




在数据库系统中,合理的数据表设计不仅能确保数据的完整性和一致性,还能大幅提升查询性能、存储效率以及系统的可扩展性。
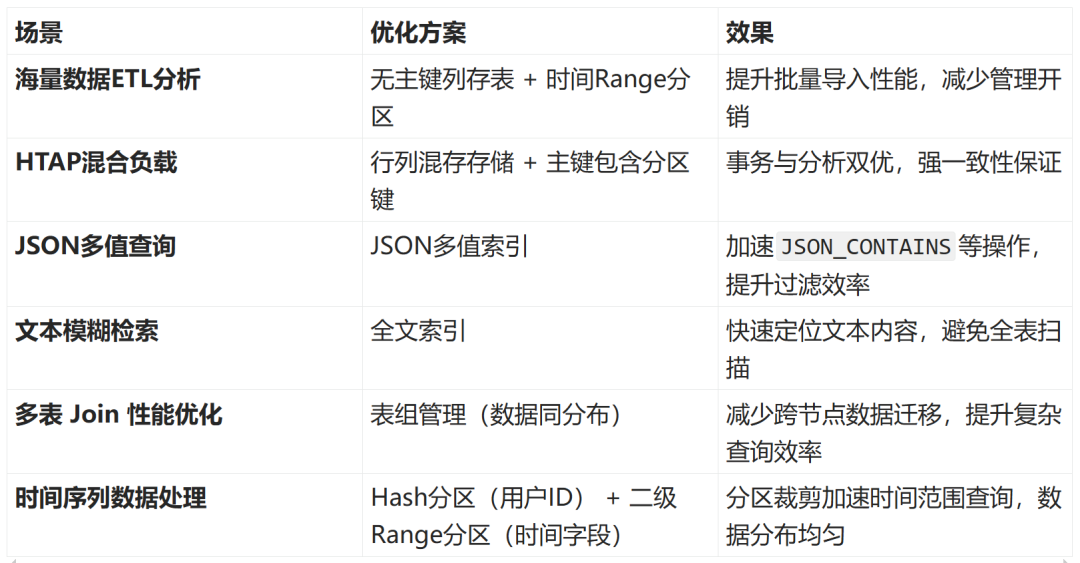
OceanBase 4.3.5 全新推出堆组织表功能,在高并发交易、海量数据分析、HTAP 混合负载等场景下,数据表设计和索引优化可在保障事务一致性的同时,实现复杂分析查询的秒级相应。本文将结合选择表的存储格式、表结构设计、主键设计,向您介绍数据表设计的最佳实践。
一、核心价值与适用场景
二、存储格式选择策略
(一)行存与列存特性对比
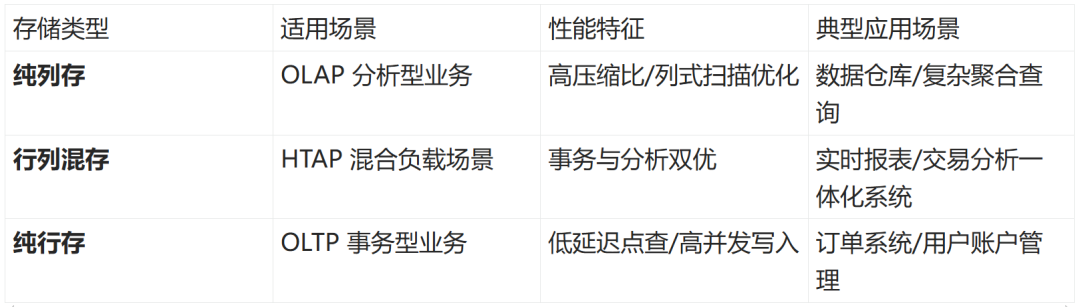
(二)行列存储配置方法
-- 查看当前存储格式配置SHOW PARAMETERS LIKE '%store_format%';-- 设置租户级默认存储格式ALTER SYSTEM SET default_table_store_format = "column"; -- 列存模式ALTER SYSTEM SET default_table_store_format = "compound"; -- 行列混存模式
三、表结构设计规范
(一)索引组织表与堆组织表设计
1、索引组织表与堆组织表对比
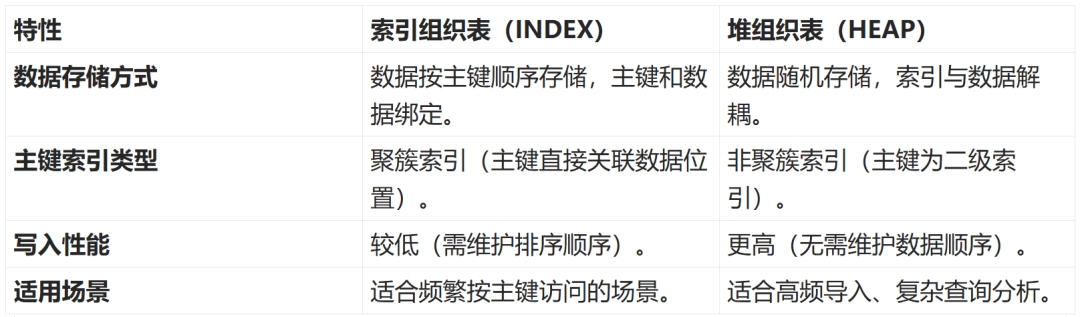
索引组织表(INDEX)
索引组织表有以下三个特点:
👉 主键和数据绑定:数据按主键存储和排序,主键为聚簇索引(Clustered Index),无额外空间开销。
👉 高效访问:主键直接关联数据存储位置,查询时通过主键定位数据更高效。
👉 写入性能:插入数据需按主键顺序存储,可能影响写入速度(尤其在高并发场景)。
示例表结构:
CREATE TABLE customer (user_id bigint NOT NULL,login_time timestamp NOT NULL,customer_name varchar(100) NOT NULL,phone_num bigint NOT NULL,city_name varchar(50) NOT NULL,sex int NOT NULL,id_number varchar(18) NOT NULL,home_address varchar(255) NOT NULL,office_address varchar(255) NOT NULL,age int NOT NULL);
说明:此示例默认为索引组织表。OceanBase 数据库提供配置项 default_table_organization 控制默认创建表的表组织模式。设置配置项的值为 HEAP,表示表组织形式为堆组织表;设置配置项的值为 INDEX,表示表组织形式为索引组织表。
堆组织表(HEAP)
OceanBase V4.3.5 BP1 及以上版本支持堆组织表。特点如下:
👉 数据无序存储:插入数据不依赖主键排序。
👉 主键为二级索引:主键实际为非聚簇索引(Non-Clustered Index),数据与索引解耦。
👉 写入性能优势:因无需维护数据顺序,写入速度更快。
示例表结构:
CREATE TABLE customer_heap (user_id BIGINT NOT NULL PRIMARY KEY,login_time TIMESTAMP NOT NULL,customer_name VARCHAR(100) NOT NULL,...) ORGANIZATION = HEAP;
(二)分区设计策略
分区场景有以下两种:
👉 数据量过大:当数据表的记录数达到亿级甚至更高时,单表操作会导致查询性能下降,甚至引发数据库的资源瓶颈。
👉 查询频繁依赖某些字段:例如,时间字段是常用的查询条件之一,按时间分区能够提高时间相关查询的效率。
分区类型选择策略:
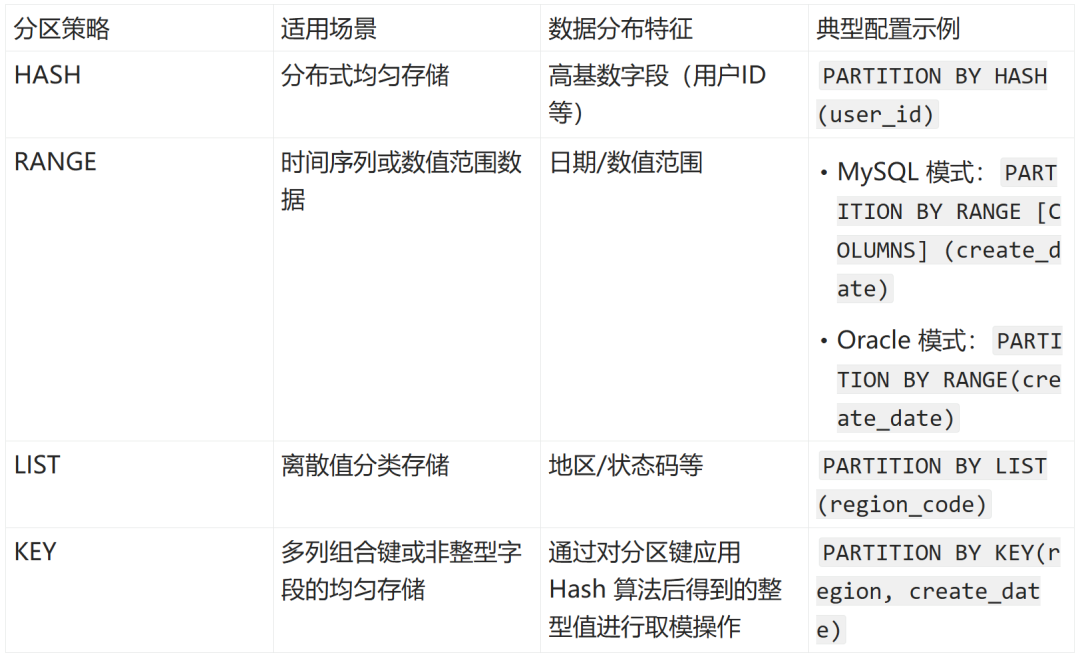
注意:OceanBase 数据库 KEY 分区仅 MySQL 模式支持。在 AP 场景里,通常涉及多个维度的分析查询,如果没有一个维度可以将数据进行分区且适用于各查询,而又需要分区将数据打散分布到多台机器,利用分布式节点计算的能力,此时可按如下方式选择分区键做 Hash 分区,尽量将用户数据均匀打散:
👉 NDV(即 number of distinct values,表示某一列中不同值的数量)远大于分区数。
👉 此列数据没有倾斜,或只有少量倾斜,例如:交易 ID、用户 ID 或者自增列等。
👉 优先选择整形列,时间列,再考虑 varchar/char。
👉 优先选择高频率出现查询条件的字段,方便分区裁剪。
选择 HASH 分区示例如下:
CREATE TABLE customer (user_id BIGINT NOT NULL,login_time TIMESTAMP NOT NULL,customer_name VARCHAR(100) NOT NULL,phone_num BIGINT NOT NULL,city_name VARCHAR(50) NOT NULL,sex INT NOT NULL,id_number VARCHAR(18) NOT NULL,home_address VARCHAR(255) NOT NULL,office_address VARCHAR(255) NOT NULL,age INT NOT NULL)PARTITION BY HASH(user_id) PARTITIONS 128;
