





在大数据分析中,Doris 的 Catalog 联邦分析功能为整合多源数据提供了有力支持。然而,在实际应用中,可能会遇到各种问题影响其正常运行。本文将详细剖析这些问题并提供解决方案。

一、联邦分析查询慢:内外表通用排查逻辑
当遇到 Doris Catalog 联邦分析查询慢的问题时,无论操作的是内表还是外表,都可以遵循以下通用逻辑进行排查:
1. 统计信息准确性验证
核心作用:统计信息(如行数、列分布)是查询优化器生成执行计划的关键依据。若统计信息缺失或过时,可能导致优化器误判数据量,选择低效的执行路径(如全表扫描而非索引扫描)。
排查方法
通过
SHOW STATS
命令查看表的统计信息是否存在,以及更新时间是否合理。对于外表,需注意其统计信息默认关闭,需手动开启(参考 Doris 文档)。
2. 执行计划合理性分析
核心工具:使用
EXPLAIN VERBOSE + SQL
命令查看执行计划,重点关注以下部分:SCAN NODE
:是否触发全表扫描?是否命中索引?对于外表,是否应用了分区裁剪?JOIN
顺序与方法:优化器是否选择了合理的表连接顺序?是否使用了高效的连接算法(如哈希连接、嵌套循环连接)?典型问题
谓词条件未下推至外表,导致从源端读取大量冗余数据。 多表关联时连接条件错误,引发笛卡尔积,数据量爆炸式增长。
★注意: 目前JDBC 的下推能力是有限的,所以对于复杂SQL,可以考虑使用 SQL 透传功能 来直接把完整的 SQL 发到源端。
3. 并发度配置检查
核心参数:Doris 的并发度(如
parallel_fragment_exec_instance_num
)会影响查询并行处理能力。问题表现
并发度过低:无法充分利用集群资源,查询耗时延长。 并发度过高:可能导致资源竞争(如内存、网络带宽),反而降低性能。
二、外表查询慢:特有瓶颈与排查重点
外表查询(如 JDBC、Hive、Iceberg 等)因涉及跨网络数据交互和外部系统访问,存在特有的性能瓶颈,需从以下维度深入排查:
1. FE 端:元数据访问与查询规划
网络开销
FE 在解析查询时,需访问外部数据源的元数据(如 Hive 的分区信息、JDBC 的表结构),若网络延迟高或元数据量庞大(如百万级分区),会导致
Plan Time
显著增加。排查方法:单独执行
EXPLAIN SQL
,观察Plan Time
是否异常(正常情况下应在毫秒级,复杂元数据可能达秒级)。元数据缓存
若未开启元数据缓存(参考 Doris 元数据缓存文档),每次查询都需重新拉取元数据,导致重复开销。
★注意:数据缓存仅用于缓存parquet/orc/text 等文件格式。对于jdbc、jni 部分的数据,没有缓存效果。
2. BE 端:数据扫描与读取
FILE_SCAN
** 耗时分析**FileNumber
:扫描的文件数量,小文件过多(如数万级)会导致高 IOPS 和元数据开销。FileReadBytes
:实际读取的数据量,若远大于预期,可能是谓词条件未下推或分区裁剪失败。MergedSmallIO
:合并小 IO 的情况,若MergedBytes
远大于RequestBytes
,说明存在读放大,需调整合并策略(如merged_oss_min_io_size
参数)。通过
PROFILE
查看SCAN_OPERATOR
部分的ExecTime
,若该值占总查询时间的 70% 以上,说明瓶颈在数据扫描阶段。关键指标
文件格式与分片优化
分片数过多(如
InputSplitNum
