





本文字数:11004;估计阅读时间:289 分钟
作者:Tom Schreiber

Meetup活动
ClickHouse 杭州第二届 Meetup 讲师招募中,欢迎讲师在文末扫码报名!
简而言之
我们构建了一个面向云对象存储的分布式缓存 —— 一个共享的低延迟缓存层,能够为所有计算节点提供对热点数据的快速访问。
本文将深入讲解其内部原理:过去的热数据是如何缓存的,为何对象存储让事情变得更复杂,以及我们全新架构是如何彻底解决这一难题的。我们还将展示基准测试结果。
→ 分布式缓存目前已开放私密预览注册,点击此处申请试用【https://clickhouse.com/cloud/distributed-cache-waitlist】。

想象一下这样一种数据库架构:你可以随意通过更换更强的计算节点来纵向扩展,或者通过增加节点数量来横向扩展,无需担心缓存的热数据会丢失。更进一步,每个节点还能立刻受益于其他节点已经完成的计算任务 —— 不再有冷启动,也无需反复读取存储,更不会有无谓的资源浪费。
听起来像幻想?在如今解耦的云数据库架构中,持续保持热数据的可用性确实是一项挑战。
我们现在为 ClickHouse Cloud 推出分布式缓存,这是一个共享的缓存层,专为解决这一长期难题而设计 —— 即便计算节点在扩容、缩容或迁移时,也能始终将热点数据保留在靠近计算的位置。
接下来我们将回顾 ClickHouse 中缓存机制的演变历程,介绍分布式缓存的工作原理,以及它在性能和弹性方面带来的突破。
最后,我们还会展示它与以往方案的基准对比,包括基于 SSD 的自托管服务器。(提前透露一下:哪怕在冷启动下,我们的表现依然更胜一筹。)
在理解我们为何构建这个分布式缓存之前,我们需要先看清 —— 到底缓存了什么。
ClickHouse 内置了几乎所有方面的缓存机制:从 DNS 解析记录、输入文件结构、表的元数据、稀疏主键索引和标记文件,到未压缩的表数据、编译后的表达式、满足查询条件的表数据,甚至完整的查询结果。每一类缓存都在加速查询执行中发挥着重要作用,后续我们也会在其他文章中深入探讨。
本文聚焦于其中影响最深远的一项技术:将热表数据缓存在内存中。
这一机制与 ClickHouse 的分层 I/O 优化紧密结合,后者的核心目标是尽可能减少读取的数据量。一旦这些优化生效,查询引擎只会加载真正需要的数据 —— 也就是热表数据 —— 到内存中进行处理。为了让数据加载速度更快,尤其是在重复查询时,ClickHouse 会在执行前将热表数据缓存到本地内存中,尽可能靠近查询引擎的位置。
为什么这很重要?
因为从内存读取数据的速度远远快于从磁盘读取 —— 差距可能高达百万倍。前者是纳秒级,后者则是毫秒级;前者的吞吐量可以高达 100 GB/s,而后者往往只有几 GB/s。
这些数字我们稍后会具体展开,但首先,先来看看“热表数据”在实际中的含义。
下图展示了一个简化查询在表上的执行过程:
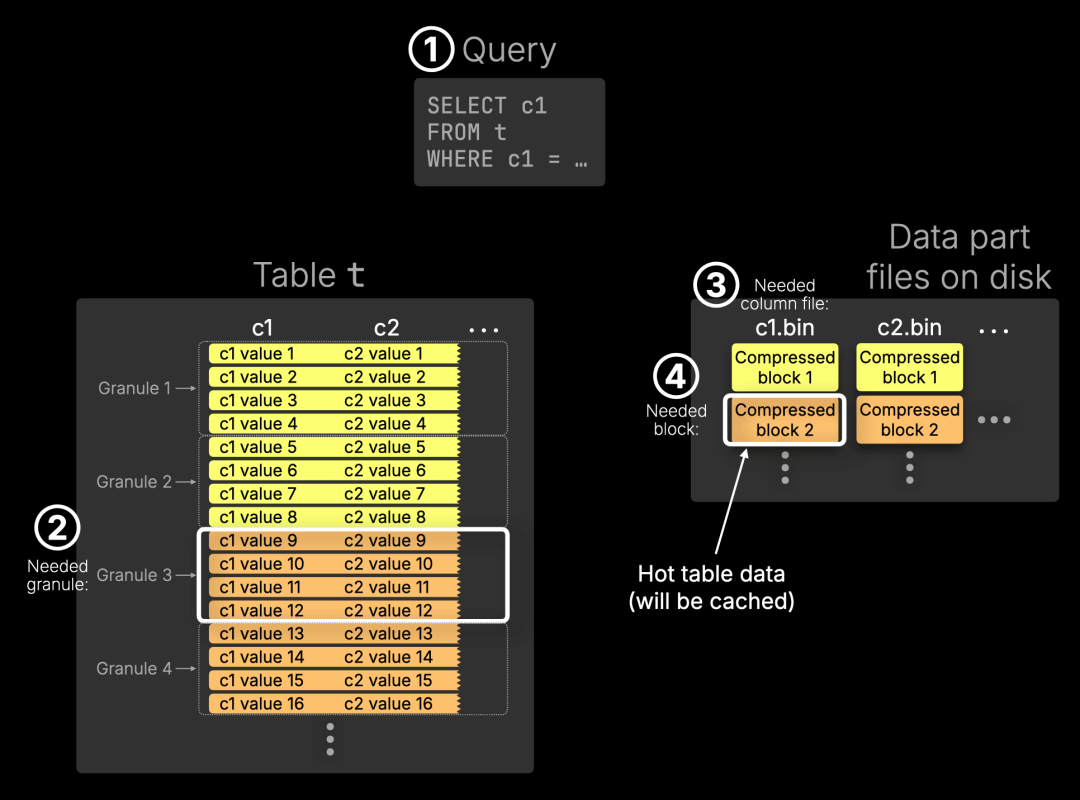
① 查询
一个 SELECT 查询选取列 c1,并通过 WHERE 子句筛选特定的行。
② 所需 granule
ClickHouse 会将表划分为 granule(最小的查询处理单元),默认每个 granule 含有 8,192 行。在本示例中简化为每个 granule 仅包含 4 行。通过索引分析,Granule 3 被识别为可能包含匹配行。
③ ④ 所需列文件与数据块
磁盘中每一列单独存储为一个文件(位于某个数据分片目录中),文件由多个压缩数据块组成,每个块覆盖多个 granule。在本例中,每个块包含 2 个 granule。查询引擎判断需要读取列文件 c1.bin,并定位到其中的第 2 个数据块包含了 Granule 3。因此,该块即为本次查询的热表数据。
那么什么是热表数据?
