




1.LetNet5简介
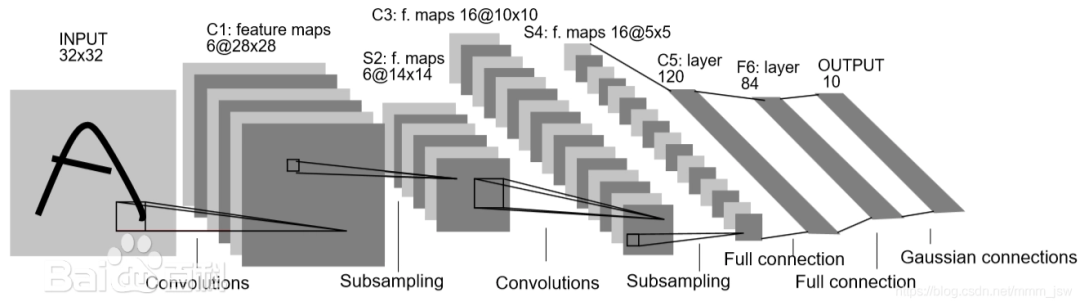
LeNet5是由Yann LeCun等人在1998年提出的一种卷积神经网络架构,主要用于手写数字识别。它是早期卷积神经网络的成功应用之一,为现代深度学习模型奠定了基础。LeNet5的名字来源于其发明者LeCun和网络层数(5层)。
LeNet5的主要特点包括:
使用卷积层提取空间特征 使用子采样层(池化层)降低特征维度 使用全连接层进行分类 采用梯度下降法进行训练
虽然LeNet5最初是为识别手写数字设计的,但我们可以将其应用于更广泛的图像分类任务,如FashionMNIST数据集。
2. LeNet5网络结构原理
LeNet5的网络结构可以分为7层(包含输入层),但通常我们说有5层可训练层(2个卷积层和3个全连接层)。让我们详细分析每一层的结构:
2.1 输入层
原始LeNet5的输入是32×32的灰度图像。在我们的实现中,为了适应FashionMNIST数据集,我们将其调整为28×28。
2.2 C1层 - 第一卷积层
卷积核大小: 5×5 卷积核数量: 6 步长: 1 填充: 2 (为了保持输出尺寸与输入相同) 激活函数: Sigmoid
神经元数量计算:
输入尺寸:28×28
输出尺寸:(28 + 2 * 2 - 5)/1 + 1 = 28×28
每个特征图有28×28=784个神经元
共有6个特征图,所以总神经元数=6×784=4704
2.3 S2层 - 第一池化层
池化类型: 平均池化 池化大小: 2×2 步长: 2
神经元数量计算:
输入尺寸:28×28
输出尺寸:(28 - 2)/2 + 1 = 14×14
每个特征图有14×14=196个神经元
共有6个特征图,所以总神经元数=6×196=1176
2.4 C3层 - 第二卷积层
卷积核大小: 5×5 卷积核数量: 16 步长: 1 填充: 0 激活函数: Sigmoid
神经元数量计算:
输入尺寸:14×14
输出尺寸:(14 - 5)/1 + 1 = 10×10
每个特征图有10×10=100个神经元
共有16个特征图,所以总神经元数=16×100=1600
2.5 S4层 - 第二池化层
池化类型: 平均池化 池化大小: 2×2 步长: 2
神经元数量计算:
输入尺寸:10×10
输出尺寸:(10 - 2)/2 + 1 = 5×5
每个特征图有5×5=25个神经元
共有16个特征图,所以总神经元数=16×25=400
2.6 C5层 - 第一全连接层
输入: 16×5×5=400 输出: 120 激活函数: Sigmoid
神经元数量: 120
2.7 F6层 - 第二全连接层
输入: 120 输出: 84 激活函数: Sigmoid
神经元数量: 84
2.8 输出层
输入: 84 输出: 10 (对应10个类别) 激活函数: Softmax
神经元数量: 10
3. PyTorch实现详解
现在让我们详细分析LeNet5的PyTorch实现代码,包含每一行的解释。
3.1 模型定义 (main.py)
import torchimport torch.nn as nnfrom torchsummary import summaryclass LeNet5(nn.Module):def __init__(self, num_classes=10):super(LeNet5, self).__init__()# 第一卷积层: 输入通道1(灰度图), 输出通道6, 5x5卷积核, padding=2保持尺寸self.conv1 = nn.Conv2d(in_channels=1, out_channels=6, kernel_size=5, stride=1, padding=2)self.sig = nn.Sigmoid() # Sigmoid激活函数self.pool = nn.AvgPool2d(kernel_size=2, stride=2) # 平均池化层# 第二卷积层: 输入通道6, 输出通道16, 5x5卷积核, 无paddingself.conv2 = nn.Conv2d(in_channels=6, out_channels=16, kernel_size=5, stride=1, padding=0)self.pool2 = nn.AvgPool2d(kernel_size=2, stride=2) # 第二个平均池化层self.flatten = nn.Flatten() # 展平层,将多维输入一维化# 第一个全连接层: 输入16 * 5 * 5=400, 输出120self.f5 = nn.Linear(16 * 5 * 5, 120)# 第二个全连接层: 输入120, 输出84self.f6 = nn.Linear(120, 84)# 输出层: 输入84, 输出类别数self.f7 = nn.Linear(84, num_classes)self.softmax = nn.Softmax(dim=1) # Softmax激活函数def forward(self, x):# 第一卷积块x = self.conv1(x) # 卷积x = self.sig(x) # 激活x = self.pool(x) # 池化# 第二卷积块x = self.conv2(x) # 卷积x = self.sig(x) # 激活x = self.pool2(x) # 池化# 全连接部分x = self.flatten(x) # 展平x = self.f5(x) # 全连接x = self.sig(x) # 激活x = self.f6(x) # 全连接x = self.sig(x) # 激活x = self.f7(x) # 输出层# 注意: 训练时通常不在这里使用softmax,因为CrossEntropyLoss已经包含了softmaxreturn xif __name__ == "__main__":device = torch.device("cuda" if torch.cuda.is_available() else "cpu")model = LeNet5(num_classes=10).to(device)summary(model, (1, 28, 28)) # 打印模型结构摘要
3.2 训练脚本 (train.py)
