





网络应用程序、社交媒体和物联网的激增,加上业务流程的大规模数字化,导致原始数据量呈爆炸式增长。
各行业的企业开始认识到每种形式的数据都是一种战略资产,并越来越多地利用这些复杂数据来做出数据驱动的业务决策。
大数据解决方案正被用来实现企业的 “数据湖”,存储来自所有可用来源的处理过的数据,并为各种应用程序提供动力。
大数据解决方案还将成为企业解决方案的关键组成部分,用于预测分析和物联网部署。
SAP 内部部署和按需解决方案,尤其是 HANA 平台,则需要与Hadoop生态系统进行更紧密的集成。
1.
什么是 “大数据”?
数据集的特点是体积、速度和种类。大数据是指具有明显高于传统数据集的一个或多个这些属性的数据类。
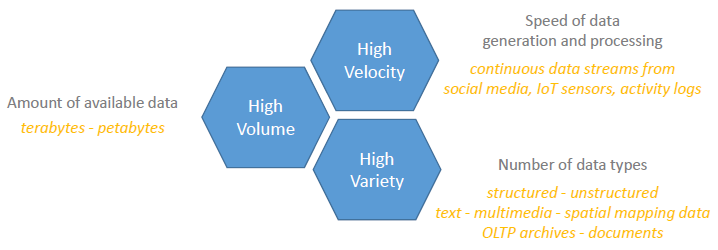
大数据为数据处理解决方案的所有方面带来了独特的挑战,包括数据的采集、存储、处理、搜索、查询、更新、可视化、传输和安全性。
2.
Hadoop解决方案拯救大数据
Hadoop是一个开源软件框架,用于使用大型机器集群对大数据进行分布式存储和处理。
Hadoop的工作方式是先分后和,在小块中完成任务、在多个节点上并行存储和处理、最后将结果组合在一起。
Hadoop并不是唯一可用的大数据解决方案。Hadoop和其他潜在的替代品存在着几种商业分布,这些变种在体系结构上是非常不同的。
将SAP HANA的高速内存处理能力与Hadoop以经济高效的方式存储和处理大量结构化和非结构化数据的能力相结合,将会为业务解决方案提供了无限的可能性。
Hadoop系统可以成为任何SAP环境中的一个极其重要的补充,能够起到这些作用:
* 一个简单的数据库和低成本的存档,用于扩展SAP系统的存储容量,以保留大量历史数据或不经常使用的数据。
* 灵活的数据存储,增强SAP系统持久性层的功能,并为半结构化和非结构化数据 (如 xml-json-text-images) 提供高效存储。
* 庞大的数据处理/分析引擎,用于扩展或替换包括SAP HANA在内的SAP系统的分析/转换能力。
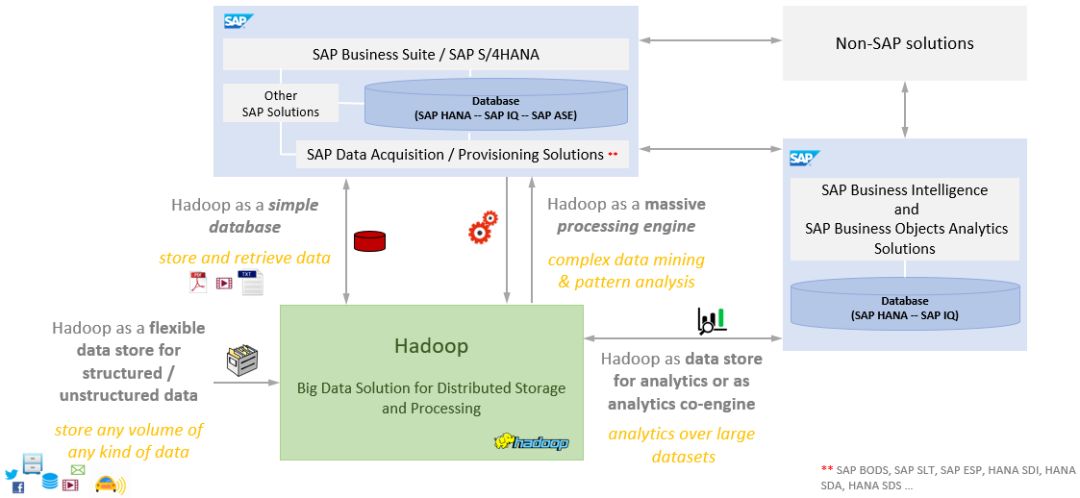
Hadoop生态系统
Hadoop的核心是一个基于Java的软件库,它为跨服务器群集的分布式存储和并行数据处理提供了实用程序模块。然而,通常的说法是,“Hadoop” 一词几乎总是指整个生态系统,其中包括广泛的apache开源和基于核心软件库的商业工具。
Hadoop目前可以作为一组开源包,也可以通过多个企业级的商业发行版提供。Hadoop解决方案可作为来自多个供应商的SaaS/PaaS云产品,以及用于内部部署的传统产品。
根据 Gartner 和 Forrester Research 的最新市场指南提供的突出分销服务快照:
* Apache Hadoop [开源]
* Cloudera Enterprise | Cloudera CDH [开源]
* Hortonworks Data Platform HDP [开源]
* MapR
* IBM Big Insights ^^
* Amazon Elastic MapReduce (EMR)
* 微软 Azure HDInsight
* Google Cloud Dataproc
* Oracle 大数据云服务
* SAP 云平台大数据服务(原 AP Altiscale数据云)(可能中断的解决方案)
Hadoop 核心组件是整个数据访问和处理解决方案生态系统的基础。
* Hadoop HDFS是一种可扩展的、容错的分布式存储系统,它使用本机操作系统文件将数据存储在大量节点上。HDFS 可以支持任何类型的数据,并通过跨多个节点复制文件来提供高度的容错能力。
* Hadoop YARN和Hadoop Common为整个集群的资源管理提供了基础框架和实用程序
Hadoop MapReduce是开发和执行分布式数据处理应用程序的框架。Spark和tez是基于数据流图的备用处理框架,被认为是Mapreduce作为Hadoop中分布式处理的基础执行引擎的下一代替换。
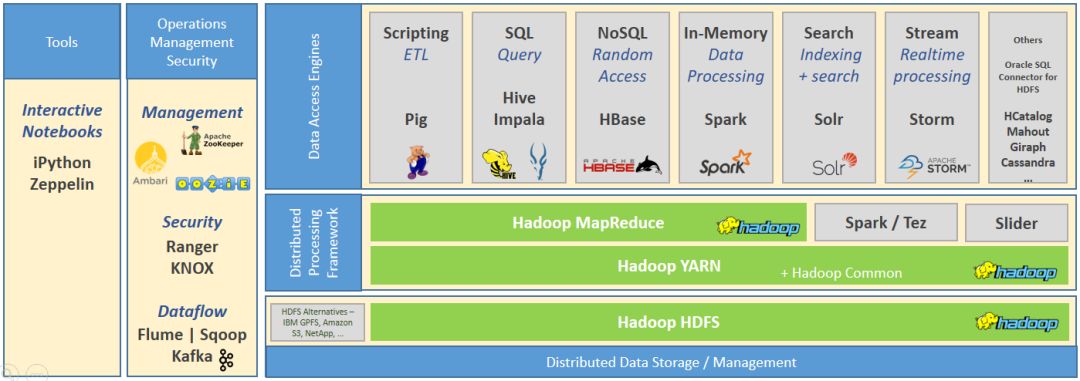

各种数据访问/处理引擎可以与Hadoop MapReduce引擎一起运行,以处理HDFS数据集。Hadoop生态系统在不断发展,组件经常具有一些补充、重叠和类似的出现功能,但基础体系结构或方法却大不相同。
Hadoop生态系统中流行的组件应用程序-引擎工具 (不是一个详尽的列表; 企业在特定用例中,使用了几个更多的开源和供应商特定的应用程序)
* Pig - 用于开发和执行高级语言 (Pig Latin) 脚本的平台,用于 Hadoop 数据集上复杂的 etl 和数据分析作业
* Hive - 只读在 Hadoop 内核之上运行的关系数据库,并支持基于 Sql 的对 Hadoop 数据集的查询;由hive-metastore 支持
* Impala -大规模并行处理 (mpp) 分析数据库和基于sql的交互式查询引擎,用于实时分析
* HBase,NoSQL(非关系型) 数据库,它提供对Hadoop中数据集的实时随机读写访问;由HCatalog支持
* Spark - 内存中数据处理引擎,可以在Hadoop上运行,也可以作为Hadoop 自身的替代
* Solr - 搜索引擎/平台,实现强大的全文搜索和实时近似索引
* Storm - 用于连续计算&实时分析的流式数据处理引擎
* Mahout - 统计、分析和机器学习软件库,可在Hadoop上运行,可用于数据挖掘和分析
