





1.指标管理/服务面临的问题以及解决方案
指标管理/服务面临的问题
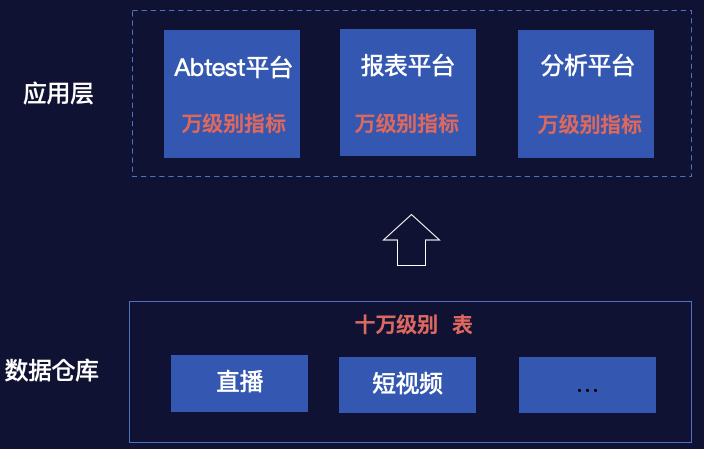
指标管理不统一 多处管理:成本较高 重复管理:指标泛滥 指标口径不统一 同名不同义:口径不一致 同义不同名:命名不规范 指标流程不统一 系统独立:管理不统一、流程不统一
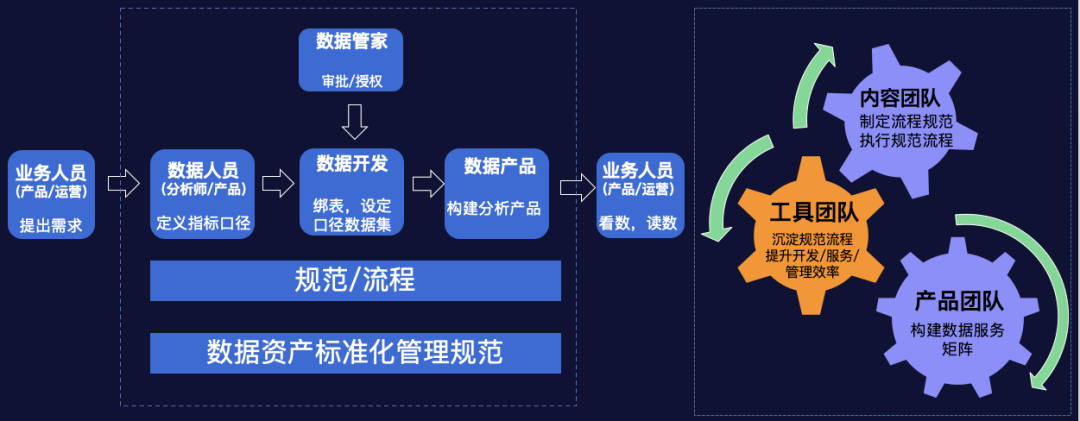
数据字典,约等于wiki; 无体系化的流程保障机制,数据准确性无法保障; 指标血缘关系缺失,与数据生产、数据消费没有建立血缘关系; 管理与数据应用分离,无法一处变更,全局生效。
解决方案
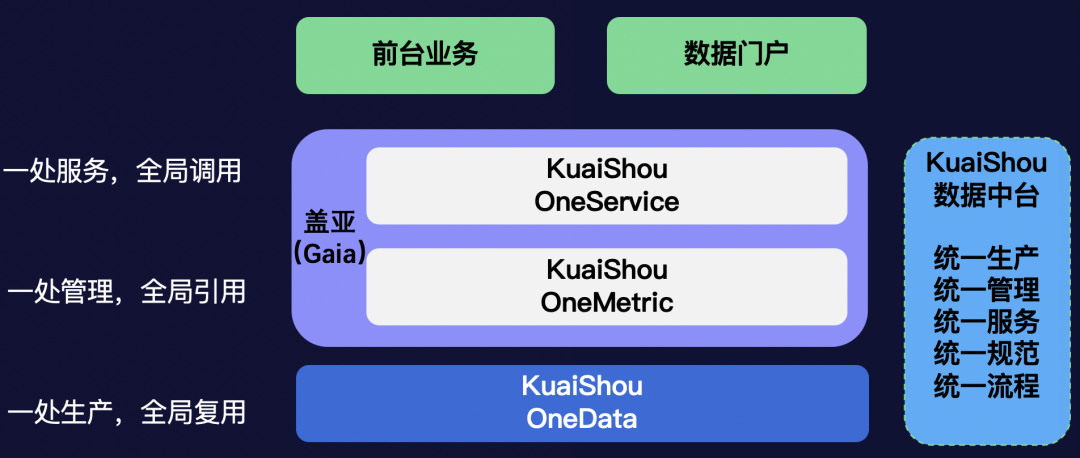