达百万级)会导致 BE 节点任务调度开销增大,可通过调整变量file_split_size
(默认 64MB)合并分片。explain 的 verbose 方式会打印出具体文件分片。如: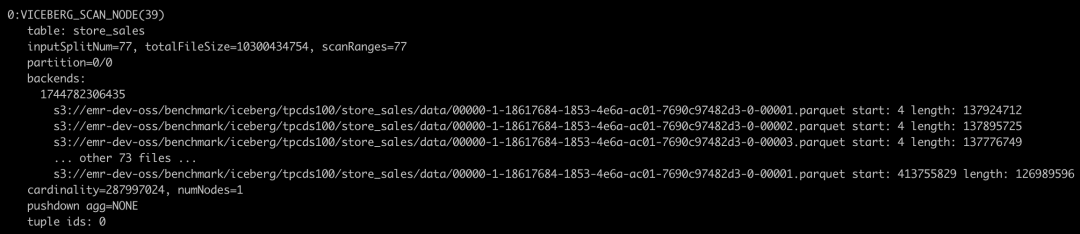
对于 Hive/Iceberg 表,若分区裁剪失败(如时间字段存储为字符串类型,导致隐式转换),需修正表结构或查询条件。
格式影响:Parquet/Orc 格式支持列式存储和谓词下推,性能优于 Text 格式;Text 格式需全量读取,仅适用于小数据量。(text比较吃磁盘IO 或网络带宽。也无法进行列式读取。一般text 格式不保证性能)
分片策略:
3. 网络与磁盘 IO 影响
网络延迟
BE 节点访问外部数据源(如 HDFS、对象存储)时,若使用公网 IP 或跨 VPC 访问,网络延迟可能高达数百毫秒,导致
FileReadTime
激增。排查方法:通过
ping
或curl
测试 BE 节点与数据源的网络连通性,确保延迟在可接受范围内(如 < 10ms)。磁盘性能
若数据存储在机械硬盘或高负载磁盘上, FileScannerOpenReaderTime
和ParseFooterTime
可能长达秒级,可通过更换 SSD 或优化磁盘队列提升性能。
三、典型外表类型的针对性优化
1. JDBC 外表:下推逻辑与连接优化
SQL 下推限制
JDBC 的谓词下推能力有限(如仅支持简单的 WHERE
条件),复杂逻辑(如ORDER BY
、LIMIT
)需手动通过 SQL 透传功能 推至源端执行(参考 Doris JDBC 透传文档)。内存问题定位
确保 BE 节点与源数据库的连接参数正确(如端口、用户名、密码),可以通过 jstack
或async-profiler
排查 JNI 调用或 JVM 内存问题(如连接泄漏)。
2. Hive/Iceberg 外表:分区与文件管理
分区裁剪优化
确保分区字段类型与查询条件一致(如日期字段存储为
DATE
而非STRING
),避免隐式转换导致裁剪失败。通过
EXPLAIN VERBOSE
确认Partition
部分是否显示有效裁剪,若未裁剪,需调整查询条件或表结构。小文件与 Delete 文件处理
Iceberg 表若存在大量
Equality Delete
或Position Delete
文件,需定期执行COMPACT
操作合并数据(参考 Iceberg 维护文档)。对于 Flink 写入的 Iceberg 表,建议开启自动合并策略,避免小文件堆积。
3. Paimon/Hudi 外表:Native Reader 与 JNI 优化
优先使用 Native Reader
Paimon/Hudi 的 Native Reader
(C++ 实现)性能优于JNI Reader
,通过EXPLAIN
查看scan node
是否包含paimonNativeReadSplits
,若JNI Reader
占比过高,需引导用户对表进行COMPACTION
,减少增量数据。JVM 性能调优
若 JNI Reader
内存占用过高,可通过调整 BE 的 JVM 参数(如be.conf
中的java_opts
)或使用jstat
监控 GC 情况,避免频繁 Full GC 影响性能。
四、实战优化步骤与工具链
1. 快速定位瓶颈的 3 步流程
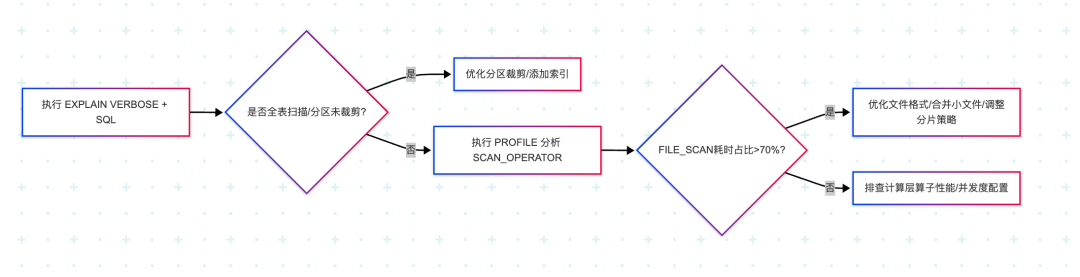
2. 关键工具与命令
执行计划分析:
EXPLAIN VERBOSE + SQL