* Giraph - 基于Giraph框架的迭代图形处理引擎
* Cassandra - 分布式NoSQL (非关系型) 数据库,具有极高的可用性功能
* Oozie - 用于管理作业和工作流的计划程序引擎
* Sqoop - 可扩展的应用程序,用于在Hadoop和结构化数据存储以及关系数据库之间批量传输数据
* Flume - 分布式服务,可将大容量流数据输入HDFS
* Kafka - 流处理和消息系统
* Ambari - 基于Web的工具,用于设置、管理和监视Hadoop群集和各种本机数据访问引擎
* Zookeeper – 集中服务,维护Hadoop配置信息,并实现分布式Hadoop流程之间的协调
* Ranger – 集中式框架,用于跨Hadoop组件一致地定义、管理和管理细粒度访问控制和安全策略
* Knox – 作为反向代理的应用程序网关,为Hadoop群集提供外围安全,并支持与SSO和IDM解决方案的集成
3.
连接两个世界,Hadoop和SAP生态系统
SAP解决方案,尤其是SAP HANA平台,可以根据任何用例的具体要求,使用各种解决方案和方法与Hadoop生态系统 “集成”。
集成时应考虑的 SAP 解决方案包括:
* SAP BO Data Services
* SAP BO BI Platform | Lumira
* SAP HANA Smart Data Access
* SAP HANA Enterprise Information Management
* SAP HANA Data Warehousing Foundation – Data Lifecycle Manager
* SAP HANA Spark Controller
* SAP Near-Line Storage
* SAP Vora
* …. <possibly more !>
* Apache Sqoop [Not officially supported by SAP for HANA]
SAP HANA可以利用HANA智能数据访问来联合Hadoop (作为数据源访问 Hadoop) 的数据,而无需将远程数据复制到HANA中。
SDA 支持使用虚拟表的数据联盟 (读/写),并支持Apache Hadoop/Hive和 Apache Spark作为远程数据源,此外还有许多其他数据库系统,包括SAP IQ, SAP ASE, Teradata, MS SQL, IBM DB2, IBM Netezza 和 Oracle。
Hadoop可用作SAP HANA中虚拟表的远程数据源,使用以下适配器 (内置 HANA):
* Hadoop/Spark ODBC Adaptor - 要求在 HANA 服务器上安装 Unix ODBC 驱动程序 + Apache HIVE-SPIPARK ODBC 驱动程序
