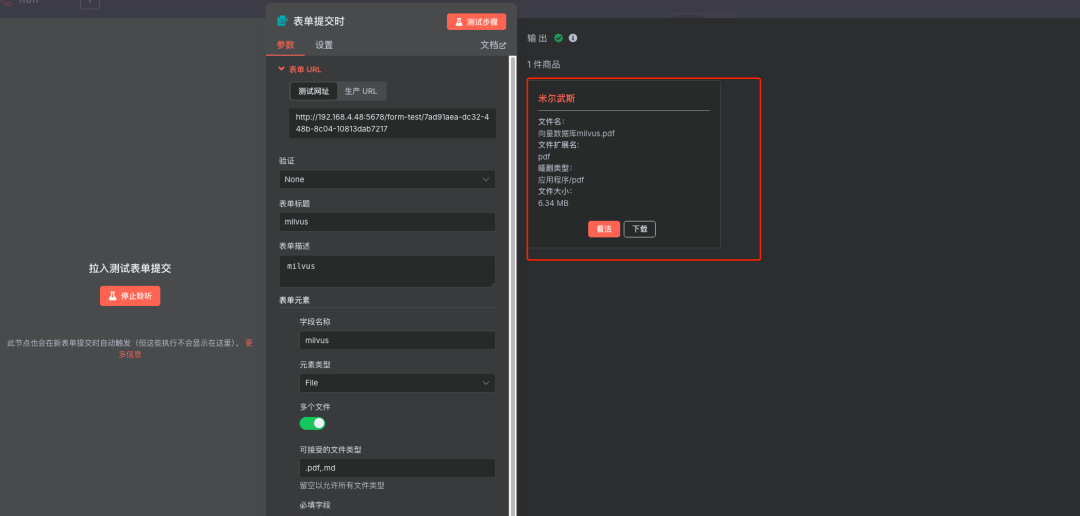
步骤9:开始测试文本向量化
说明:从触发节点上传一个任意PDF格式的文本即可自动完成向量存储过程。 运行整个第一阶段工作流,上传一个PDF文件进行测试。
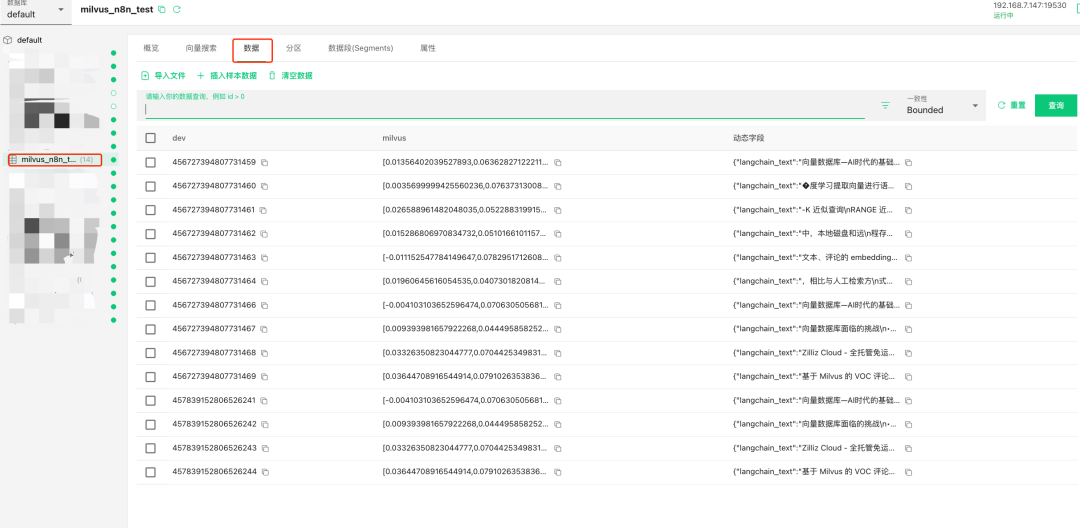
步骤10:验证Milvus中是否嵌入成功
说明:测试完成后,检查Milvus数据库对应的Collection,确认文本向量是否已成功嵌入。
第二阶段:聊天对话与向量检索工作流搭建
步骤1:添加聊天触发组件
说明:在N8N中创建一个新的工作流或在现有工作流中添加一个聊天触发器(例如 "Webhook" 节点或专门的聊天机器人触发器),用于接收用户输入的问题。
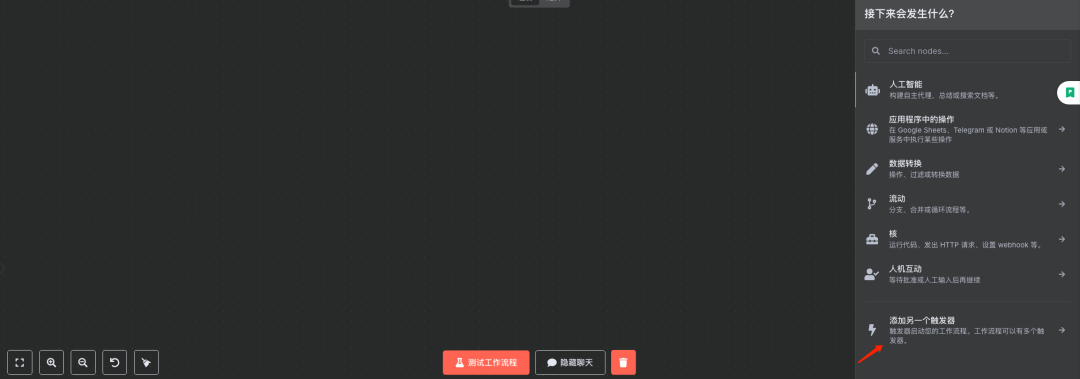
