




PostgreSQL 索引 opclass 和 opfamily 以及索引使用判断标准解析
概述
对于一个具体的类型,如果要能够正常使用索引,除了需要定义对应的比较操作符,PostgreSQL(后续简称 PG)中还要求添加额外的信息。这些额外信息就是 PG 中的 opclass 和 opfamily,而具体的实现的元信息是由一系列系统表记录。本文主要介绍了opclass 和 opfamily 的功能和联系,然后给出了具体组织系统表之间的架构,最后给出了使用索引的判断标准。(后续分析均来自 PG 14.13 版本)
背景
Access Method (访问方法, AM)是 PG 的一个重要组成部分,它定义了表的存储(heap)和检索(index)方式。PG 中最常见的 AM 就是索引,例如 B-tree、Hash、Gin 等索引分别表示一种 AM。pg_am 系统表中的一行记录对应着 PostgreSQL 支持的一种 AM。
为了更加通用, AM 中 amhandler
函数会生成一个 IndexAMRoutine 类型结构,它包含内核使用该索引访问方法所需的所有信息(通用接口)。IndexAmRoutine
结构(也被称为AM 的API 结构)中的域指定了访问方法的各种固定性质:
/*
* API struct for an index AM. Note this must be stored in a single palloc'd
* chunk of memory.
*/
typedef struct IndexAmRoutine
{
NodeTag type;
/*
* Total number of strategies (operators) by which we can traverse/search
* this AM. Zero if AM does not have a fixed set of strategy assignments.
*/
uint16 amstrategies;
/* total number of support functions that this AM uses */
uint16 amsupport;
/* opclass options support function number or 0 */
uint16 amoptsprocnum;
/* does AM support ORDER BY indexed column's value? */
bool amcanorder;
/* does AM support ORDER BY result of an operator on indexed column? */
bool amcanorderbyop;
/* does AM support backward scanning? */
bool amcanbackward;
/* does AM support UNIQUE indexes? */
bool amcanunique;
/* does AM support multi-column indexes? */
bool amcanmulticol;
/* does AM require scans to have a constraint on the first index column? */
bool amoptionalkey;
/* does AM handle ScalarArrayOpExpr quals? */
bool amsearcharray;
/* does AM handle IS NULL/IS NOT NULL quals? */
bool amsearchnulls;
/* can index storage data type differ from column data type? */
bool amstorage;
/* can an index of this type be clustered on? */
bool amclusterable;
/* does AM handle predicate locks? */
bool ampredlocks;
/* does AM support parallel scan? */
bool amcanparallel;
/* does AM support columns included with clause INCLUDE? */
bool amcaninclude;
/* does AM use maintenance_work_mem? */
bool amusemaintenanceworkmem;
/* OR of parallel vacuum flags. See vacuum.h for flags. */
uint8 amparallelvacuumoptions;
/* type of data stored in index, or InvalidOid if variable */
Oid amkeytype;
/*
* If you add new properties to either the above or the below lists, then
* they should also (usually) be exposed via the property API (see
* IndexAMProperty at the top of the file, and utils/adt/amutils.c).
