




摘要:最近,数据圈被一条炸裂新闻刷屏了!
不是谁又融资、谁又IPO,而是:一直被当作轻量级分析数据库的DuckDB,突然“上头了”。
它搞了个大动作:推出了自己的表格式DuckLake,直接对现有主流湖仓方案发起挑战。

消息一出,整个圈子沸腾了:
有人拍手叫好,说这是未来的方向;
有人看热闹,觉得不过是小打小闹;
也有人泼冷水:“你一个本地SQL引擎,也想革数据湖仓的命?”
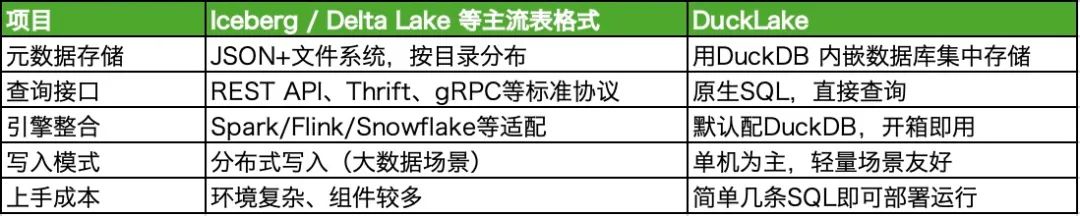
Iceberg和Delta Lake:能用,但也妥协了很多
过去,数据湖改数据太难了!想“修改一下”数据,对不起,只能靠自研脚本,容错难、事务性差、回滚也难搞。
为了解决数据湖的“可修改”问题,Apache Iceberg和Delta Lake等开源标准相继出现。它们让数据湖不再只能“只读”,而是真正具备了数据库的一些能力,比如版本管理、结构变更、事务提交等等。
Iceberg为了保住“无数据库”的纯粹性,不得不搞一堆JSON/Avro文件来描述表结构、快照、元数据等;
每次更新都要生成一个完整的全新快照文件;
要保证一致性还得加一层 Catalog 服务,用数据库去维护这些文件“当前该用哪一个版本”。