(三)主键设计
加主键的场景主要包括以下两个方面:
👉 保证数据唯一性:当表中的数据需要确保每条记录的唯一性时,可以设计主键。
👉 提高查询效率:主键能够帮助优化器生成更高效的查询计划,尤其是当数据查询依赖于主键时,建议将查询一定会携带的字段作为主键字段,这样可以利用主键来提升查询性能。
示例如下所示:
CREATE TABLE customer (user_id BIGINT NOT NULL,login_time TIMESTAMP NOT NULL,customer_name VARCHAR(100) NOT NULL,phone_num BIGINT NOT NULL,city_name VARCHAR(50) NOT NULL,sex INT NOT NULL,id_number VARCHAR(18) NOT NULL,home_address VARCHAR(255) NOT NULL,office_address VARCHAR(255) NOT NULL,age INT NOT NULL,PRIMARY KEY (user_id, age, login_time))PARTITION BY HASH(user_id)PARTITIONS 128SUBPARTITION BY RANGE(age)SUBPARTITION TEMPLATE (SUBPARTITION p_youth VALUES LESS THAN (25),SUBPARTITION p_adult VALUES LESS THAN (40),SUBPARTITION p_middle_aged VALUES LESS THAN (60),SUBPARTITION p_senior VALUES LESS THAN (MAXVALUE));
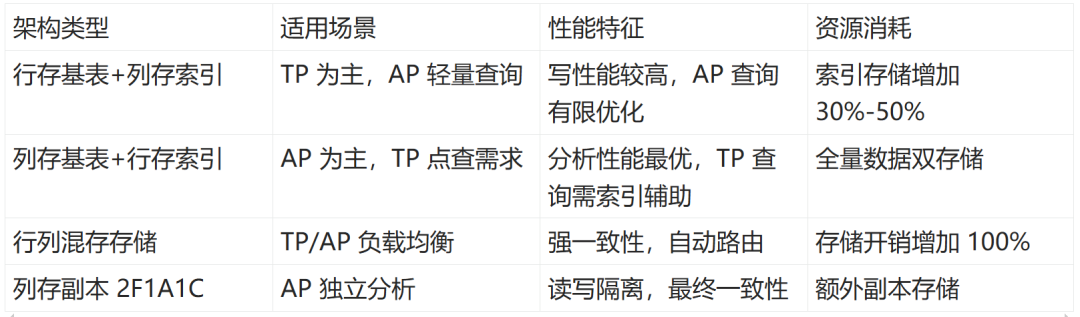
四、HTAP 混合负载优化方案
存储架构选型包括以下几种类型:
五、特殊索引优化实践
(一)JSON 多值索引
JSON 多值索引是专门为 JSON 文档中数组字段设计的索引类型,适用于需要对多个值或属性进行查询的场景。典型应用包括:
多对多关联查询:当两个实体之间存在多对多关系时,多值索引可以加速查询。例如,演员可以出演多部影片,而一部影片可能由多个演员参与。可以使用 JSON 数组保存影片涉及的所有演员,并利用 JSON 多值索引优化查询特定演员出演的影片。
标签和分类查询:当实体具有多个标签或分类时,可以使用多值索引加速查询。例如,一个商品可能包含多个标签属性,通过 JSON 数组存储商品的多个标签,可以快速查询包含某个或多个标签的商品。
JSON 多值索引则常用于加速基于 JSON 数组且 WHERE 条件中带有以下三种谓词的查询:
👉 MEMBER OF()
👉 JSON_CONTAINS()
👉 JSON_OVERLAPS()
更多关于 JSON 多值索引的详细信息,可通过下方链接,参考多值索引:
https://www.oceanbase.com/docs/common-oceanbase-database-cn-1000000002016787
假设我们有一张用户信息表,记录用户 ID、姓名、年龄和爱好,其中爱好以 JSON 数组形式保存。一个用户可能会有多个爱好,这些爱好可以理解为用户的标签。用于存储用户信息的表结构即数据如下:
create table user_info(user_id bigint, name varchar(1024), age bigint, hobbies json);insert into user_info values(1, "LiLei", 18, '["reading", "knitting", "hiking"]');insert into user_info values(2, "HanMeimei", 17, '["reading", "Painting", "Swimming"]');insert into user_info values(3, "XiaoMing", 19, '["hiking", "Camping", "Swimming"]');
在商品广告投放中,需要根据用户的爱好进行精准定位。例如,在投放登山户外设备广告之前,需要查询哪些用户有“hiking”的爱好。对应的查询语句如下:
select user_id, name from user_info where JSON_CONTAINS(hobbies->'$[*]', CAST('["hiking"]' AS JSON));查询返回结果如下所示:
+---------+----------+| user_id | name |+---------+----------+| 1 | LiLei || 3 | XiaoMing |+---------+----------+
现在我们执行以下语句,检查初次查询的效率:
-- 初次执行该查询时,可能需要全表扫描,效率较低Explain select user_id, name from user_info where JSON_CONTAINS(hobbies->'$[*]', CAST('["hiking"]' AS JSON));
返回结果如下所示:
+-------------------------------------------------------------------------------------------------------------------------------------------------------------------------+| Query Plan |+-------------------------------------------------------------------------------------------------------------------------------------------------------------------------+| ==================================================== || |ID|OPERATOR |NAME |EST.ROWS|EST.TIME(us)| || ---------------------------------------------------- || |0 |TABLE FULL SCAN|user_info|2 |3 | || ==================================================== || Outputs & filters: || ------------------------------------- || 0 - output([user_info.user_id], [user_info.name]), filter([JSON_CONTAINS(JSON_EXTRACT(user_info.hobbies, '$[*]'), cast('[\"hiking\"]', JSON(536870911)))]), rowset=16 || access([user_info.hobbies], [user_info.user_id], [user_info.name]), partitions(p0) || is_index_back=false, is_global_index=false, filter_before_indexback[false], || range_key([user_info.__pk_increment]), range(MIN ; MAX)always true |+-------------------------------------------------------------------------------------------------------------------------------------------------------------------------+11 rows in set
从上面的查询计划可以看出,整个查询需要对全表进行扫描(也就是TABLE FULL SCAN),且逐行对 JSON 数组进行过滤比对。JSON 本身的过滤开销也不小,当需要过滤的记录行数达到一定数量的时候,会严重影响查询的效率。此时,通过在 hobbies 列上创建 JSON 多值索引,可显著提升该查询的效率。
当前 JSON 多值索引的后建功能默认关闭,需要在 Sys 租户下打开后建 JSON 多值索引的开关。
Alter system set _enable_add_fulltext_index_to_existing_table = true;-- 可以看到,查询计划显示需要对整个表进行扫描。为优化性能,建议在 hobbies 列上创建 JSON 多值索引:CREATE TABLE user_info (user_id BIGINT,name VARCHAR(1024),age BIGINT,hobbies JSON,INDEX idx1((CAST(hobbies->"$[*]" AS UNSIGNED ARRAY))));
再次查询,查看查询效率是否提升:
-- 创建索引后,再次执行查询,性能显著提升Explain select user_id, name from user_info where JSON_CONTAINS(hobbies->'$[*]', CAST('["hiking"]' AS JSON));
返回结果如下所示:
+--------------------------------------------------------------------------------------------------------------------------------------------------------------+| Query Plan |+--------------------------------------------------------------------------------------------------------------------------------------------------------------+| ========================================================== || |ID|OPERATOR |NAME |EST.ROWS|EST.TIME(us)| || ---------------------------------------------------------- || |0 |TABLE FULL SCAN|user_info(idx1)|1 |10 | || ========================================================== || Outputs & filters: || ------------------------------------- || 0 - output([user_info.user_id], [user_info.name]), filter([JSON_CONTAINS(JSON_EXTRACT(user_info.hobbies, '$[*]'), cast('[\"hiking\"]', JSON(536870911)))]) || access([user_info.__pk_increment], [user_info.hobbies], [user_info.user_id], [user_info.name]), partitions(p0) || is_index_back=true, is_global_index=false, filter_before_indexback[false], || range_key([user_info.SYS_NC_mvi_21], [user_info.__pk_increment], [user_info.__doc_id_1733716274684183]), range(hiking,MIN,MIN ; hiking,MAX,MAX) |+--------------------------------------------------------------------------------------------------------------------------------------------------------------+11 rows in set
需要注意的是,JSON 多值索引会占用额外存储空间,并可能对写入性能造成影响,当对包含多值索引的 JSON 字段进行修改(如插入、更新、删除操作)时,索引也会随之更新,写入的开销会变大。因此在使用过程中需要权衡 JSON 多值索引的优缺点,按需创建。
(二)全文索引
在涉及大量文本数据需要进行模糊检索的场景,如果通过全表扫描来对每一行数据进行模糊查询,文本较大、数据量较多的情况下性能往往不能满足要求。另外一些复杂的查询场景,如近似匹配、相关性排序等,也难以通过改写 SQL 支撑。
为了更好的支撑这些场景,全文索引应运而生,它通过预先处理文本内容,建立关键词索引,有效提升全文检索效率。全文索引适用于多种场景,下面列举几个具体的案例:
企业内部知识库:许多大型企业都会构建自己的内部知识库系统,用来存储项目文档、会议记录、研究报告等资料。使用全文索引可以帮助员工更加快速准确地找到所需信息,提高工作效率。
在线图书馆与电子书平台:对于提供大量书籍资源供用户阅读的服务来说,全文索引是极其重要的。用户可以输入书名、作者名字甚至是书中某段文字作为关键字来进行搜索,系统基于全文索引迅速定位到符合条件的结果。
新闻门户和社交媒体网站:这类平台上每天都会产生海量的新鲜内容,包括文章、帖子、评论等。利用全文索引可以让用户按照自己关心的话题、事件或是人物名称来过滤信息流,获取最相关的内容。
法律文书检索系统:法律行业涉及到大量的文件审阅工作,如合同、判决书、法律法规条文等。一个高效的全文搜索引擎能够极大地简化律师的工作流程,让他们能够更快地找到先例、引用条款以及相关的法律依据。
医疗健康信息系统:在医疗领域,医生经常需要查阅病人的历史病例、最新的医学研究论文以及其他参考资料。借助全文索引,医护人员可以更加便捷地访问相关信息,从而做出更为准确的诊断决策。
任何涉及到大量非结构化文本数据管理和查询的应用都可以考虑采用全文索引来提升检索效率。更多关于 OceanBase 全文检索能力的详细信息,可通过下方链接,参见全文索引。
https://www.oceanbase.com/docs/common-oceanbase-database-cn-1000000002016782
我们定义一个表以保存文档资料,并为文档设置全文索引。利用全文索引可快速匹配包含期望关键字的文档,并按相似性从高到低排序。