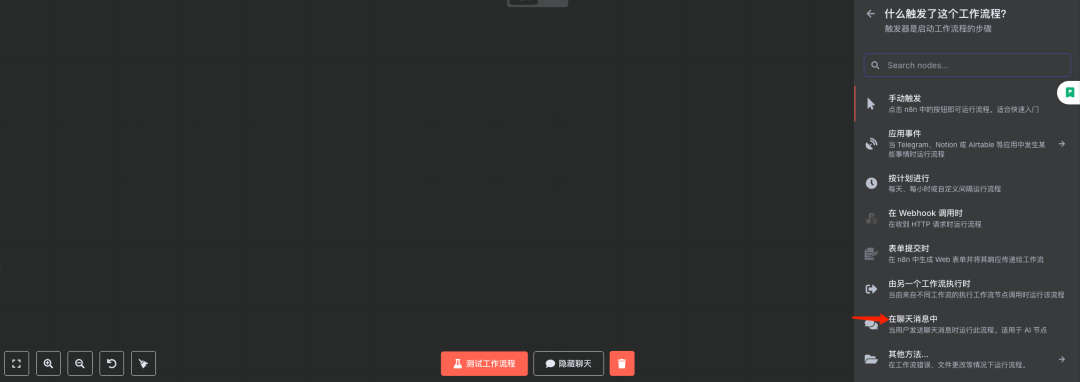
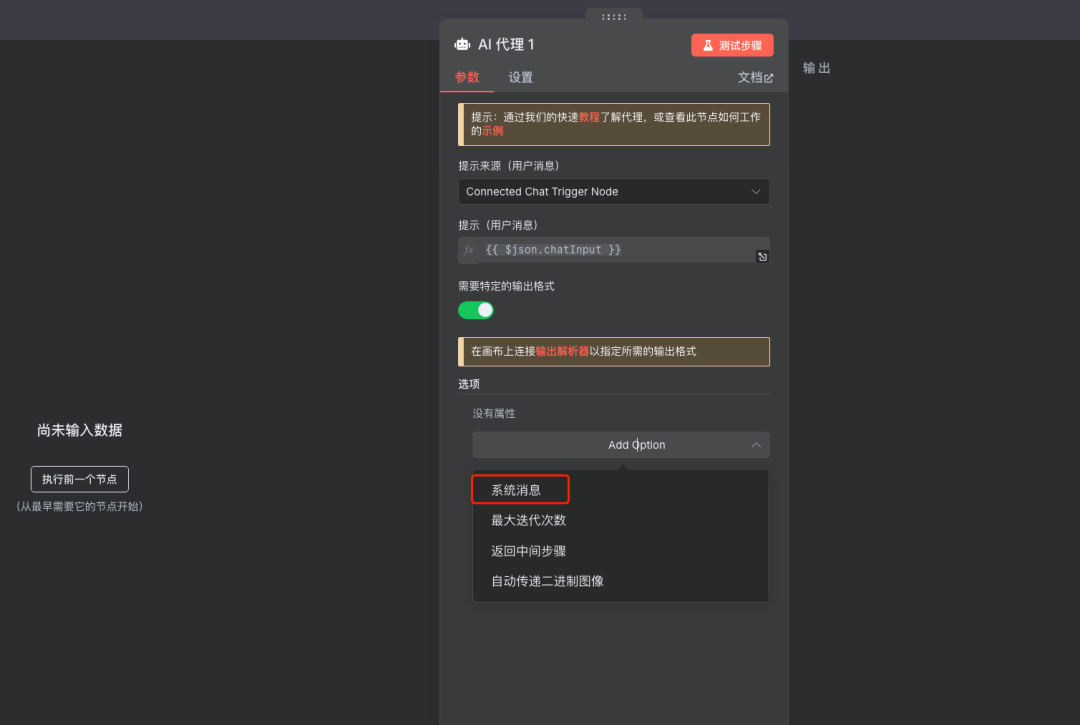
步骤2:添加AI-Agent代理节点
说明:添加一个AI Agent或类似的逻辑处理节点,用于协调后续的LLM调用和工具使用。


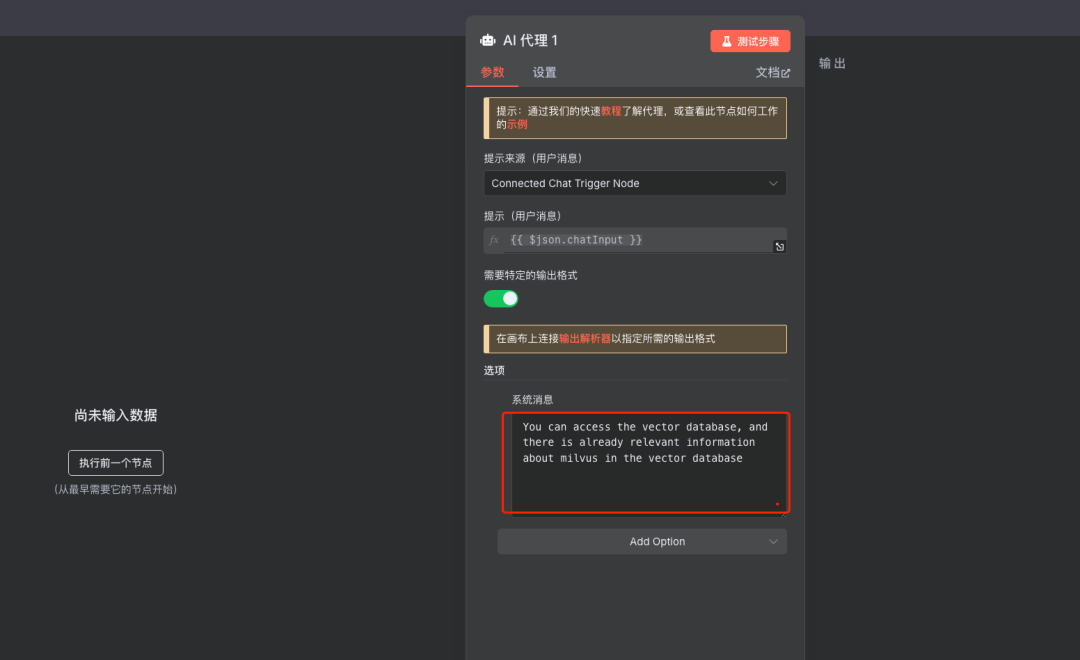
添加系统提示词
说明:提示词中英文都可以尝试,本文使用英文提示词测试如下。 为AI Agent配置系统提示词 (System Prompt),指导其行为。例如:
You can access the vector database, and there is already relevant information about milvus in the vector database[...]