从技术角度来看,热表数据是指列文件中与本次查询命中 granule 对应的压缩数据块。这些块会从磁盘中读取,并缓存至内存,以加速未来的查询。
在 ClickHouse 的发展过程中,热表数据的缓存方式经历了三个重要阶段:
最初,它使用的是本地磁盘上的操作系统页面缓存。这种方式既简单又高效,但高度依赖于具体机器。
在进入云时代后,我们引入了本地文件系统缓存,用以填补对象存储与内存计算之间的性能差距。
现在,我们迈出了下一步:将文件系统缓存演变为一个共享的网络服务。全新的分布式缓存保留了原有的缓存逻辑,同时能够为所有计算节点提供服务,实现了热数据访问的一致性、弹性扩展能力以及秒级响应。
下面,我们逐个回顾这三个阶段,看看它们如何一步步引领我们走向分布式缓存架构。
在传统的 shared-nothing 架构中,ClickHouse 采用分片方式进行横向扩展,每个服务器仅在本地磁盘中保存并访问属于自己的数据。在这种架构下,ClickHouse 借助操作系统自带的页面缓存机制,自动缓存查询过程中加载的列数据段。
下图动画展示了整个处理流程(点击可全屏查看):
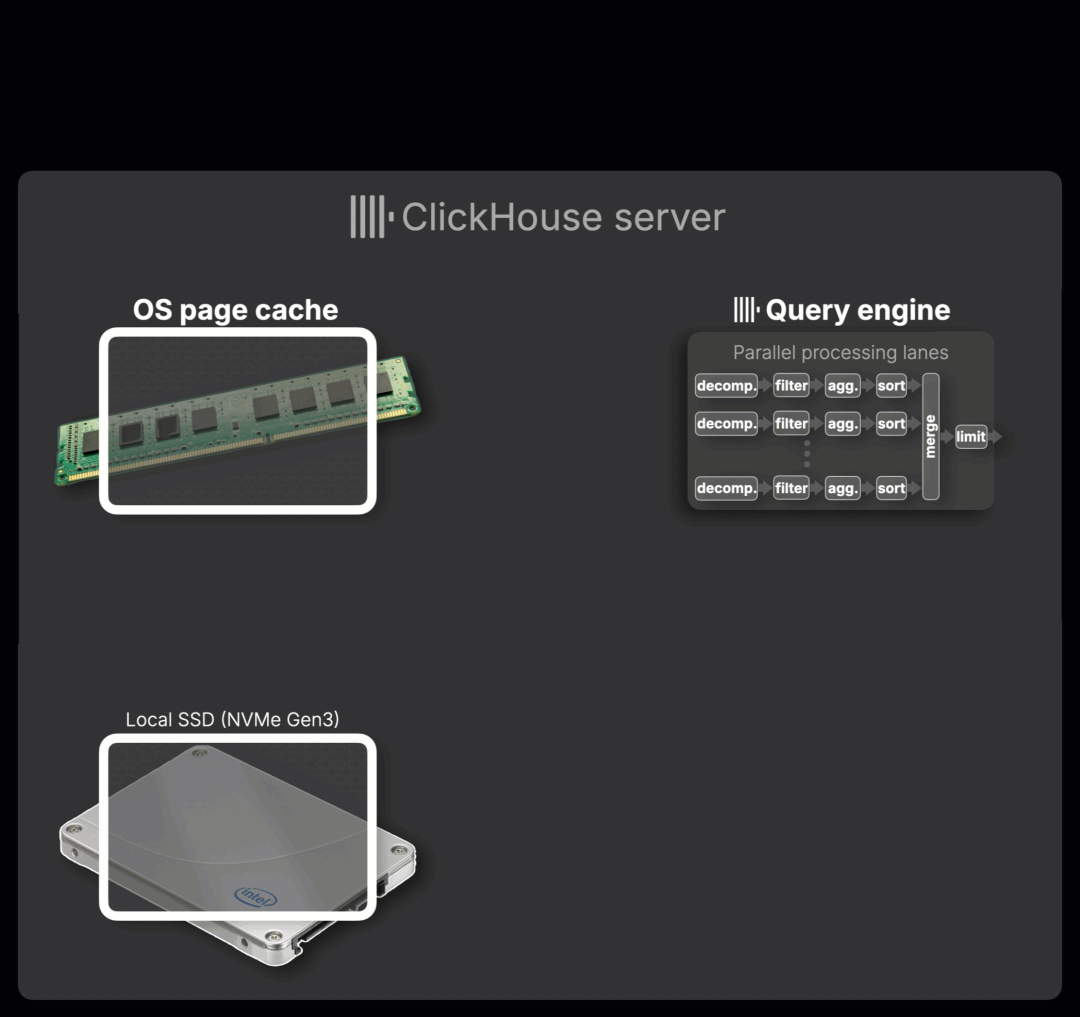
① 查询到达
一个查询抵达 ClickHouse 服务器。服务器会首先分析索引文件,以确定需要读取哪些压缩列块来满足查询条件。
② 数据加载
若所需的数据块尚未被缓存,则会从本地 SSD(例如 NVMe Gen3)读取,并自动缓存在操作系统页面缓存中。
③ 内存处理
缓存中的压缩块以流式方式传输至查询引擎,传输速度可达 50–100 GB/s,此时性能瓶颈来自内存带宽,而非磁盘 I/O。ClickHouse 随后在内存中对这些数据逐块处理,采用流式执行,利用多个独立的并行处理通道对数据进行解压、筛选、聚合与排序。
这些并发通道的数量由 max_threads 参数控制,默认等于可用的 CPU 核心数。
同一个参数也决定了在数据尚未缓存时,从磁盘读取数据所使用的并发流数量,从而实现最大化的数据加载效率,动画中对此进行了直观展示。
④ 结果生成
处理完的数据将按需合并并执行限制操作,最终返回结果给客户端。
热数据的内存缓存策略
ClickHouse 主要依赖操作系统提供的页面缓存机制,它能自动、透明地处理读写操作。这种机制既支持读取直通缓存 —— 数据被读取后直接保留在内存中,也支持写入直通缓存 —— 新写入的数据即时缓存,从而可以立即被查询,无需落盘。只要内存容量足够,数据就会保持在缓存中;一旦空间不足,系统会自动清除最近最少使用的内容。
为进一步降低查询延迟,ClickHouse 还提供了一个可选功能:未压缩块缓存。它会将经常访问的数据块以未压缩形式保存在内存中,从而避免每次都重复解压操作。虽然 ClickHouse 的解压性能已经很强,但在高频短查询场景下,直接使用未压缩数据依然可以显著提升性能。
