




摘要:本文由 Fluss Contributor Giannis Polyzos 撰写,由阿里云智能汪洋老师翻译,主要分为以下几个内容:
部分更新:一种基于 Fluss 的全新方案 示例:构建一个统一的宽表 总结

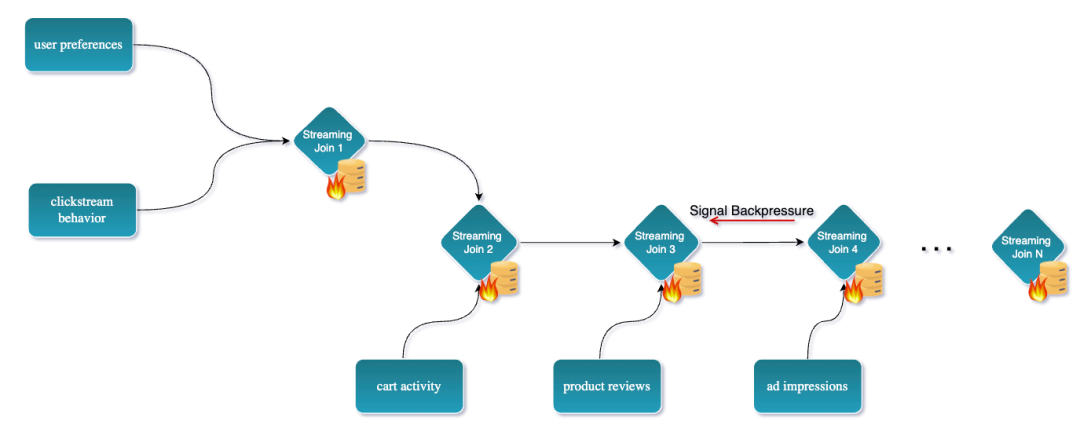
传统流式数据管道通常需要在主键上 Join 多个表或流,以创建一个宽表。例如,假设你正在为一个电子商务平台构建实时推荐引擎。为了提供高度个性化的推荐,你的系统需要拥有每个用户的完整 360° 视图,包括:用户偏好、过往购买记录、点击流行为、购物车活动、产品评价、客服工单、广告曝光以及会员忠诚度状态等信息。
这至少涉及8个不同的数据源,每个数据源都会独立地产生更新。
在大规模场景下 Join 多个数据流虽然可以通过 Apache Flink 实现,但实际上非常具有挑战性且消耗大量资源。更具体地说,可能会导致以下问题:
Flink 中的状态规模可能变得非常庞大:因为系统需要缓存所有传入的事件,直到它们可以被 Join。在很多情况下,这些状态需要长期保留,甚至无限期保留。
面临检查点(checkpoint)开销和反压(backpressure)问题:由于 Join 操作以及大规模状态的上传,可能会成为整个数据管道中的性能瓶颈。
状态难以查看和调试:因为它们通常既庞大又复杂。这使得理解管道中发生了什么、以及为什么某些事件没有被正确处理变得困难。
状态的 TTL(存活时间)可能导致结果不一致:因为事件可能在被 Join 之前就被丢弃了。这可能导致数据丢失,并最终输出错误的结果。
总体而言,这种方法不仅消耗大量的内存和 CPU 资源,还使作业的设计和维护变得更加复杂。
部分更新:一种基于 Fluss 的全新方案
Fluss 引入了一种更为优雅的解决方案:对主键表进行部分更新。
不同于在流处理作业中执行多路 Join,Fluss 允许每个数据流源根据主键独立地仅将其相关的列更新到一张共享的宽表中。在 Fluss 中,你可以定义一张宽表(例如,以 user_id
为主键的 user_profile
表),其中包含来自所有数据源的所有可能字段。然后,每个源数据流只需将它所知道的部分字段写入到这张表中。
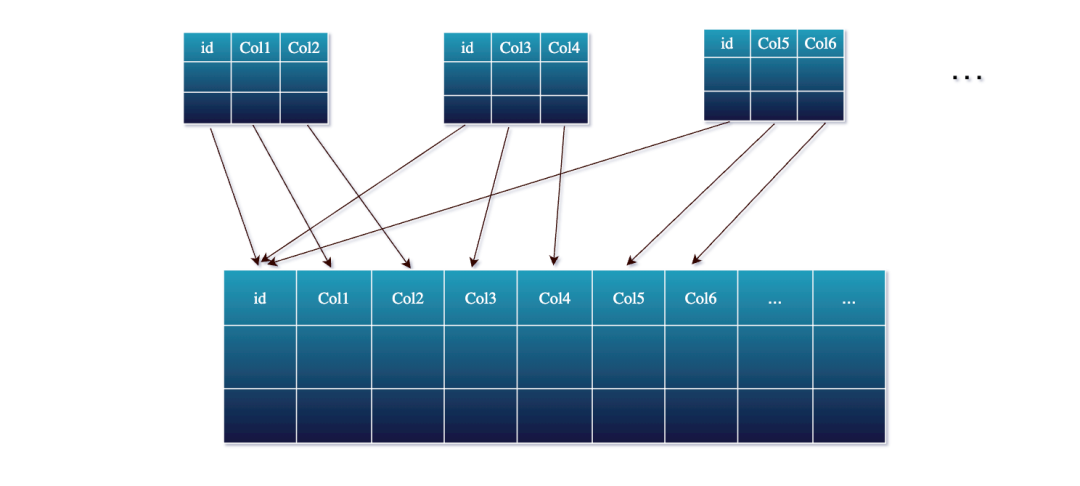
Fluss 的存储引擎会根据主键自动将这些部分更新合并在一起。本质上,Fluss 会为每个主键维护最新的完整数据,因此你无需再在 Flink 中管理庞大的 Join 状态。
在底层,当某个主键的部分更新到达时,Fluss 会查找该主键已有的记录,然后仅更新此次提供的特定列,其余列保持不变。合并后的结果会被作为该记录的新版本写回。这一切都是实时发生的,因此这张表始终都包含来自各个数据流的最新信息。
接下来,我们将通过一个具体的例子来更好地理解这一机制在实际中的工作方式。
示例:构建一个统一的宽表
你可以在 GitHub[1] 上找到完整的源代码。首先克隆仓库,然后运行 docker compose up
启动开发环境。最后,打开一个终端进入 jobmanager
,并运行以下命令启动 Flink SQL CLI:
./bin/sql-client.sh
到目前为止很棒!👍
第一步:我们需要做的第一件事是创建一个 Flink Catalog,用于存储我们将要创建的表。让我们创建一个名为 fluss_catalog
的 Catalog,并使用这个 Catalog。
CREATE CATALOG fluss_catalog WITH ('type' = 'fluss','bootstrap.servers' = 'coordinator-server:9123');USE CATALOG fluss_catalog;
第二步:接下来我们创建 3 张表,代表用于构建推荐宽表的不同数据源。
-- Recommendations – model scoresCREATE TABLE recommendations (user_id STRING,item_id STRING,rec_score DOUBLE,rec_ts TIMESTAMP(3),PRIMARY KEY (user_id, item_id) NOT ENFORCED) WITH ('bucket.num' = '3', 'table.datalake.enabled' = 'true');-- Impressions – how often we showed somethingCREATE TABLE impressions (user_id STRING,item_id STRING,imp_cnt INT,imp_ts TIMESTAMP(3),PRIMARY KEY (user_id, item_id) NOT ENFORCED) WITH ('bucket.num' = '3', 'table.datalake.enabled' = 'true');-- Clicks – user engagementCREATE TABLE clicks (user_id STRING,item_id STRING,click_cnt INT,clk_ts TIMESTAMP(3),PRIMARY KEY (user_id, item_id) NOT ENFORCED) WITH ('bucket.num' = '3', 'table.datalake.enabled' = 'true');CREATE TABLE user_rec_wide (user_id STRING,item_id STRING,rec_score DOUBLE, -- updated by recs streamimp_cnt INT, -- updated by impressions streamclick_cnt INT, -- updated by clicks streamPRIMARY KEY (user_id, item_id) NOT ENFORCED) WITH ('bucket.num' = '3', 'table.datalake.enabled' = 'true');