OneMetric体系:统一管理指标口径信息,基于指标口径的元信息构建数据模型,做到“一处管理,全局引用”。
OneService体系:统一指标服务出口,上层业务、数据门户等都统一从OneService获取指标数据,做到“一处服务,全局调用”。
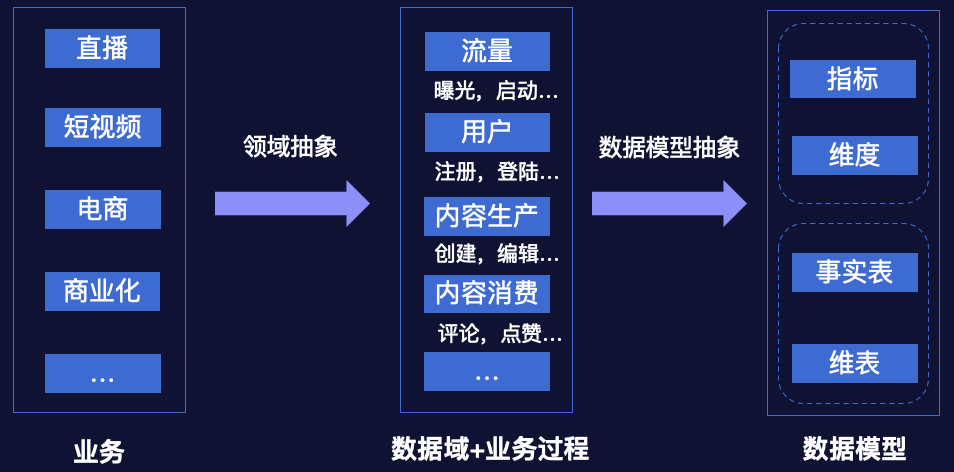
2.指标规范化建设
规范流程建设
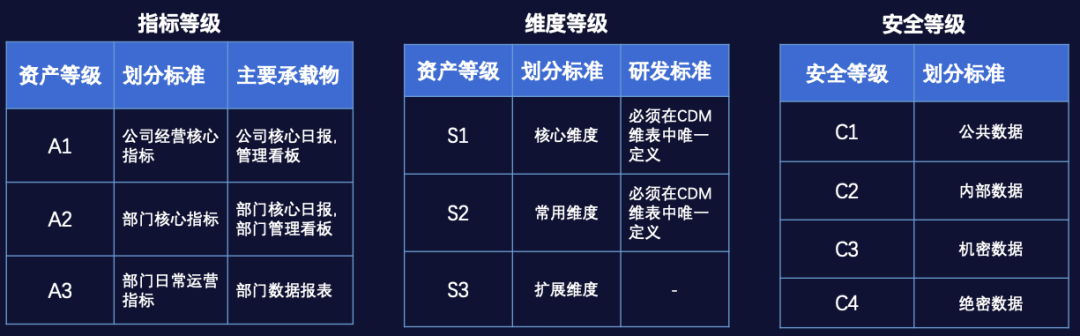
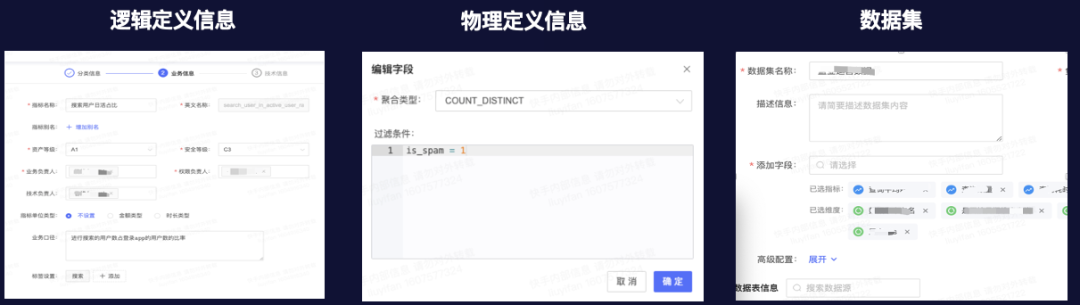
OneMetric系统
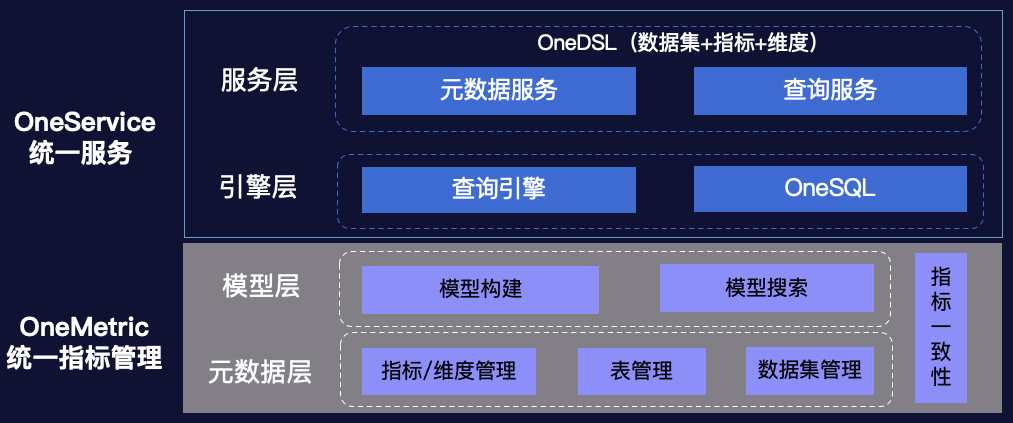
元数据管理模块
指标一致性模块