步骤3:添加聊天模型
说明:使用OpenRouter供应商提供的在线LLM大模型。 添加一个LLM调用节点,用于与大语言模型进行交互。
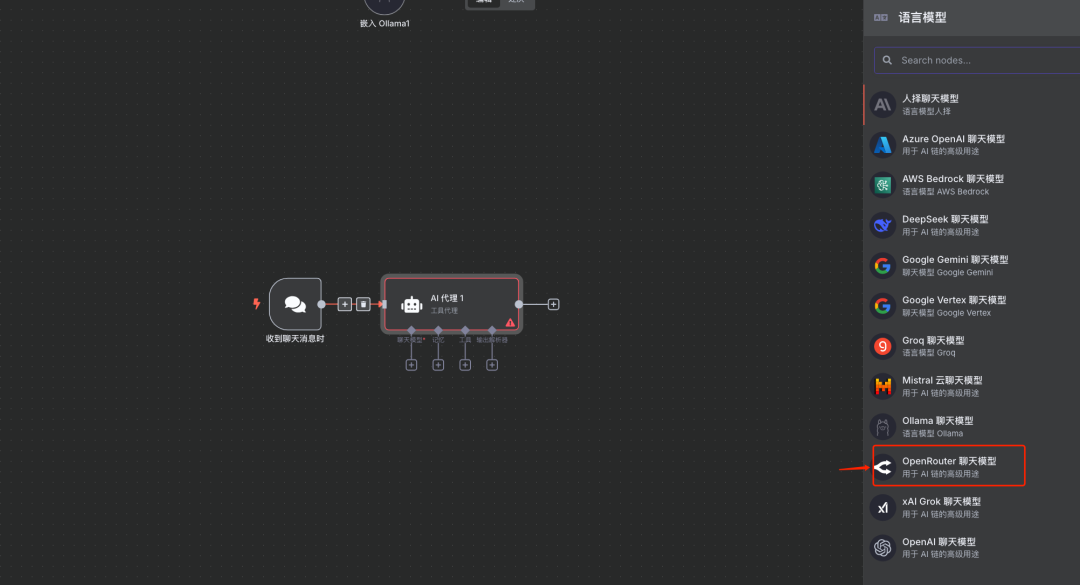
添加API-KEY并选择模型
说明:添加刚才在OpenRouter创建好的Key并选择支持Tools工具的模型即可。 在LLM节点中配置OpenRouter的API密钥,并选择之前确定好的、支持Tools的模型。
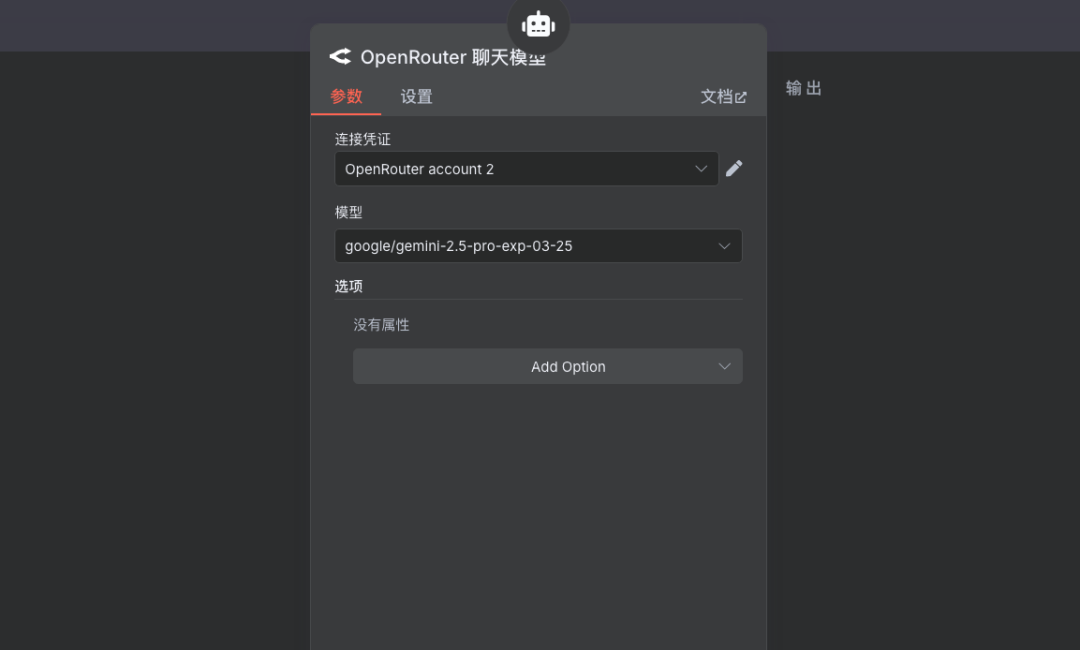