该功能默认关闭,因为未压缩块的内存占用远高于压缩块,尤其考虑到 ClickHouse 本身具备极高的压缩比。
有趣的是,正如 Alexey Milovidov 在一次演讲中展示的那样,在内存中处理压缩数据的速度,往往还快于处理未压缩数据。
这些缓存机制在传统 shared-nothing 架构、数据保存在本地磁盘时运行良好。但如果数据不再保存在本地,又该如何处理?
在 ClickHouse Cloud 中,缓存机制发生了明显变化。由于计算与存储分离,所有计算节点都从统一的对象存储中读取数据。它们不再各自维护分片,而是作为多个副本,统一读取一个逻辑上的无限分片。
然而,这种共享存储也带来了新的性能挑战。
对象存储的真正短板:高延迟
尽管对象存储的吞吐量可以通过优化达到可接受水平,但访问延迟却往往成为性能瓶颈。为了弥补这一差距,ClickHouse Cloud 选择在计算节点上部署直连 SSD,构建本地文件系统缓存,作为对象存储与内存之间的中间缓冲层。
如下表所示,这几类存储层存在明显差异:
Layer | |||
需要说明的是,这里的分布式缓存机制与下文提到的内容并无直接关系。我们还在探索将 Amazon S3 Express One Zone(AWS 上延迟最低的云对象存储)集成至主存储与缓存体系中。该方案具备个位数毫秒级延迟,有望进一步改善性能与成本结构。点击阅读更多 →【https://aws.amazon.com/cn/blogs/storage/clickhouse-cloud-amazon-s3-express-one-zone-making-a-blazing-fast-analytical-database-even-faster/】
如图表所示,在延迟上,内存比 S3 快了几个数量级甚至百万倍,吞吐量差距同样巨大。SSD 居于中间位置,虽然远快于 S3,但依然不及内存。
而即便是在 ClickHouse Cloud 的典型部署中,S3 与 SSD 的吞吐对比如 m7gd.16xlarge 这类 EC2 实例所示 —— 2 GB/s vs. 4 GB/s —— 其实已经是在多线程并发和预取等技术手段强力优化后的表现。
事实上,原始的 S3 通常每个线程只能实现几百 MB/s 的吞吐。ClickHouse 借助多线程读取与异步预取(asynchronous prefetching)机制,才能实现多 GB/s 的性能。详细内容可参考 Kseniia 的演讲,她是本地文件系统缓存模块的核心开发者。
尽管如此,S3 的访问延迟依然是最大的短板 —— 百毫秒 vs. 微秒甚至纳秒。不同于吞吐量,延迟难以通过并行手段消除。当每一次读取都需等待数百毫秒,再多的线程也无法加快响应速度。S3 就是慢,这一点无可回避。
因此,在许多真实分析查询场景中,延迟往往成为主要瓶颈 —— 无法用带宽或并发手段“摊平”。
短查询通常只涉及少量压缩块;