*/
/* interface functions */
ambuild_function ambuild;
ambuildempty_function ambuildempty;
aminsert_function aminsert;
ambulkdelete_function ambulkdelete;
amvacuumcleanup_function amvacuumcleanup;
amcanreturn_function amcanreturn; /* can be NULL */
amcostestimate_function amcostestimate;
amoptions_function amoptions;
amproperty_function amproperty; * can be NULL */
ambuildphasename_function ambuildphasename; * can be NULL */
amvalidate_function amvalidate;
amadjustmembers_function amadjustmembers; /* can be NULL */
ambeginscan_function ambeginscan;
amrescan_function amrescan;
amgettuple_function amgettuple; * can be NULL */
amgetbitmap_function amgetbitmap; /* can be NULL */
amendscan_function amendscan;
ammarkpos_function ammarkpos; /* can be NULL */
amrestrpos_function amrestrpos; * can be NULL */
/* interface functions to support parallel index scans */
amestimateparallelscan_function amestimateparallelscan; * can be NULL */
aminitparallelscan_function aminitparallelscan; * can be NULL */
amparallelrescan_function amparallelrescan; * can be NULL */
} IndexAmRoutine;
每个 AM 需要根据自己的需求去实现这些接口的行为。
有关 AM API 更详细的介绍可以参考官方文档相关介绍。针对某个具体的表上索引,PG 提供了_pg_index_column_has_property()_
等函数来查询索引相关的性质。
对于索引 AM,如果想被不同类型真正地使用,它还必须拥有一个或者多个相应的 opfamily (操作符族)和 opclass (操作符类),这些项的元信息记录在 pg_opfamily,pg_opclass,pg_amop 和 pg_amproc 系统表中,被用于****优化器判断哪种查询条件适用于这个索引访问方法的索引。
opclass 和 opfamily
为了让后面的内容更容易被理解,在介绍 opclass 的 opfamily 之前,我先强调一些它们区别和联系:
一个 opclass 只针对一种类型,不会有多种类型出现;而一个 opfamily 可能会包含多个 opclass,可以包含多种类型。
一个 opclass 的成员是一个整体,只能整体创建和删除,不能通过修改(ALTER)操作添加和删除;而 opfamily 可以通过修改操作动态修改成员。
一个 opclass 必须属于一个 opfamily ,创建 opclass 时如果没有指定会默认创建一个同名的 opfamily。
实际使用中,只有在创建索引时指定(CREATE INDEX)会使用 opclass,判断是否能走索引时,都是使用 opclass 所在的 opfamily。
opclass(操作符类)
一个 opclass (操作符类)定义了用于某个 AM 的一种特定数据类型的一组操作。
之所以被称为 opclass 是因为它包含的主要内容 就是可以被用于一个 AM 的
WHERE-clause
操作符集合(即,能被转换成一个索引扫描条件,e.g. where t1.a <= 1 中的 '<=' ),称为可索引的操作符集合( indexable operators set)。一个 opclass 也能指定一些 AM 内部操作所需的
support function
,这些函数不能被用于索引的任何WHERE-clause
操作符替代。
我门可以为一个数据类型的同一个索引方法定义多个 opclass。其中最常用的一个 opclass 会被标记为 default opclass,作为这个类型在一个 AM 下的默认 opclass。通过这种方式,我们可以为一种数据类型定义多个索引语义集合。例如,对一种复数数据类型来说,拥有一个可以根据复数绝对值排序的 B-tree opclass 和另一个可以根据实数部分排序的 opclass 可能会很有用。
相同的 opclass 名称可以被用于多个不同的索引方法(例如,B-tree 和 Hash 方法都有名为date_ops
的操作符类)。但是每一个这样的 opclass 都是一个独立实体并且必须被单独定义。
AM 的 strategy 与 support function
opclass(以及后面的 opfamily )中的操作符对应 AM 具体的 strategy(策略),函数对应 AM 具体的 support function(支持函数)。这就是 AM 定义的两个概念,我们记住即可,看个最常见的例子。
B-tree AM 定义了 5 种策略:
B-tree AM 定义了 5 种支持函数:
B-tree AM 的策略和支持函数更详细的介绍可以参考B-tree 文档,__其它 AM 信息请参考AM 介绍文档。
以 int4 支持 B-tree 索引定义int4_ops
opclass 为例,假设用 SQL 定义,可以写为:
CREATE OPERATOR CLASS int4_ops
DEFAULT FOR TYPE int4 USING btree FAMILY integer_ops AS
-- operator set (strategies)
OPERATOR 1 <(int4, int4) ,
OPERATOR 2 <=(int4, int4) ,
OPERATOR 3 =(int4, int4) ,
OPERATOR 4 >=(int4, int4) ,
OPERATOR 5 >(int4, int4) ,
-- support functions
FUNCTION 1 btint4cmp(int4, int4) ,
FUNCTION 2 btint4sortsupport(internal) ,
FUNCTION 3 in_range(int4, int4, int4, boolean, boolean) ,
FUNCTION 4 btequalimage(oid) ;
opfamily (操作符族)
上面 int4 的例子中不仅有int4_ops
opclass,还有integer_ops
opfamily。它们之间的联系和区别是什么呢?
