




本文从数据库系统通信管理、SQL引擎和存储引擎3个方面对openGauss的代码结构进行介绍。
一、通信管理
openGauss查询响应使用简单的“单一用户对应一个服务器线程”的客户端/服务器模型实现。由于无法提前知道需要建立多少个连接,因此必须使用主进程(gaussmaster)。主进程在指定的TCP/IP(transmission control protocol/internet protocol,传输控制协议/互联网协议)端口上侦听传入的连接,只要检测到连接请求,主进程就会生成一个新的服务器线程。服务器线程之间使用信号量和共享内存相互通信,以确保整个并发数据访问期间的数据完整性。
客户端进程可以被理解为满足openGauss协议的任何程序。许多客户端都基于C语言库libpq进行通信,但是该协议有几种独立的实现,例如Java JDBC驱动程序。
建立连接后,客户端进程可以将查询发送到后端服务器。查询使用纯文本传输,即在前端(客户端)中没有进行解析。服务器解析查询语句、创建执行计划、执行并通过在已建立连接上传输检索到的结果集,将其返回给客户端。
openGauss数据库中处理客户端连接请求的模块叫作作postmaster。前端程序发送启动信息给postmaster,postmaster根据信息内容建立后端响应线程。postmaster也管理系统级的操作,比如调用启动和关闭程序。postmaster在启动时创建共享内存和信号量池,但它自身不管理内存、信号量和锁操作。
当客户端发来一个请求信息,postmaster立刻启动一个新会话,新会话对请求进行验证,验证成功后为它匹配后端工作线程。这种模式架构上处理简单,但是高并发下由于线程过多,切换和轻量级锁区域的冲突过大导致性能急剧下降。因此openGauss通过线程资源池化复用的技术来解决该问题。线程池技术的整体设计思想是线程资源池化,并且在不同连接直接复用。
1. postmaster源码组织
postmaster源码目录为:/src/gausskernel/process/postmaster。postmaster源码文件如下表所示。
表 postmaster源码文件
模块 | 源码文件 | 功能 |
postmaster | postmaster.cpp | 用户响应主程序 |
aiocompleter.cpp | 完成预取(prefetch)和后端写(backWrite)I/O操作 | |
alarmchecker.cpp | 闹钟检查线程 | |
lwlockmonitor.cpp | 轻量锁的死锁检测 | |
pagewriter.cpp | 写页面 | |
pgarch.cpp | 日志存档 | |
pgaudit.cpp | 审计线程 | |
pgstat.cpp | 统计信息收集 | |
startup.cpp | 服务初始化和恢复 | |
syslogger.cpp | 捕捉并写所有错误日志 | |
autovacuum.cpp | 垃圾清理线程 | |
bgworker.cpp | 后台工作线程(服务共享内存) | |
bgwriter.cpp | 后台写线程(写共享缓存) | |
cbmwriter.cpp | 修改数据块跟踪记录线程 | |
remoteservice.cpp | 远程服务线程,用于双机损坏页修复时的远程服务 | |
checkpointer.cpp | 检查点处理 | |
fencedudf.cpp | 保护模式下运行用户定义函数 | |
gaussdb_version.cpp | 版本特性控制 | |
twophasecleaner.cpp | 清理两阶段事务线程 | |
walwriter.cpp | 预写式日志写入 |
2. postmaster主流程
postmaster主流程代码如下:
/* postmaster.cpp */
...
int PostmasterMain(int argc, char* argv[])
{
InitializePostmasterGUC(); /* 初始化postmaster模块配置参数*/
...
pgaudit_agent_init(); /* 初始化审计模块*/
...
for (i = 0; i < MAXLISTEN; i++) /* 建立输入socket监听*/
t_thrd.postmaster_cxt.ListenSocket[i] = PGINVALID_SOCKET;
...
/* 建立共享内存和信号池*/
reset_shared(g_instance.attr.attr_network.PostPortNumber);
...
/* 初始化postmaster信号管理*/
gs_signal_slots_init(GLOBAL_ALL_PROCS + EXTERN_SLOTS_NUM);
...
InitPostmasterDeathWatchHandle(); /* 初始化宕机监听*/
...
pgstat_init(); /* 初始化统计数据收集子系统*/
InitializeWorkloadManager(); /* 初始化工作负载管理器*/
...
InitUniqueSQL(); /* 初始化unique SQL资源*/
...
autovac_init(); /* 初始化垃圾清理线程子系统*/
...
status = ServerLoop(); /* 启动postmaster主业务循环*/
...
}
二、SQL引擎
数据库的SQL引擎是数据库重要的子系统之一,它对上负责承接应用程序发送过来的SQL语句,对下则负责指挥执行器运行执行计划。其中优化器作为SQL引擎中最重要、最复杂的模块,被称为数据库的“大脑”,优化器产生的执行计划的优劣直接决定数据库的性能。
本节从SQL语句发送到数据库服务器开始,对SQL引擎的各个模块进行全面的介绍与源码解析,以实现对SQL语句执行的逻辑与源码更深入的理解。其响应流程如图所示。
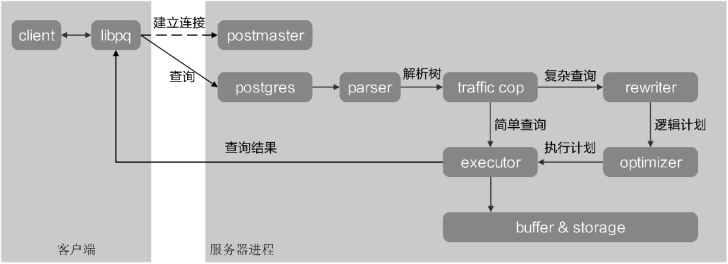
openGauss数据库SQL查询响应流程
1. 查询解析——parser
SQL解析对输入的SQL语句进行词法分析、语法分析、语义分析,获得查询解析树或者逻辑计划。SQL查询语句解析的解析器(parser)阶段包括如下。
(1) 词法分析:从查询语句中识别出系统支持的关键字、标识符、操作符、终结符等,每个词确定自己固有的词性。
(2) 语法分析:根据SQL语言的标准定义语法规则,使用词法分析中产生的词去匹配语法规则,如果一个SQL语句能够匹配一个语法规则,则生成对应的语法树(abstract synatax tree,AST)。
(3) 语义分析:对语法树进行检查与分析,检查语法树中对应的表、列、函数、表达式是否有对应的元数据(指数据库中定义有关数据特征的数据,用来检索数据库信息)描述,基于分析结果对语法树进行扩充,输出查询树(Query)。主要检查的内容包括:
检查关系的使用:FROM子句中出现的关系必须是该查询对应模式中的关系或视图。
‚ 检查与解析属性的使用:在SELECT语句中或者WHERE子句中出现的各个属性必须是FROM子句中某个关系或视图的属性。
ƒ 检查数据类型:所有属性的数据类型必须是匹配的。
词法和语法分析代码基于gram.y和scan.l中定义的规则,使用UNIX工具bison和flex构建产生。其中,词法分析器在文件scan.l中定义,它负责识别标识符、SQL关键字等。对于找到的每个关键字或标识符,都会生成一个标记并将其传递给解析器。语法解析器在文件gram.y中定义,由一组语法规则和每当触发规则时执行的动作组成,基于这些动作代码架构并输出语法树。在解析过程中,如果语法正确,则进入语义分析阶段并建立查询树返回,否则将返回错误,终止解析过程。
解析器在词法和语法分析阶段仅使用有关SQL语法结构的固定规则来创建语法树。它不会在系统目录中进行任何查找,因此无法理解所请求操作的详细语义。
语法解析完成后,语义分析过程将解析器返回的语法树作为输入,并进行语义分析以了解查询所引用的表、函数和运算符。用来表示此信息的数据结构称为查询树。解析器解析过程分为原始解析与语义分析,分开的原因是,系统目录查找只能在事务内完成,并且不希望在收到查询字符串后立即启动事务。原始解析阶段足以识别事务控制命令(BEGIN,ROLLBACK等),然后可以正确执行这些命令而无须任何进一步分析。一旦知道正在处理的实际查询(例如SELECT或UPDATE),就可以开始事务,这时才调用语义分析过程。
1) parser源码组织
parser源码目录为:/src/common/backend/parser。parser源码文件如下表所示。
表 parser源码文件
模块 | 源码文件 | 功能 |
parser | parser.cpp | 解析主程序 |
scan.l | 词法分析,分解查询成token(令牌) | |
scansup.cpp | 处理查询语句转义符 | |
kwlookup.cpp | 将关键词转换为具体的token | |
keywords.cpp | 标准关键词列表 | |
analyze.cpp | 语义分析 | |
gram.y | 语法分析,解析查询token并产生原始解析树 | |
parse_agg.cpp | 处理聚集操作,比如SUM(col1)、AVG(col2) | |
parse_clause.cpp | 处理子句,比如WHERE、ORDER BY | |
parse_compatibility.cpp | 处理数据库兼容语法和特性支持 | |
parse_coerce.cpp | 处理表达式数据类型强制转换 | |
parse_collate.cpp | 对完成表达式添加校对信息 | |
parse_cte.cpp | 处理公共表格表达式(WITH 子句) | |
parse_expr.cpp | 处理表达式,比如col、col+3、x=3 | |
parse_func.cpp | 处理函数,table.column和列标识符 | |
parse_node.cpp | 对各种结构创建解析节点 | |
parse_oper.cpp | 处理表达式中的操作符 | |
parse_param.cpp | 处理参数 | |
parse_relation.cpp | 支持表和列的关系处理程序 | |
parse_target.cpp | 处理查询解析的结果列表 | |
parse_type.cpp | 处理数据类型 | |
parse_utilcmd.cpp | 处理实用命令的解析分析 |
2) parser主流程
parser主流程代码如下:
/* parser.cpp */
...