而零散的数据访问模式涉及大量分布式小块读取。
在这些场景下,带宽不再是问题,延迟才是真正限制。
这正是为什么将热数据缓存到查询引擎附近如此关键 —— 不仅是为了带宽,更是为了实现真正“秒开的速度”。本地文件系统缓存正是为此而生,它有效屏蔽了对象存储的访问延迟。
文件系统缓存:不仅仅是热数据
除了缓存热表数据,ClickHouse Cloud 中基于磁盘的文件系统缓存还具备以下能力:
缓存表的元数据信息,例如跳过索引和标记文件; 存储查询过程中的中间数据,如聚合、排序和连接操作中产生的溢出数据; 缓存远程来源的外部文件(如在查询 Parquet 文件时)。
文件系统缓存的工作机制
文件系统缓存支持读写两种操作:
写入直通缓存:当有新数据写入时,系统会同时将其写入对象存储和本地文件系统缓存。这不仅包括用户主动的插入操作,也涵盖后台自动合并过程中生成的新数据分片。虽然这种机制确保了数据持久性,但并不能减少对象存储的写入延迟。不过,操作系统会自动将这些新写入的文件保留在内存中,从而在 SSD 和内存之间形成一个高效的两级缓存结构。
读取直通缓存:当系统从对象存储(如 S3)中读取数据时,会将其同时写入本地文件系统缓存中。这不仅避免了重复下载,还能让后续查询以本地磁盘的速度访问这些远程数据。
如果本地缓存磁盘空间不足,系统会自动驱逐最久未使用的数据块来腾出空间。由于 ClickHouse 的列式存储文件是不可变的,因此基本无需显式处理缓存失效的问题。
下图动画展示了读取直通缓存的实际运作过程(点击可全屏查看):

ClickHouse Cloud 中热表数据的整体处理流程在结构上与传统 shared-nothing 架构类似,但有几个关键区别:
① 查询到达
查询首先被路由至 ClickHouse Cloud 中的某个计算节点。与传统架构不同的是,该节点访问的是存储在 S3 等对象存储中的共享数据,而非本地磁盘。
② 从对象存储加载数据
如果所需数据尚未缓存在本地,系统会通过多线程读取和异步预取机制,从对象存储中流式加载数据,并将其写入本地文件系统缓存。
③ 内存缓存
数据块被加载至文件系统缓存后,操作系统页面缓存会自动将其留在内存中,从而加速未来的访问,就像传统本地磁盘环境一样。
④ ⑤ 内存中执行
查询引擎随后以并行方式对数据逐块处理,从页面缓存中流式传输数据至执行通道,速率可达 50–100 GB/s,受限于内存带宽。
我们为什么需要更好的方案?
下图动画展示了 ClickHouse Cloud 当前热数据缓存机制的一个核心限制(点击可全屏查看):
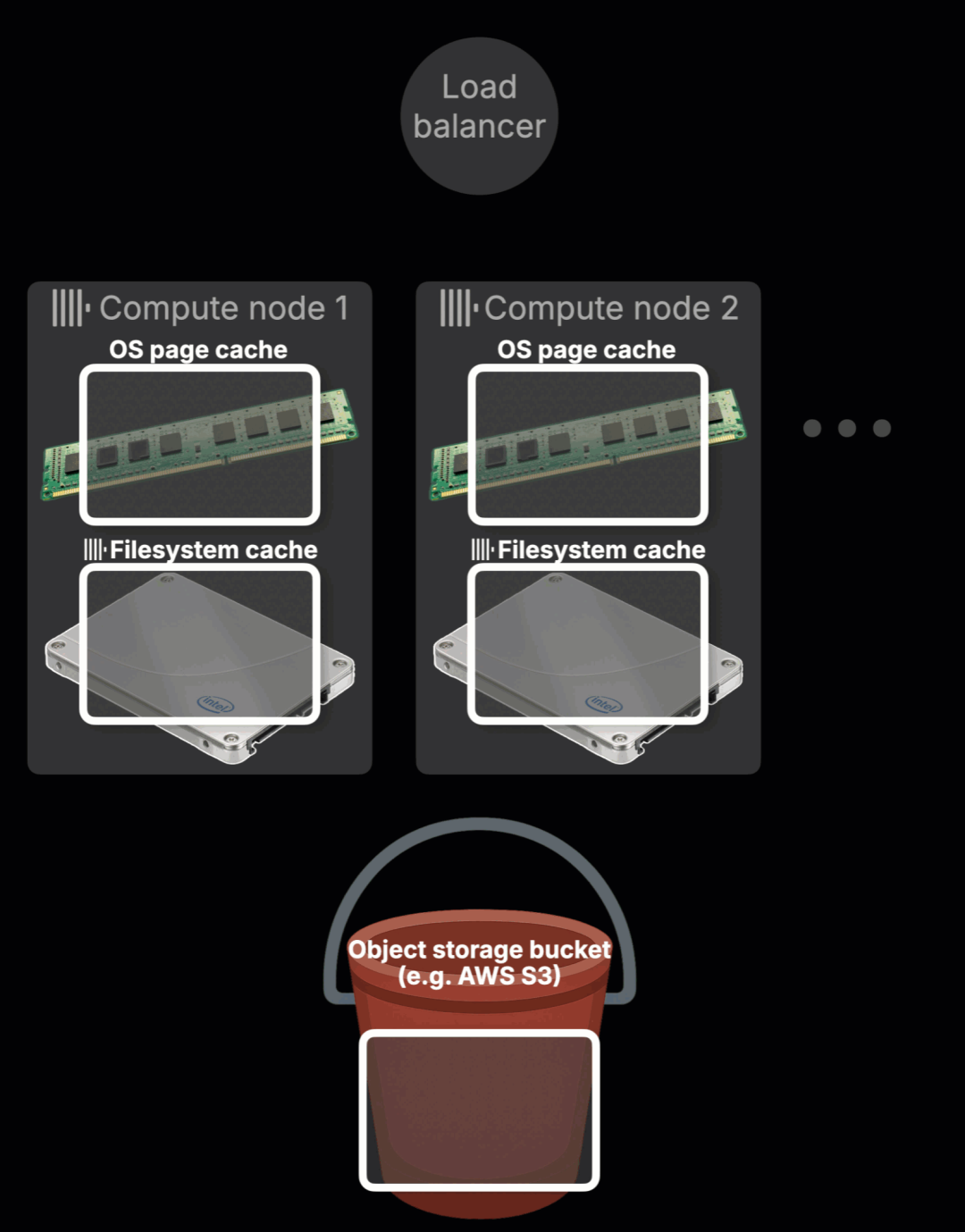
动画内容说明如下:
查询路由(①–②)
某个查询首先到达 ClickHouse Cloud 的负载均衡器,并被路由至某个计算节点(例如节点 2)。在本次查询中,节点 1 和节点 2 都还未缓存目标数据,因此属于冷缓存状态。