CREATE TABLE Articles (id INT AUTO_INCREMENT,title VARCHAR(255) ,content TEXT ,PRIMARY KEY (id),FULLTEXT ft1 (content) WITH PARSER SPACE);INSERT INTO Articles (title, content) VALUES('Introduction to OceanBase', 'OceanBase is an open-source relational database management system.'),('Full-Text Search in Databases', 'Full-text search allows for searching within the text of documents stored in a database. It is particularly useful for finding specific information quickly.'),('Advantages of Using OceanBase', 'OceanBase offers several advantages such as high performance, reliability, and ease of use. ');select * from Articles;
查询返回结果如下所示:
+----+-------------------------------+--------------------------------------------------------------------------------------------------------------------------------------------------------------+| id | title | content |+----+-------------------------------+--------------------------------------------------------------------------------------------------------------------------------------------------------------+| 1 | Introduction to OceanBase | OceanBase is an open-source relational database management system. || 2 | Full-Text Search in Databases | Full-text search allows for searching within the text of documents stored in a database. It is particularly useful for finding specific information quickly. || 3 | Advantages of Using OceanBase | OceanBase offers several advantages such as high performance, reliability, and ease of use. |+----+-------------------------------+--------------------------------------------------------------------------------------------------------------------------------------------------------------+3 rows in SET
再次执行下面的查询语句,查询匹配的文档:
-- 查询匹配的文档select id,title, content,match(content) against('OceanBase database') score from Articles where match(content) against('OceanBase database');
返回结果如下所示:
+----+-------------------------------+--------------------------------------------------------------------------------------------------------------------------------------------------------------+---------------------+| id | title | content | score |+----+-------------------------------+--------------------------------------------------------------------------------------------------------------------------------------------------------------+---------------------+| 1 | Introduction to OceanBase | OceanBase is an open-source relational database management system. | 0.5699481865284975 || 3 | Advantages