/* 原始解析器,输入查询字符串,做词法和语法分析,返回原始语法解析树列表*/
List* raw_parser(const char* str, List** query_string_locationlist)
{
...
/* 初始化 flex scanner */
yyscanner = scanner_init(str, &yyextra.core_yy_extra, ScanKeywords, NumScanKeywords);
...
/* 初始化 bison parser */
parser_init(&yyextra);
/* 解析! */
yyresult = base_yyparse(yyscanner);
/* 清理释放内存*/
scanner_finish(yyscanner);
...
return yyextra.parsetree;
}
/* analyze.cpp */
...
/* 分析原始语法解析树,做语义分析并输出查询树 */
Query* parse_analyze(
Node* parseTree, const char* sourceText, Oid* paramTypes, int numParams, bool isFirstNode, bool isCreateView)
{
/* 初始化解析状态和查询树 */
ParseState* pstate = make_parsestate(NULL);
Query* query = NULL;
...
/* 将解析树转换为查询树 */
query = transformTopLevelStmt(pstate, parseTree, isFirstNode, isCreateView);
...
/* 释放解析状态 */
free_parsestate(pstate);
...
return query;
}
2. SQL查询分流——traffic cop
traffic cop模块负责查询的分流,它负责区分简单和复杂的查询指令。事务控制命令(例如BEGIN和ROLLBACK)非常简单,因此不需要其他处理,而其他命令(例如SELECT和JOIN)则传递给重写器(参考第6章)。这种区分通过对简单命令执行最少的优化,并将更多的时间投入复杂的命令上,从而减少了处理时间。简单和复杂查询指令也对应如下两类解析。
(1) 软解析(简单,旧查询):当openGauss共享缓冲区中存在已提交SQL语句的已解析表示形式时,可以重复利用缓存内容执行语法和语义检查,避免查询优化相对昂贵的操作。
(2) 硬解析(复杂,新查询):如果无缓存语句可重用,或者第一次将SQL语句加载到openGauss共享缓冲区中,则会导致硬解析。同样,当一条语句在共享缓冲区中老化时,再次重新加载该语句时,还会导致另一次硬解析。因此,共享缓冲区的大小也会影响解析调用的数量。
可以查询gs_prepared_statements查看缓存了什么,以区分软/硬解析(它仅对当前会话可见)。此外,gs_buffercache模块提供了一种实时检查共享缓冲区高速缓存内容的方法,它甚至可以分辨出有多少数据块来自磁盘,有多少数据来自共享缓冲区。
1) traffic cop(tcop)源码组织
traffic cop(tcop)源码目录为:/src/common/backend/tcop。traffic cop(tcop)源码文件如下表所示。
表 traffic cop(tcop)源码文件
模块 | 源码文件 | 功能 |
tcop | auditfuncs.cpp | 记录数据库操作审计信息 |
autonomous.cpp | 创建可被用来执行SQL查询的自动会话 | |
dest.cpp | 与查询结果被发往的终点通信 | |
utility.cpp | 数据库通用指令控制函数 | |
fastpath.cpp | 在事务期间缓存操作函数和类型等信息 | |
postgres.cpp | 后端服务器主程序 | |
pquery.cpp | 查询处理指令 | |
stmt_retry.cpp | 执行SQL语句失败时,分析返回的错误码,决定是否进行重试 |
2) traffic cop主流程
traffic cop主流程代码如下:
...
/*原始解析器,输入查询字符串,做词法和语法分析,返回原始解析树列表*/
int PostgresMain(int argc, char* argv[], const char* dbname, const char* username)
{
...
/* 整体初始化*/
t_thrd.proc_cxt.PostInit->SetDatabaseAndUser(dbname, InvalidOid, username);
...
/* 事务的自动错误处理 */
if (sigsetjmp(local_sigjmp_buf, 1) != 0) { ... }
...
/* 错误语句的重新尝试阶段 */
if (IsStmtRetryEnabled() && StmtRetryController->IsQueryRetrying())
{ ... }
/* 无错误查询指令循环处理*/
for (;;) {
...
/* 按命令类型执行处理流程*/
switch(firstchar){
...
case: 'Q': ... /* 简单查询 */
case: 'P': ... /* 解析 */
case: 'E': ... /* 执行 */
}
...
}
...