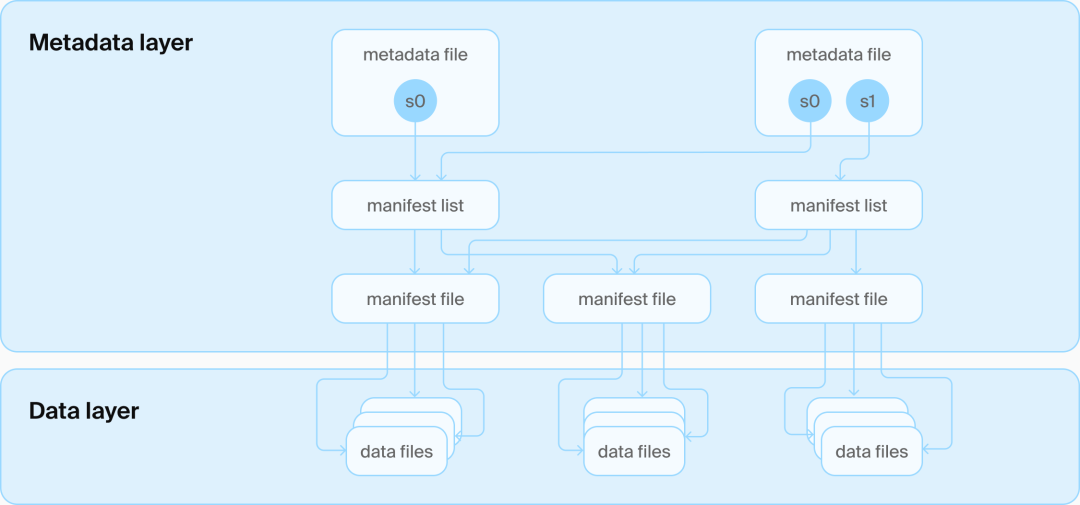
Iceberg表架构
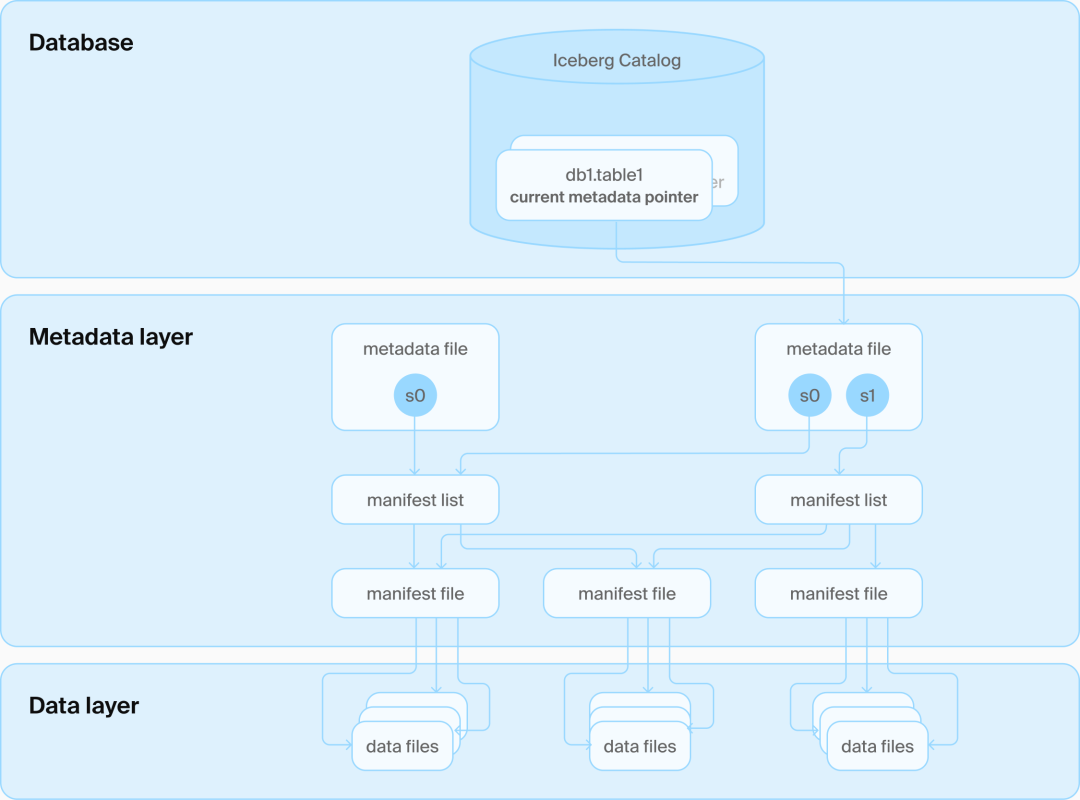
Iceberg目录架构
你没看错,为了不依赖数据库,Iceberg最后还是引入了数据库…
可惜,它们并没有回过头来重新审视整个技术架构,还是坚持用“文件堆叠”做核心逻辑。这导致很多小修改、并发事务的处理依旧繁琐低效。
这也让人不禁想问一句:为啥不直接用数据库来管理元数据呢?
湖仓大战的格局,还没定,就被打断了?
过去几年,湖仓圈的焦点一直在Iceberg、Delta Lake等“开源表格式”之间的卡位战。
2023年,Databricks豪掷10亿美元收购Tabular,把Iceberg两位创始人(Netflix出身的Ryan Blue和Dan Weeks)招入麾下。
当时很多人预测:Iceberg+Delta Lake,很可能会慢慢走向融合统一。
但还没等这盘棋下完,DuckDB突然冲出来,自己立了块牌子:
不光推出自己的开源表格式 DuckLake
还一口气把“对象存储支持、表格式元数据管理、分析引擎集成”三件事全做了!
