






右滑动查看英文版 >>>
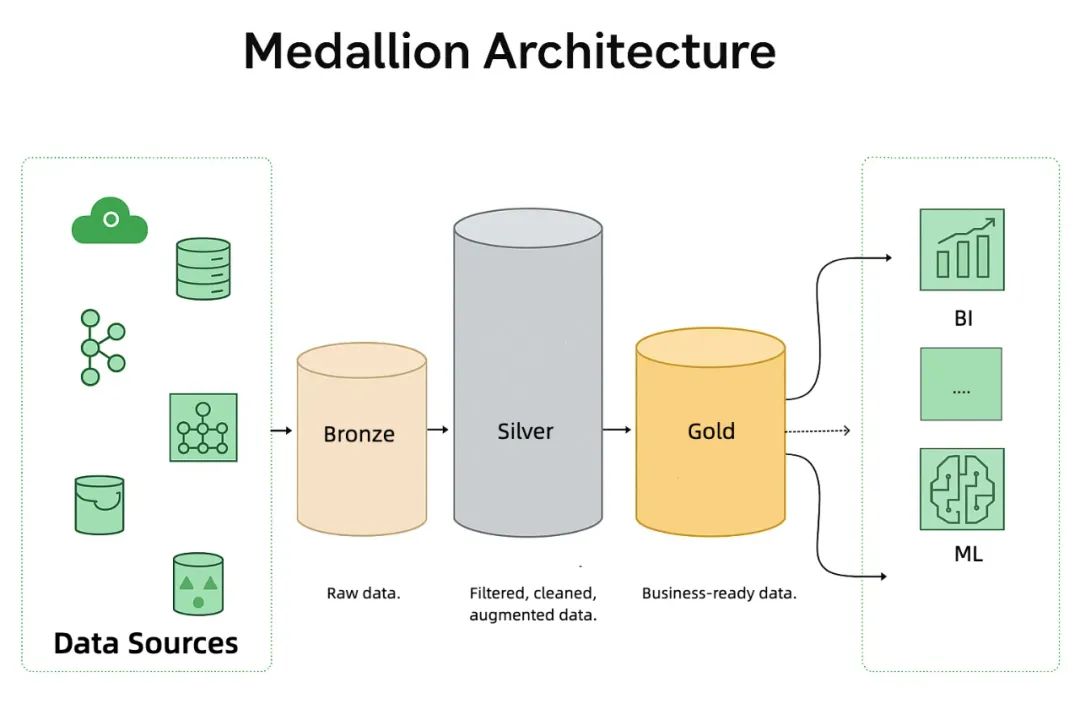
从工厂的 IoT 设备,到城市基础设施的传感器,再到用户操作日志和能耗数据,这些信息通常都被采集下来——然后被丢进一个又一个孤岛系统里。很多企业尝试通过搭建所谓的 Medallion 架构来整合数据流:Bronze 层存原始数据,Silver 层做清洗增强,Gold 层输出分析指标。但这些架构大多依赖离线批处理,运行慢、结构复杂、不易维护,对实时性要求高的业务完全无法支持。

架构设计:让 Medallion 架构“流起来”
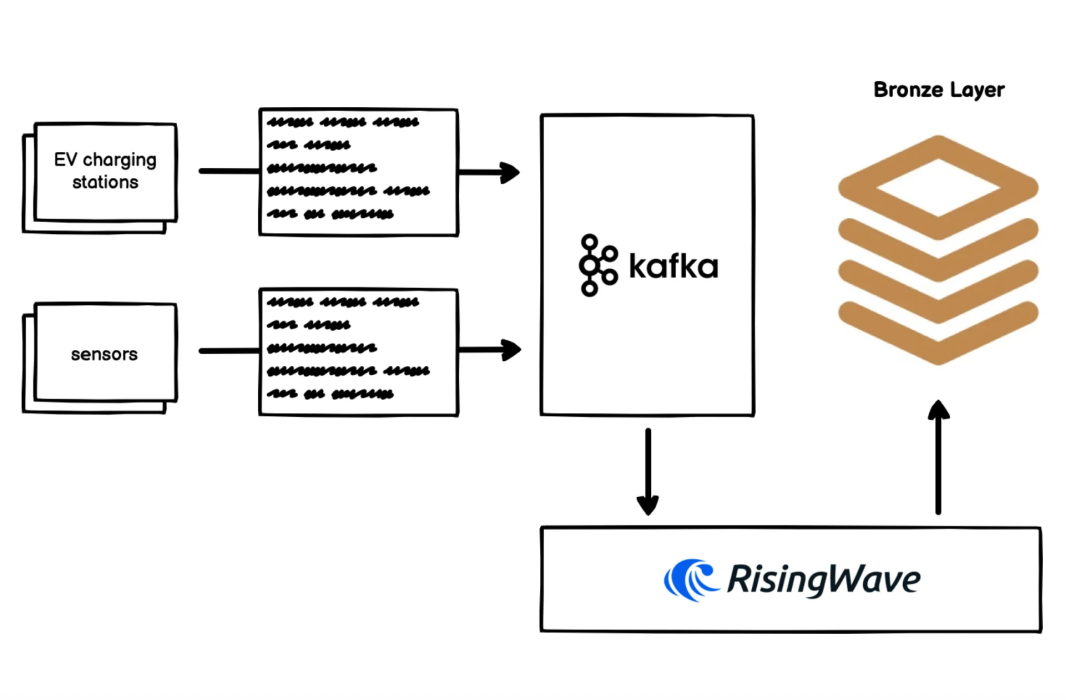
Hivemind 在多个项目中验证了这套设计模式的可行性。下面以某城市 EV 充电网络为例,展示具体的架构如何运行。
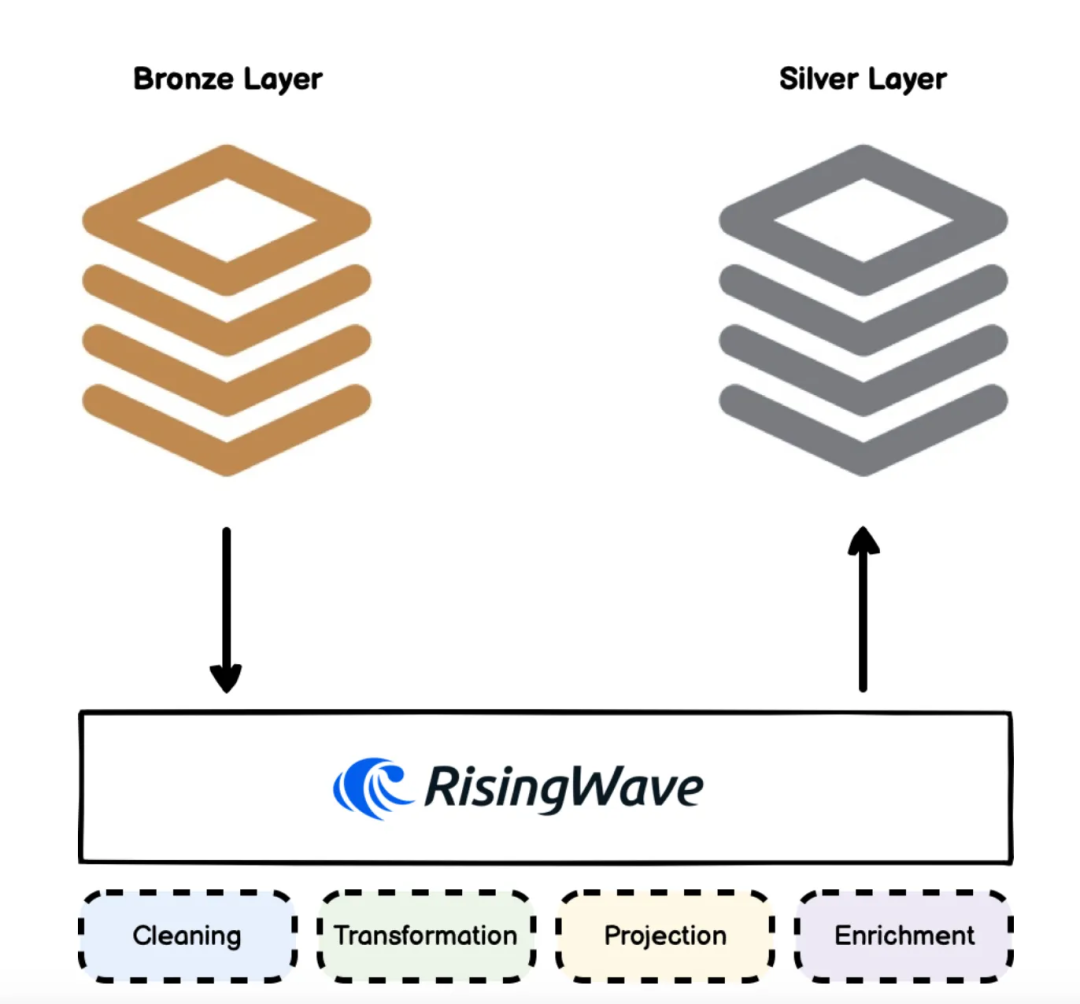
把不同字段名统一(如 temp_c, temperature_f → temperature_c);
把单位转换成统一标准;
把缺失的字段 enrich(例如经纬度转地址,或加入天气信息); 对不合法数据做实时过滤。
每小时每个充电桩的总充电量;
哪些时间段是高峰;
哪些设备报错频率异常高;
某城市哪些区域电网负载最重。
直接提供给可视化平台做 dashboard;
同步到 Iceberg 表供离线分析;
投送到 Kafka topic 被下游系统订阅;
存入 Postgres 或其他 OLAP 系统供 BI 查询。

为什么选择 RisingWave