本地缓存(③)
节点 2 开始处理该查询,从对象存储中加载所需热表数据,并将这些数据写入本地的文件系统缓存和操作系统页面缓存。
缓存隔离的现实挑战
当一个查询被路由到另一个节点(如节点 1)时,它无法访问其他节点(如节点 2)已经缓存的数据。它必须重新从对象存储加载同样的数据,并从零开始预热缓存。
每个节点维护独立的本地文件系统缓存,这种方式虽然能保证单节点稳定性,但在如今讲求弹性和无状态的计算环境中,就显得力不从心了:
热数据无法迁移:每个节点的缓存互不共享; 缓存命中无法复用:一个节点的加载工作对其他节点没有帮助; 扩容意味着重新开始:新增或替换节点会丢失原有的缓存数据。
实际结果是:
你扩容到了更大实例,但它是冷启动,没有任何热数据; 你新增节点提升性能,却发现它还要从头加载全部数据; 查询几秒钟前还响应飞快,现在却因缓存未命中而延迟明显; 一旦计算拓扑发生变更,原有热数据立即“降温”。
本地缓存的确有用,但它的效用止步于单个节点。要让缓存真正适用于云原生环境,我们必须建立一个共享机制。
为了打破缓存孤岛、避免重复加载和冷启动带来的性能损失,我们打造了分布式缓存 —— 一个封装文件系统缓存的共享网络服务,让所有 ClickHouse 计算节点都能快速读取和写入热数据。节点不再各自建立本地缓存,而是统一接入共享缓存服务。
接下来我们来看看,这个分布式缓存系统为何具备高性能、强扩展性以及云原生特性。
栈中新增一层:网络
ClickHouse Cloud 将原本的本地文件系统缓存,升级为可通过网络访问的共享服务,这得益于现代网络的高带宽与低延迟特性。
在 AWS 中,同一区内网络延迟低至 100–250 微秒,比 S3 常见的 500 毫秒尾部响应快上百倍。网络吞吐通常可达 1.5 至 12.5 GB/s,足以媲美本地 SSD,部分高性能实例甚至可达 100 Gbps(12.5 GB/s),某些专用架构还能突破这一上限。
网络层在延迟和吞吐量方面的表现,与其他存储层相比如下:
从延迟与吞吐角度来看,网络层的表现处于 SSD 与内存之间。也正因如此,分布式缓存能有效解决对象存储的最大瓶颈 —— 高延迟问题。
而且它具备天然的扩展能力。热表数据被分布在多个缓存节点中,ClickHouse 可通过并发方式加载数据块,从而实现极高的聚合吞吐。节点数量足够时,整体性能甚至能接近内存级别,达到数十甚至上百 GB/s(稍后将介绍详细机制)。
如同本地缓存一样,分布式缓存同样让热数据贴近查询引擎 —— 先写入 SSD,再直达计算节点内存,实现实时分析所需的低延迟处理。
专为无状态计算设计
这种架构让 ClickHouse 的计算节点无需磁盘,可完全无状态运行。分布式缓存节点则采用磁盘优化配置,专为高吞吐低延迟的热数据访问而设计。
按可用区就近部署