of Using OceanBase | OceanBase offers several advantages such as high performance, reliability, and ease of use. | 0.240174672489083 || 2 | Full-Text Search in Databases | Full-text search allows for searching within the text of documents stored in a database. It is particularly useful for finding specific information quickly. | 0.20072992700729927 |+----+-------------------------------+--------------------------------------------------------------------------------------------------------------------------------------------------------------+---------------------+3 rows in set
利用下面的 EXPLAIN 命令,您可以查看查询计划并分析其性能:
Explain select id,title, content,match(content) against('OceanBase database') score from Articles where match(content) against('OceanBase database');执行结果如下所示:
+-----------------------------------------------------------------------------------------------------------------------------------------------------+| Query Plan |+-----------------------------------------------------------------------------------------------------------------------------------------------------+| ============================================================== || |ID|OPERATOR |NAME |EST.ROWS|EST.TIME(us)| || -------------------------------------------------------------- || |0 |SORT | |17 |145 | || |1 |└─TEXT RETRIEVAL SCAN|articles(ft1)|17 |138 | || ============================================================== || Outputs & filters: || ------------------------------------- || 0 - output([articles.id], [articles.title], [articles.content], [MATCH(articles.content) AGAINST('OceanBase database')]), filter(nil), rowset=256 || sort_keys([MATCH(articles.content) AGAINST('OceanBase database'), DESC]) || 1 - output([articles.id], [articles.content], [articles.title], [MATCH(articles.content) AGAINST('OceanBase database')]), filter(nil), rowset=256 || access([articles.id], [articles.content], [articles.title]), partitions(p0) || is_index_back=true, is_global_index=false, || calc_relevance=true, match_expr(MATCH(articles.content) AGAINST('OceanBase database')), || pushdown_match_filter(MATCH(articles.content) AGAINST('OceanBase database')) |+-----------------------------------------------------------------------------------------------------------------------------------------------------+15 rows in set