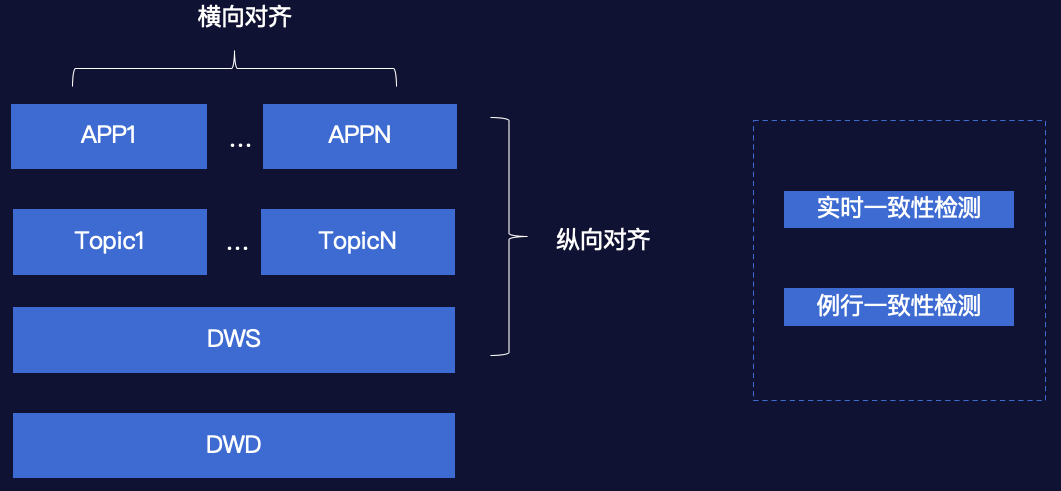
第一种情况:同一指标在不同层次会出现; 第二种情况:同一指标也会在同一层不同数据表存在。
实时一致性检测:在指标绑定新的物理表时,若指标在现有数据仓库已经存在绑定的计算口径,需要确保两个计算口径的结果一致性,这时会进行两个计算口径实时的一致性检测; 例行一致性检测:在经过实时一致性检测之后,能确保指标在不同路径下的口径一致性,但在实际应用中,还会存在数据刷新、逻辑变更等情况,这时我们可以通过例行的检测,发现不同计算路径的数据不一致问题。
模型构建模块
表与表之间的连接关系:表与表如何关联,通过什么字段关联; 指标/维度与模型之间的关系:指标/维度在哪些数据模型中存在; 指标与引擎之间的关系:指标可以在哪些物理引擎中支持。