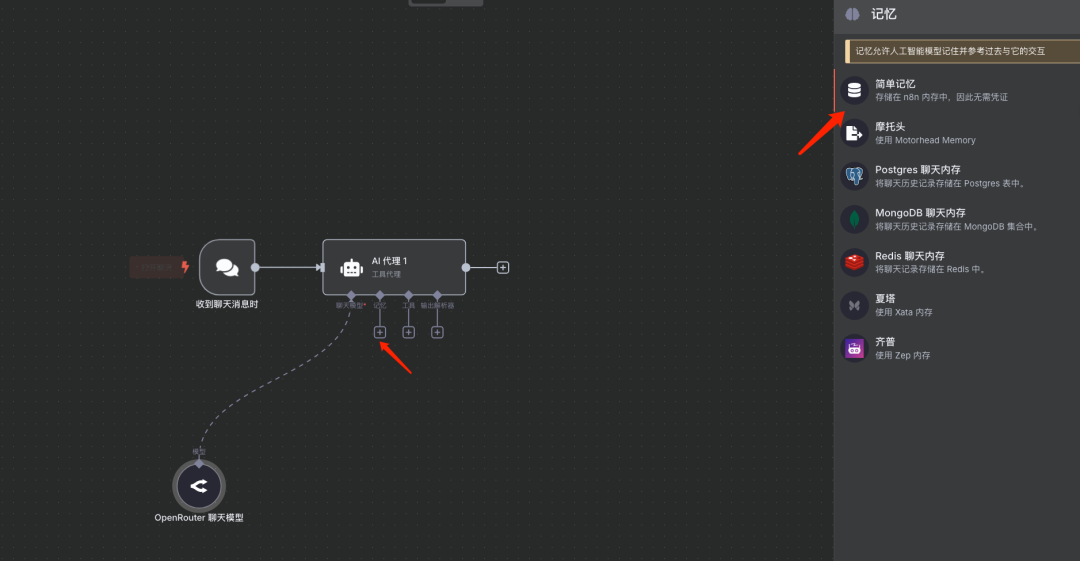
添加记忆
说明:本文采用简单记忆作为演示。 为聊天流程配置记忆功能(例如 "Simple Memory"),使得对话能够保持上下文。
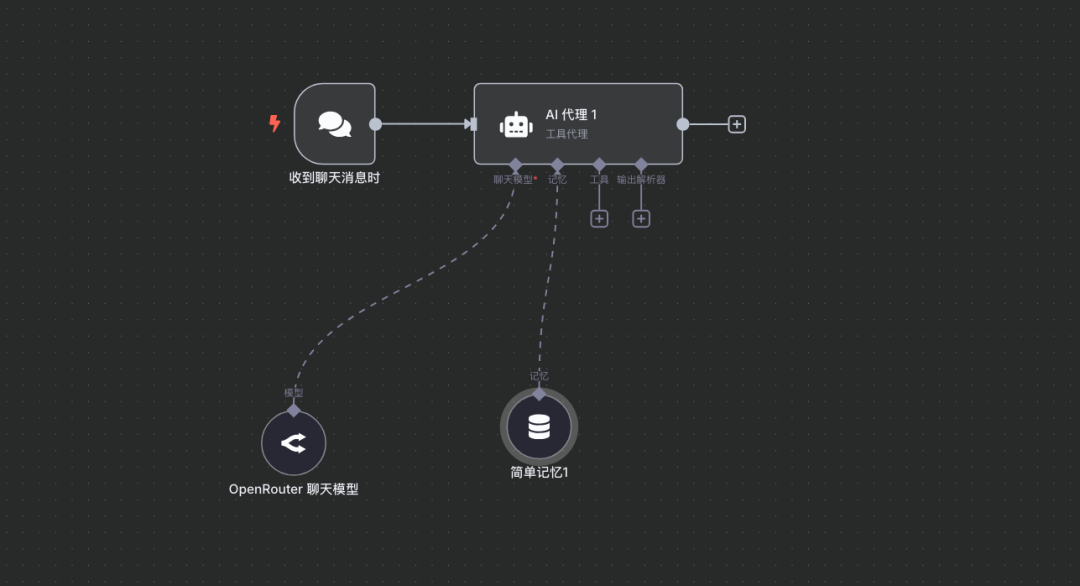
步骤4:添加工具(向量数据库问答)
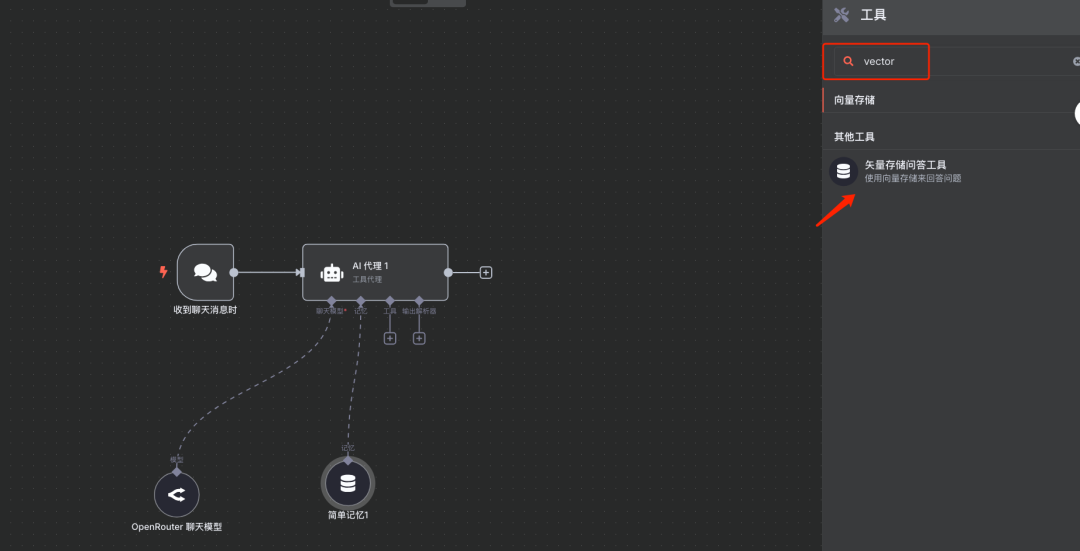
说明:采用N8N提供的向量数据库问答工具,LLM会调用此工具进行向量检索并将结果返回。(输入关键字vector
进行工具搜索) 在AI Agent或LLM配置中添加一个工具 (Tool),该工具用于从向量数据库中检索信息。
