




第一章 SQL查询
第一节 流程编排
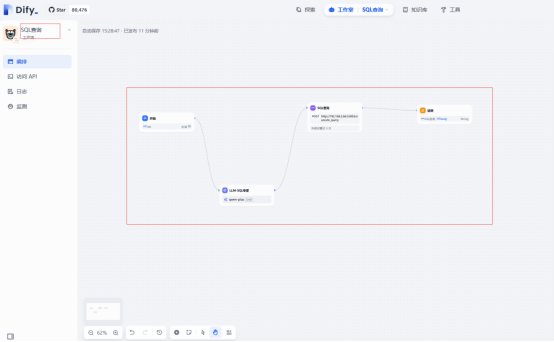
1.1 步骤
- 开始:用户输入分析需求
- LLM-SQL 专家:大模型根据用户输入需求生成 SQL 查询
- SQL查询:执行查询并获取数据
- 结束:输出查询结果集
1.2 工作流
第二节 组件配置
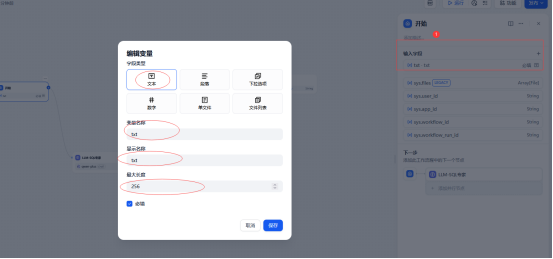
2.1 开始
新建一个开始组件,并增加一个输入参数,用于用户输入自然语言
2.2 LLM-SQL 专家
增加一个LLM模型组件,命名为LLM-SQL 专家
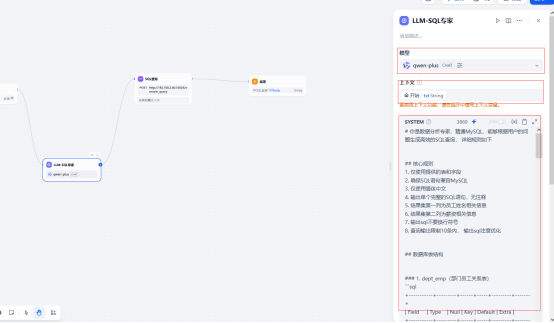
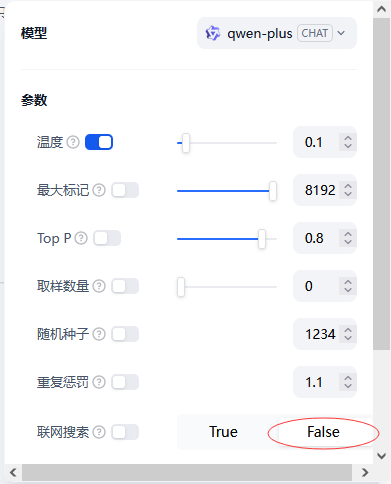
2.2.1 模型
选择自己已经部署的模型,设置不联网
2.2.2 上下文
输入/ 出现变量,选择跟开始组件中对应的变量名即可
2.2.3 System
你是数据分析专家,精通MySQL,能够根据用户的问题生成高效的SQL查询, 详细规则如下
核心规则
仅使用提供的表和字段
确保SQL语句兼容MySQL
仅使用简体中文
输出单个完整的SQL语句,无注释
结果集第一列为员工姓名相关信息
结果集第二列为薪资相关信息
输出sql不要换行符号
查询输出限制10条内, 输出sql注意优化
数据库表结构
dept_emp(部门员工关系表)
+-----------+---------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+-----------+---------+------+-----+---------+-------+
| emp_no | int | NO | PRI | NULL | |
| dept_no | char(4) | NO | PRI | NULL | |
| from_date | date | NO | | NULL | |
| to_date | date | NO | | NULL | |
+-----------+---------+------+-----+---------+-------+
departments(部门表)
+-----------+-------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+-----------+-------------+------+-----+---------+-------+
| dept_no | char(4) | NO | PRI | NULL | |
| dept_name | varchar(40) | NO | UNI | NULL | |
+-----------+-------------+------+-----+---------+-------+
employees(员工表)
+------------+---------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+------------+---------------+------+-----+---------+-------+
| emp_no | int | NO | PRI | NULL | |
| birth_date | date | NO | | NULL | |
| first_name | varchar(14) | NO | | NULL | |
| last_name | varchar(16) | NO | | NULL | |
| gender | enum('M','F') | NO | | NULL | |
| hire_date | date | NO | | NULL | |
+------------+---------------+------+-----+---------+-------+
salaries(薪资表)
+-----------+------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+-----------+------+------+-----+---------+-------+
| emp_no | int | NO | PRI | NULL | |
| salary | int | NO | | NULL | |
| from_date | date | NO | PRI | NULL | |
| to_date | date | NO | | NULL | |
+-----------+------+------+-----+---------+-------+