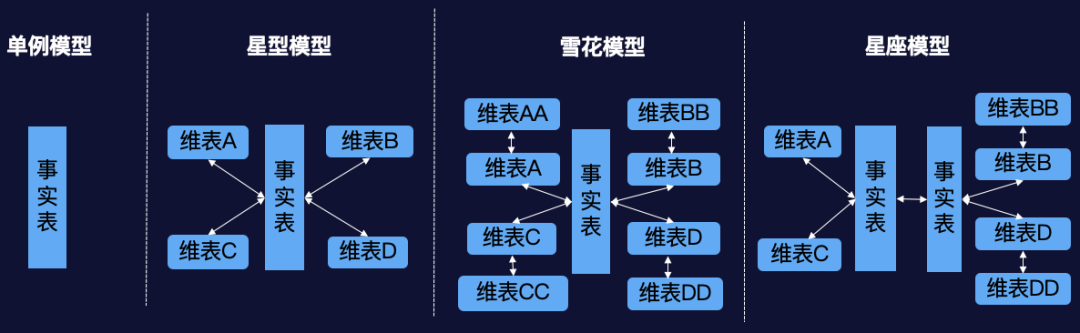
模型搜索模块
筛选阶段:在OneMetric体系下,通常满足一个指标/维度组合会存在多个模型,筛选阶段就是找出符合条件的模型。 指标筛选:筛选出包含指标的模型 维度筛选:筛选出包含维度的模型 范围筛选:筛选出维度范围满足要求的模型 日期筛选:筛选出时间范围满足要求的模型 排序阶段:基于筛选出的模型,进行各维度的排序,选择出最优模型。 生产排序:按照模型中表的生产完成时间,取完成时间比较早的表 效率排序:按照模型中表的引擎、表的宽度进行排序,优先取高速引擎(例如OLAP引擎优先),宽表减少数据Join操作 维度排序:按照模型中表的粒度,粒度越粗则聚合成本越低 手动排序:按照模型中表的优先级进行排序