import osimport syssys.path.append(os.getcwd()) # 添加当前目录到系统路径,以便导入自定义模块import timefrom torchvision.datasets import FashionMNIST # 导入FashionMNIST数据集from torchvision import transforms # 图像预处理from torch.utils.data import DataLoader, random_split # 数据加载和划分import numpy as npimport matplotlib.pyplot as plt # 绘图import torchfrom torch import nn, optim # 神经网络和优化器import copy # 用于模型参数深拷贝import pandas as pd # 数据处理from LetNet5_model.main import LeNet5 # 导入我们的LeNet5模型def train_val_date_load():# 加载FashionMNIST训练集train_dataset = FashionMNIST(root="./data", # 数据存储路径train=True, # 加载训练集download=True, # 自动下载transform=transforms.Compose([transforms.Resize(size=28), # 调整大小到28x28transforms.ToTensor(), # 转为Tensor并归一化到[0,1]]),)# 按8:2划分训练集和验证集train_date, val_data = random_split(train_dataset,[int(len(train_dataset) * 0.8), # 80%训练len(train_dataset) - int(len(train_dataset) * 0.8), # 20%验证],)# 创建数据加载器train_loader = DataLoader(dataset=train_date, batch_size=128, shuffle=True, num_workers=1)val_loader = DataLoader(dataset=val_data, batch_size=128, shuffle=True, num_workers=1)return train_loader, val_loaderdef train_model_process(model, train_loader, val_loader, epochs=10):device = "cuda" if torch.cuda.is_available() else "cpu"optimizer = optim.Adam(model.parameters(), lr=0.001) # Adam优化器criterion = nn.CrossEntropyLoss() # 交叉熵损失model.to(device) # 模型移到设备# 初始化变量记录最佳模型和训练过程best_model_wts = copy.deepcopy(model.state_dict())best_acc = 0.0train_loss_all = []val_loss_all = []train_acc_all = []val_acc_all = []since = time.time() # 计时开始for epoch in range(epochs):print(f"Epoch {epoch + 1}/{epochs}")# 初始化统计变量train_loss = 0.0train_correct = 0val_loss = 0.0val_correct = 0train_num = 0val_num = 0# 训练阶段for step, (images, labels) in enumerate(train_loader):images, labels = images.to(device), labels.to(device)model.train() # 训练模式outputs = model(images)pre_lab = torch.argmax(outputs, dim=1) # 预测标签loss = criterion(outputs, labels) # 计算损失optimizer.zero_grad() # 梯度清零loss.backward() # 反向传播optimizer.step() # 参数更新# 统计信息train_loss += loss.item() * images.size(0)train_correct += torch.sum(pre_lab == labels.data)train_num += labels.size(0)# 验证阶段for step, (images, labels) in enumerate(val_loader):images, labels = images.to(device), labels.to(device)model.eval() # 评估模式with torch.no_grad(): # 不计算梯度outputs = model(images)pre_lab = torch.argmax(outputs, dim=1)loss = criterion(outputs, labels)val_loss += loss.item() * images.size(0)val_correct += torch.sum(pre_lab == labels.data)val_num += labels.size(0)# 记录本轮结果train_loss_all.append(train_loss train_num)val_loss_all.append(val_loss / val_num)train_acc = train_correct.double() / train_numval_acc = val_correct.double() / val_numtrain_acc_all.append(train_acc.item())val_acc_all.append(val_acc.item())print(f"Train Loss: {train_loss / train_num:.4f}, Train Acc: {train_acc:.4f}, "f"Val Loss: {val_loss / val_num:.4f}, Val Acc: {val_acc:.4f}")# 更新最佳模型if val_acc_all[-1] > best_acc:best_acc = val_acc_all[-1]best_model_wts = copy.deepcopy(model.state_dict())# 训练结束time_elapsed = time.time() - sinceprint(f"Training complete in {time_elapsed // 60:.0f}m {time_elapsed % 60:.0f}s\n"f"Best val Acc: {best_acc:.4f}")# 保存模型和训练过程torch.save(model.state_dict(), "./models/le_net5_best_model.pth")train_process = pd.DataFrame({"epoch": range(1, epochs + 1),"train_loss_all": train_loss_all,"val_loss_all": val_loss_all,"train_acc_all": train_acc_all,"val_acc_all": val_acc_all,})return train_processdef matplot_acc_loss(train_process):# 绘制训练曲线plt.figure(figsize=(12, 5))# 损失曲线plt.subplot(1, 2, 1)plt.plot(train_process["epoch"], train_process["train_loss_all"], label="Train Loss")plt.plot(train_process["epoch"], train_process["val_loss_all"], label="Val Loss")plt.xlabel("Epoch")plt.ylabel("Loss")plt.title("Loss vs Epoch")plt.legend()# 准确率曲线plt.subplot(1, 2, 2)plt.plot(train_process["epoch"], train_process["train_acc_all"], label="Train Acc")plt.plot(train_process["epoch"], train_process["val_acc_all"], label="Val Acc")plt.xlabel("Epoch")plt.ylabel("Accuracy")plt.title("Accuracy vs Epoch")plt.legend()plt.tight_layout()plt.ion()plt.show()plt.savefig("./models/le_net5_output.png")if __name__ == "__main__":traindatam, valdata = train_val_date_load() # 加载数据result = train_model_process(LeNet5(), traindatam, valdata, 10) # 训练模型matplot_acc_loss(result) # 绘制曲线
3.3 测试脚本 (test.py)
import osimport syssys.path.append(os.getcwd()) # 添加当前目录到系统路径import torchfrom torch.utils.data import DataLoaderfrom torchvision import transformsfrom torchvision.datasets import FashionMNISTfrom LetNet5_model.main import LeNet5def test_data_load():# 加载测试集test_dataset = FashionMNIST(root="./data",train=False, # 测试集download=True,transform=transforms.Compose([transforms.Resize(size=28),transforms.ToTensor(),]),)# 创建测试数据加载器test_loader = DataLoader(dataset=test_dataset, batch_size=128, shuffle=True, num_workers=1)return test_loaderdef test_model_process(model, test_loader):device = "cuda" if torch.cuda.is_available() else "cpu"model.to(device)model.eval() # 评估模式correct = 0total = 0with torch.no_grad(): # 不计算梯度for images, labels in test_loader:images, labels = images.to(device), labels.to(device)outputs = model(images)_, predicted = torch.max(outputs, 1) # 获取预测类别total += labels.size(0)correct += torch.sum(predicted == labels.data) # 统计正确数accuracy = correct / total * 100print(f"Test Accuracy: {accuracy:.2f}%") # 打印测试准确率if __name__ == "__main__":test_loader = test_data_load() # 加载测试数据model = LeNet5() # 实例化模型model.load_state_dict(torch.load("./models/le_net5_best_model.pth")) # 加载训练好的权重test_model_process(model, test_loader) # 测试模型
4. 训练与结果分析
4.1 训练过程
训练过程展示了模型在训练集和验证集上的损失和准确率变化。典型的训练过程会显示以下特征:
损失曲线:
训练损失应随着epoch增加而持续下降 验证损失初期下降,后期可能趋于平稳或略有上升(过拟合) 准确率曲线:
训练准确率应持续上升 验证准确率初期上升,后期趋于平稳
4.2 超参数选择
在我们的实现中使用了以下关键超参数:
学习率: 0.001 (Adam优化器的默认学习率) 批量大小: 128 训练周期: 10 优化器: Adam
这些参数可以根据具体任务进行调整以获得更好的性能。
4.3 模型性能
在FashionMNIST测试集上,LeNet5通常能达到85%-90%的准确率。虽然不如现代深度学习模型,但对于教学和理解CNN基本原理已经足够。
5. 总结与扩展
LeNet5虽然是一个简单的CNN模型,但它包含了现代深度学习模型的许多核心概念:
- 局部感受野
: 通过卷积核实现 - 权值共享
: 同一卷积核在整个图像上滑动 - 空间子采样
: 通过池化层实现 - 多层感知机
: 最后的全连接层
扩展改进建议:
使用ReLU代替Sigmoid作为激活函数 使用最大池化代替平均池化 添加Batch Normalization层 增加数据增强技术 尝试不同的学习率调度策略
通过这些改进,可以显著提高模型在FashionMNIST上的性能。
LeNet5作为卷积神经网络的鼻祖,其设计思想和实现方式至今仍在影响着深度学习领域。通过实现和理解LeNet5,我们可以更好地掌握现代深度学习模型的基础。