在选型阶段,Hivemind 考察了多种实时处理方案,包括 Apache Flink、Kafka Streams、Spark Structured Streaming,以及各种主流 ETL 平台。但这些工具要么太重、太复杂,要么上手门槛高、维护成本高。
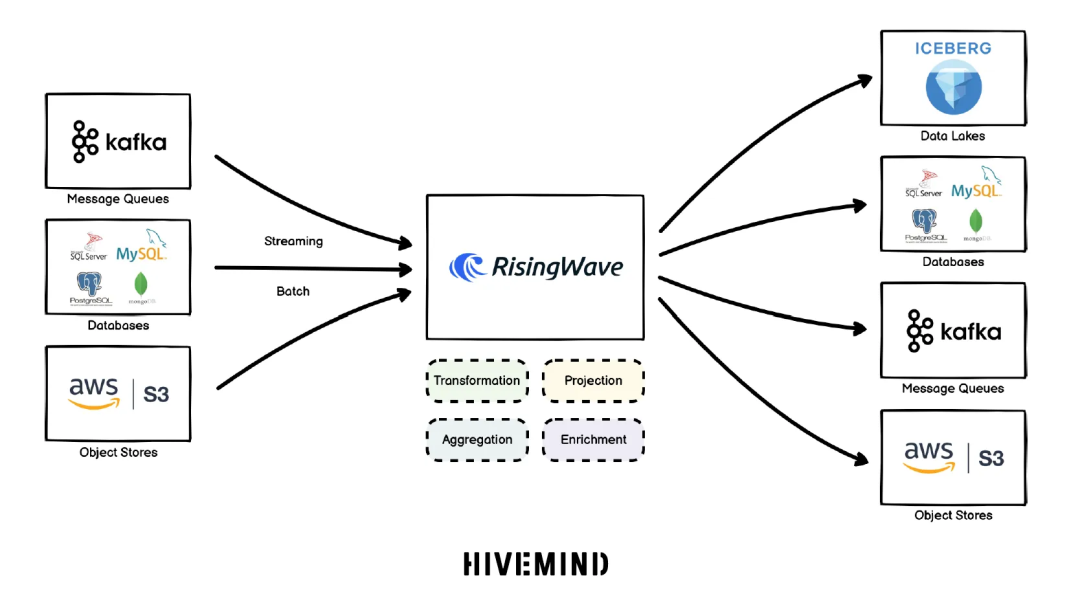
最终,他们选择了 RisingWave——一个支持标准 PostgreSQL 语法的分布式流式数据库。这个系统不仅能以 SQL 的方式处理流数据,还能原生支持物化视图、流式聚合、多源输入与多目标输出,几乎天然适配 Medallion 架构的三个层次。
更重要的是,RisingWave 提供的“实时计算 + 实时存储 + 多目标交付”组合,极大简化了企业部署数据平台的复杂度。这意味着 Hivemind 可以用很少的人力和时间,为客户交付一套真正能跑、能查、能省钱的现代化数据系统。

在西门子的项目中,数据来自于成千上万的现场设备和传感器,之前的系统靠 nightly batch job 来同步清洗数据,处理链路长、延迟高、成本居高不下。Hivemind 将整套逻辑迁移到 RisingWave 之后,带来了立竿见影的改进:
数据延迟从小时级降至秒级;
清洗逻辑从脚本堆栈变为 SQL 规则,维护成本大幅下降; 基础设施资源节省超过 50%,不再需要专门的调度集群和数据落盘中间层; 数据可用性提升,业务部门可以直接基于视图做实时决策。

结语:重构思维方式
Hivemind 并不以构建数据库为使命,但他们以工程视角敏锐捕捉到企业数据架构中的瓶颈,并用 RisingWave 提供了一种更简单、更实时、更可控的替代方案。
Hivemind: https://hivemindtechnologies.com/
<<< 左滑查看中文版
From IoT devices in factories and sensors in urban infrastructure to user operation logs and energy consumption data, information is typically collected, and then siloed away in disparate systems. Many enterprises attempt to consolidate data flows by implementing so-called Medallion architectures: Bronze for raw data, Silver for cleaned and enriched data, and Gold for analytical outputs. However, these architectures often rely on offline batch processing, resulting in slow performance, complex structures, and difficult maintenance, often rendering them unsuitable for businesses with high real-time requirements.
