




ScaleFlux、AIC和ExponTech展示了与NVIDIA BlueField-3 DPU配合的惊人存储性能,进一步验证了这一创新解决方案在AI推理领域的卓越表现。
回顾第一部分
在第一部分中为AI推理需求的未来做准备:第一部分,我们探讨了AIC F2026 AI推理服务器的初始性能基准测试,突显了其使用两个DPU时的可扩展性和效率。AIC F2026 AI推理服务器在2U系统中集成了多达26个ScaleFlux CSD5000 NVMe SSD和最多8个NVIDIA BlueField-3数据处理单元(DPU),提供了跟上AI工作负载所需的高吞吐量、低延迟和可扩展性。
在F2026仅配置2个DPU的第一轮测试中,团队展示了随着更多计算服务器连接到存储阵列,系统性能的扩展能力。(详细内容请参阅博客"为AI推理需求的未来做准备:第一部分")
我们还承诺在其他场景下进一步测试该系统。基于这些发现,第二部分深入探讨了更高级的测试场景,包括全面的存储性能评估和MLPerf基准测试,以评估系统在各种苛刻AI工作负载下的能力。
测试设置
ExponTech与NVIDIA、ScaleFlux和AIC合作,对AIC F2026进行了一系列性能测试。
硬件配置
存储服务器:一台配备26个ScaleFlux CSD5000 SSD和四个BlueField-3 DPU的AIC F2026推理服务器。ScaleFlux SSD集成了内联数据压缩引擎,可执行线速率数据压缩和解压缩。NVIDIA DPU提供高达1600Gbps的网络带宽。
网络环境:在测试环境中,选择了四个NVIDIA Spectrum-X交换机组成第2层网络,主要是为了模拟大规模网络,并验证RoCE网络是否能有效处理拥塞。此外,测试旨在确保存储软件能在大规模网络场景中保持稳定的存储性能和低延迟。
计算服务器:一台标准2U服务器,配备四个NVIDIA BlueField-3 DPU,提供800Gbps网络带宽,并在DPU上运行ExponTech WADP存储软件。存储软件和网络流量由DPU管理,使计算服务器的GPU可以自由用于训练或推理任务。由于存储I/O由DPU处理,计算服务器的CPU和内存资源也可用于运行应用程序。
软件配置
ExponTech下一代分布式存储软件WADP(一个统一数据平台)在F2026推理AI服务器的DPU上运行。WADP同时支持:
需要超高IOPS和超低延迟的事务性数据(如数据库) 需要海量容量、超高吞吐量和高元数据性能的大规模AI数据
测试拓扑图
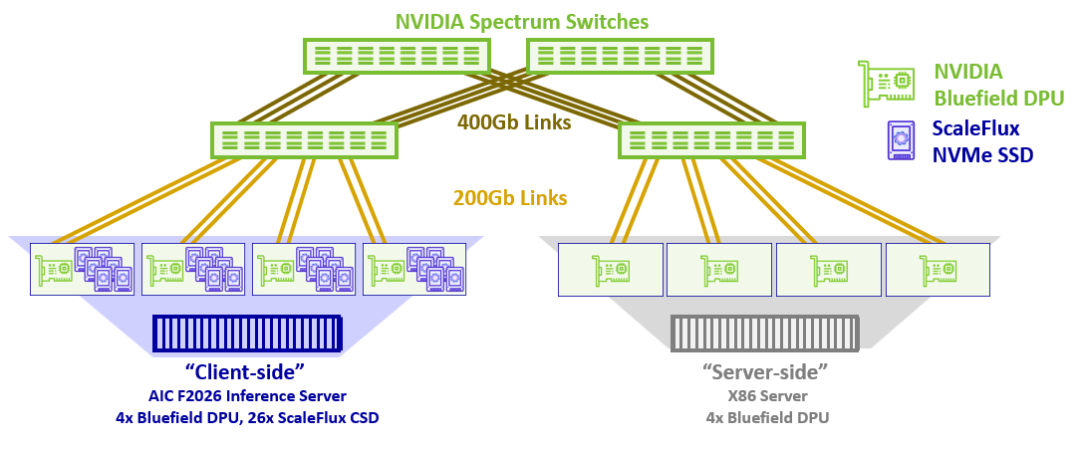
JBOF和计算服务器都可以独立扩展,并且可以根据需要添加更多JBOF或计算服务器,形成大规模的存储-计算分离集群,用于按需AI训练和推理。
测试轮次1 – 基本存储性能
使用在计算服务器上运行的FIO,团队收集了各种I/O块大小(4K、128K、1MB)的读写性能结果。第一次性能测试配置计算服务器装有单个DPU。第二次运行则在计算服务器上配置了四个DPU。在这两种情况下,存储服务器都有四个DPU和26个SSD。
结果与第一部分的结果一致,存储服务器性能几乎与拓扑中的DPU数量呈线性扩展。增加F2026中的DPU数量使潜在的SSD带宽和IOPS得到更充分利用。增加计算服务器上的DPU数量使F2026的性能得到更充分利用。Spectrum交换机在计算和存储服务器之间提供了一致的低延迟数据路径。
表1:FIO性能结果
| 计算服务器配1个DPU,存储服务器配4个DPU | 计算服务器配4个DPU,存储服务器配4个DPU | |||||
|---|---|---|---|---|---|---|
| 工作负载 | IOPS | 带宽 | 延迟(微秒) | IOPS | 带宽 | 延迟(微秒) |
| 4k随机读 | ||||||
| 4k随机写 | ||||||
| 128k读 | ||||||
| 128k写 | ||||||
| 1M读 | ||||||
| 1M写 | ||||||
关键观察结果
突破性带宽表现:单个计算节点与单个存储节点连接可实现接近90 GB/s的存储带宽,这接近计算节点网卡物理带宽的上限