为避免跨区流量与相关成本,分布式缓存按可用区部署。它既可以作为区域本地缓存(延迟更低),也可以配置为跨区共享缓存(提高命中率但增加延迟和成本)。缓存服务在多个 ClickHouse Cloud 服务之间共享,但彼此严格隔离,配有完整的认证与加密机制。
超越表数据
分布式文件系统缓存不仅延续了表数据的功能,还支持之前本地缓存的所有用途:缓存表元数据(如跳过索引、标记文件)、临时中间结果落盘、远程外部文件缓存(包括数据湖表文件)等。
分布式缓存的运行机制
和早期每个节点独立维护本地文件系统缓存的方式一样,分布式缓存同样支持两种模式:读取直通缓存(在查询时自动填充缓存)和 写入直通缓存(插入数据或合并表分片后,将数据保温,确保可被立即查询)。
下面这段动画展示了 ClickHouse Cloud 中分布式缓存的读取直通缓存机制(点击可全屏查看):
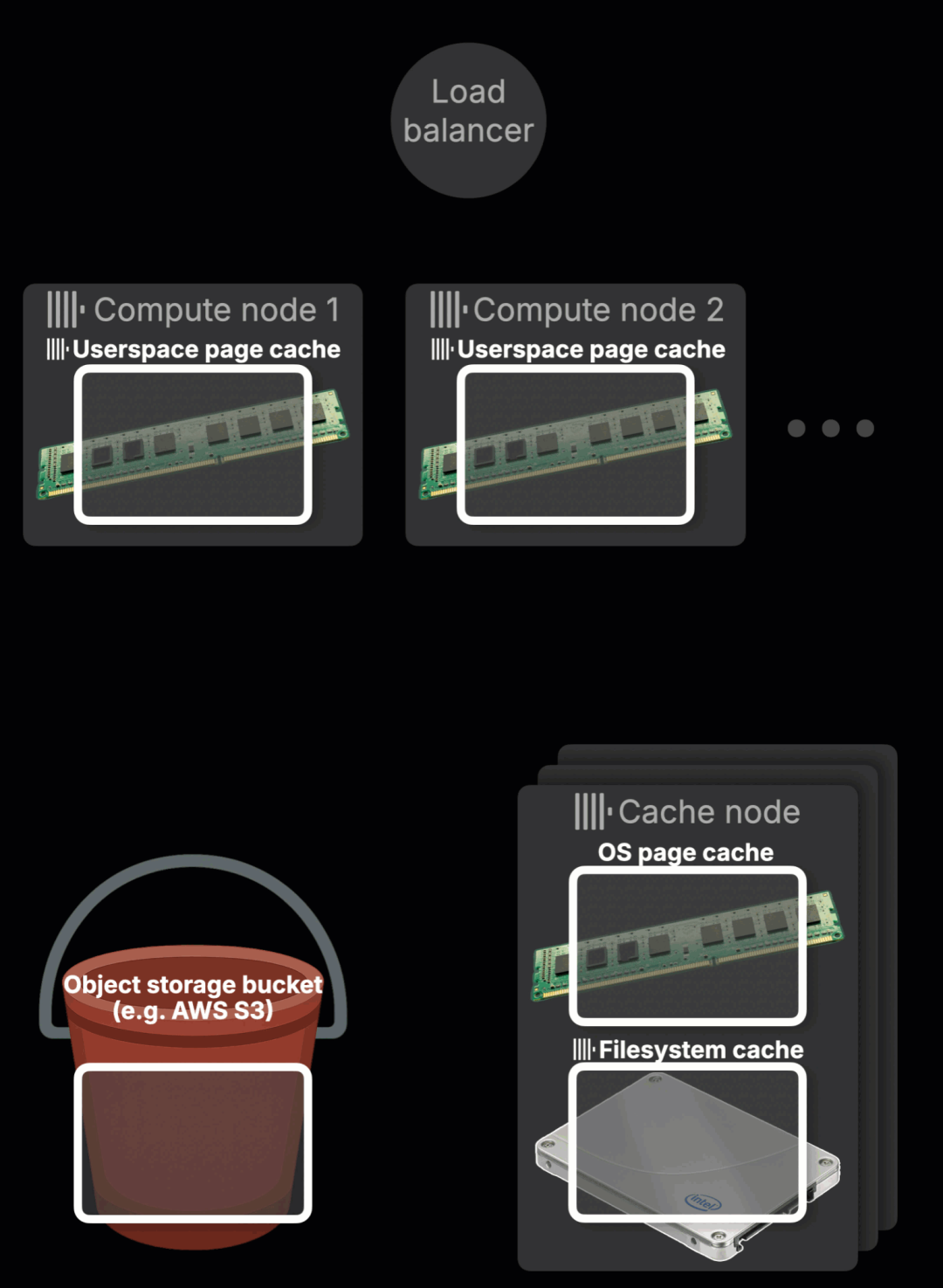
① 查询到达
查询抵达 ClickHouse Cloud 服务,由负载均衡器决定分配给哪个计算节点处理。
② 节点选择
例如该查询被路由到节点 2。在此之前,节点 1 和节点 2 都未缓存本次查询需要的数据,处于冷缓存状态。
③ 缓存查找与加载
如果计算节点的内存中尚未命中所需数据(参考下文的“用户态页面缓存”),系统会从分布式缓存中读取。这一缓存服务部署在当前可用区的多个专用节点上。每个缓存节点负责存储部分热表数据,分区采用一致性哈希(consistent hashing)方式进行划分。缓存节点若发现数据缺失,会从对象存储中拉取数据块,并将其写入本地 SSD,同时也通过操作系统页面缓存透明地加载到内存中。
④ 并行拉取数据
计算节点会并发从多个缓存节点中拉取所需的数据块。正如前文所述,热数据的访问延迟介于 SSD 和内存之间,总体吞吐甚至超过本地 SSD,常见速度为 50–100 GB/s,甚至更高。
其他节点的即时缓存复用能力
当数据被某个节点加载并加热之后,分布式缓存的真正优势便显现出来:所有计算节点都可以即时复用这份缓存。如果下一个查询被路由至另一个节点(如节点 1),它可以直接从分布式缓存中拉取热数据,无需再次访问高延迟的对象存储。
用户态页面缓存:内存中的极致加速
RAM 依旧是最快的缓存层,因此将热数据存入内存,是确保查询低延迟的关键手段。但由于 ClickHouse Cloud 的计算节点不再依赖本地磁盘,操作系统页面缓存也就无法使用。为此,我们引入了 用户态页面缓存(userspace page cache) —— 一种驻留于内存的数据缓冲区,用于缓存从分布式缓存或远程文件中读取或写入的数据。
至此,我们构建出一套完整的现代缓存架构:完全解耦、低延迟、支持并发扩展与无状态计算的现代化方案。
接下来,我们将对比这套完整缓存栈在实际环境中的表现 —— 与传统 ClickHouse 架构以及早期 ClickHouse Cloud 阶段的表现相比,它带来了怎样的提升?