}
3. 查询重写——rewriter
查询重写利用已有语句特征和关系代数运算来生成更高效的等价语句,在数据库优化器中扮演关键角色;尤其在复杂查询中,能够在性能上带来数量级的提升,可谓是“立竿见影”的“黑科技”。SQL语言是丰富多样的,非常灵活,不同的开发人员依据经验的不同,手写的SQL语句也是各式各样,另外还可以通过工具自动生成。同时SQL语言是一种描述性语言,数据库的使用者只是描述了想要的结果,而不关心数据的具体获取方式,输入数据库的SQL语言很难做到以最优形式表示,往往隐含了一些冗余信息,这些信息可以被挖掘生成更加高效的SQL语句。查询重写就是把用户输入的SQL语句转换为更高效的等价SQL。查询重写遵循两个基本原则。
(1) 等价性:原语句和重写后的语句,输出结果相同。
(2) 高效性:重写后的语句,比原语句在执行时间和资源使用上更高效。
介绍如下几个openGauss数据库关键的查询重写技术。
(1) 常量表达式化简:常量表达式,即用户输入SQL语句中包含运算结果为常量的表达式,分为算数表达式、逻辑运算表达式、函数表达式。查询重写可以对常量表达式预先计算以提升效率。例如“SELECT * FROM table WHERE a=1+1;”语句被重写为“SELECT * FROM table WHERE a=2”语句。
(2) 子查询提升:由于子查询表示的结构更清晰,符合人的阅读理解习惯,用户输入的SQL语句往往包含了大量的子查询,但是相关子查询往往需要使用嵌套循环的方法来实现,执行效率较低,因此将子查询优化为semi join的形式可以在优化规划时选择其他的执行方法,或能提高执行效率。例如“SELECT * FROM t1 WHERE t1.a in (SELECT t2.a FROM t2);”语句可重写为“SELECT * FROM t1 LEFT SEMI JOIN t2 ON t1.a=t2.a”语句。
(3) 谓词下推:谓词(Predicate),通常为SQL语句中的条件,例如“SELECT * FROM t1 WHERE t1.a=1;”语句中的“t1.a=1”即为谓词。等价类(equivalent-class)是指等价的属性、实体等对象的集合,例如“WHERE t1.a=t2.a”语句中,t1.a和t2.a互相等价,组成一个等价类{t1.a,t2.a}。利用等价类推理(又称作传递闭包),可以生成新的谓词条件,从而达到减小数据量和最大化利用索引的目的。举一个形象的例子来说明谓词下推的威力,假设有两个表t1、t2,它们分别包含[1,2,3,…,100]共100行数据,那么查询语句“SELECT * FROM t1 JOIN t2 ON t1.a=t2.a WHERE t1.a=1”的逻辑计划在经过查询重写前后的对比,如图所示。
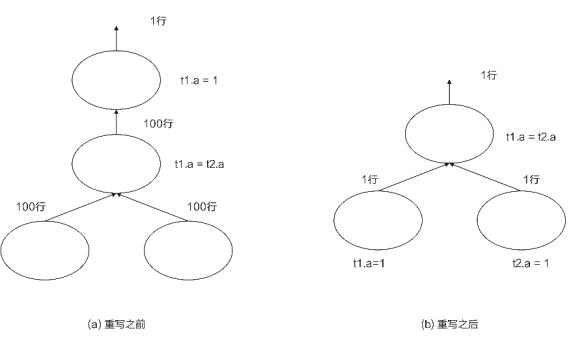
查询重写前后对比
查询重写的主要工作在优化器中实现,源代码目录主要在/src/gausskernel/optimizer/prep,源码文件如表所示。
表 查询重写源代码文件
模块 | 源码文件 | 功能 |
prep | prepqual.cpp | 对谓词进行正则化 |
preptlist.cpp | 对投影进行重写 | |
prepunion.cpp | 处理查询中的集合操作 | |
preprownum.cpp | 对表达式中的rownum进行预处理 | |
prepjointree.cpp | 化简表达式、子查询 | |
prepnonjointree.cpp | Lazy Aggregation优化 |
除此之外,openGauss还提供了基于规则的rewrite接口,用户可以通过创建替换规则的方法对逻辑执行计划进行改写。例如视图展开功能,即通过rewrite模块中的规则进行替换,而视图展开的规则是在创建视图的过程中默认创建的。
1) rewriter源码组织
rewriter源码目录为:/src/gausskernel/optimizer/rewrite。源码文件如表所示。
表 rewriter源码文件
模块 | 源码文件 | 功能 |
rewrite | rewriteDefine.cpp | 定义重写规则 |
rewriteHandler.cpp | 重写主模块 | |
rewriteManip.cpp | 重写操作函数 | |
rewriteRemove.cpp | 重写规则移除函数 | |
rewriteRlsPolicy.cpp | 重写行粒度安全策略 | |
rewriteSupport.cpp | 重写辅助函数 |
2) rewriter主流程
rewriter主流程代码如下:
/* rewrite.cpp */
...
/* 查询重写主函数 */
List* QueryRewrite(Query* parsetree)
{
...
/* 应用所有non-SELECT规则获取改写查询列表 */
querylist = RewriteQuery(parsetree, NIL);
/* 对每个改写查询应用RIR规则 */
results = NIL;
foreach (l, querylist) {
Query* query = (Query*)lfirst(l);
query = fireRIRrules(query, NIL, false);
query->queryId = input_query_id;
results = lappend(results, query);
}
/* 从重写列表确定一个重写结果 */
origCmdType = parsetree->commandType;
foundOriginalQuery = false;
lastInstead = NULL;
foreach (l, results) {...}
...
return results;
}
4. 查询优化——optimizer
优化器(optimizer)的任务是创建最佳执行计划。一个给定的SQL查询以及一个查询树实际上可以以多种不同的方式执行,每种方式都会产生相同的结果集。如果在计算上可行,则查询优化器将检查这些可能的执行计划中的每一个,最终选择预期运行速度最快的执行计划。
在某些情况下,检查执行查询的每种可能方式都会占用大量时间和内存空间,特别是在执行涉及大量连接操作(join)的查询时。为了在合理的时间内确定合理的(不一定是最佳的)查询计划,当查询连接数超过阈值时,openGauss使用遗传查询优化器(genetic query optimizer),通过遗传算法来做执行计划的枚举。
优化器的查询计划(plan)搜索过程实际上与称为路径(path)的数据结构一起使用,该路径只是计划的简化表示,其中仅包含确定计划所需的关键信息。确定代价最低的路径后,将构建完整的计划树以传递给执行器。这足够详细地表示了所需的执行计划,供执行者运行。在本节的其余部分,将忽略路径和计划之间的区别。
1) 生成查询计划
首先,优化器会生成查询中使用的每个单独关系(表)的计划。候选计划由每个关系上的可用索引确定。对关系的顺序扫描是查询最基本的方法,因此总是会创建顺序扫描计划。假设在关系上定义了索引(例如B树索引),并且查询属性恰好与B树索引的键匹配,则使用B树索引创建另一个基于索引的查询计划。如果还存在其他索引并且查询中的限制恰好与索引的关键字匹配,则将考虑其他计划生成更多计划。
其次,如果查询需要连接两个或多个关系,则在找到所有可行的扫描单个关系的计划之后,将考虑连接关系的计划。连接关系有3种可用的连接策略:
(1) 嵌套循环连接:对在左关系中找到的每一行,都会扫描一次右关系。此策略易于实施,但非常耗时。(但是如果可以使用索引扫描来扫描右关系,这可能是一个不错的策略。可以将左关系的当前行中的值用作右索引扫描的键。)
(2)合并连接:在开始连接之前,对进行连接的每个关系的连接属性进行排序。然后,并行扫描进行连接的这两个关系,并组合匹配的行以形成连接行。这种连接更具吸引力,因为每个关系只需扫描一次。所需的排序可以通过明确的排序步骤来实现,也可以通过使用连接键上的索引以正确的顺序扫描关系来实现。
(3) 哈希连接:首先将正确的关系扫描并使用其连接属性作为哈希键加载到哈希表(hash table,也叫散列表)中。接下来,扫描左关系,并将找到的每一行的适当值用作哈希键,以在表中找到匹配的行。
当查询涉及两个以上的关系时,最终结果必须由构建连接树来确定。优化器检查不同的可能连接顺序以找到代价最低的连接顺序。
如果查询所使用的关系数目较少(少于启动启发式搜索阈值),那么将进行近乎穷举的搜索以找到最佳连接顺序。优化器优先考虑存在WHERE限定条件子句中的两个关系之间的连接(即存在诸如rel1.attr1 = rel2.attr2之类的限制),最后才考虑不具有join子句的连接对。优化器会对每个连接操作生成所有可能的执行计划,然后选择(估计)代价最低的那个。当连接表数目超过geqo_threshold时,所考虑的连接顺序由基因查询优化(Genetic Query Optimization,GEQO)启发式方法确定。
完成的计划树包括对基础关系的顺序或索引扫描,以及根据需要的嵌套循环、合并、哈希连接节点和其他辅助步骤,例如排序节点或聚合函数计算节点。这些计划节点类型中的大多数具有执行选择(丢弃不满足指定布尔条件的行)和投影(基于给定列值计算派生列集,即执行标量表达式的运算)的附加功能。优化器的职责之一是将WHERE子句中的选择条件附加起来,并将所需的输出表达式安排到计划树的最适当节点上。
2) 查询计划代价估计
openGauss的优化器是基于代价的优化器,对每条SQL语句生成的多个候选的计划,优化器会计算一个执行代价,最后选择代价最小的计划。