* SPARK SQL Adaptor - 需要在Hadoop群集上安装SAP HANA Spark Controller(推荐适配器)
* Hadoop Adaptor (WebHDFS)
* Vora Adaptor
SAP HANA还可以利用HANA智能数据集成,将 Hadoop 中所需的数据复制到 HANA 中。
SDI 提供预构建的适配器 & 适配器 SDK,以连接到各种数据源 (包括 Hadoop)。HANA SDI 要求在独立的计算机上安装远程数据源的数据资源调配代理 (包含标准适配器) 和本机驱动程序。基于DWF-DLM的SAP HANA XS引擎可以通过Spark SQL adaptor / Spark Controller将数据从HANA到 HANA Dynamic Tiering、HANA 扩展节点、SAP IQ 和 Hadoop 之间重新定位。
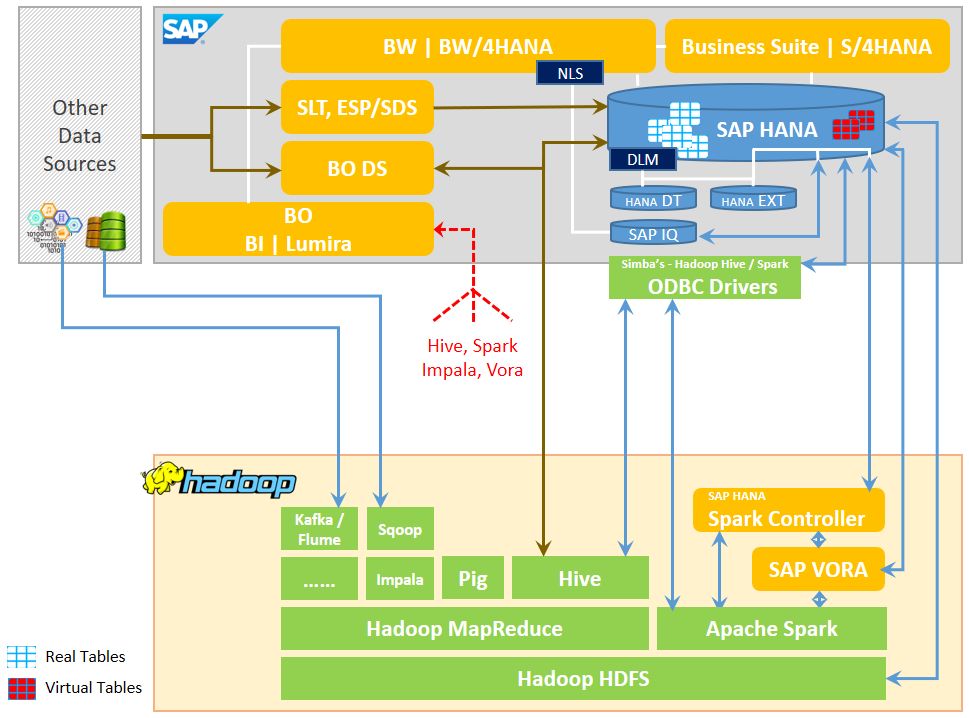
SAP Vora是一个内存中的查询引擎,在Apache Spark框架的顶部运行,并对 Hadoop中的数据提供丰富的交互式分析。Vora中的数据可以直接通过Vora适配器或通过 SPARK SQL 适配器 (HANA Spark 控制器) 在 HANA 中访问。支持Hortonworks, Cloudera and MapR。
SAP BO Data Services (BODS) 是一种全面的数据复制/集成 (ETL 处理) 解决方案。SAP BODS 具有访问 Hadoop 中的数据、将数据推送到 Hadoop、处理 Hadoop 中的数据以及使用 Hive/Spark 查询、pig scripts、MapReduce 作业和与 HDFS 直接交互的功能 (通过打包的驱动器连接器适配器适配器)。本机操作系统文件。SAP SLT没有与 Hadoop 通信的本机功能。
SAP Business Objects (BI Platform, Lumira, Crystal Reports, …) 可以访问 Hadoop (HDFS – Hive – Spark – Impala – SAP Vora) 中的数据并将其可视化,从而将数据与 SAP HANA 和其他非 SAP 源的数据结合起来。SAP BO 应用程序使用其内置的 ODBC/JDBC 驱动程序或通用连接器连接到 Hadoop 生态系统。Apache Zeppelin可用于 SAP vora 的交互式分析可视化。
Apache Sqoop支持在非结构化、半结构化和结构化数据存储之间批量传输数据。Sqoop 可用于在 Apache Hadoop 和关系数据库 (包括 SAP HANA) 之间传输数据 (尽管没有得到 SAP 的正式支持)。
4.