六、分布式环境优化
(一)表组管理
对于分布式数据库, 多个表由于划分分区使得数据可能会分布在不同的机器上, 这样在执行 JOIN 查询等复杂操作时就需要涉及跨机器的通信,可以利用表组的能力来避免跨机访问带来的查询性能不优的问题。创建一个 Sharding 属性为 ADAPTIVE 的表组 tg1,和两个一级分区表 customer、sales。在两个分区表的连接操作中,若连接条件包含分区键时,可以使用 Partition Wise Join 的方式提升性能。示例如下:
CREATE TABLEGROUP tg1 SHARDING = 'ADAPTIVE';CREATE TABLE customer (user_id BIGINT NOT NULL,login_time TIMESTAMP NOT NULL,customer_name VARCHAR(100) NOT NULL,phone_num BIGINT NOT NULL,city_name VARCHAR(50) NOT NULL,sex INT NOT NULL,id_number VARCHAR(18) NOT NULL,home_address VARCHAR(255) NOT NULL,office_address VARCHAR(255) NOT NULL,age INT NOT NULL)TABLEGROUP = tg1PARTITION BY HASH(user_id) PARTITIONS 128;CREATE TABLE sales (order_id INT,user_id INT primary key,item_id INT,item_count INT)TABLEGROUP = tg1PARTITION BY HASH(user_id) PARTITIONS 128;SELECT * FROM customer, sales where customer.user_id = sales.user_id;
(二)二级分区管理
如果业务数据量很大,且查询特点清晰,可以创建二级分区,来进一步利用分区裁剪的能力加速查询。AP 的查询特点通常是查询最近一天或者一个月的数据,通常是带有时间属性的查询,所以二级分区键建议选择时间类型的字段或时间函数,并且选择 Range 分区方便做范围查询。
CREATE TABLE customer (user_id BIGINT NOT NULL,login_time TIMESTAMP NOT NULL,customer_name VARCHAR(100) NOT NULL,phone_num BIGINT NOT NULL,city_name VARCHAR(50) NOT NULL,sex INT NOT NULL,id_number VARCHAR(18) NOT NULL,home_address VARCHAR(255) NOT NULL,office_address VARCHAR(255) NOT NULL,age INT NOT NULL,-- 主键包含所有分区键(user_id 和 age)PRIMARY KEY (user_id, age, login_time))-- 主分区:按 user_id 哈希分布PARTITION BY HASH(user_id)PARTITIONS 128SUBPARTITION BY RANGE(age)SUBPARTITION TEMPLATE (-- 示例分区:按年龄段划分SUBPARTITION p_youth VALUES LESS THAN (25),SUBPARTITION p_adult VALUES LESS THAN (40),SUBPARTITION p_middle_aged VALUES LESS THAN (60),SUBPARTITION p_senior VALUES LESS THAN (MAXVALUE));
(三)注意事项
1、索引权衡:JSON 多值索引和全文索引会增加存储开销,需根据写入频率与查询需求权衡。
2、分区键选择:
👉 主键必须包含所有分区键。
👉 Hash/Key 分区键需选择高基数、无倾斜、高频查询的字段,如用户 ID、订单号等。
👉 Range 分区键可选择时间列、数值列按范围划定分区。
👉 LIST 分区键可选择低基数字段,如省份、公司名称等。
3、分布式设计:关联表需同表组部署,确保数据同分布,降低 JOIN 操作的网络开销。
4、二级分区:AP 场景优先按时间或业务维度字段设计二级 Range 分区(如按季度划分),无需避免低基数字段,但需确保分区逻辑与查询模式匹配。
OceanBase 数据表设计与索引优化的核心逻辑,是围绕业务场景需求实现 “数据存储结构化” 与 “查询效率最大化” 的平衡。通过选择行存 / 列存 / 行列混存的存储格式,结合主键设计、分区策略(如 Hash+Range 二级分区)与表组管理,可解决海量数据下的存储与查询瓶颈;而 JSON 多值索引、全文索引等特性,则为非结构化数据查询提供了专项优化方案。
随着 OceanBase 在各类业务场景下不断打磨,其性能、稳定性与可扩展性显著提升,已成为企业级应用坚实的数据底座支撑。