我们对 ClickHouse 的不同缓存机制进行了基准测试,观察它们在实际场景中的表现。
需要说明的是,分布式缓存目前仍处于测试阶段,尚未完成全面优化与大规模扩展,因此下列测试结果尚不代表其最终生产性能。
我们在相同数据集上执行了两类查询:
- 吞吐量测试型查询:对整张表进行扫描,用于衡量系统的整体读取带宽。
- 延迟敏感型查询:进行零散、非连续读取,重点考察访问延迟。
测试覆盖了以下三种缓存架构:
自建 SSD 本地缓存的 shared-nothing 架构。 ClickHouse Cloud 使用传统的本地文件系统缓存。 ClickHouse Cloud 引入分布式文件系统缓存。
所有测试环境硬件规格相近:
自建服务器:m6i.8xlarge EC2 实例(32 核,128 GB 内存) ClickHouse Cloud 计算节点:每节点 30 核,120 GB 内存 分布式缓存后端:每个可用区部署 8 个专用缓存节点
为了保证查询完全命中缓存,我们使用了压缩后为 32 GB、可以完全装入内存的 Amazon 用户评论数据集。
SELECTformatReadableQuantity(sum(rows)) AS rows,round(sum(data_uncompressed_bytes) / 1e9) AS data_size_gb,round(sum(data_compressed_bytes) / 1e9) AS compressed_size_gbFROM system.partsWHERE active AND database = 'amazon' AND table = 'amazon_reviews';
┌─rows───────────┬─data_size_gb─┬─compressed_size_gb─┐│ 150.96 million │ 76 │ 32 │└────────────────┴──────────────┴────────────────────┘
吞吐量测试:全表扫描
为了测试实际效果,我们运行了一次全表扫描,测试环境如下:
SELECT count()FROM amazon.amazon_reviewsWHERE NOT ignore(*);
我们使用对所有压缩列的完整扫描来测试缓存的端到端吞吐能力。
结果如下图所示:
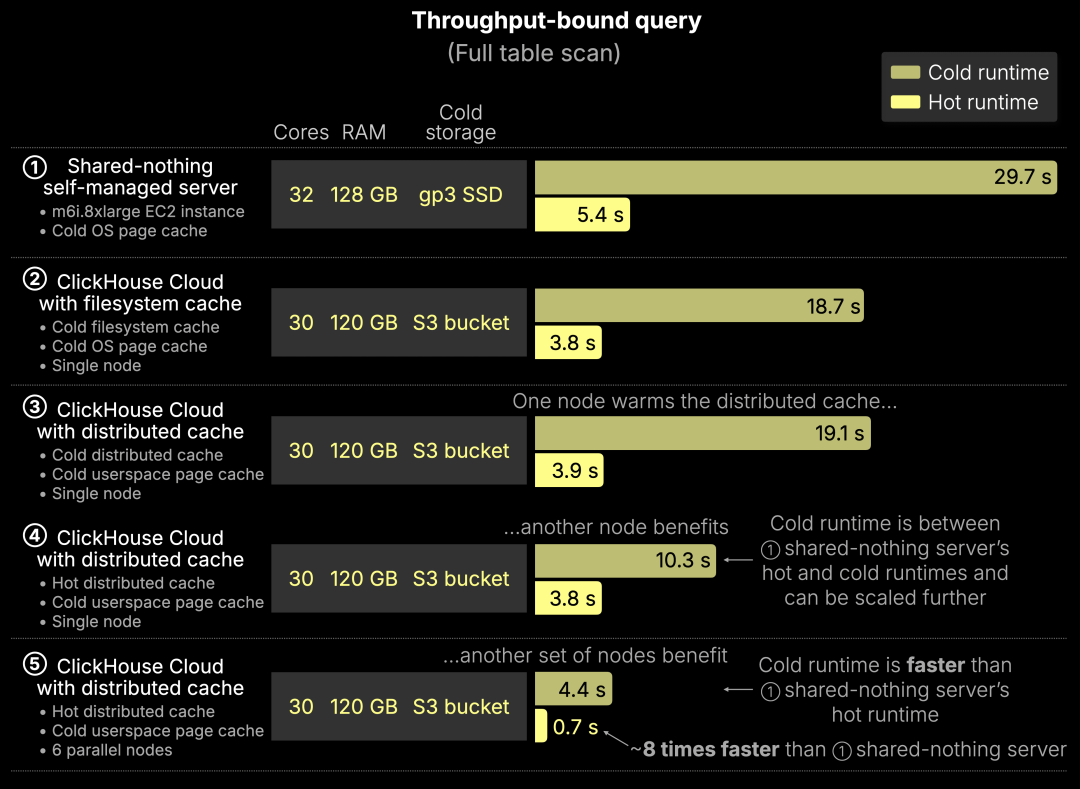
以下为五种测试配置的结果:
① 自建服务器(shared-nothing)
基线方案,使用 SSD 与 OS 页面缓存。SSD 为 gp3 EBS(16k IOPS,1000 MiB/s),为该实例类型中性能最高的选项。
冷启动(cold run):29.7 秒 —— 完全依赖 SSD 扫描 热启动(hot run):5.4 秒 —— 热数据被 OS 页面缓存命中,执行更快
② ClickHouse Cloud + 本地文件系统缓存
使用直连 SSD 缓存 S3 数据的单个计算节点。
冷启动:18.7 秒 —— 多线程读取 + 预取机制让性能优于① 热启动:3.8 秒 —— 热数据命中页面缓存,快速执行
③ ClickHouse Cloud + 分布式缓存(首次加载)
单节点首次加载数据,写入分布式缓存及本地用户态页面缓存。
冷启动:19.1 秒 —— 与②相近 热启动:3.9 秒 —— 所有热数据保留在用户态页面缓存中
④ ClickHouse Cloud + 分布式缓存(其他节点复用)
第二个节点冷启动,但分布式缓存已有热数据。
冷启动:10.3 秒 —— 无需访问 S3,从分布式缓存并发拉取数据 比 S3 快近 2 倍 比自建 SSD 架构快约 3 倍 热启动:3.8 秒 —— 与③相同,用户态缓存命中
⑤ ClickHouse Cloud + 分布式缓存(6 节点并发冷启动)
6 个冷启动节点并发查询,全部从分布式缓存中读取。
冷启动:4.4 秒 —— 比①的热启动还快 热启动:0.7 秒 —— 比①热启动快 8 倍,得益于并发读取 + 缓存共享实现的超线性提升
我们只需要添加无状态计算节点即可扩展集群性能,就这么简单。而在传统 shared-nothing 架构中,若想实现这样的并行度,需要手动进行数据重分片与再分布,过程繁琐、耗时。而当需要缩容时,还得再重复一次。在 ClickHouse Cloud 中,这一切都由弹性扩展自动完成。
共享缓存 + 弹性计算 = 即便冷启动也能超越本地 SSD 的性能表现。
零散查询的延迟测试