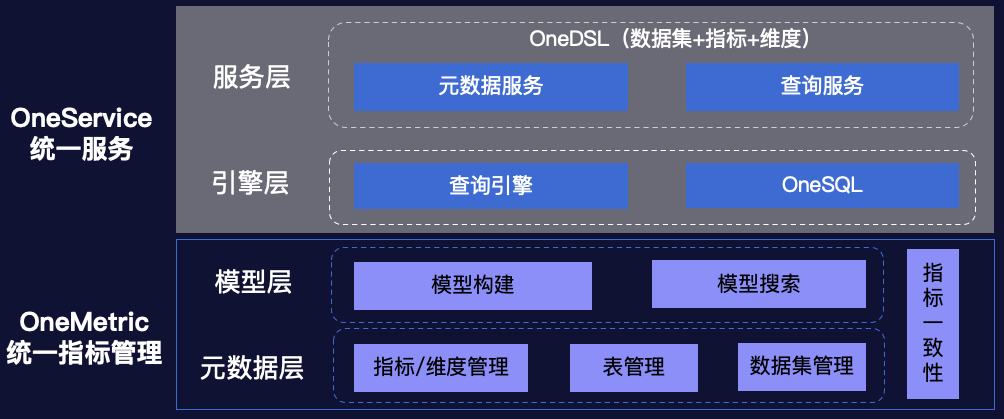
3.指标服务OneService平台化建设
系统架构
语言翻译能力:将面向指标/维度的查询语言转换为面向引擎的查询语言。 二次计算能力:基于表的取数结果再进行二次的运算能力。在实际应用场景下,通常会有二次计算的需求,例如同环比、分位查询等。
关键技术-语言抽象
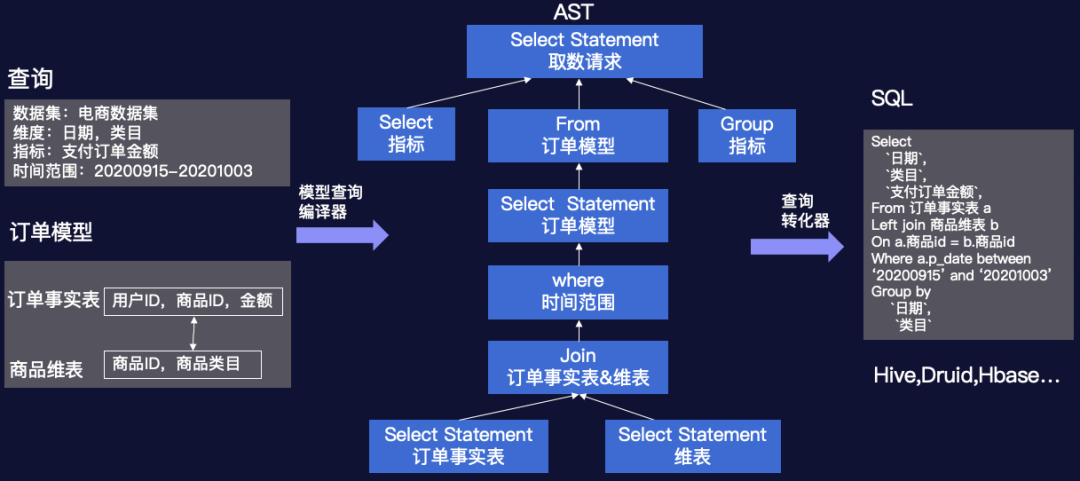
电商本周各地域母婴产品支付订单金额
电商:数据范围本周:时间范围 = [20201019 – 20201025]各地域:维度 = [地域]母婴产品:过滤条件 = [商品二级类目 = 母婴产品]支付订单金额 :指标 = [支付订单金额 ]