,重点关注SCAN NODE
和JOIN
节点。性能 profiling:通过
PROFILE
来分析Plan Time
、Scan Time
、Compute Time
等指标。Java 诊断工具:
jstack
(线程栈分析)、jstat
(JVM 内存监控)、async-profiler
(火焰图生成),用于排查 JNI 或 JVM 相关性能问题。系统表查询:通过
information_schema.file_cache_statistics
查看数据缓存命中率,system.runtime.metrics
监控集群资源使用情况。
五、优化方案总结
1. 数据层优化
文件格式:优先使用 Parquet/Orc,避免 Text 格式;对 Iceberg/Paimon/Hudi 表定期执行
COMPACTION
合并小文件。分区策略:基于时间、地域等高频查询维度创建分区,确保分区字段类型与查询条件匹配。
统计信息:开启外表统计信息收集(
SET enable_external_table_stats_collect = true
),定期更新统计信息(ANALYZE TABLE
)。
2. 查询层优化
下推逻辑:对 JDBC 外表使用 SQL 透传,将复杂逻辑推至源端;对 Hive/Iceberg 外表确保谓词下推和分区裁剪生效。
并发度调整:根据集群资源设置合理并发度(如
SET parallel_fragment_exec_instance_num = 16
),避免资源竞争。
3. 基础设施优化
网络连通性:确保 FE/BE 节点与外部数据源在同一 VPC 内,关闭不必要的防火墙规则,降低网络延迟。
硬件升级:将机械硬盘替换为 SSD,提升磁盘 IO 性能;为高负载节点增加内存或 CPU 资源。
缓存配置:开启元数据缓存(
metastore_cache.ttl
)和数据缓存(enable_file_cache = true
),减少重复访问开销。
六、总结
Doris Catalog 联邦分析的查询性能优化是一个系统性工程,需结合执行计划分析、外表特性、基础设施等多维度排查。通过本文提供的通用逻辑和针对性方案,可快速定位瓶颈并实施优化,充分发挥 Doris 在多源数据联邦分析中的性能优势。实际操作中建议先从小规模数据测试优化效果,再逐步应用于生产环境,确保稳定性与效率的平衡。

往期推荐
完
Apache Doris社区是目前国内最活跃的开源社区(之一)。Apache Doris(Apache 顶级项目) 聚集了世界全国各地的用户与开发人员,致力于打造一个内容完整、持续成长的互联网开发者学习生态圈!
如果您对Apache Doris感兴趣,可以通过以下入口访问官方网站、社区论坛、GitHub和dev邮件组:
PowerData是由一群数据从业人员,因为热爱凝聚在一起,以开源精神为基础,组成的数据开源社区。
社区群内会定期组织模拟面试、线上分享、行业研讨、线下Meetup、城市聚会、求职内推等活动,同时在社区群内你可以进行技术讨论、问题请教,结识更多志同道合的数据朋友。
社区整理了一份每日一题汇总及社区分享PPT,内容涵盖大数据组件、编程语言、数据结构与算法、企业真实面试题等各个领域,帮助您提升自我,成功上岸。
可以加作者微信(Faith_xzc)直接进PowrData官方社区群
叮咚✨ “数据极客圈” 向你敞开大门,走对圈子跟对人,行业大咖 “唠” 数据,实用锦囊天天有,就缺你咯!快快关注数据极客圈,共同成长!

点击上方公众号关注我们