当查询规模减小时,系统瓶颈就从吞吐量转向了延迟。本次测试使用了一个轻量级查询,涉及多个不连续、零散的数据读取。由于数据量不足以填满 I/O 管道,延迟就成为决定性能的关键因素。
SELECT *FROM amazon.amazon_reviewsWHERE review_date in ['1995-06-24', '2015-06-24', …]FORMAT Null;
在这种场景下,ClickHouse 无法依赖多线程并发读取来“掩盖”延迟,真正影响结果的是每一次小数据读取的完成速度。
测试结果如下所示:

以下是各个方案在延迟测试中的表现拆解:
① 自建服务器(shared-nothing 架构)
这是评估低延迟访问的基准方案,基于 SSD 和操作系统页面缓存。
冷启动:0.18 秒 —— 直接从本地 SSD 读取 热启动:65 毫秒 —— 通过 OS 页面缓存实现的内存级访问速度
② ClickHouse Cloud + 本地文件系统缓存
包含本地 SSD 和操作系统缓存的计算节点,用作 S3 缓存。
冷启动:0.46 秒 —— 由于 S3 初始延迟,性能劣于自建方案
不同于吞吐量测试,在吞吐场景下,Cloud 的多线程 + 预取机制让其即使从 S3 读取也能胜出。但在这种零散查询中,这一优势不复存在。由于数据块太小、过于离散,无法形成有效并发。哪怕多个线程同时发起读取,最终还是受限于最慢一次访问的延迟(尾部延迟)。此时,S3 的高延迟显现无疑。
热启动:60 毫秒 —— 与自建方案几乎一致
③ ClickHouse Cloud + 分布式缓存(首次加载)
分布式缓存与用户态页面缓存均为空。
冷启动:0.42 秒 —— 与②相近 热启动:59 毫秒 —— 与其他缓存预热后的表现一致
④ ClickHouse Cloud + 分布式缓存(其他节点访问)
分布式缓存已热,计算节点的内存缓存仍为空。
冷启动:0.21 秒 —— 数据通过网络从分布式缓存拉取,无需访问 S3 表现几乎与本地 SSD 一致,却无需本地磁盘 热启动:59 毫秒 —— 与最佳结果一致,完全命中内存
我们在不依赖本地磁盘的前提下,实现了 SSD 级甚至内存级的延迟表现。
通过将缓存从计算中解耦,分布式缓存让 ClickHouse Cloud 能够在弹性、无状态架构中实现对热数据的快速一致访问。
带来的优势包括:
- 更快的热启动:任意计算节点都能从分布式缓存中低延迟加载数据,无需重新访问对象存储;
- 缓存共享:一次缓存,多节点受益;
- 弹性扩展:任意添加、移除或调整计算节点规模,缓存数据不会丢失;
- 无状态计算:节点无需本地持久化,也无需重启后重建缓存。
在测试数据集上的基准测试结果显示,分布式缓存带来了显著性能收益,尤其体现在两大方面:
- 吞吐性能:在全表扫描中,冷查询的执行速度比传统自建 SSD 架构快了最多 4 倍,得益于并行拉取与缓存共享;
- 延迟表现:在零散小查询中,冷启动查询性能等同 SSD,热启动则达到了低于 60 毫秒的内存级访问速度 —— 全程无需本地存储。
这些结果充分说明:云原生缓存机制无需依赖本地磁盘,也能达到甚至超越 SSD 级的性能表现。它代表了一种根本性的能力升级,使 ClickHouse Cloud 更加敏捷、高效、易于运维,尤其适合动态扩展、并发密集的现代分析场景。
目前,分布式缓存已支持 S3 和 GCS,对 Azure Blob Storage 的支持也即将推出。
想要体验这一性能飞跃?我们现已开放分布式缓存的私密预览申请,欢迎抢先注册,共同参与低延迟分析架构的下一阶段进化。

我们正为杭州活动招募讲师,如果你有独特的技术见解、实践经验或 ClickHouse 使用故事,非常欢迎你加入我们,成为这次活动的讲师,与大家分享你的经验。

/END/
试用阿里云 ClickHouse企业版
轻松节省30%云资源成本?阿里云数据库ClickHouse 云原生架构全新升级,首次购买ClickHouse企业版计算和存储资源组合,首月消费不超过99.58元(包含最大16CCU+450G OSS用量)了解详情:https://t.aliyun.com/Kz5Z0q9G


征稿启示
面向社区长期正文,文章内容包括但不限于关于 ClickHouse 的技术研究、项目实践和创新做法等。建议行文风格干货输出&图文并茂。质量合格的文章将会发布在本公众号,优秀者也有机会推荐到 ClickHouse 官网。请将文章稿件的 WORD 版本发邮件至:Tracy.Wang@clickhouse.com