第三步:当然,我们需要一些示例数据来进行操作,因此让我们继续向表中插入一些记录吧。💻
-- Recommendations – model scoresINSERT INTO recommendations VALUES('user_101','prod_501',0.92 , TIMESTAMP '2025-05-16 09:15:02'),('user_101','prod_502',0.78 , TIMESTAMP '2025-05-16 09:15:05'),('user_102','prod_503',0.83 , TIMESTAMP '2025-05-16 09:16:00'),('user_103','prod_501',0.67 , TIMESTAMP '2025-05-16 09:16:20'),('user_104','prod_504',0.88 , TIMESTAMP '2025-05-16 09:16:45');
-- Impressions – how often each (user,item) was shownINSERT INTO impressions VALUES('user_101','prod_501', 3, TIMESTAMP '2025-05-16 09:17:10'),('user_101','prod_502', 1, TIMESTAMP '2025-05-16 09:17:15'),('user_102','prod_503', 7, TIMESTAMP '2025-05-16 09:18:22'),('user_103','prod_501', 4, TIMESTAMP '2025-05-16 09:18:30'),('user_104','prod_504', 2, TIMESTAMP '2025-05-16 09:18:55');
-- Clicks – user engagementINSERT INTO clicks VALUES('user_101','prod_501', 1, TIMESTAMP '2025-05-16 09:19:00'),('user_101','prod_502', 2, TIMESTAMP '2025-05-16 09:19:07'),('user_102','prod_503', 1, TIMESTAMP '2025-05-16 09:19:12'),('user_103','prod_501', 1, TIMESTAMP '2025-05-16 09:19:20'),('user_104','prod_504', 1, TIMESTAMP '2025-05-16 09:19:25');
注意:🚨 到目前为止我们运行的作业都是有界作业,因此它们在插入记录后就会完成。接下来我们将运行一些流式作业。请记住,每个作业都以并行度 3
运行,而我们的环境总共配置了 10 个 slot
。因此,请务必关注 Flink Web UI,查看已使用和可用的 slot 数量,并在不再需要时停止一些作业,以释放资源。
第四步:此时,让我们打开一个新的终端并启动 Flink SQL CLI。在这个新终端中,请确保设置以下输出模式:
SET 'sql-client.execution.result-mode' = 'tableau';
随后运行:
SELECT * FROM user_rec_wide;
以便在我们从不同数据源向表中插入部分记录时,能够观察到表的输出结果。
第五步:让我们将推荐表中的记录插入到 user_rec_wide
宽表中。
-- Apply recommendation scoresINSERT INTO user_rec_wide (user_id, item_id, rec_score)SELECTuser_id,item_id,rec_scoreFROM recommendations;
输出:请注意,在 user_rec_wide
表中,只有相关的列被更新,其余列则为 NULL。
Flink SQL> SELECT * FROM user_rec_wide;+----+--------------------------------+--------------------------------+--------------------------------+-------------+-------------+| op | user_id | item_id | rec_score | imp_cnt | click_cnt |+----+--------------------------------+--------------------------------+--------------------------------+-------------+-------------+| +I | user_101 | prod_501 | 0.92 | <NULL> | <NULL> || +I | user_101 | prod_502 | 0.78 | <NULL> | <NULL> || +I | user_104 | prod_504 | 0.88 | <NULL> | <NULL> || +I | user_102 | prod_503 | 0.83 | <NULL> | <NULL> || +I | user_103 | prod_501 | 0.67 | <NULL> | <NULL> |
