




作者:YashanDB SQL开发负责人 王海峰
本文主要对YashanDB V23.4 LTS新版本的SQL在Oracle兼容性、执行性能、可维护性等方面的新特性进行解读,以便于读者快速熟悉我们新版本。
在数字化转型与国产化替代的双重浪潮下,企业核心系统正加速向国产数据库迁移。然而,这一过程受到多重阻碍。
首先是迁移成本问题,企业核心系统往往深度依赖Oracle的部分功能特性,且其使用范围常常超出国产数据库现有的兼容能力,导致需大量重写应用代码,成本高昂且伴随质量风险。YashanDB凭借原有版本对Oracle的高兼容能力,在V23.4 LTS版本新增多项企业级特性兼容,不断降低迁移成本。
其次是技术债务问题,企业核心系统经过长期发展积累不少历史债务,表现在对性能指标以及可维护性上的严格要求,而且在国产化替代过程中,常会出现替换后的性能不达标、运维体系不兼容等进一步劣化的问题。YashanDB始终致力于打造高性能的企业级数据库管理系统,并构建与Oracle高度兼容的运维体系,确保用户在数据库的国产化替代过程中,性能不丢失、运维工具平滑迁移。
再则是安全问题,企业面临数据安全与合规性的压力,使用开源生态会面临开源软件漏洞和开源生态供应链风险。而YashanDB一直坚持全自研路线,遵循严谨规范的安全开发流程,以及数据库管理系统的各项安全标准和规范,从根本上解决开源生态可能带来的安全隐患。
以下将对YashanDB V23.4 LTS新版本的SQL在Oracle兼容性、执行性能、可维护性等方面的新特性进行解读,以便于读者快速熟悉我们新版本。
Oracle深度兼容
特性一 新增时区类型
YashanDB在已有26+数据类型的基础上,新增了两种TIMESTAMP时区类型,进一步提升数据类型的兼容性。时区类型用于处理涉及时间和日期的数据,尤其是在跨时区的应用程序中,能保证数据库可正确存储、转换和比较涉及时区的日期和时间信息。
(1)时区类型(Timestamp With Time Zone)

存储数据格式由时间戳+时区两部分来组成,其信息包括了年、月、日、时、分、秒、微秒以及时区信息。该类型将完整的、带时区的日期和时间信息进行存储,参与到计算引擎计算过程中。在跨时区的应用处理程序中,可以确保不论用户位于哪个时区,记录的时间都是准确的。
(2)本地时区类型(Timestamp With Local Time Zone)