通过统计信息,代价估算系统就可以了解一个表有多少行数据、用了多少个数据页面、某个值出现的频率等,以确定约束条件过滤出的数据占总数据量的比例,即选择率。当一个约束条件确定了选择率之后,就可以确定每个计划路径所需要处理的行数,并根据行数可以推算出所需要处理的页面数。当计划路径处理页面的时候,会产生I/O代价。而当计划路径处理元组的时候(例如针对元组做表达式计算),会产生CPU代价。由于openGauss是单机数据库,无服务器节点间传输数据(元组)会产生通信的代价,因此一个计划的总体代价可以表示为:
总代价 = I/O代价 + CPU代价
openGauss把所有顺序扫描一个页面的代价定义为单位1,所有其他算子的代价都归一化到这个单位1上。比如把随机扫描一个页面的代价定义为4,即认为随机扫描一个页面所需代价是顺序扫描一个页面所需代价的4倍。又比如,把CPU处理一条元组的代价为0.01,即认为CPU处理一条元组所需代价为顺序扫描一个页面所需代价的1/100。
从另一个角度来看,openGauss将代价又分成了启动代价和执行代价,其中:
总代价 = 启动代价 + 执行代价
(1) 启动代价。
从SQL语句开始执行到此算子输出第一条元组为止,所需要的代价称为启动代价。有的算子启动代价很小,比如基表上的扫描算子,一旦开始读取数据页,就可以输出元组,因此启动代价为0。有的算子的启动代价相对较大,比如排序算子,它需要把所有下层算子的输出全部读取到,并且把这些元组排序之后,才能输出第一条元组,因此它的启动代价比较大。
(2) 执行代价。
从输出第一条算子开始,至查询结束,所需要的代价,称为执行代价。这个代价中又可以包含CPU代价、I/O代价,执行代价的大小与算子需要处理的数据量有关,也与每个算子完成的功能有关。处理的数据量越大、算子需要完成的任务越重,则执行代价越大。
(3) 总代价。
如图所示示例,查询中包含两张表,分别命名为t1、t2。t1与t2进行join操作,并且对c1列做聚集。
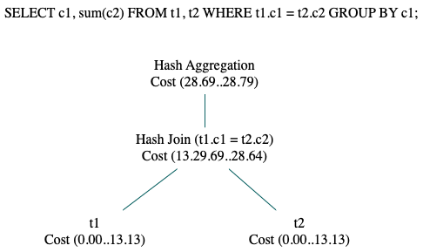
代价计算示例
示例中涉及的代价包括:
(1) 扫描t1的启动代价为0,总代价为13.13。13.13的意思是“总代价相当于顺序扫描13.13个页面”,t2表的扫描同理。
(2) 此计划的join方式为hash join,使用hash join时,必须先对一个子节点的所有数据建立哈希表,再依次使用另一个子节点的每一条元组尝试与hash join中的元组进行匹配。因此hash join的启动代价包括了建立哈希表的代价。
此计划中hash join的启动代价为13.29,对某个结果集建立哈希表时,必须拿到此结果集的所有数据,因此13.29比下层扫描算子的代价13.13大。
此计划中hash join的总代价为28.64。
(3) join完毕之后,需要做聚集运算,此计划中的聚集运算使用了HashAGG算子,此算子需要对join的结果集以c1列作为hash Key建立哈希表,因此它的启动代价又包含了一个建立哈希表的代价。聚集操作的启动代价为28.69,总代价为28.79。
3) optimizer源码组织
optimizer源码目录为:/src/gausskernel/optimizer。optimizer源码文件如表所示。
表 optimizer源码文件
模块 | 源码文件 | 功能 |
plan | analyzejoins.cpp | 初始化查询后的连接简化 |
createplan.cpp | 创建查询计划 | |
dynsmp_single.cpp | SMP自适应接口函数 | |
planner.cpp | 查询优化外部接口 | |
planrecursive_single.cpp | with_recursive递归查询的处理函数 | |
planrewrite.cpp | 基于代价的查询重写 | |
setrefs.cpp | 完成的查询计划树的后处理(修复子计划变量引用) | |
initsplan.cpp | 目标列表、限定条件和连接信息初始化 | |
pgxcplan_single.cpp | 简单查询的旁路执行器 | |
planagg.cpp | 聚集查询的特殊计划 | |
planmain.cpp | 计划主函数:单个查询的计划 | |
streamplan_single.cpp | 流计划相关函数 | |
subselect.cpp | 子选择和参数的计划函数 | |
path | allpaths.cpp | 查找所有可能查询执行路径 |
clausesel.cpp | 子句选择性计算 | |
costsize.cpp | 计算关系和路径代价 | |
pathkeys.cpp | 匹配并建立路径键的公用函数 | |
pgxcpath_single.cpp | 查找关系和代价的所有可能远程查询路径 | |
streampath_single.cpp | 并行处理的路径生成 | |
tidpath.cpp | 确定扫描关系TID(tuple identifier,元组标识符)条件并创建对应TID路径 | |
equivclass.cpp | 管理等价类 | |
indxpath.cpp | 确定可使用索引并创建对应路径 | |
joinpath.cpp | 查找执行一组join操作的所有路径 | |
joinrels.cpp | 确定需要被连接的关系 | |
orindxpath.cpp | 查找匹配OR子句集的索引路径 |
4) optimizer主流程
optimizer主流程代码如下:
/* planmain.cpp */
...
/*
*优化器主函数
*生成基本查询的路径(最简化的查询计划)
*输入参数:
*root:描述需要计划的查询
*tlist: 查询生成的目标列表
*tuple_fraction: 被抽取的元组数量比例
*limit_tuples: 抽取元组数量的数量限制
*输出参数:
*cheapest_path: 查询整体上代价最低的路径
*sorted_path: 排好序的代价最低的数个路径
*num_groups: 估计组的数量(如果查询不使用group运算返回1)
*/
void query_planner(PlannerInfo* root, List* tlist, double tuple_fraction, double limit_tuples,query_pathkeys_callback qp_callback, void *qp_extra, Path** cheapest_path, Path** sorted_path, double* num_groups, List* rollup_groupclauses, List* rollup_lists){
...
/* 空连接树简单query 快速处理 */
if (parse->jointree->fromlist == NIL) {
...
return;
}
setup_simple_rel_arrays(root); /* 获取线性版的范围表,加速读取 */
/* 为基础关系建立RelOptInfo节点 */
add_base_rels_to_query(root, (Node*)parse->jointree);
check_scan_hint_validity(root);
/* 向目标列表添加条目,占位符信息生成,最后形成连接列表 */
build_base_rel_tlists(root, tlist);
find_placeholders_in_jointree(root);
joinlist = deconstruct_jointree(root);
reconsider_outer_join_clauses(root); /* 基于等价类重新考虑外连接*/
/* 对等价类生成额外的限制性子句 */
generate_base_implied_equalities(root);
generate_base_implied_qualities(root);
(*qp_callback) (root, qp_extra); /* 将完整合并的等价类集合转换为标准型 */
fix_placeholder_input_needed_levels(root); /* 检查占位符表达式 */
joinlist = remove_useless_joins(root, joinlist); /* 移除无用外连接 */
add_placeholders_to_base_rels(root); /* 将占位符添加到基础关系 */
/* 对每个参与查询表的大小进行估计,计算total_table_pages */
total_pages = 0;
for (rti = 1; rti < (unsigned int)root->simple_rel_array_size; rti++)
{...}
root->total_table_pages = total_pages;
/* 准备开始主查询计划 */
final_rel = make_one_rel(root, joinlist);
final_rel->consider_parallel = consider_parallel;
...
/* 如果有分组子句,估计结果组数量 */
if (parse->groupClause) {...} /* 如果有分组子句,估计结果组数量 */
else if (parse->hasAggs||root->hasHavingQual||parse->groupingSets)
{...} /* 非分组聚集查询读取所有元组 */
else if (parse->distinctClause) {...} /* 非分组非聚集独立子句估计结果行数 */
else {...} /* 平凡非分组非聚集查询,计算绝对的元组比例 */
/* 计算代价整体最小路径和预排序的代价最小路径 */
cheapestpath = get_cheapest_path(root, final_rel, num_groups, has_groupby);
...