第六步:接下来,让我们将 impressions
表中的记录插入到 user_rec_wide
宽表中。
-- Apply impression countsINSERT INTO user_rec_wide (user_id, item_id, imp_cnt)SELECTuser_id,item_id,imp_cntFROM impressions;
输出:请注意观察impressions
表的记录是如何插入到user_rec_wide
表中,并且 imp_cnt
列是如何更新的。
Flink SQL> SELECT * FROM user_rec_wide;+----+--------------------------------+--------------------------------+--------------------------------+-------------+-------------+| op | user_id | item_id | rec_score | imp_cnt | click_cnt |+----+--------------------------------+--------------------------------+--------------------------------+-------------+-------------+| +I | user_101 | prod_501 | 0.92 | <NULL> | <NULL> || +I | user_101 | prod_502 | 0.78 | <NULL> | <NULL> || +I | user_104 | prod_504 | 0.88 | <NULL> | <NULL> || +I | user_102 | prod_503 | 0.83 | <NULL> | <NULL> || +I | user_103 | prod_501 | 0.67 | <NULL> | <NULL> || -U | user_101 | prod_501 | 0.92 | <NULL> | <NULL> || +U | user_101 | prod_501 | 0.92 | 3 | <NULL> || -U | user_101 | prod_502 | 0.78 | <NULL> | <NULL> || +U | user_101 | prod_502 | 0.78 | 1 | <NULL> || -U | user_104 | prod_504 | 0.88 | <NULL> | <NULL> || +U | user_104 | prod_504 | 0.88 | 2 | <NULL> || -U | user_102 | prod_503 | 0.83 | <NULL> | <NULL> || +U | user_102 | prod_503 | 0.83 | 7 | <NULL> || -U | user_103 | prod_501 | 0.67 | <NULL> | <NULL> || +U | user_103 | prod_501 | 0.67 | 4 | <NULL> |
第七步:最后,让我们将 clicks
表中的记录插入到 user_rec_wide
宽表中。
-- Apply click countsINSERT INTO user_rec_wide (user_id, item_id, click_cnt)SELECTuser_id,item_id,click_cntFROM clicks;
输出:请注意观察clicks
表的记录是如何插入到 user_rec_wide
表中的,以及 click_cnt
列是如何更新的。
Flink SQL> SELECT * FROM user_rec_wide;+----+--------------------------------+--------------------------------+--------------------------------+-------------+-------------+| op | user_id | item_id | rec_score | imp_cnt | click_cnt |+----+--------------------------------+--------------------------------+--------------------------------+-------------+-------------+| +I | user_101 | prod_501 | 0.92 | <NULL> | <NULL> || +I | user_101 | prod_502 | 0.78 | <NULL> | <NULL> || +I | user_104 | prod_504 | 0.88 | <NULL> | <NULL> || +I | user_102 | prod_503 | 0.83 | <NULL> | <NULL> || +I | user_103 | prod_501 | 0.67 | <NULL> | <NULL> || -U | user_101 | prod_501 | 0.92 | <NULL> | <NULL> || +U | user_101 | prod_501 | 0.92 | 3 | <NULL> || -U | user_101 | prod_502 | 0.78 | <NULL> | <NULL> || +U | user_101 | prod_502 | 0.78 | 1 | <NULL> || -U | user_104 | prod_504 | 0.88 | <NULL> | <NULL> || +U | user_104 | prod_504 | 0.88 | 2 | <NULL> || -U | user_102 | prod_503 | 0.83 | <NULL> | <NULL> || +U | user_102 | prod_503 | 0.83 | 7 | <NULL> || -U | user_103 | prod_501 | 0.67 | <NULL> | <NULL> || +U | user_103 | prod_501 | 0.67 | 4 | <NULL> || -U | user_103 | prod_501 | 0.67 | 4 | <NULL> || +U | user_103 | prod_501 | 0.67 | 4 | 1 || -U | user_101 | prod_501 | 0.92 | 3 | <NULL> || +U | user_101 | prod_501 | 0.92 | 3 | 1 || -U | user_101 | prod_502 | 0.78 | 1 | <NULL> || +U | user_101 | prod_502 | 0.78 | 1 | 2 || -U | user_104 | prod_504 | 0.88 | 2 | <NULL> || +U | user_104 | prod_504 | 0.88 | 2 | 1 || -U | user_102 | prod_503 | 0.83 | 7 | <NULL> || +U | user_102 | prod_503 | 0.83 | 7 | 1 |
提醒:‼️ 如前所述,请务必停止不再需要的作业,以释放资源。现在,让我们切换到批处理模式,并查询 user_rec_wide
表的当前快照。但在那之前,我们需要启动分层服务(Tiering Service),该服务支持将表迁移为Lakehouse表。
第八步:在 Coordinator Server 中打开一个新终端 💻,并运行以下命令来启动分层服务:
./bin/lakehouse.sh -D flink.rest.address=jobmanager -D flink.rest.port=8081 -D flink.execution.checkpointing.interval=30s -D flink.parallelism.default=2
配置的检查点间隔为 flink.execution.checkpointing.interval=30s
,因此请稍等片刻,直到第一个检查点创建完成,并且数据将迁移至 Lakehouse 表中。
第九步:最后,让我们切换到批处理模式,并查询 user_rec_wide
表的当前快照。
SET 'execution.runtime-mode' = 'batch';Flink SQL> SELECT * FROM user_rec_wide;+----------+----------+-----------+---------+-----------+| user_id | item_id | rec_score | imp_cnt | click_cnt |+----------+----------+-----------+---------+-----------+| user_102 | prod_503 | 0.83 | 7 | 1 || user_103 | prod_501 | 0.67 | 4 | 1 || user_101 | prod_501 | 0.92 | 3 | 1 || user_101 | prod_502 | 0.78 | 1 | 2 || user_104 | prod_504 | 0.88 | 2 | 1 |+----------+----------+-----------+---------+-----------+5 rows in set (2.63 seconds)
🎉 就是这样!你已成功使用 Fluss 中的部分更新功能创建了一个统一的宽表。
总结
Fluss中的部分更新(Partial Updates)为流式数据打宽提供了替代性技术路径。
当所有数据源共享主键时(否则可灵活组合流式 Lookup Join[2]),你可以转变思路:以增量方式更新一张统一的宽表,而非实时 Join 流。
这种方式最终带来了更具可扩展性、更易维护且更高效的流水线。工程师们可以减少在 Flink 状态管理、Checkpoint 和 Join 机制上的投入时间,而将更多精力放在提供新鲜、整合的数据上,从而支持实时分析和应用。借助 Fluss 来处理合并逻辑,从多个差异化的数据流中获得一个统一且最新的数据视图变得更加优雅。😁
欢迎加入“Fluss 社区交流群”群的钉钉群号: 109135004351

[2] https://alibaba.github.io/fluss-docs/docs/engine-flink/lookups/#lookup



 点击「阅读原文」跳转阿里云实时计算 Flink~
点击「阅读原文」跳转阿里云实时计算 Flink~