更炸裂的是,它不搞JSON、不搞REST协议,不走Iceberg那套“表格式 + 文件系统”的组合拳,而是:
直接用数据库来存元数据、查数据、管元数据,全部打通。
换句话说,它不再像过去那样只是一个“本地SQL引擎”,而是试图搞出一个“能存、能算、能管”的 一体化迷你湖仓系统。
这波操作,有点像别人还在研究怎么造一个更智能的遥控器,它直接就说:“手机直接当遥控器不就完了?”
DuckLake到底做了什么?和Iceberg有什么不同?
从DuckDB官方文章看,其架构路线和Iceberg们完全不同,DuckLake的理念很简单:数据照样存Parquet,元数据全交给标准SQL数据库管理,不再折腾一堆文件夹和格式。
DuckDB团队的思路很直接:
既然Iceberg和Delta最后还是绕不过数据库这条路,为什么不一开始就用数据库来做元数据管理?
我们不否认数据文件该放在开放格式、对象存储里,但管理元数据这种事,就应该交给数据库来干。
于是就有了——DuckLake。
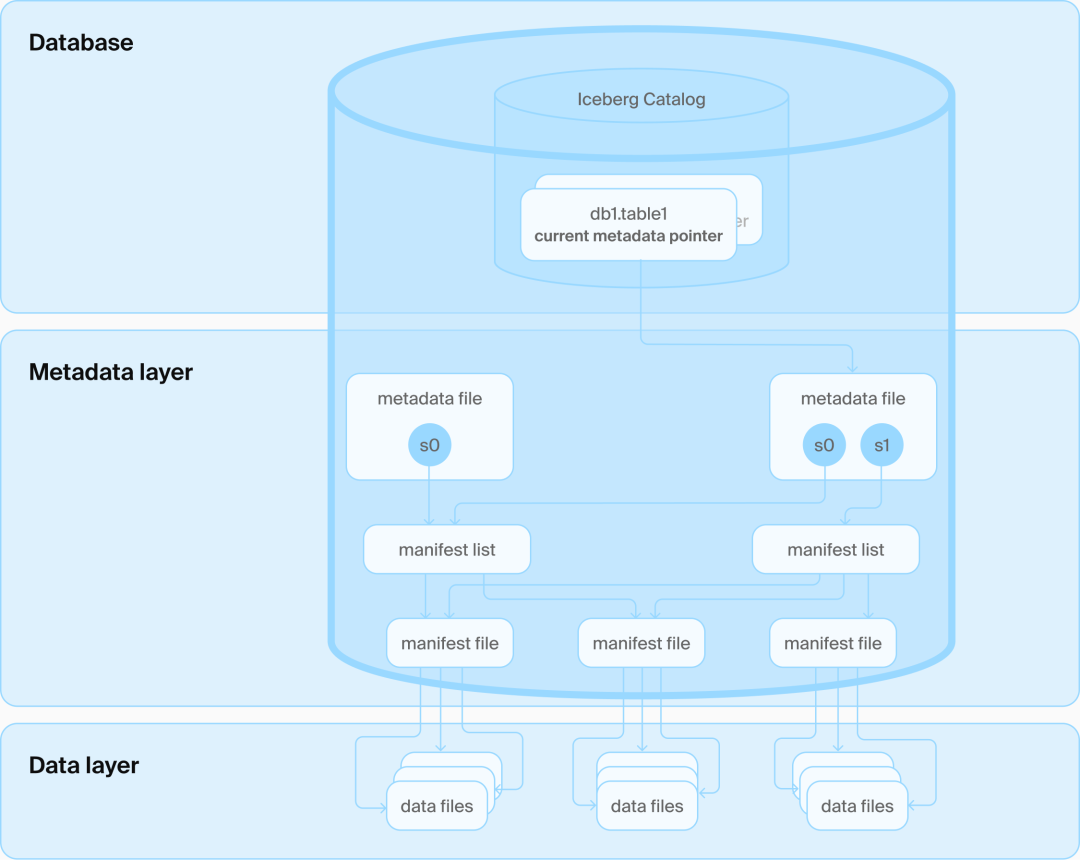
DuckLake架构:一个数据库和一些Parquet文件
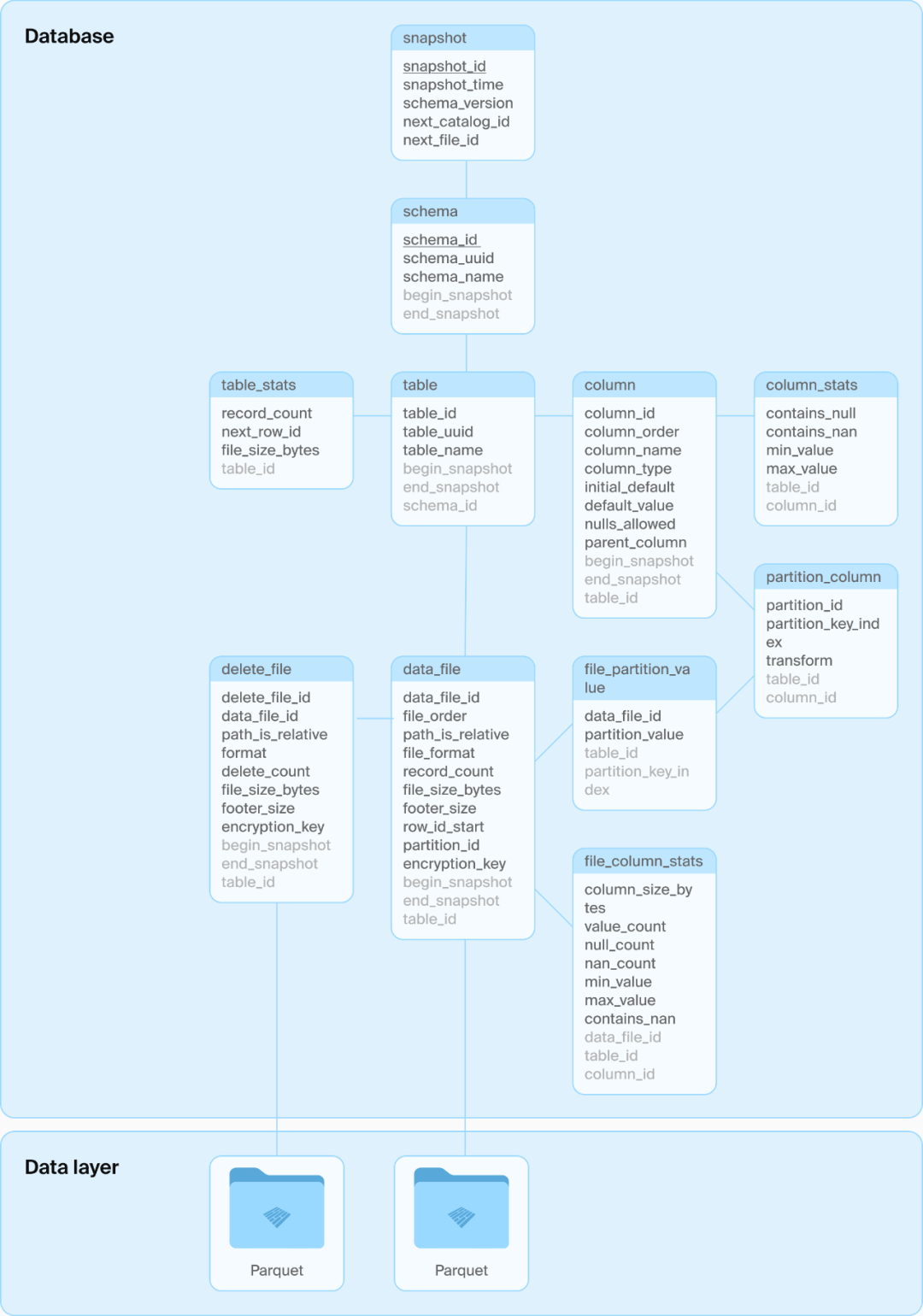
DuckLake模式
DuckLake把整个数据系统分成三块:
存储:所有数据依然存在对象存储(比如 S3),支持Parquet;
计算:无数DuckDB实例可以并发访问存储;
元数据管理:SQL数据库负责Catalog 服务,记录所有变更。
整个系统依然是“存算分离”。这不是巧合,BigQuery用Spanner,Snowflake用FoundationDB,本质上也是类似的架构。
来简单说一下DuckLake的关键创新点:
你要部署?一个DuckDB+插件,几行SQL配置,连对象存储都能直接接上。
你要分析?不用动Spark,不用开集群,直接在本地运行DuckDB即可处理。
对于很多数据分析师、小团队开发者来说,这种“一体化体验”简直不要太丝滑。
AWS:很兴奋,我们内部都在玩!