入门: Hadoop 部署概述
Hadoop 是一个分布式存储和处理框架,通常部署在一个由多达几台独立计算机组成的集群中,每个计算机都参与数据存储和处理。每个群集节点可以是独立服务器,也可以是虚拟机。一些组织更喜欢有少量较大的集群;其他人根据工作负载配置文件和数据量选择更多的较小的群集。
HDFS 数据被复制到多个节点,以实现容错。Hadoop 群集的部署通常 HDFS 复制系数为三个,这意味着每个数据块都有三个副本—原始副本加两个副本。因此,Hadoop 群集的存储要求是预期的输入管理数据集大小的四倍多。Hadoop 群集的推荐存储选项是具有具有本地 (Direct Attached Storage – DAS) 存储的节点。SAN / NAS存储可以使用,但并不常见 (可能是效率低下?),因为 Hadoop 集群本质上是一个 “不共享体系结构”。
节点的区别在于它们的类型和作用。主节点为分布式存储和处理系统提供关键的中央协调服务,而工作节点是实际的存储和计算节点。
节点角色表示作为守护进程或进程运行的一组服务。基本 Hadoop 群集由 NameNode (+ 待机)、数据节点、资源管理器 (+ 待机) 和节点管理器角色组成。名称节点协调数据节点上的数据存储,而资源管理器节点协调群集中节点上节点上的数据处理。群集中的大多数节点是通常同时执行数据节点和节点管理器角色的工作人员,但也可以有数据专用节点或仅计算节点。
从 Hadoop 生态系统中部署各种其他组件/引擎会带来更多的服务和节点类型,这些角色可以添加到群集节点中。任何应用程序的各种服务的节点分配都是特定于该应用程序的 (请参阅安装指南)。许多这样的组件还需要自己的数据库来进行作为组件服务一部分的操作。群集可以为具有非常特殊要求 (如内存处理和流式处理) 的应用程序引擎设置专用节点。
Master / Management节点部署在具有 HA 保护的企业级硬件上;而工作人员可以部署在商品服务器上,因为分布式处理模式本身和 HDFS 数据复制提供了容错能力。Hadoop 有自己的内置故障恢复算法来检测和修复 Hadoop 群集组件。
Hadoop 群集节点的典型规范取决于工作负载配置文件是存储密集型还是计算密集型。所有节点不一定都需要具有相同的规范。
* 2 quad-/hex-/octo-core CPUs and 64-512 GB RAM
* 1-1.5 disk per core; 12-24 1-4TB hard disks; JBOD (Just a Bunch Of Disks) configuration for Worker nodes and RAID protection for Master nodes
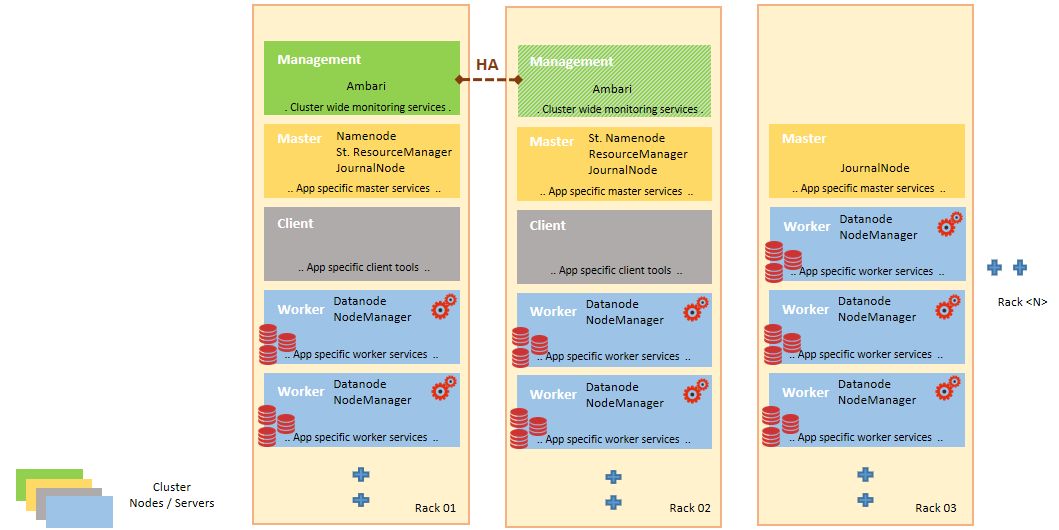
Hadoop 应用程序 (数据访问/处理引擎和工具,如 Hive、Hbase、Spark 和 Storm、SAP HANA Spark 控制器和 SAP Vora) 可以跨群集节点部署,可以使Ambari / Cloudera 管理器等设置工具,也可以手动部署。
部署要求可以是: 所有节点、至少一个节点、一个或多个节点、多个节点、下面是各自的特点:

5.