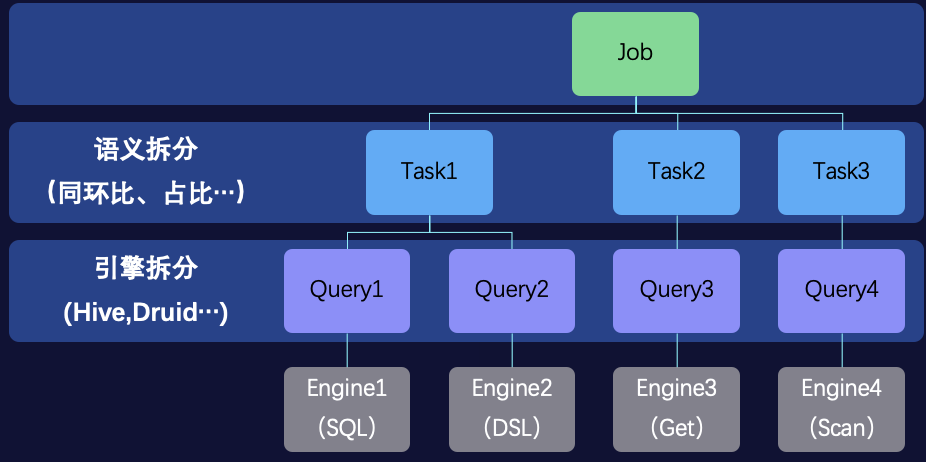
关键技术-执行计划
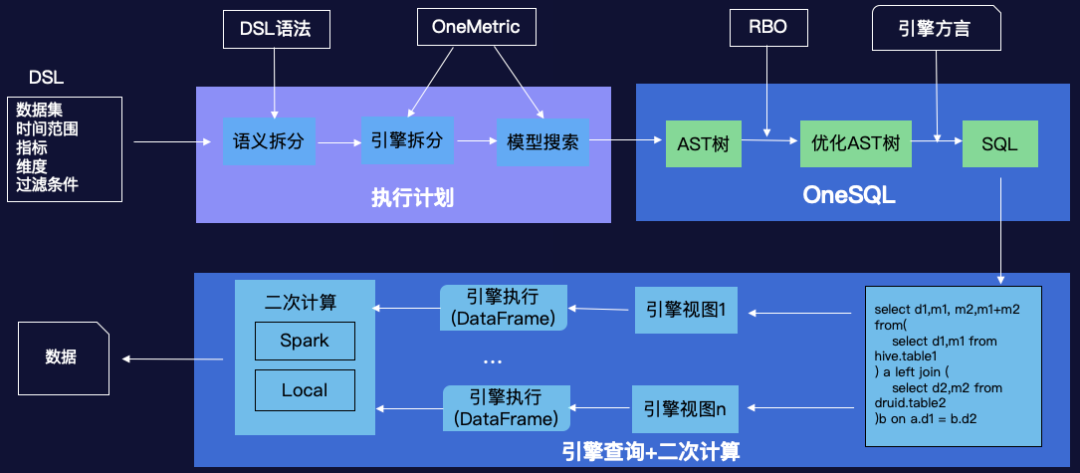
关键技术-OneSQL
4.落地成果与未来规划
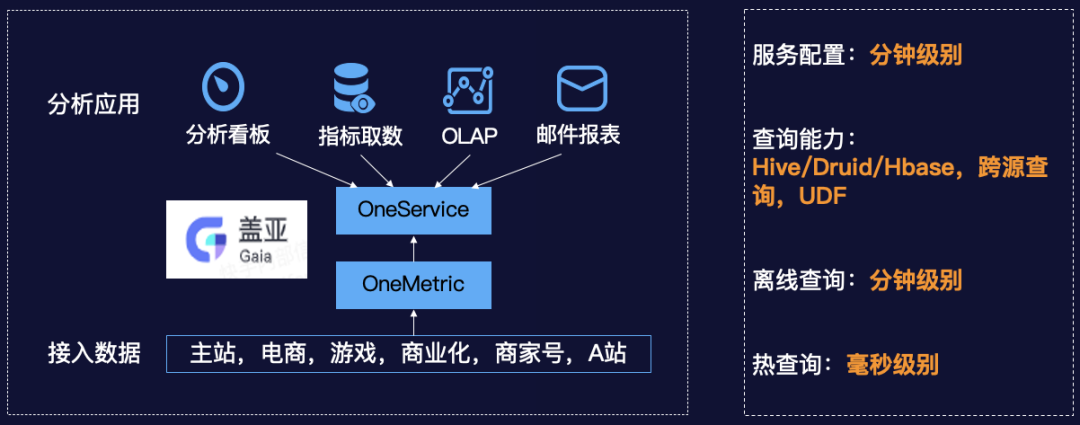
落地成果
未来规划
接入更多业务,全面推广到公司更多数据业务 构建数据服务领域的OneService,让数据配置即服务 构建面向数据服务的OneDSL 构建OneCache,提升性能 自动化/智能化探索
作者介绍
文章转载自hadoop123,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
