




 点击蓝字,关注我们
点击蓝字,关注我们
问题背景
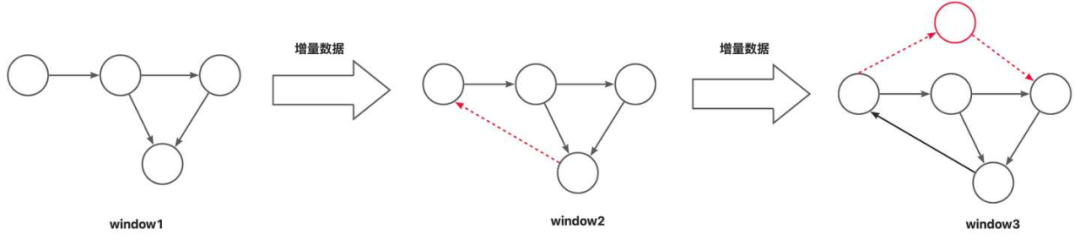
当前问题
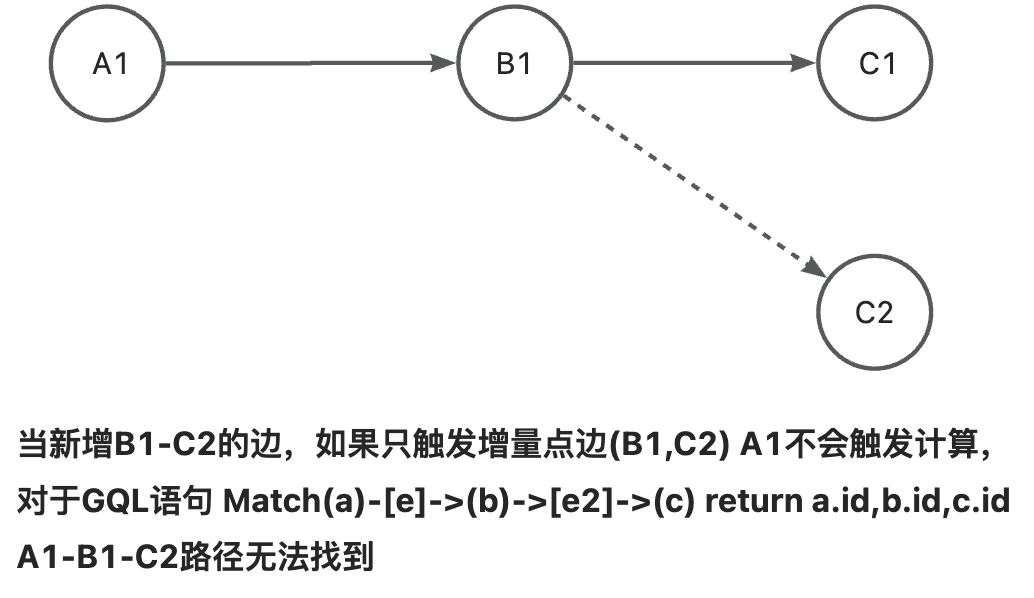
Geaflow引擎基于点中心框架(vertex center),通过迭代的方式,每一轮迭代中,每个点向其他点发送消息,并在下一轮收到消息时进行处理、分析。在Geaflow的框架中,GQL的查询需要从前往后进行Traversal遍历走图,即从起始节点开始出发,进行扩散,依次进行点边匹配,直到match所需要的查询pattern。在动态图里,如果只使用新增的点边触发计算,结果会有缺失,例如下面例子所示。
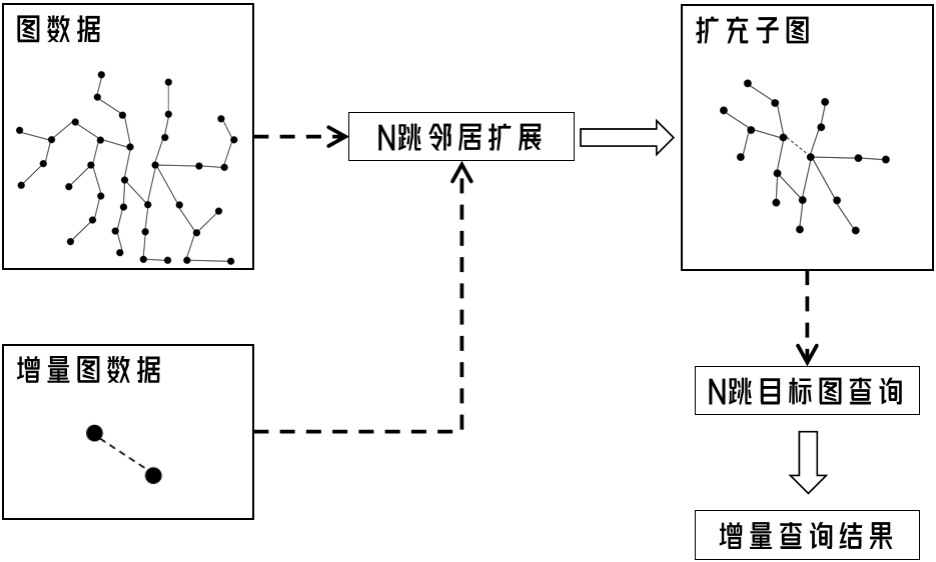
整体流程示例图如下:
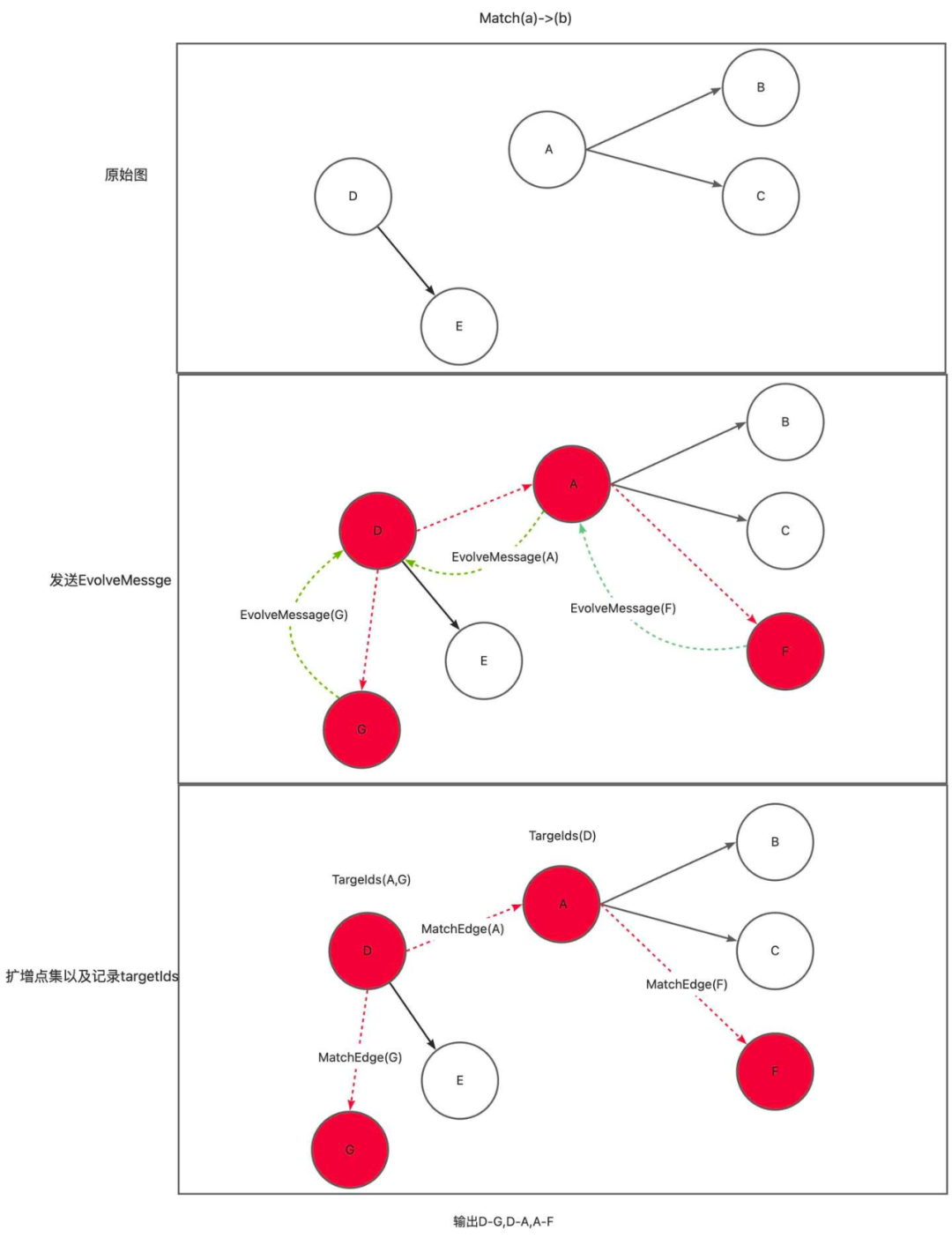
例如match(a)迭代数为1,此时不需要Evolve逻辑match(a)-[e]->(b)迭代数为2,此时不需要Evolve逻辑match(a)-[e]->(b)->[e2]->(c)迭代数为3 最大迭代数5
反向扩展的主要逻辑在GeaFlowDynamicVCTraversalFunction中,GeaFlowDynamicVCTraversalFunction继承自IncVertexCentricFunction,在Geaflow中IncVertexCentricFunction是一个表示增量VC方法(点中心)的接口,在每次迭代中,都会对当前收到消息的点进行触发,执行compute方法中的逻辑。
@Overridepublic void compute(Object vertexId, Iterator<MessageBox> messageIterator) {TraversalRuntimeContext context = commonFunction.getContext();if (needIncrTraversal()) {long iterationId = context.getIterationId();// sendEvolveMessage to evolve subGraphs when iterationId is less than the plan iterationif (iterationId < queryMaxIteration - 1) {evolveIds.add(vertexId);sendEvolveMessage(vertexId, context);return;}if (iterationId == queryMaxIteration - 1) {// the current iteration is the end of evolve phase.evolveIds.add(vertexId);return;}// traversalcommonFunction.compute(vertexId, messageIterator);} else {commonFunction.compute(vertexId, messageIterator);}}
具体示例如下:
总结进行Evolve扩展的条件:
Demo示例
在Geaflow中,通过设置点表或边表的windowSize来默认实现增量逻辑,即每一批读入windowSize大小的点边数据,来构建增量图。
CREATE GRAPH modern (Vertex person (id bigint ID,name varchar,age int),Edge knows (srcId bigint SOURCE ID,targetId bigint DESTINATION ID,weight double),) WITH (storeType='rocksdb',shardCount = 1);CREATE TABLE modern_vertex (id varchar,type varchar,name varchar,other varchar) WITH (type='file',geaflow.dsl.file.path = 'resource:///data/incr_modern_vertex.txt',geaflow.dsl.window.size = 20);CREATE TABLE modern_edge (srcId bigint,targetId bigint,type varchar,weight double) WITH (type='file',geaflow.dsl.file.path = 'resource:///data/incr_modern_edge.txt',geaflow.dsl.window.size = 3);INSERT INTO modern.personSELECT cast(id as bigint), name, cast(other as int) as ageFROM modern_vertex WHERE type = 'person';INSERT INTO modern.knowsSELECT srcId, targetId, weightFROM modern_edge WHERE type = 'knows';CREATE TABLE tbl_result (a_id BIGINT,b_id BIGINT,c_id BIGINT,d_id BIGINT) WITH (type='file',geaflow.dsl.file.path='${target}');USE GRAPH modern;INSERT INTO tbl_resultSELECTa_id, b_id, c_id,d_idFROM (MATCH (a:person) -[e:knows]->(b:person)<-[e2:knows]-(c:person)<-[e3:knows]-(d:person) where a.id!=c.idRETURN a.id as a_id,b.id as b_id,c.id as c_id , d.id as d_id);
在Demo中,设置点windowSize为20,边windowSize为3,即构图时每个window导入20个点,3条边。并执行3跳的查询语句。示例Demo在IncrMatchTest.java中, 可直接运行执行Demo。
总结和展望
在动态图/流图的场景中,图的点边是在实时变化的,在进行图查询时,对于不同窗口数据的图,我们往往可以根据一些历史信息,只对增量的部分触发计算,来进行增量地计算,避免触发全图的遍历。Geaflow使用了一种基于子图扩展的增量match方法,应用于点中心分布式图计算框架,在动态图场景下进行增量的查询,未来期望实现更多更复杂场景下的增量匹配逻辑。
·END·

欢迎关注TuGraph代码仓库✨
https://github.com/tugraph-family/tugraph-db
https://github.com/tugraph-family/tugraph-analytics