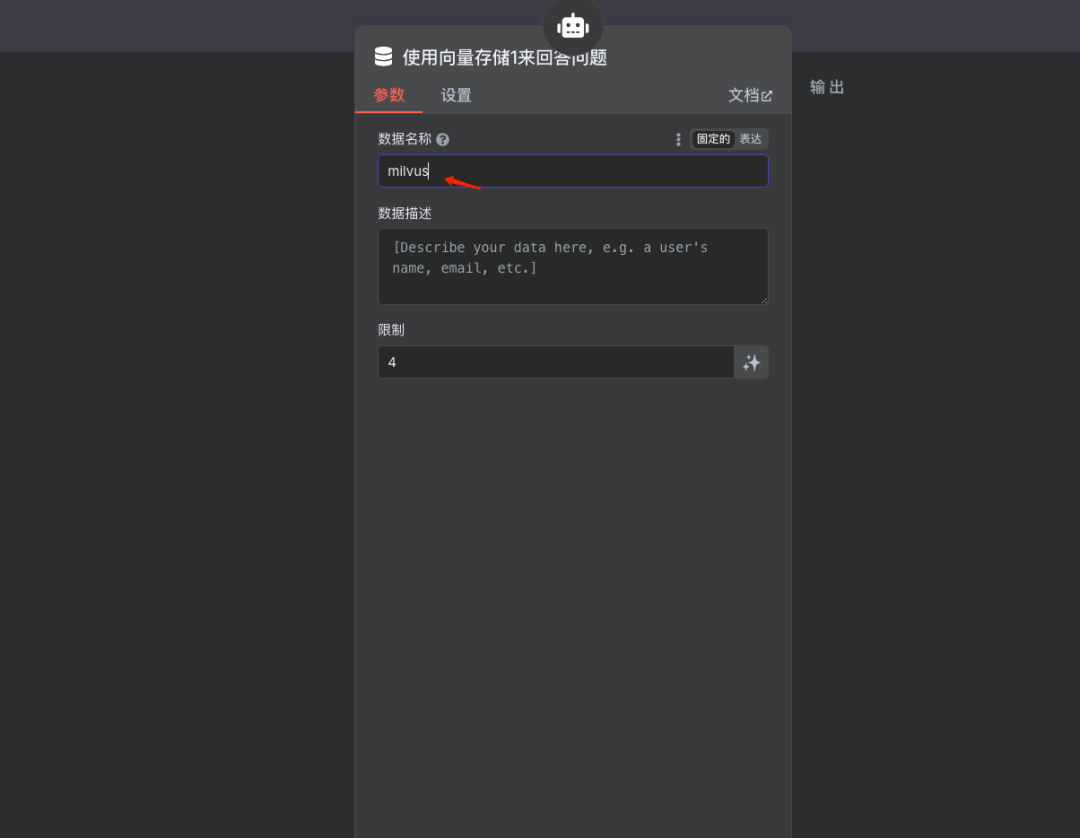
添加数据名称
说明:为该工具配置一个易于识别的名称
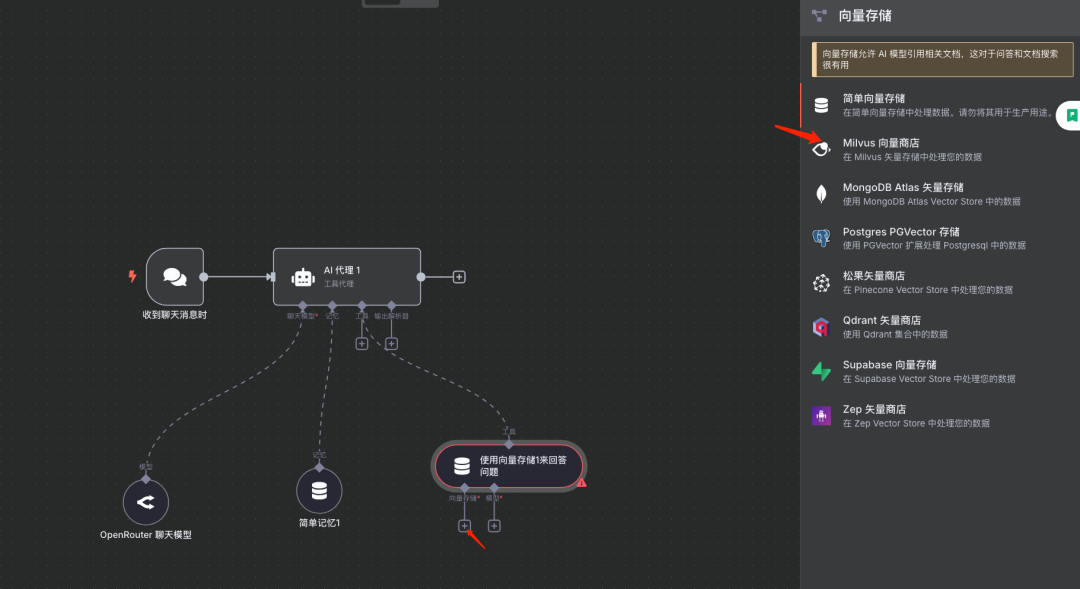
配置向量存储及嵌入模型
说明:在此工具的配置中,指定之前设置好的Milvus向量存储(Collection)以及用于查询向量化的嵌入模型(与第一阶段一致)。
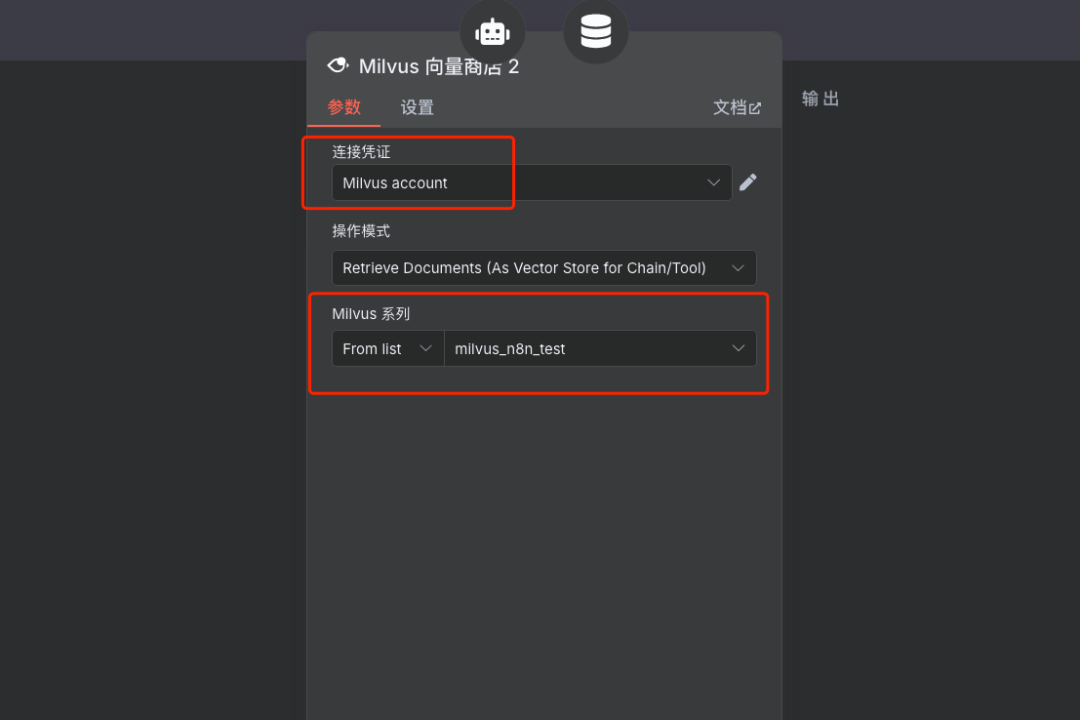
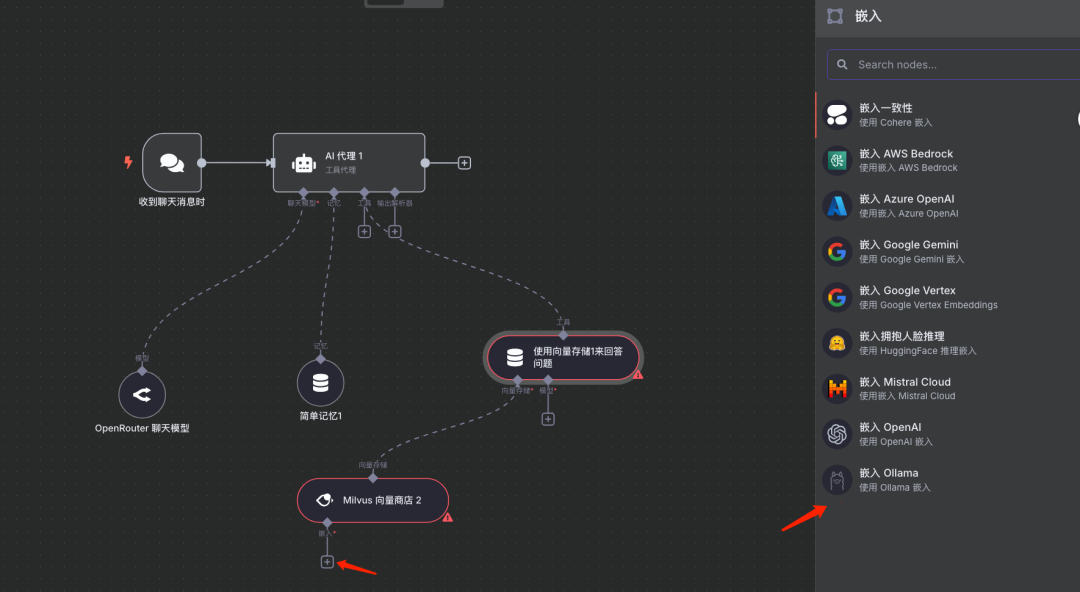