存储数据格式只保留时间戳信息,而计算过程中所需的时区信息将由数据库会话时区自动补充。该类型可以缩减时区类型存储的数据空间,但计算过程可以按数据库会话时区进行自动转换,确保数据计算的准确。
为什么时区类型很重要?
适应全球时区差异性:提供了全球化的应用时间解决方案,确保跨时区的应用程序运行时,可以适应各个时区的差异;
提供统一的时间存储格式:通过提供的2类时区类型,可以确保不同时区的用户数据可以统一存储和转换,确保记录时间的准确性。
避免手动转化数据带来的误差:数据转换与比较,在跨时区操作中,时区类型数据可以避免手动调整和转换时区可能带来的错误。
特性二 PL/SQL语言面向对象能力增强-重载能力
YashanDB在新版本增强PL/SQL语言面向对象语言能力,增加PACKAGE支持PROCEDURE和FUNCTION的重载能力,持续提升PL/SQL语言的可编程能力。
在PACKAGE内部,支持多个同名,但参数列表不同的子过程、子函数。参数列表不同,包括参数数量、参数类型、参数顺序等的不同。如下图所示,为一个带重载能力的高级包示例:
CREATE OR REPLACE PACKAGE pack_compare ASFUNCTION max(val1 NUMBER, val2 NUMBER) RETURN NUMBER;FUNCTION max(val1 NUMBER, val2 NUMBER, val3 NUMBER) RETURN NUMBER;FUNCTION max(val1 VARCHAR, val2 VARCHAR) RETURN VARCHAR;FUNCTION max(val1 VARCHAR, val2 VARCHAR, val3 VARCHAR) RETURN VARCHAR;FUNCTION max(val1 TIMESTAMP, val2 TIMESTAMP) RETURN BINARY_DOUBLE;FUNCTION max(val1 TIMESTAMP, val2 TIMESTAMP, val3 TIMESTAMP) RETURN BINARY_DOUBLE;END;/
当调用函数遇到重载的多个函数时,会优先选择与形参数据类型完全一致版本。
当不存在完全一致的版本时,比如上图的max调用函数传入nvarchar数据类型时,没有完全一致的函数版本,此时会根据代价算法计算得到最优的函数。因为nvarchar数据类型与varchar数据类型的转换代价最低,所以选择varchar数据类型的max函数。
但如果计算结果是同时存在大于1个的最优函数,将报候选函数过多的错误。这种情况下,则提醒用户需要改变调用方式,或者修改重载函数,提升使用该特性的可靠性。
特性三 PL/SQL语言语义兼容性提升-表列资源优先
YashanDB在V23.4版本为了进一步提升Oracle的语义兼容性,做了一次将静态SQL、游标等特性的重构动作,这样可以减少语义不兼容带来的业务应用修改。如下图所示:
DROP TABLE IF EXISTS table1;CREATE TABLE table1(col1 int, col2 int);...DECLAREcol1 int;BEGINselect col1 into col1 from table1 order by col2;dbms_output.put_line(col1);END;
YashanDB始终深度兼容Oracle语义。在早期版本中,我们在传入SQL引擎编译前进行了一次预编译动作。然而,该设计在某些场景下导致了与Oracle语义的差异,如在投影位置的col1匹配上,原本应优先匹配表的列名,却因预编译动作而优先匹配为变量col1。这种差异虽然出于技术优化的初衷,但是带来了额外的应用业务改造成本。为了实现真正意义上的平滑替代,YashanDB在V23.4 LTS版本中做了重构,摒弃了原有的预编译动作,改用两阶段编译技术方案,显著提升了对Oracle的语义兼容。
特性一 子查询缓存复用机制
YashanDB新增子查询缓存复用机制,针对子查询场景的查询语句进行性能提升。如下图所示,为父子关联查询示例:
select c.classId , c.namefrom class cwhere ( select count(s.id)from student swhere f(c.classid)=s.classId) >= 2;
这是一个父子关联查询比较典型的场景。之前版本会反复执行子查询,这个版本我们对子查询首次执行结果进行缓存,后续通过复用缓存有效减少执行代价,降低大数据量多次执行子查询的性能开销。相较于历史版本,复杂子查询性能平均提升3倍以上,充分满足高并发OLTP与复杂分析混合负载需求。
但这特性是否一定能带来性能提升的整体收益?答案是不一定的。因为对执行结果进行缓存,需要花费大的缓存构建代价,而这个构建代价是单纯执行子查询所不需要的,所以结果是否能提升还需依赖于缓存被复用的次数。
图中所示的子查询因为重复的classld值而查询出多个相同结果集,会产生子查询的重复执行代价。当重复执行代价大于前文缓存构建代价,就会带来收益。随着重复值越来越多,收益也会越大。
换成基于代价模型的选择公式如下:
不优化路径的cost = 子查询引用执行数 * 子查询执行代价
优化路径的cost = 子查询NDV数 * 子查询执行代价 + 缓存构建代价
注释:NDV, Number of Distinct Value
在大数据量、重复值高的子查询场景,缓存复用机制收益大,性能提升显著。目前此优化已覆盖了多种关联子查询场景,典型如兄弟关联、父子关联等。