线性IOPS扩展:单个计算节点的IOPS从80万扩展到310万,几乎与DPU数量呈线性扩展。在这两种情况下,计算服务器而非存储服务器是性能的限制因素。考虑到整个存储系统的后端和协议端运行在DPU的核心上(功耗低于传统x86 CPU核心),测试充分展示了该解决方案惊人的IO处理效率。
出色横向扩展能力:存储系统的IOPS数量与部署在存储节点上的DPU数量成线性比例,系统的IOPS与部署的DPU数量成线性扩展,表明系统具有出色的横向扩展能力。
超低延迟性能:当存储系统使用小I/O大小时,并发高压力延迟低至266微秒。对于大I/O大小,计算节点的网络带宽饱和,延迟保持在1毫秒以下。
灵活升级路径:虽然当前性能取决于DPU的处理能力,但这种设置允许针对性地升级DPU,确保存储系统能够根据需要扩展。
测试轮次2 – MLPerf
MLPerf基准测试是一组旨在测量计算机运行人工智能(AI)任务的速度和效率的测试。就像汽车可能被测试速度和燃油效率一样,MLPerf评估计算机系统处理识别图像、翻译语言或提供推荐等AI日常任务的能力。
基准测试背景
MLPerf由一组公司和研究人员创建,他们希望以公平、透明的方式更容易地比较不同硬件和软件设置的性能。它既检查系统训练AI模型(从数据中学习)的速度,也检查训练后做出预测(称为推理)的速度。
这些测试对依赖AI的企业和研究人员特别有用,因为它们显示哪些系统最适合他们的需求。MLPerf还帮助硬件制造商证明其技术的强大。它已成为行业中最受信任的AI性能基准测试工具之一。
MLPerf基准测试套件包括反映常见真实世界AI任务的各种测试:
训练基准:图像分类、物体检测、语音识别、自然语言处理、推荐系统 推理基准:在数据中心、边缘设备和服务器环境中测试模型决策速度和准确性
使用ScaleFlux SSD和ExponTech测试F2026
团队使用了一台F2026和一台通过NVIDIA Spectrum网络连接的计算服务器的相同设置。他们使用MLPerf® Storage Benchmark v1.0评估存储系统,该基准测试基于真实世界的MLPerf训练配置文件模拟AI工作负载的I/O需求。
使用ResNet-50跟踪,存储解决方案实现了相当于支持240个模拟NVIDIA A100 GPU的性能,持续22.5 GiB/s的读取吞吐量。该性能还支持168个模拟NVIDIA H100 GPU,持续29.4GiB/s的吞吐量。这一结果展示了阵列提供一致高带宽数据访问的能力,满足大规模AI训练的强烈数据摄取需求。
"测试配置中计算服务器的有限能力使结果远低于存储系统的能力。使用更多计算客户端或更强大的计算节点,存储系统的得分会更高!"
——曹宇中,ExponTech首席技术官
表2:MLPerf Storage v1.0测试结果(ResNet-50模型)
| ExponTech | 240 | 22.51 | 168 | 29.40 | |
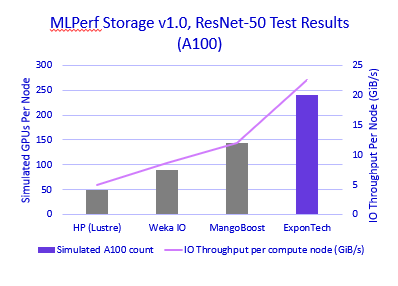
MLPerf Storage v1.0,ResNet-50测试结果(A100) - 显示性能比较的条形图
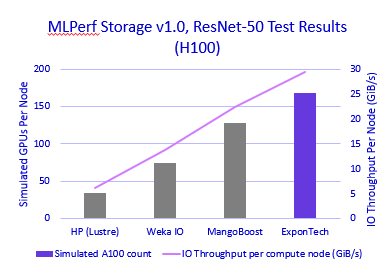
MLPerf Storage v1.0,ResNet-50测试结果(H100) - 显示性能比较的条形图
关键要点
🔹 卓越的整体性能:通过AIC系统专业知识与ScaleFlux CSD5000 NVMe SSD、NVIDIA BlueField-3 DPU和ExponTech软件的组合,实现了出色的整体吞吐量、延迟和可扩展性。
🔹 超高存储密度:每2U阵列26个驱动器的超高密度设计。
🔹 智能数据压缩:CSD5000中的透明数据压缩和解压缩可以在不消耗额外系统资源或影响性能的情况下,倍增原始存储容量和存储效率。
🔹 全场景AI解决方案:适用于所有AI管道场景的出色解决方案,如数据收集、数据准备和RAG。
🔹 灵活扩展能力:强大的并行可扩展性,存储节点和计算节点可以独立添加,按比例扩展存储性能和容量。
🔹 高可靠性设计:JBOF内部冗余硬件设计确保了高可靠性和可维护性。
🔹 先进网络架构:它支持基于RoCE的超大规模网络,采用RoCE动态路由和细粒度负载均衡,在基于标准以太网的大规模网络中实现更好的拥塞控制、高效带宽、低抖动和超低延迟。
寻找更多信息或额外测试?请访问www.scaleflux.cn与我们联系