在介绍 opclass 中,始终强调了是针对 一种特定类型,所以可以认为 opclass是与类型绑定的。但是存在两类需求:
虽然在一个特定的索引列中必定只有一种数据类型,但是索引列与一种不同数据类型的值比较的场景也很常见。
此外,如果几种数据类型比较“相似”(相互之间的比较满足一定的条件),它们之间能够建立起明确的联系可能会很有用,因为这可以帮助规划器进行 SQL 查询优化(尤其是对于 B-树操作符类,因为规划器包含了大量有关如何使用它们的知识)。
为了处理这些需求,PostgreSQL使用了 opfamily 的概念。opfamily 包含一个或者多个 opclass,并且也能包含属于该 opfamily 而不属于其中任何单一 opclass 的可索引操作符和相应的支持函数。我们说这样的操作符和函数是“松散”地存在于该opfamily 中,而不是被绑定在一个特定的 opclass 中。通常每个 opclass 包含单一数据类型的操作符,而跨数据类型操作符则“松散”地存在于 opfamily 中。
注意一个 opfamily 中的所有操作符和函数必须具有兼容的语义,其中的兼容性要求由索引方法设定。PG 为什么要这么麻烦地把 opfamily 的特定子集单另出来成为 opclass,并且实际上(由于很多原因)这种划分与操作符之间没有什么直接的关联,只有 opfamily 才是实际的分组。PG 给出的解释是:定义 opclass 的原因是它们指定了特定索引对操作符族的依赖程度。如果一个索引使用着一个 opclass,那么不删除该索引是不能删除该 opclass 的,但是 opfamily 的其他部分(即其他 opclass 和“松散”的操作符)可以被删除。因此,一个 opclass 应该包含一个索引在特定数据类型上正常工作所需要的最小操作符和函数集合,而相关但不关键的操作符可以作为 opfamily 的“松散”成员被加入。
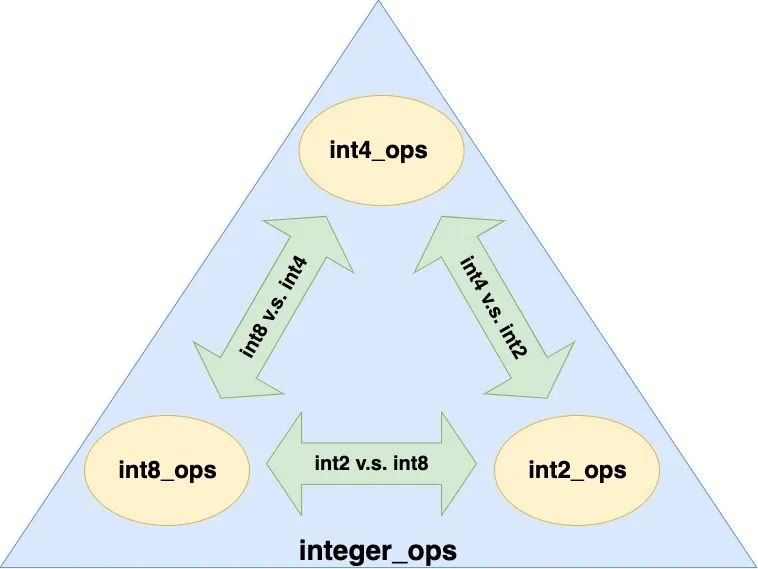
相应地,再次以 int2 int4 int8 支持 B-tree 索引能够相互关联为例,不同类型交互的 SQL 可以写为:
ALTER OPERATOR FAMILY integer_ops USING btree ADD
-- cross-type comparisons int8 vs int2
OPERATOR 1 < (int8, int2) ,
OPERATOR 2 <= (int8, int2) ,
OPERATOR 3 = (int8, int2) ,
OPERATOR 4 >= (int8, int2) ,
OPERATOR 5 > (int8, int2) ,
FUNCTION 1 btint82cmp(int8, int2) ,
-- cross-type comparisons int8 vs int4
OPERATOR 1 < (int8, int4) ,
OPERATOR 2 <= (int8, int4) ,
OPERATOR 3 = (int8, int4) ,
OPERATOR 4 >= (int8, int4) ,
OPERATOR 5 > (int8, int4) ,
FUNCTION 1 btint84cmp(int8, int4) ,
-- cross-type comparisons int4 vs int2
OPERATOR 1 < (int4, int2) ,
OPERATOR 2 <= (int4, int2) ,
OPERATOR 3 = (int4, int2) ,
OPERATOR 4 >= (int4, int2) ,