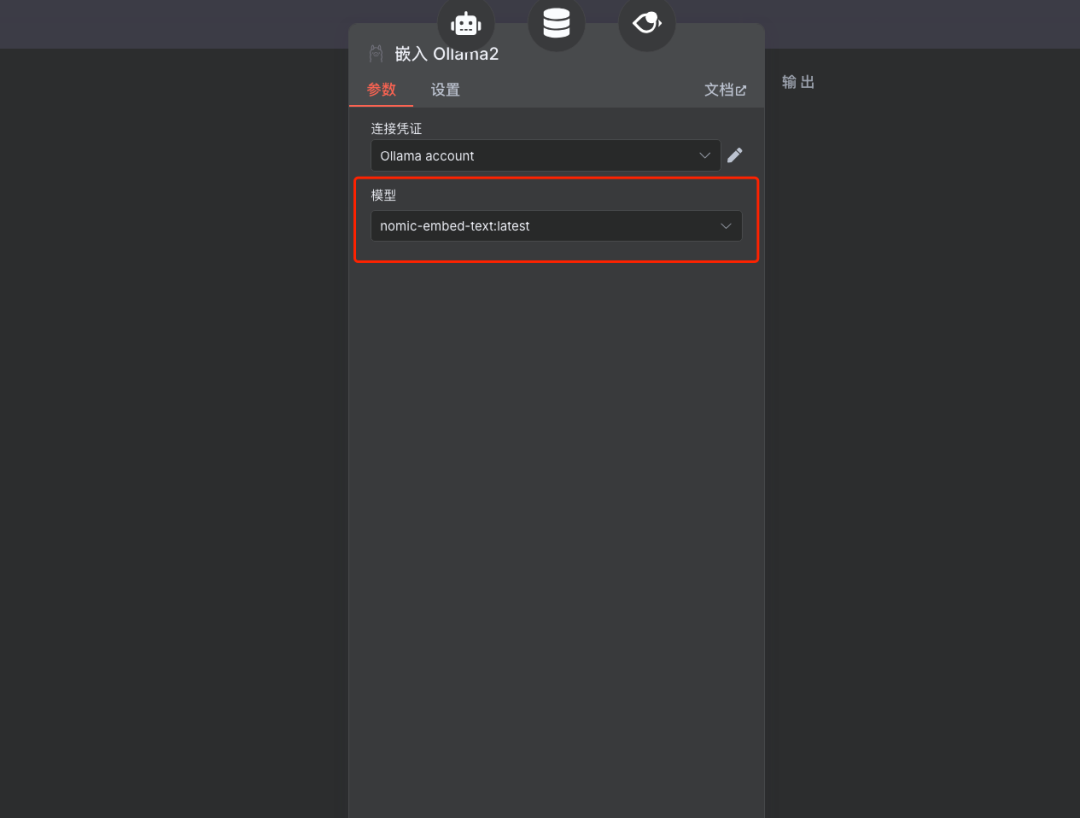
配置LLM模型
说明:指定该工具在内部处理或生成响应时可能需要调用的LLM模型
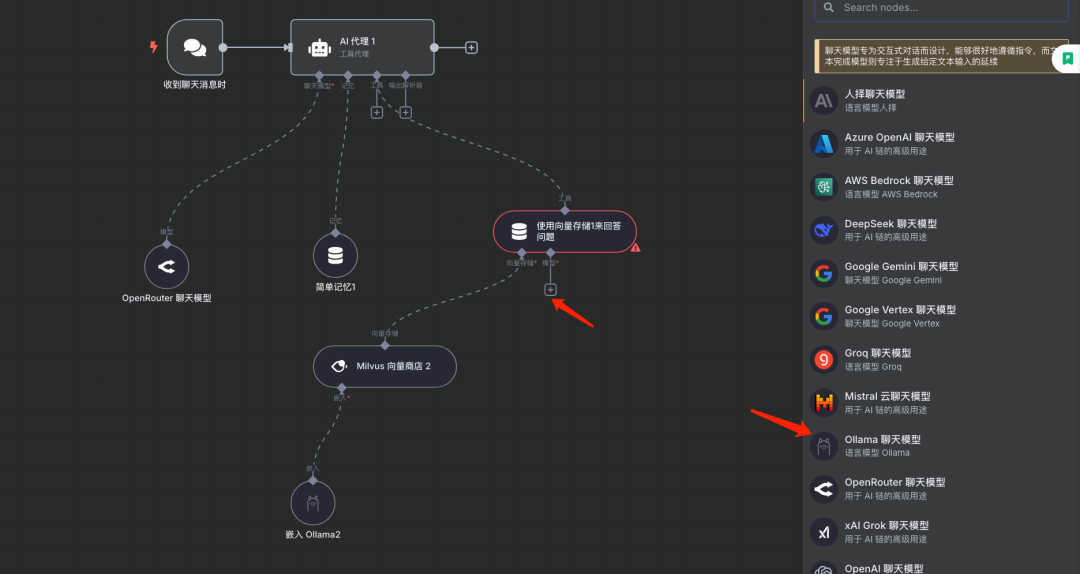
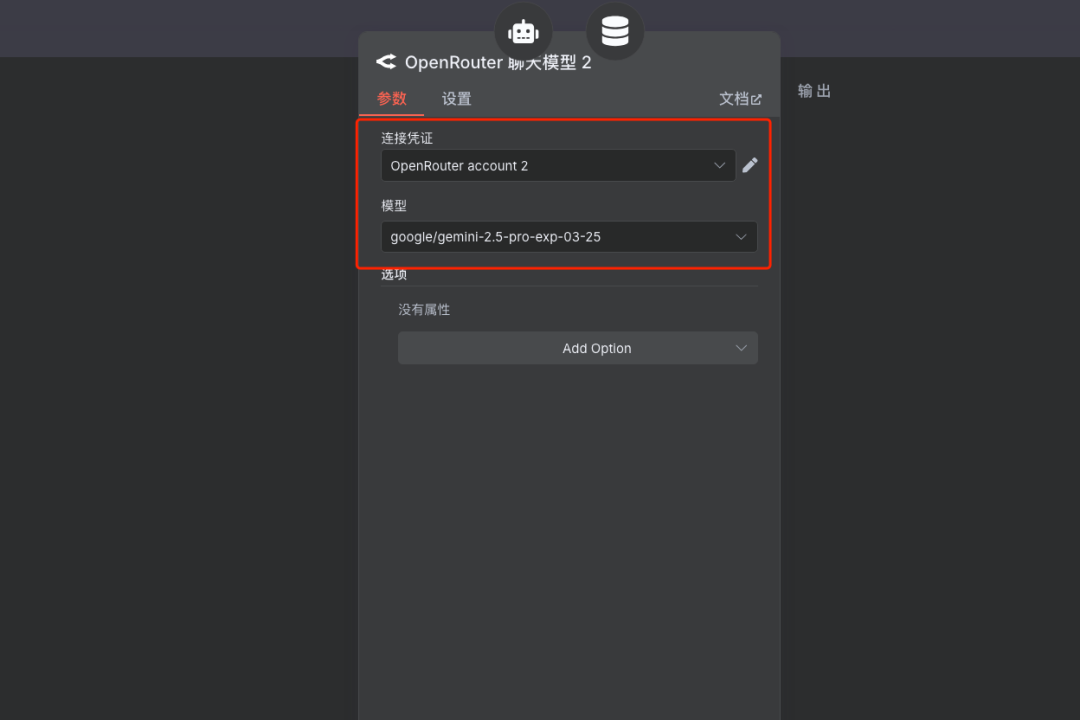
步骤5: 完成第二阶段配置
检查并确认第二阶段所有节点的配置均已正确完成
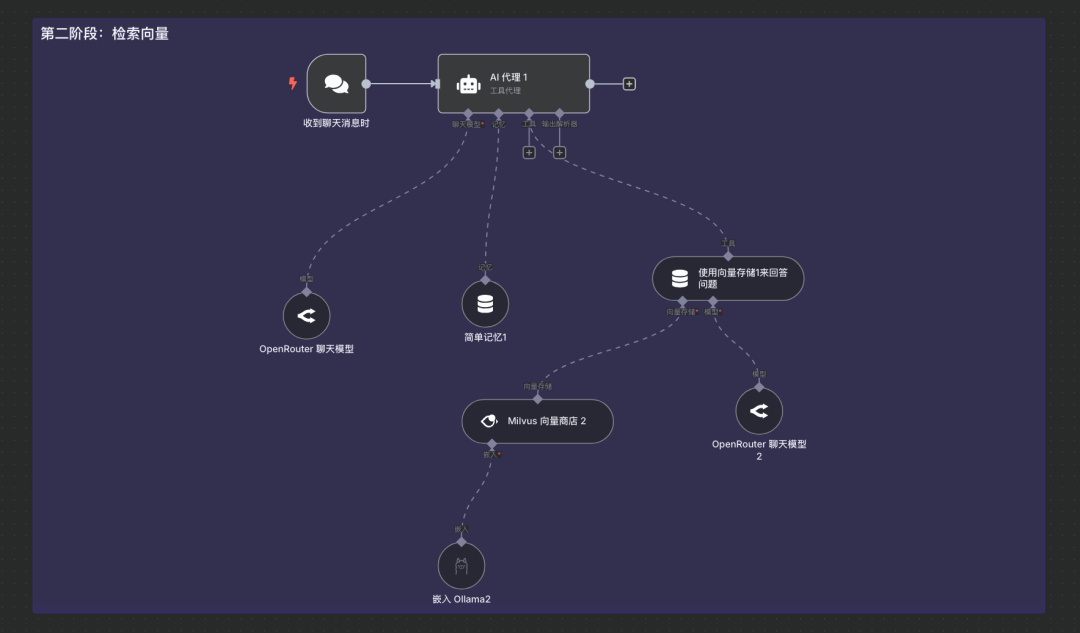
步骤6:开始测试对话