*cheapest_path = cheapestpath;
*sorted_path = sortedpath;
}
5. 查询执行——executor
执行器(executor)采用优化器创建的计划,并对其进行递归处理以提取所需的行的集合。这本质上是一种需求驱动的流水线执行机制,即每次调用一个计划节点时,它都必须再传送一行,或者报告已完成传送所有行。
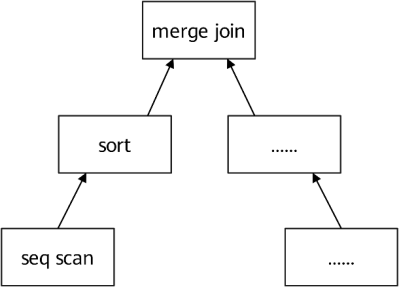
执行计划树示例
如上图所示的执行计划树示例,顶部节点是merge join节点。在进行任何合并操作之前,必须获取两个元组(merge join节点的两个子计划各返回1个元组)。因此,执行器以递归方式调用自身以处理其子计划(如从左子树的子计划开始)。merge join由于要做归并操作,因此它要子计划按序返回元组,从图1-5可以看出,它的子计划是一个sort节点。sort的子节点可能是seq scan节点,代表对表的实际读取。执行seq scan节点会使执行程序从表中获取一行并将其返回到调用节点。sort节点将反复调用其子节点以获得所有要排序的行。当输入完毕时(如子节点返回NULL而不是新行),sort算子对获取的元组进行排序,它每次返回1个元组,即已排序的第1行。然后不断排序并向父节点传递剩余的排好序的元组。
merge join节点类似地需要获得其右侧子计划中的第1个元组,看是否可以合并。如果是,它将向其调用方返回1个连接行。在下一次调用时,或者如果它不能连接当前输入对,则立即前进到1个表或另1个表的下一行(取决于比较的结果),然后再次检查是否匹配。最终,1个或另1个子计划用尽,并且merge join节点返回NULL,以指示无法再形成更多的连接行。
复杂的查询可能涉及多个级别的计划节点,但是一般方法是相同的:每个节点都会在每次调用时计算并返回其下一个输出行。每个节点还负责执行优化器分配给它的任何选择或投影表达式。
执行器机制用于执行所有4种基本SQL查询类型:SELECT、INSERT、UPDATE和DELETE。
(1) 对于SELECT,顶级执行程序代码仅需要将查询计划树返回的每一行发送给客户端。
(2) 对于INSERT,每个返回的行都插入INSERT指定的目标表中。这是在称为ModifyTable的特殊顶层计划节点中完成的。(1个简单的“INSERT ... VALUES”命令创建了1个简单的计划树,该树由单个Result节点组成,该节点仅计算一个结果行,并传递给ModifyTable树节点实现插入)。
(3) 对于UPDATE,优化器对每个计算的更新行附着所更新的列值,以及原始目标行的TID(tuple identifier,元组ID或行ID);此数据被馈送到ModifyTable节点,并使用该信息来创建新的更新行并标记旧行已删除。
(4) 对于DELETE,计划实际返回的唯一列是TID,而ModifyTable节点仅使用TID访问每个目标行并将其标记为已删除。
执行器的主要处理控制流程如下。
(1) 创建查询描述。
(2) 查询初始化:创建执行器状态(查询执行上下文)、执行节点初始化(创建表达式与每个元组上下文、执行表达式初始化)。
(3) 查询执行:执行处理节点(递归调用查询上下文、执行表达式,然后释放内存,重复操作)。
(4) 查询完成;执行未完成的表格修改节点。
(5) 查询结束:递归释放资源、释放查询及其子节点上下文。
(6) 释放查询描述。
1) executor源码组织
executor源码目录为:/src/gausskernel/runtime/executor。executor源码文件如下表所示。
表 executor源码文件
模块 | 源码文件 | 功能 |
executor | execAmi.cpp | 各种执行器访问方法 |
execClusterResize.cpp | 集群大小调整 | |
execCurrent.cpp | 支持WHERE CURRENT OF | |
execGrouping.cpp | 支持分组、哈希和聚集操作 | |
execJunk.cpp | 伪列的支持 | |
execMain.cpp | 顶层执行器接口 | |
execMerge.cpp | 处理MERGE指令 | |
execParallel.cpp | 支持并行执行 | |
execProcnode.cpp | 分发函数按节点调用相关初始化等函数 | |
execQual.cpp | 评估资质和目标列表的表达式 | |
execScan.cpp | 通用的关系扫描 | |
execTuples.cpp | 元组相关的资源管理 | |
execUtils.cpp | 多种执行相关工具函数 | |
functions.cpp | 执行SQL语言函数 | |
instrument.cpp | 计划执行工具 | |
lightProxy.cpp | 轻量级执行代理 | |
node*.cpp | 处理*相关节点操作的函数 | |
opfusion.cpp | 旁路执行器:处理简单查询 | |
spi.cpp | 服务器编程接口 | |
tqueue.cpp | 并行后端之间的元组信息传输 | |
tstoreReceiver.cpp | 存储结果元组 |
2) executor主流程
executor主流程代码为:
/* execMain.cpp */
...
/* 执行器启动 */
void ExecutorStart(QueryDesc *queryDesc, int eflags)
{
gstrace_entry(GS_TRC_ID_ExecutorStart);
if (ExecutorStart_hook) {
(*ExecutorStart_hook)(queryDesc, eflags);
} else {
standard_ExecutorStart(queryDesc, eflags);
}
gstrace_exit(GS_TRC_ID_ExecutorStart);
}
/* 执行器运行 */
void ExecutorRun(QueryDesc *queryDesc, ScanDirection direction, long count)
{
...
/* SQL 自调优: 查询执行完毕时,基于运行时信息分析查询计划问题 */
if (u_sess->exec_cxt.need_track_resource && queryDesc != NULL && has_track_operator &&(IS_PGXC_COORDINATOR || IS_SINGLE_NODE)) {
List *issue_results = PlanAnalyzerOperator(queryDesc, queryDesc->planstate);
/* 如果查询问题找到,存在系统视图 gs_wlm_session_history */
if (issue_results != NIL) {
RecordQueryPlanIssues(issue_results);
}
}
/* 查询动态特征, 操作历史统计信息 */
if (can_operator_history_statistics) {
u_sess->instr_cxt.can_record_to_table = true;
ExplainNodeFinish(queryDesc->planstate, queryDesc->plannedstmt, GetCurrentTimestamp(), false);
...
}
}
/* 执行器完成 */
void ExecutorFinish(QueryDesc *queryDesc)
{
if (ExecutorFinish_hook) {
(*ExecutorFinish_hook)(queryDesc);
} else {
standard_ExecutorFinish(queryDesc);
}
}
/* 执行器结束 */
void ExecutorEnd(QueryDesc *queryDesc)
{
if (ExecutorEnd_hook) {
(*ExecutorEnd_hook)(queryDesc);
} else {
standard_ExecutorEnd(queryDesc);
}
}
三、存储引擎
openGauss存储引擎支持多个存储引擎来满足不同场景的业务诉求,目前支持行存储引擎、列存储引擎和内存引擎。
早期计算机程序通过文件系统管理数据,到了20世纪60年代这种方式就开始不能满足数据管理要求了,用户逐渐对数据并发写入的完整性、高效检索提出更高的要求。由于机械磁盘的随机读写性能问题,从20世纪80年代开始,大多数数据库一直在围绕着减少随机读写磁盘进行设计。主要思路是把对数据页面的随机写盘转换为对WAL(write ahead log,预写式日志)的顺序写盘,WAL持久化完成,事务就算提交成功,数据页面异步刷盘。但是随着内存容量变大、保电内存、非易失性内存的发展,以及SSD技术逐渐地成熟,I/O性能极大提高,经历了几十年发展的存储引擎需要调整架构来发挥SSD的性能和充分利用大内存计算的优势。随着互联网、移动互联网的发展,数据量剧增,业务场景多样化,一套固定不变的存储引擎不可能满足所有应用场景的诉求。因此现在的DBMS(database management system,数据库管理系统)需要设计支持多种存储引擎,根据业务场景来选择合适的存储模型。
1. 数据库存储引擎要解决的问题
(1) 存储的数据必须要保证ACID:原子性(atomicity)、一致性(consistency)、隔离性(isolation)、持久性(durability)。
(2) 高并发读写,高性能。
(3) 数据高效存储和检索能力。
2. openGauss存储引擎概述
openGauss整个系统设计支持多个存储引擎来满足不同场景的业务诉求。当前openGauss存储引擎有以下3种:
(1) 行存储引擎。主要面向OLTP(online transaction processing,在线交易处理)场景设计,例如订货发货,银行交易系统。
(2) 列存储引擎。主要面向OLAP场景设计,例如数据统计报表分析。
(3) 内存引擎。主要面向极致性能场景设计,例如银行风控场景。
创建表的时候可以指定行存储引擎表、列存储引擎表、内存引擎表,支持一个事务里包含对3种引擎表的DML(Data Manipulation Language,数据操作语言)操作,可以保证事务ACID。
1) storage源码组织
storage源码目录为:/src/gausskernel/storage。storage源码文件如表所示。
表 storage源码文件
模块 | 源码文件 | 功能 |
storage | access | 基础行存储引擎方法 |
cbtree | ||
hash | ||
heap | ||
index | ||
... | ||
buffer | 缓冲区 | |
freespace | 空闲空间管理 | |
ipc | 进程内交互 | |
large_object | 大对象处理 | |
remote | 远程读 | |
replication | 复制备份 | |
smgr | 存储管理 | |
cmgr | 公共缓存方法 | |
cstore | 列存储引擎 | |
dfs | 分布式文件系统 | |
file | 文件类 | |
lmgr | 锁管理 | |
mot | 内存引擎 | |
page | 数据页 |
2) storage主流程
storage主流程代码如下:
/* smgr/smgr.cpp, 存储管理 */
...