OPERATOR 5 > (int4, int2) ,
FUNCTION 1 btint42cmp(int4, int2) ,
-- cross-type comparisons int4 vs int8
OPERATOR 1 < (int4, int8) ,
OPERATOR 2 <= (int4, int8) ,
OPERATOR 3 = (int4, int8) ,
OPERATOR 4 >= (int4, int8) ,
OPERATOR 5 > (int4, int8) ,
FUNCTION 1 btint48cmp(int4, int8) ,
-- cross-type comparisons int2 vs int8
OPERATOR 1 < (int2, int8) ,
OPERATOR 2 <= (int2, int8) ,
OPERATOR 3 = (int2, int8) ,
OPERATOR 4 >= (int2, int8) ,
OPERATOR 5 > (int2, int8) ,
FUNCTION 1 btint28cmp(int2, int8) ,
-- cross-type comparisons int2 vs int4
OPERATOR 1 < (int2, int4) ,
OPERATOR 2 <= (int2, int4) ,
OPERATOR 3 = (int2, int4) ,
OPERATOR 4 >= (int2, int4) ,
OPERATOR 5 > (int2, int4) ,
FUNCTION 1 btint24cmp(int2, int4) ,
-- cross-type in_range functions
FUNCTION 3 in_range(int4, int4, int8, boolean, boolean) ,
FUNCTION 3 in_range(int4, int4, int2, boolean, boolean) ,
FUNCTION 3 in_range(int2, int2, int8, boolean, boolean) ,
FUNCTION 3 in_range(int2, int2, int4, boolean, boolean) ;
综合 opclass 和 opfamily 的 case,我们可以得到 B-tree interger_ops opfamily 成员关系图:
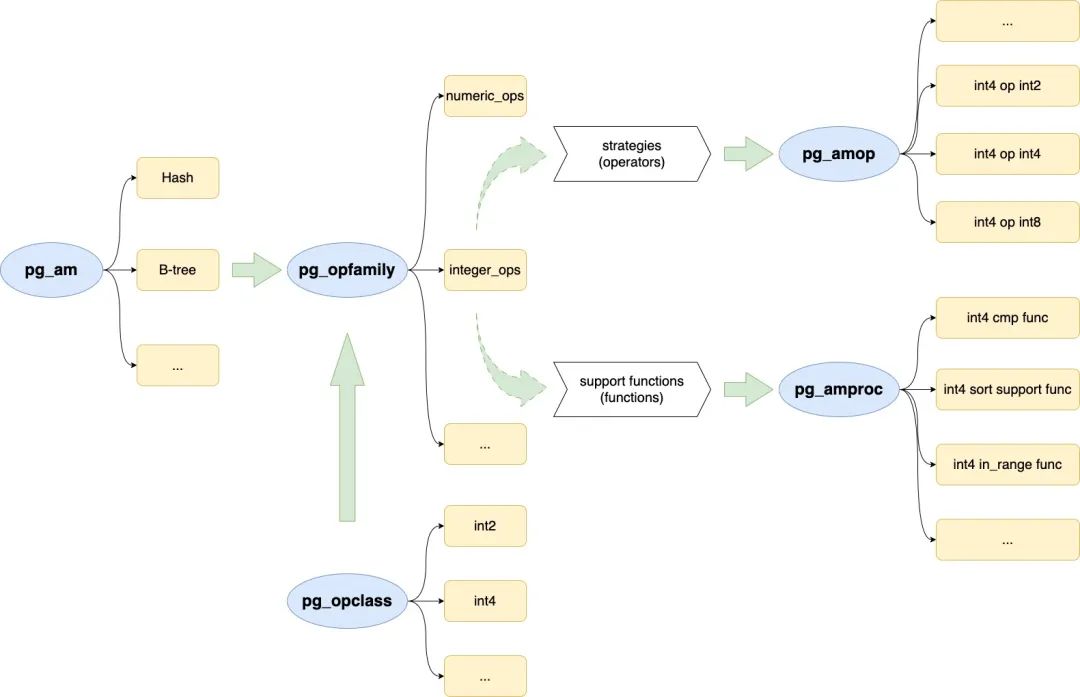
pg_am / pg_opfamily / pg_opclass / pg_amop / pg_amproc 之间的关系
PG 具体实现 opclass 和 opfamily 时,利用了多张系统表来记录元信息,包括 pg_am、pg_opfamily、pg_opclass,pg_amop 和 pg_amproc。每张系统表的具体作用可以参考官方文档,这里不再赘述。下面将给出这些系统表之间的框架图,帮助理解它们之间的联系。
使用索引判断标准
接下来介绍下 PG 优化器判断能够生成索引路径的标准。但是在这之前,先简单介绍下创建索引时确定的对应的 opclass 逻辑。
创建索引时如何确定索引列的 opclass & opfamily
如果索引创建时指定了 opclass,就存下对应的oid;如果没有指定会依照对应索引列的类型,查找 pg_opclass 得到的 deafult opclass。然后根据 opclass 得到索引每个 key 的 opfamily / sortfamily。
pg_index 系统表indclass