特性二 新增SORT GROUPBY STOPKEY算子
YashanDB新增SORT GROUPBY STOPKEY算子,针对STOP KEY和带分组子查询场景进行性能提升。如下图所示,为优化场景语句示例:
select * from (select id from ... group by id) where rownum <= 10select * from (select id from ... group by id) where limit 10select * from (select id from ... group by id) where offset first 10 rows only...
此类语句生成的典型执行计划优化效果如下图所示:
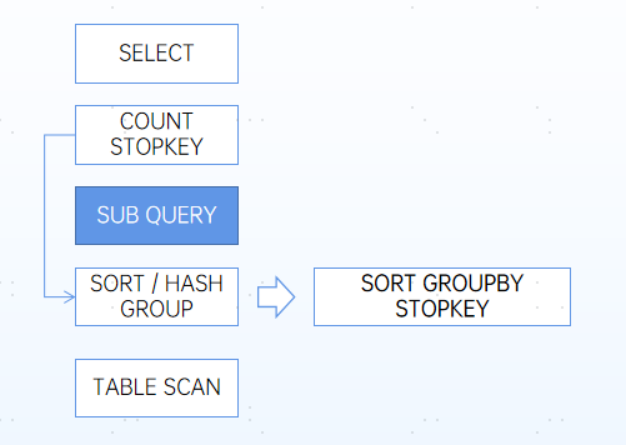
对比两边的计划示意图,可以很明显的看到,左边的COUNT STOPKEY + SORT HASH GROUP 被优化成了SORT GROUPBY STOPKEY,这个优化很直观的从2个算子合并成了1个算子,在子查询数据量大而STOP KEY少的场景下,合并后的算子收益非常明显。
可以基于以下算法判定是否能下推:
1.计算正常路径上父查询COUNT STOPKEY + 子查询选择SORT GROUP代价;
2.计算正常路径上父查询COUNT STOPKEY + 子查询选择HASH GROUP代价;
3.计算父查询COUNT STOPKEY下推后合并子查询分组选择SORT GROUPBY STOPKEY的代价;
4.比较选择最优路径。
当子查询数据量大而需投影的行数少,下推后可大幅减少分组计算代价,性能提升明显。
特性三 FILTER多列增加索引选择规则
YashanDB继续丰富索引选择规则,此次在filter多列语句支持生成索引计划。
CREATE INDEX id1 ON table(col1);/CREATE INDEX id2 ON table(col1, col2, col3);/CREATE INDEX id3 ON table(col1, col2);/SELECT ... FROM table WHERE (col1, col2, col3) in ((value1_1, value1_2, value1_3), (value2_1, value2_2, value2_3))SELECT ... FROM table WHERE (col1 = value1_1 and col2 = value1_2 and col3 = value1_3) or (col1 = value2_1 and col2 = value2_2 and col3 = value2_3) or (col1 = value3_1 and col2 = value3_2 and col3 = value3_3)
如图所示,在filter in,filter and/or等场景,可以根据代价模型的选择,结合已建立的索引,根据filter的多列情况,选择最优索引计划。
当建立了单列索引、多列索引情况下,出现的filter多列,在少于索引列、与索引列一致、多于索引列等多种组合情况下,生成多种不同索引计划,然后选择最优代价的索引计划。在filter多列场景下选择高效的索引计划,性能提升10倍以上。
特性四 DBLINK性能提升
在一些传统的应用业务系统中,存在大量使用DBLINK访问Oracle数据库查询数据情况,因此对性能有较强诉求。
在V23.4版本我们进行了多项优化,使得DBLINK的执行性能提升明显:
支持收集及使用远端统计信息, 参与生成更准确的执行计划。
远端连接池化,有效减少多余建链开销。
协议编解码优化,提高远端对接效率。

可维护性
特性 支持执行计划追踪功能
YashanDB实现了一套追踪(trace)机制,用来追踪SQL执行过程中优化器的内部状态和执行过程,将其执行过程信息输出到一份追踪文件(trace文件)中。
Trace机制是一个非常有用的工具,可以通过事件定制需要追踪的组件状态,追踪的级别,输出追踪信息。可以帮助DBA快速分析计划生成的合理性。

以下是一个trace文件的输出案例,可以看到我们将执行计划的生成在追踪信息进行了较为详尽的输出。


总结
在过去的几十年时间里,Oracle数据库凭借出色的产品能力与硬核的技术实力始终处于领先地位,使得国内诸多关键行业的企业核心系统深度依赖Oracle。在企业核心系统正加速向国产数据库迁移的大背景下,YashanDB选择高度兼容Oracle,以最大程度降低应用迁移的成本与风险;同时聚焦技术痛点与需求,包括性能、可维护性等的提升,帮助用户达成业务目标。
YashanDB始终坚持自主研发的路线,做一个好的国产数据库产品。我们将始终以用户需求为导向,以技术创新为驱动力,在真实场景中反复打磨锤炼,持续完善兼容性、性能、可维护性等各方面能力,助力用户实现数据库国产化的平滑迁移。
最后,如果你对V23.4 LTS版本共享集群新特性想要进一步了解,可以在公众号后台回复小助手,添加微信获取讲师干货PPT。
YashanDB金融特性数据库根原创实验室成果发布,1:1替代Oracle能力获数十家金融权威专家验证
YashanDB V23.4 LTS共享集群在线扩容能力解读
▽ 点击「阅读原文」,上手体验YashanDB