/* 存储管理函数列表,包含磁盘初始化、开关、同步等操作函数 */
static const f_smgr g_smgrsw[] = {
/* 磁盘*/
{mdinit,
NULL,
mdclose,
mdcreate,
mdexists,
mdunlink,
mdextend,
mdprefetch,
mdread,
mdwrite,
mdwriteback,
mdnblocks,
mdtruncate,
mdimmedsync,
mdpreckpt,
mdsync,
mdpostckpt,
mdasyncread,
mdasyncwrite}};
/*
* 存储管理初始化
* 当服务器后端启动时调用
*/
void smgrinit(void)
{
int i;
/* 初始化所有存储相关管理器 */
for (i = 0; i < SMGRSW_LENGTH; i++) {
if (g_smgrsw[i].smgr_init) {
(*(g_smgrsw[i].smgr_init))();
}
}
/* 登记存储管理终止程序 */
if (!IS_THREAD_POOL_SESSION) {
on_proc_exit(smgrshutdown, 0);
}
}
/*
* 当后端服务关闭时,执行存储管理关闭代码
*/
static void smgrshutdown(int code, Datum arg)
{
int i;
/* 关闭所有存储关联服务 */
for (i = 0; i < SMGRSW_LENGTH; i++) {
if (g_smgrsw[i].smgr_shutdown) {
(*(g_smgrsw[i].smgr_shutdown))();
}
}
}
3. 行存储引擎
openGauss的行存储引擎设计上支持MVCC(multi-version concurrency control,多版本并发控制),采用集中式垃圾版本回收机制,可以提供OLTP业务系统的高并发读写要求。架构如图所示。
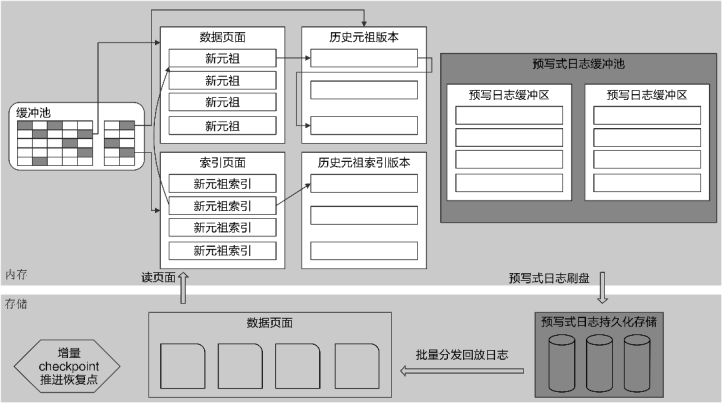
行存储架构
行存储引擎的关键技术有:
(1) 基于CSN(commit sequence number,待提交事务的序列号,它是一个64位递增无符号数)的MVCC并发控制机制,进行集中式垃圾数据清理。
(2) 并行刷新日志,并行恢复。传统数据库一般都采用串行刷日志的设计,因为日志有顺序依赖关系,例如一个由事务产生的redo/undo log是有前后依赖关系的。openGauss的日志系统采用多个logwriter线程并行写的机制,充分发挥SSD的多通道I/O能力。
(3) 基于大内存设计的缓冲管理器。
行存储缓冲区主流程代码如下:
/* buffer/bufmgr.cpp, 基础行存储管理 */
...
/* 查找或创建一个缓冲区 */
Buffer ReadBufferExtended(
Relation reln, ForkNumber fork_num, BlockNumber block_num, ReadBufferMode mode, BufferAccessStrategy strategy)
{
bool hit = false;
Buffer buf;
if (block_num == P_NEW) {
STORAGE_SPACE_OPERATION(reln, BLCKSZ);
}
/* 以smgr(存储管理器)级别打开一个缓冲区 */
RelationOpenSmgr(reln);
/* 拒绝读取非局部临时关系的请求,因为可能会获得监控不到的错误数据 */
if (RELATION_IS_OTHER_TEMP(reln) && fork_num <= INIT_FORKNUM)
ereport(ERROR,
(errcode(ERRCODE_FEATURE_NOT_SUPPORTED), errmsg("cannot access temporary tables of other sessions")));
/* 读取缓冲区,更新统计信息数量反馈缓存命中与否情况 */
pgstat_count_buffer_read(reln);
pgstatCountBlocksFetched4SessionLevel();
buf = ReadBuffer_common(reln->rd_smgr, reln->rd_rel->relpersistence, fork_num, block_num, mode, strategy, &hit);
if (hit) {
pgstat_count_buffer_hit(reln);
}
return buf;
}
/* 释放一个缓冲区 */
void ReleaseBuffer(Buffer buffer)
{
BufferDesc* buf_desc = NULL;
PrivateRefCountEntry* ref = NULL;
/* 错误释放处理 */
if (!BufferIsValid(buffer)) {
ereport(ERROR, (errcode(ERRCODE_INVALID_BUFFER), (errmsg("bad buffer ID: %d", buffer))));
}
ResourceOwnerForgetBuffer(t_thrd.utils_cxt.CurrentResourceOwner, buffer);
if (BufferIsLocal(buffer)) {
Assert(u_sess->storage_cxt.LocalRefCount[-buffer - 1] > 0);
u_sess->storage_cxt.LocalRefCount[-buffer - 1]--;
return;
}
/* 释放当前缓冲区 */
buf_desc = GetBufferDescriptor(buffer - 1);
PrivateRefCountEntry *free_entry = NULL;
ref = GetPrivateRefCountEntryFast(buffer, free_entry);
if (ref == NULL) {
ref = GetPrivateRefCountEntrySlow(buffer, false, false, free_entry);}
Assert(ref != NULL);
Assert(ref->refcount > 0);
if (ref->refcount > 1) {
ref->refcount--;
} else {
UnpinBuffer(buf_desc, false);
}
}
/* 标记写脏缓冲区 */
void MarkBufferDirty(Buffer buffer)
{
BufferDesc* buf_desc = NULL;
uint32 buf_state;
uint32 old_buf_state;
if (!BufferIsValid(buffer)) {
ereport(ERROR, (errcode(ERRCODE_INVALID_BUFFER), (errmsg("bad buffer ID: %d", buffer))));}
if (BufferIsLocal(buffer)) {
MarkLocalBufferDirty(buffer);
return;
}
buf_desc = GetBufferDescriptor(buffer - 1);
Assert(BufferIsPinned(buffer));
Assert(LWLockHeldByMe(buf_desc->content_lock));
old_buf_state = LockBufHdr(buf_desc);
buf_state = old_buf_state | (BM_DIRTY | BM_JUST_DIRTIED);
/* 将未入队的脏页入队 */
if (g_instance.attr.attr_storage.enableIncrementalCheckpoint) {
for (;;) {
buf_state = old_buf_state | (BM_DIRTY | BM_JUST_DIRTIED);
if (!XLogRecPtrIsInvalid(pg_atomic_read_u64(&buf_desc->rec_lsn))) {
break;
}
if (!is_dirty_page_queue_full(buf_desc) && push_pending_flush_queue(buffer)) {
break;
}
UnlockBufHdr(buf_desc, old_buf_state);
pg_usleep(TEN_MICROSECOND);
old_buf_state = LockBufHdr(buf_desc);
}
}
UnlockBufHdr(buf_desc, buf_state);
/* 如果缓冲区不是“脏”状态,则更新相关计数 */
if (!(old_buf_state & BM_DIRTY)) {
t_thrd.vacuum_cxt.VacuumPageDirty++;