入门: SAP的 “桥接” 解决方案的部署概述
SAP Vora由 Vora 管理器服务和一些核心处理服务组成,这些服务可以添加到现有 Hadoop 部署的各种计算节点中
-使用 SAP Vora 安装程序在管理节点上安装 SAP Vora 管理器
-将 SAP Vora Rpm 分发到所有群集节点,并使用 Hadoop 群集资源调配工具进行安装、使用 Hadoop 群集资源调配工具在群集节点上部署 Vora 管理器
-启动 Vora 管理器,并使用 Vora 管理器在整个集群中部署各种 Vora 服务
SAP HANA Spark 控制器提供使用 Spark SQL 到底层 Hve/vora 表的 SQL 接口,需要将其添加到现有 Hadoop 部署的至少一个主节点中
-安装 Apache Spark 程序集文件 (开源库);SAP 安装程序未提供
-使用 Hadoop 群集设置工具在主节点上安装 SAP HANA Spark 控制器
SAP HANA 智能数据集成和智能数据访问是 SAP HANA 的包括组件,不需要单独安装。但是,智能数据集成确实需要激活数据资源调配服务器,并安装数据资源调配代理。
-在 HANA 系统上启用数据设置服务器
-在 HANA 系统上部署数据资源调配交付单元
-在远程数据源主机或独立主机上安装和配置数据设置代理
SAP HANA 数据仓库基础–数据生命周期管理器,是一个基于 XS 引擎的应用程序,需要在 HANA 平台上单独安装。
SAP 云平台大数据服务 (原 SAP Altiscale 数据云)是一个完全托管的基于云的大数据平台,提供预安装、预配置、生产就绪的 Apache Hadoop 平台。
-服务包括 Apache Hadoop 生态系统中的 Hive, HCatalog, Tez 和 Oozie,以及 Hadoop MapReduce / Spark 和 HDFS 的核心层
-支持 Java、Pig、R、Ruby 和 Python 语言并提供运行时环境
-支持从 Hadoop 生态系统部署非默认第三方应用程序
-服务可通过 SSH 和网络服务使用
-本质上是平台即服务 (PaaS) 产品,包括:
-基础架构配置
-Hadoop 软件堆栈部署和配置
-操作支持和可用性监控
-使客户能够专注于业务优先级及其分析/数据科学方面
通过委托 Hadoop 平台软件堆栈的技术设置和管理,
SAP 云平台支持团队的基础架构
6.
最后
Gartner 的市场研究和调查断言,Hadoop 的应用正在稳步增长,并且也从传统内部部署转向按需云部署。
准备好用大数据完成大任务吧!
Thanks for reading !!
原文地址:https://blogs.sap.com/2017/07/19/bridging-two-worlds-integration-of-sap-and-hadoop-ecosystems/
原文作者:Vimal Jain
- End -
往期精选 |  Editors' Choice
Editors' Choice

首页下拉,可看到各类「专题集」
建议、交流、合作,欢迎添加客服小哈微信