This challenge presented a clear opportunity for Hivemind. They decided to break free from the traditional "scheduling + ETL + data landing" framework and build a new type of streaming, real-time, unified data infrastructure. This approach has been successfully implemented for several large clients, including Siemens.
Architecture Design
Hivemind has validated the feasibility of this design pattern across multiple projects. To illustrate how this architecture operates, let's consider an urban EV charging network as an example.
Bronze Layer: Ingesting Raw Streaming Data
Unify different field names (e.g., temp_c, temperature_f → temperature_c).
Convert units to a consistent standard.
Enrich missing fields (e.g., converting latitude/longitude to addresses or adding weather information).
Filter out invalid data in real-time.
The Gold layer focuses on aggregation and generating insights. In the EV charging scenario, examples include:
Total charging volume per charging station per hour. Peak usage times. Devices with abnormally high error rates. Areas in a city with the heaviest power grid load.
RisingWave's materialized views generate all these metrics in real-time, eliminating the need for batch aggregation or intermediate caching layers. The results from these materialized views can be:
Directly supplied to visualization platforms for dashboards. Synced to Iceberg tables for offline analysis. Delivered to Kafka topics for downstream system subscription. Stored in PostgreSQL or other OLAP systems for BI queries.
Architecturally, the Gold layer is a "result of streaming," not a "product of batching."
Why Choose RisingWave
During the selection phase, Hivemind evaluated various real-time processing solutions, including Apache Flink, Kafka Streams, Spark Structured Streaming, and several mainstream ETL platforms. However, many of these tools proved too heavyweight, overly complex, or came with steep learning curves and high maintenance overhead.
Ultimately, they chose RisingWave—a distributed streaming database that supports standard PostgreSQL syntax. This system not only processes streaming data using SQL but also natively supports materialized views, stream aggregation, and multi-source input with multi-target output, making it a natural fit for the three layers of the Medallion architecture.
More importantly, the "real-time computation + real-time storage + multi-target delivery" combination offered by RisingWave significantly simplifies the complexity of deploying data platforms for enterprises. This enables Hivemind to deliver a modern data system to clients that is truly operational, queryable, and cost-effective, all with significantly reduced effort and time.
Hivemind has successfully deployed this streaming Medallion architecture for several large clients, with Siemens serving as a prominent example.
In the Siemens project, data was sourced from thousands of field devices and sensors. Their previous system relied on nightly batch jobs for data synchronization and cleaning, which resulted in long processing pipelines, high latency, and escalating costs. Migrating the entire logic to RisingWave yielded immediate improvements:
- Data latency dropped from hours to seconds.
- Cleaning logic transformed from complex script stacks to SQL rules, drastically reducing maintenance costs.
- Infrastructure resource savings exceeded 50%, eliminating the need for dedicated scheduling clusters and intermediate data landing layers.
- Data availability improved, allowing business departments to make real-time decisions based on views directly.
Crucially, this architecture also offers high flexibility and portability. It can run in the cloud or be deployed in on-premises data centers, fully aligning with enterprise demands for security, compliance, and operational control.
左右滑动查看中英对照
关于 RisingWave


技术内幕
👇 点击阅读原文,立即体验 RisingWave!