titles(职位表)
+-----------+-------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+-----------+-------------+------+-----+---------+-------+
| emp_no | int | NO | PRI | NULL | |
| title | varchar(50) | NO | PRI | NULL | |
| from_date | date | NO | PRI | NULL | |
| to_date | date | YES | | NULL | |
+-----------+-------------+------+-----+---------+-------+
查询技巧
1.日期处理
-- 当前在职员工
WHERE to_date = '9999-01-01'
-- 日期范围查询
WHERE from_date BETWEEN '2000-01-01' AND '2000-12-31'
2.名字处理
-- 连接姓名
CONCAT(first_name, ' ', last_name) AS full_name
-- 模糊查询
WHERE first_name LIKE '%John%'
3.聚合函数
COUNT(): 计算数量
AVG(): 计算平均值
SUM(): 计算总和
MAX()/MIN(): 获取最大/最小值
4.常用JOIN
-- 员工部门信息
FROM employees e
JOIN dept_emp de ON e.emp_no = de.emp_no
JOIN departments d ON de.dept_no = d.dept_no
-- 当前薪资信息
JOIN salaries s ON e.emp_no = s.emp_no
WHERE s.to_date = '9999-01-01'
查询示例
1.查询员工当前薪资
SELECT
CONCAT(e.first_name, ' ', e.last_name) as name,
s.salary
FROM employees e
JOIN salaries s ON e.emp_no = s.emp_no
WHERE s.to_date = '9999-01-01';
2.查询部门经理信息
SELECT
CONCAT(e.first_name, ' ', e.last_name) as name,
s.salary,
d.dept_name
FROM employees e
JOIN dept_manager dm ON e.emp_no = dm.emp_no
JOIN departments d ON dm.dept_no = d.dept_no
JOIN salaries s ON e.emp_no = s.emp_no
WHERE dm.to_date = '9999-01-01'
AND s.to_date = '9999-01-01';
注意事项
查询当前状态需检查to_date
使用适当的索引以提高查询效率
合理使用JOIN条件
注意日期格式的一致性
使用合适的聚合函数2.2.4 User
请将此 开始/(x)txt 翻译成一段SQL语句,不要注释注意此红色即为开始中的输入参数,要当做用户参数传给大模型
2.2.5 输出变量
默认 text string即可
2.3 SQL查询
2.3.1 环境准备
在本地mysql新建数据库employees ,执行脚本 employees.sql新建表和数据
在python中写一段脚本
-- coding: UTF-8 --
from fastapi import FastAPI, HTTPException, Header
from pydantic import BaseModel
from typing import List, Dict, Any, Optional, Union
import pymysql
import uvicorn
from contextlib import contextmanager
import json
app = FastAPI()
class SQLQuery(BaseModel):
sql_query: str
@contextmanager
def get_db_connection(config):
"""数据库连接的上下文管理器"""
conn = None
try:
conn = pymysql.connect(**config)
yield conn
finally:
if conn:
conn.close()
@app.post("/execute_query")