存储了索引中每个相关列对应的opclass
。
主要逻辑在 _ComputeIndexAttrs_
函数中。
优化器判断是否能够走索引逻辑
完成 opclass 和 opfamily 定义工作后,优化器是通过什么逻辑判断这个类型的索引能够被利用呢?
PG 中判别走索引的情况可以分为两类:
限制子句:这种情况主要是判别限制子句中的 operator 是否在索引 IndexOptInfo 中 opfamily 中,参考 match_clause_to_indexcol 函数。有以下几种情况:
(indexcol) OP (no other rel col) e.g. a = 1 这类情况会判断 operator 是否在 indexcol 对应的 opfamily 中,如果在,才有可能生成一条 index path。(存在一种特殊情况,有些操作符不满足条件,但是如果 OP 右边是 const 值,也有可能会走索引,比如 a like 'a%')。
(indexcol) IN ANY (ScalarArray) e.g. a in (1, 2, 3, 4) 这类情况同 1.1 。
(no other rel col) OP (indexcol) e.g. 1 = a 这类情况与 1.1 类似,只是判断标准变成 OP 的 commutator 是否在 indexcol 的 opfamily 中。
(indexcol) OP (other rel col) e.g. t1.a = t2.a 这类场景和 1.1 & 1.3 类似,但只适合 Btree AM。
(ndexcol) IS (not) NULL e.g. a is NULL 这类情况是检查 indexcol 对应的 AM 是否支持KEY为NULL 。
那上述 OP 是如何确定的呢?实际上发生在 parser 阶段(RawStmt ==> Query),参考 transformAExprOp,如果没有定义的 operator,则会走隐式类型的转换规则。
排序操作:针对有序索引,建立一个index path,会保留对应的排序顺序、比较操作符等信息,称为 pathkeys ,在上层尝试生成排序节点时,会将path 的 pathkeys 与期望的 pathkey 进行对比,如果能够满足要求,则会省去 sort 节点的开销,使得这个 plan 的cost降低。
在生成 index path 期间,如果发现 PlannerInfo-> query_pathkeys != NULL,优化器就会认为 index path 的顺序可能会有用,为这个 index path 生成 pathkey,采用 indexcol 对应的 opfamily,参考 build_index_paths 函数。
检测生成的 pathkey 是否能用于 merge / ordering 场景,参考 truncate_useless_pathkeys 。
其中 query_pathkeys ,表示这个query 是否有可能需要排序的操作,主要来源于 groupClause / WindowClause / distinctClause / sortClause 。
上面提到的 query_pathkeys 是如何生成的?默认情况下是选择调用 standard_qp_callback 函数生成,而生成的 pathkey 包含有 opfamily 信息,这个信息是如何确定的呢?同样发生在parser 阶段,对于 sortClause 参考 transformSortClause(其余排序场景类似),最终会调用到 get_ordering_op_properties 函数,得到 opfamily 信息。