AWS云计算副总裁Andy Warfield公开表示:
“我们内部团队已经广泛测试DuckLake,确实让人眼前一亮。”
他认为,DuckDB准确地指出了Iceberg/Delta Lake当前方案的一些“老毛病”:
太强调“持久化格式”,对高性能I/O支持不够;
查询时频繁和对象存储打交道,性能开销大;
元数据分散,缺乏统一的“加速访问层”。
而DuckLake的做法是:
用数据库统一管理元数据,减少I/O往返,既省钱又提速。
对于习惯用DuckDB做本地分析的人来说,几乎是量身定制。
但也有人泼冷水:这玩意能规模化吗?
LanceDB工程师Jake Ye(前AWS员工)就提出了质疑:
“DuckLake用SQL来定义和管理元数据,看起来方便,是个有趣的点子,但风险很大。”
他的核心观点是:现在主流趋势是倾向于采用基于JSON的协议作为互操作性的基础,这种趋势不仅体现在像Iceberg REST Catalog (IRC)、Polaris、Gravitino、Unity这样的目录标准上,也出现在AI领域的MCP和A2A协议中。
这些方案的共同点是:
接口标准化,方便多方对接;
权限隔离明确,防误操作;
数据结构清晰,版本可控;
相比之下,直接用SQL虽然灵活,但如果权限控制不到位,很容易出现“误操作毁全局”的问题。
当然,DuckDB团队也在探索更安全的封装式API和权限机制,这块还在进化中。
Snowflake回应:别担心,Iceberg也在进化
Snowflake首席工程师Russell Spitzer则表示,很多项目已经“在Iceberg的路上走得挺远了”。:
“DuckDB提出的问题,其实是Iceberg社区早已关注并正在解决的问题”
比如:
引入了新的Scan API,提高读取效率;
增加了客户端缓存机制,减少对象存储交互;
Iceberg v3还支持了“变体类型字段”,可以接收schema之外的字段,不用改表结构。
他说得也很直白:
“元数据存在哪里不重要,关键是访问的效率和灵活性。只要API好,文件系统、数据库、内存,统统都能跑。”
是革命者,还是昙花一现?
不可否认,DuckLake确实不是给大规模并发、多用户、多租户的企业环境设计的。
它依然是建立在单机DuckDB架构之上,对高并发写入、横向扩展的支持较弱,更适合轻量场景,比如:
数据科学团队的实验分析;
中小企业的离线报表系统;
想省钱又不想搭集群的小公司;
但正是这种“小而美”的定位,让DuckLake一炮而红。
它让整个行业意识到:
有时候,越“轻”的方案,越能揭示“重”架构的盲点。不是所有数据湖都要从Iceberg起步,也可以是“一锅炖”的DuckLake。
写在最后:湖仓这盘棋,又被搅了一次
当AWS、Snowflake、Databricks这些巨头在高处构建标准时,DuckDB从草根出发,给出了一个完全不同的答案。
这不是“谁对谁错”的问题,而是:
一个提醒——湖仓这场游戏,别忘了用户是谁。
DuckLake会不会成为主流?不好说。
但它已经让所有人重新思考:湖仓,真的非得那么重吗?
这波“轻骑兵冲阵”,虽然还没定天下,但已经打破了固有思维。
- END -
延伸阅读


欢迎订阅老鱼笔记
✬如果你喜欢这篇文章,欢迎分享到朋友圈✬
原创不易,且行且珍惜