u_sess->instr_cxt.pg_buffer_usage->shared_blks_dirtied++;
pgstatCountSharedBlocksDirtied4SessionLevel();
if (t_thrd.vacuum_cxt.VacuumCostActive) {
t_thrd.vacuum_cxt.VacuumCostBalance += u_sess->attr.attr_storage.VacuumCostPageDirty;
}
}
}
4. 列存储引擎
传统行存储数据压缩率低,必须按行读取,即使读取一列也必须读取整行。openGauss创建表的时候,可以指定行存储还是列存储。列存储表也支持DML操作和MVCC。列存储架构如图所示。
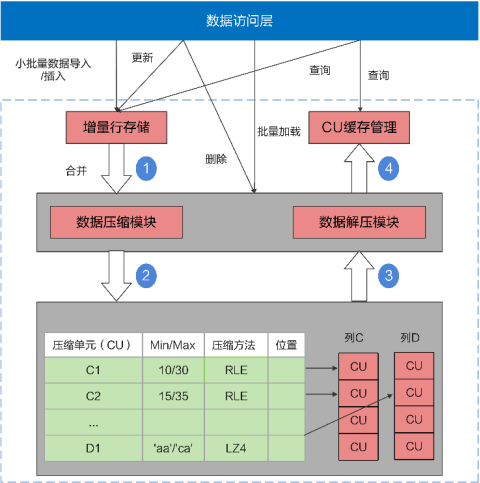
列存储架构
列存储引擎有以下优势:
(1) 列的数据特征比较相似,适合压缩,压缩比很高。
(2) 当表列的个数比较多,但是访问的列个数比较少时,列存储可以按需读取列数据,大大减少不必要的读I/O开支,提高查询性能。
(3) 基于列批量数据Vector(向量)的运算,CPU的缓存命中率比较高,性能比较好。列存储引擎更适合OLAP大数据统计分析的场景。
1) 列存储源码组织
列存储源码目录为:/src/gausskernel/storage/cstore。列存储源码文件如表所示。
表 列存储源码文件
模块 | 源码文件 | 功能 |
cstore | compression | 数据压缩与解压 |
cstore_allocspace | 空间分配 | |
cstore_am | 列存储公共API(application programming interface,应用编程接口) | |
cstore_***_func | 支持函数 | |
cstore_psort | 列内排序 | |
cu | 数据压缩单元 | |
cucache_mgr | 缓存管理器 | |
custorage | 持久化存储 | |
cstore_delete | 删除方法 | |
cstore_update | 更新方法 | |
cstore_vector | 缓冲区实现 | |
cstore_rewrite | SQL重写 | |
cstore_insert | 插入方法 | |
cstore_mem_alloc | 内存分配 |
2) 列存储主要API
列存储主要API代码如下:
/* cstore_am.cpp */
...
/* 扫描 APIs */
void InitScan(CStoreScanState *state, Snapshot snapshot = NULL);
void InitReScan();
void InitPartReScan(Relation rel);
bool IsEndScan() const;
/* 延迟读取APIs */
bool IsLateRead(int id) const;
void ResetLateRead();
/* 更新列存储扫描计时标记*/
void SetTiming(CStoreScanState *state);
/* 列存储扫描*/
void ScanByTids(_in_ CStoreIndexScanState *state, _in_ VectorBatch *idxOut, _out_ VectorBatch *vbout);
void CStoreScanWithCU(_in_ CStoreScanState *state, BatchCUData *tmpCUData, _in_ bool isVerify = false);
/* 加载数据压缩单元描述信息 */
bool LoadCUDesc(_in_ int col, __inout LoadCUDescCtl *loadInfoPtr, _in_ bool prefetch_control, _in_ Snapshot snapShot = NULL);
/* 从描述表中获取数据压缩单元描述*/
bool GetCUDesc(_in_ int col, _in_ uint32 cuid, _out_ CUDesc *cuDescPtr, _in_ Snapshot snapShot = NULL);
/* 获取元组删除信息*/
void GetCUDeleteMaskIfNeed(_in_ uint32 cuid, _in_ Snapshot snapShot);
bool GetCURowCount(_in_ int col, __inout LoadCUDescCtl *loadCUDescInfoPtr, _in_ Snapshot snapShot);
/* 获取实时行号。 */
int64 GetLivedRowNumbers(int64 *deadrows);
/* 获得数据压缩单元*/
CU *GetCUData(_in_ CUDesc *cuDescPtr, _in_ int colIdx, _in_ int valSize, _out_ int &slotId);
CU *GetUnCompressCUData(Relation rel, int col, uint32 cuid, _out_ int &slotId, ForkNumber forkNum = MAIN_FORKNUM,
bool enterCache = true) const;
/* 缓冲向量填充 APIs */
int FillVecBatch(_out_ VectorBatch *vecBatchOut);
/* 填充列向量*/
template
int FillVector(_in_ int colIdx, _in_ CUDesc *cu_desc_ptr, _out_ ScalarVector *vec);
template
void FillVectorByTids(_in_ int colIdx, _in_ ScalarVector *tids, _out_ ScalarVector *vec);
template
void FillVectorLateRead(_in_ int seq, _in_ ScalarVector *tids, _in_ CUDesc *cuDescPtr, _out_ ScalarVector *vec);
void FillVectorByIndex(_in_ int colIdx, _in_ ScalarVector *tids, _in_ ScalarVector *srcVec, _out_ ScalarVector *destVec);
/* 填充系统列*/
int FillSysColVector(_in_ int colIdx, _in_ CUDesc *cu_desc_ptr, _out_ ScalarVector *vec);
template
void FillSysVecByTid(_in_ ScalarVector *tids, _out_ ScalarVector *destVec);
template
int FillTidForLateRead(_in_ CUDesc *cuDescPtr, _out_ ScalarVector *vec);
void FillScanBatchLateIfNeed(__inout VectorBatch *vecBatch);
/* 设置数据压缩单元范围以支持索引扫描 */
void SetScanRange();
/* 判断行是否可用*/
bool IsDeadRow(uint32 cuid, uint32 row) const;
void CUListPrefetch();
void CUPrefetch(CUDesc *cudesc, int col, AioDispatchCUDesc_t **dList, int &count, File *vfdList);
/* 扫描函数 */
typedef void (CStore::*ScanFuncPtr)(_in_ CStoreScanState *state, _out_ VectorBatch *vecBatchOut);
void RunScan(_in_ CStoreScanState *state, _out_ VectorBatch *vecBatchOut);
int GetLateReadCtid() const;
void IncLoadCuDescCursor();
5. 内存引擎
openGauss引入了MOT(memory-optimized table,内存优化表)存储引擎,它是一种事务性行存储,针对多核和大内存服务器进行了优化。MOT是openGauss数据库出色的生产级特性(Beta版本),它为事务性工作负载提供更高的性能。MOT完全支持ACID,并包括严格的持久性和高可用性支持。企业可以在关键任务、性能敏感的在线事务处理(OLTP)中使用MOT,以实现高性能、高吞吐、可预测的低延迟以及多核服务器的高利用率。MOT尤其适合在多路和多核处理器的现代服务器上运行,例如基于ARM(advanced RISC machine,高级精简指令集计算机器)/鲲鹏处理器的华为TaiShan服务器,以及基于x86的戴尔或类似服务器。MOT存储引擎如图所示。