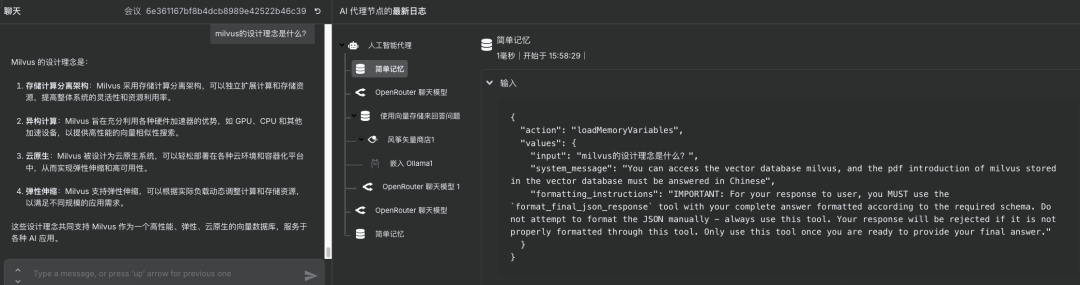
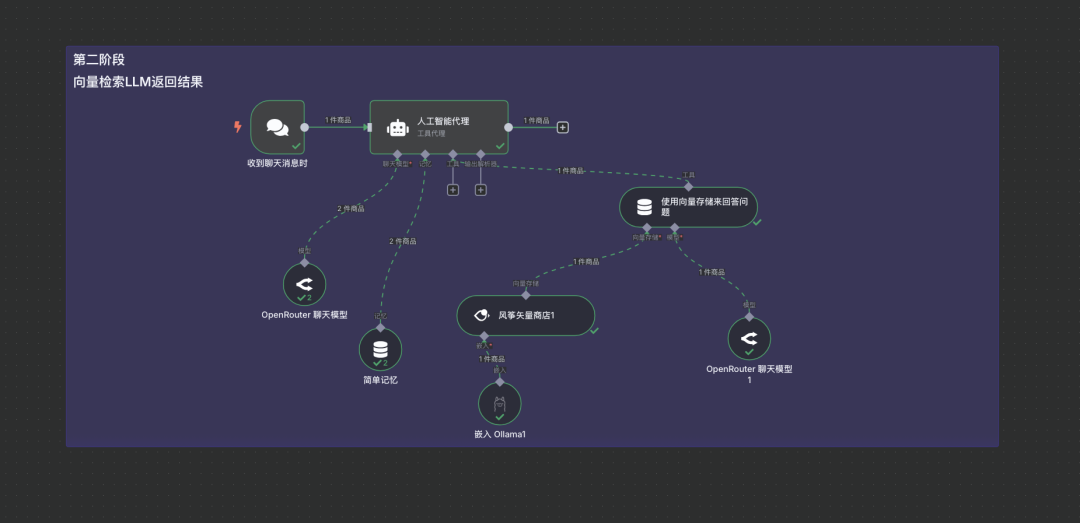
说明:通过聊天触发组件发送测试问题,检验整个RAG流程是否能够正确检索信息并给出回答
milvus的设计理念是什么?
05
写在结尾
RAG(检索增强生成)系统解决了大语言模型的三大核心痛点:
知识时效性突破:通过实时检索外部知识库,确保回答包含最新信息,解决模型训练数据截止带来的信息滞后,适用于金融、新闻、医疗等需实时数据的领域。
幻觉问题缓解:提供可验证的参考资料,显著降低模型生成不准确信息的风险,提高回答的准确性和可信度。
专业领域适应:允许访问特定领域知识库,无需昂贵微调即可回答专业问题,增强模型在垂直领域的表现。
而Milvus通过专注向量相似度搜索,支持毫秒级检索数十亿向量,可以快速定位相关知识片段,提升知识库的响应速度和准确性。其分布式架构支持水平扩展,能处理TB级数据和高并发请求,保证系统稳定。提供多种索引(如HNSW、IVF)和距离计算方法(余弦相似度、欧氏距离),便于根据场景优化检索效果。支持实时数据插入与更新,确保知识库时效性。
如对本教程仍有不理解的地方,欢迎扫描文末二维码交流。
作者介绍

Zilliz 黄金写手:尹珉