async def execute_query(
query: SQLQuery,
api_key: Optional[str] = Header(None, alias="X-API-Key")
):
"""处理POST请求以执行SQL查询。"""
try:
sql_queries = query.sql_query.strip()
if not sql_queries:
raise HTTPException(status_code=400, detail="Missing sql_query parameter")
with get_db_connection(app.db_config) as conn:
results = []
with conn.cursor(pymysql.cursors.DictCursor) as cursor:
for sql_query in sql_queries.split(';'):
if sql_query.strip():
cursor.execute(sql_query)
result = cursor.fetchall()
if result:
results.extend(result)
conn.commit()
return results
except pymysql.Error as e:
raise HTTPException(status_code=500, detail=f"数据库错误: {str(e)}")
except Exception as e:
raise HTTPException(status_code=500, detail=f"服务器错误: {str(e)}")
def verify_api_key(api_key: Optional[str]) -> bool:
"""验证API密钥"""
return api_key == app.api_key
if name == 'main':
# 数据库配置
app.db_config = {
"host": "127.0.0.1",
"user": "root",
"password": "123456",
"database": "employees",
"port": 3306,
"charset": 'utf8mb4'
}
# 添加API密钥配置
app.api_key = "oWoh*thae5" # 建议使用环境变量存储此密钥
uvicorn.run(app, host='0.0.0.0', port=35003)修改红色部分的数据库账号和密码,执行此程序,则构建了一个fastapi接口
可以在postman中调用
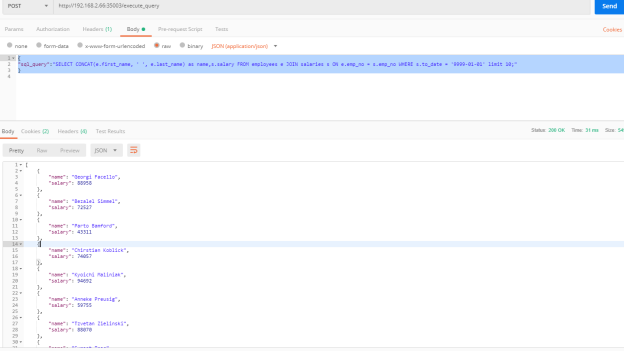
http://192.168.2.66:35003/execute_query
{
"sql_query":"SELECT CONCAT(e.first_name, ' ', e.last_name) as name,s.salary FROM employees e JOIN salaries s ON e.emp_no = s.emp_no WHERE s.to_date = '9999-01-01' limit 10;"
}测试结果如下:
2.3.2 配置组件
主要配置这两个地方:
API选择post,填入自己的地址
http://192.168.2.66:35003/execute_queryBody选择json,内容构造测试的结构
{
"sql_query":"LLM-SQL 专家/(x)text"
}红色部分即为上一个组件输出的值
2.3.3 输出变量
默认即可
2.4 结束
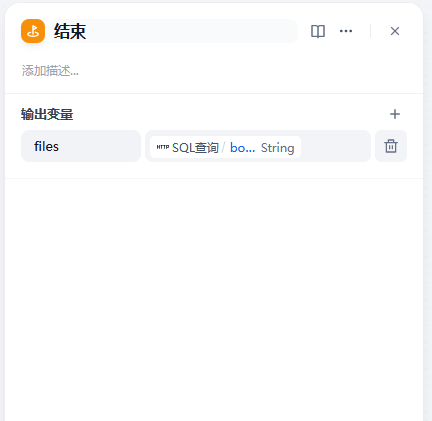
2.4.1 输出变量
files:SQL查询.body第三节 执行工作流
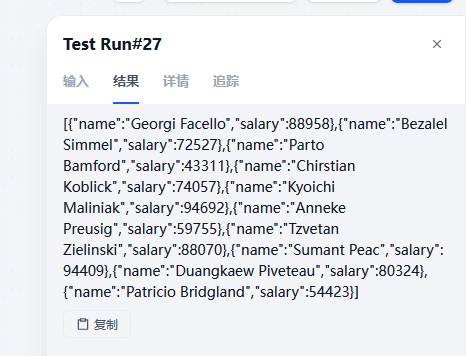
3.1 查询员工当前薪资
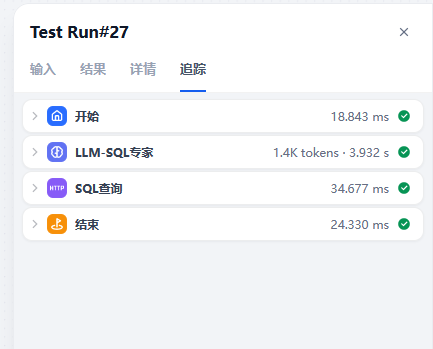
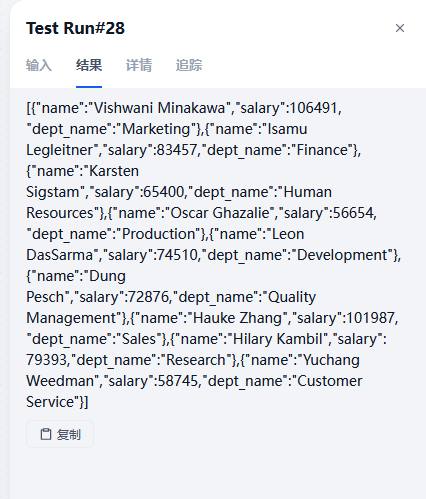
3.2 查询部门经理信息
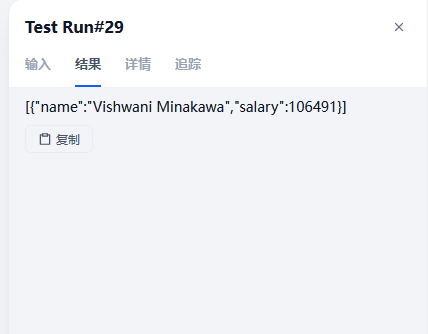
3.3 查询部门经理名叫 Vishwani的薪资
「喜欢这篇文章,您的关注和赞赏是给作者最好的鼓励」
关注作者
【版权声明】本文为墨天轮用户原创内容,转载时必须标注文章的来源(墨天轮),文章链接,文章作者等基本信息,否则作者和墨天轮有权追究责任。如果您发现墨天轮中有涉嫌抄袭或者侵权的内容,欢迎发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