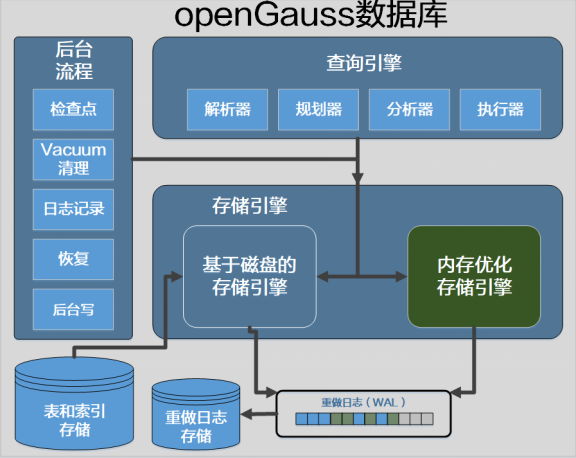
MOT存储引擎
MOT与基于磁盘的普通表并排创建。MOT的有效设计实现了几乎完全的SQL覆盖,并且支持完整的数据库功能集,如存储过程和自定义函数。通过完全存储在内存中的数据和索引、非统一内存访问感知(NUMA-aware)设计、消除锁和锁存争用的算法以及查询原生编译,MOT可提供更快的数据访问和更高效的事务执行。MOT有效的几乎无锁的设计和高度调优的实现,使其在多核服务器上实现了卓越的近线性吞吐量扩展。
MOT的高性能(查询和事务延迟)、高可扩展性(吞吐量和并发量)等特点,在某些情况下低成本(高资源利用率)方面拥有显著优势。
(1) 低延迟(low latency):提供快速的查询和事务响应时间。
(2) 高吞吐量(high throughput):支持峰值和持续高用户并发。
(3) 高资源利用率(high resource utilization):充分利用硬件。
MOT的关键技术如下。
(1) 内存优化数据结构:以实现高并发吞吐量和可预测的低延迟为目标,所有数据和索引都在内存中,不使用中间页缓冲区,并使用持续时间最短的锁。数据结构和所有算法都是专门为内存设计而优化的。
(2) 免锁事务管理:MOT在保证严格一致性和数据完整性的前提下,采用乐观的策略实现高并发和高吞吐。在事务过程中,MOT不会对正在更新的数据行的任何版本加锁,从而大大降低了一些大内存系统中的争用。
(3) 免锁索引:由于内存表的数据和索引完全存储在内存中,因此拥有一个高效的索引数据结构和算法非常重要。MOT索引机制基于领域前沿的树结构Masstree,它是一种用于多核系统的快速和可扩展的键值(key value,KV)存储索引,以B+树的Trie组织形式实现。通过这种方式,高并发工作负载在多核服务器上可以获得卓越的性能。同时MOT应用了各种先进的技术以优化性能,如优化锁方法、高速缓存感知和内存预取。
(4) NUMA-aware的内存管理:MOT内存访问的设计支持非统一内存访问(NUMA,non-uniform memory access)感知。NUMA-aware算法增强了内存中数据布局的性能,使线程访问物理上连接到线程运行的核心的内存。这是由内存控制器处理的,不需要通过使用互连(如英特尔QPI(quick path interconnect,快速路径互连))进行额外的跳转。MOT的智能内存控制模块,为各种内存对象预先分配了内存池,提高了性能、减少了锁、保证了稳定性。
(5) 高效持久性:日志和检查点是实现磁盘持久化的关键能力,也是ACID的关键要求之一。目前所有的磁盘(包括SSD和NVMe(non-volatile memory express,非易失性高速传输总线))都明显慢于内存,因此持久化是基于内存数据库引擎的瓶颈。作为一个基于内存的存储引擎,MOT的持久化设计必须实现各种各样的算法优化,以确保持久化的同时还能达到设计时的速度和吞吐量目标。
(6) 高SQL覆盖率和功能集:MOT通过扩展的openGauss外部数据封装(foreign data wrapper,FDW)以及索引,几乎支持完整的SQL范围,包括存储过程、用户定义函数和系统函数调用。
(7) 使用PREPARE语句的查询原生编译:通过使用PREPARE客户端命令,可以以交互方式执行查询和事务语句。这些命令已被预编译成原生执行格式,也称为Code-Gen或即时(just-in-time,JIT)编译。这样可以实现平均30%的性能提升。
(8) MOT和openGauss数据库的无缝集成:MOT是一个高性能的面向内存优化的存储引擎,已集成在openGauss软件包中。MOT的主内存引擎和基于磁盘的存储引擎并存,以支持多种应用场景,同时在内部重用数据库辅助服务,如WAL重做日志、复制、检查点和恢复高可用性等。
1) 内存引擎源码组织
内存引擎源码目录为:/src/gausskernel/storage/mot。内存引擎源码文件如表所示。
表 内存引擎源码文件
模块 | 源码文件 | 功能 |
mot | concurrency_control | 并发控制管理 |
infra | 辅助与配置函数 | |
memory | 内存数据管理 | |
storage | 持久化存储 | |
system | 全局控制API | |
utils | 日志等通用方法 |
2) 内存引擎主流程
内存引擎主流程代码如下:
/* system/mot_engine.cpp */
...
/* 创建内存引擎实例 */
MOTEngine* MOTEngine::CreateInstance(
const char* configFilePath /* = nullptr */, int argc /* = 0 */, char* argv[] /* = nullptr */)
{
if (m_engine == nullptr) {
if (CreateInstanceNoInit(configFilePath, argc, argv) != nullptr) {
bool result = m_engine->LoadConfig();
if (!result) {
MOT_REPORT_ERROR(MOT_ERROR_INTERNAL, "System Startup", "Failed to load Engine configuration");
} else {
result = m_engine->Initialize();
if (!result) {
MOT_REPORT_ERROR(MOT_ERROR_INTERNAL, "System Startup", "Engine initialization failed");
}
}
if (!result) {
DestroyInstance();
MOT_ASSERT(m_engine == nullptr);
}
}
}
return m_engine;
}
/* 内存引擎初始化 */
bool MOTEngine::Initialize()
{
bool result = false;
/* 初始化应用服务,开始后台任务 */
do { // instead of goto
m_initStack.push(INIT_CORE_SERVICES_PHASE);
result = InitializeCoreServices();
CHECK_INIT_STATUS(result, "Failed to Initialize core services");
m_initStack.push(INIT_APP_SERVICES_PHASE);
result = InitializeAppServices();
CHECK_INIT_STATUS(result, "Failed to Initialize applicative services");
m_initStack.push(START_BG_TASKS_PHASE);
result = StartBackgroundTasks();
CHECK_INIT_STATUS(result, "Failed to start background tasks");
} while (0);
if (result) {
MOT_LOG_INFO("Startup: MOT Engine initialization finished successfully");
m_initialized = true;
} else {
MOT_LOG_PANIC("Startup: MOT Engine initialization failed!");
/* 调用方应在失败后调用DestroyInstance() */
}
return result;
}
/* 销毁内存引擎实例 */
void MOTEngine::Destroy()
{
MOT_LOG_INFO("Shutdown: Shutting down MOT Engine");
while (!m_initStack.empty()) {
switch (m_initStack.top()) {
case START_BG_TASKS_PHASE:
StopBackgroundTasks();
break;
case INIT_APP_SERVICES_PHASE:
DestroyAppServices();
break;
case INIT_CORE_SERVICES_PHASE:
DestroyCoreServices();
break;
case LOAD_CFG_PHASE:
break;
case INIT_CFG_PHASE:
DestroyConfiguration();
break;
default:
break;
}
m_initStack.pop();
}
ClearErrorStack();
MOT_LOG_INFO("Shutdown: MOT Engine shutdown finished");
}
