




CoreWeave Google IBM Research NVIDIA Red Hat
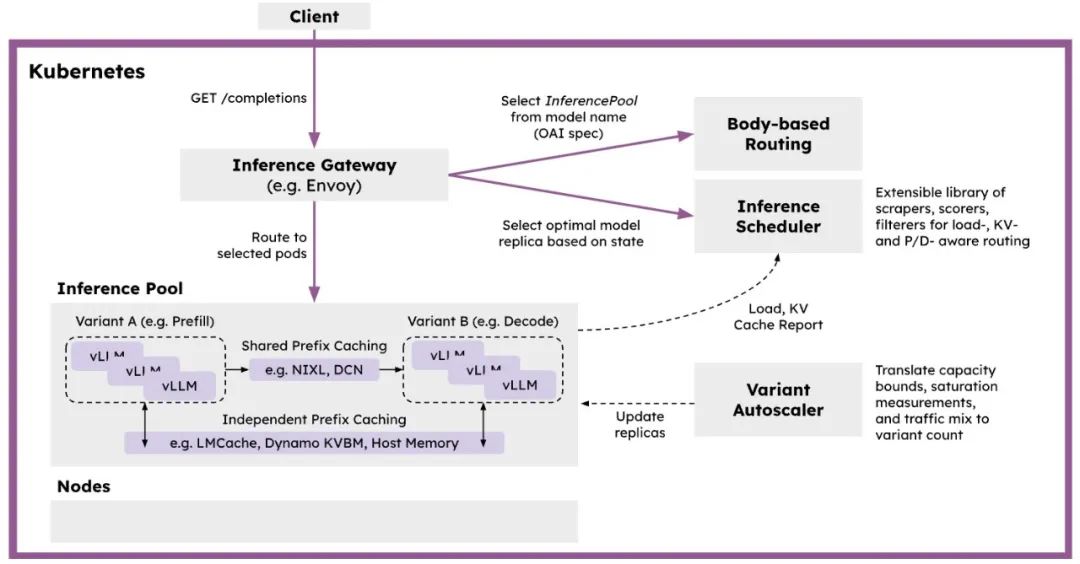
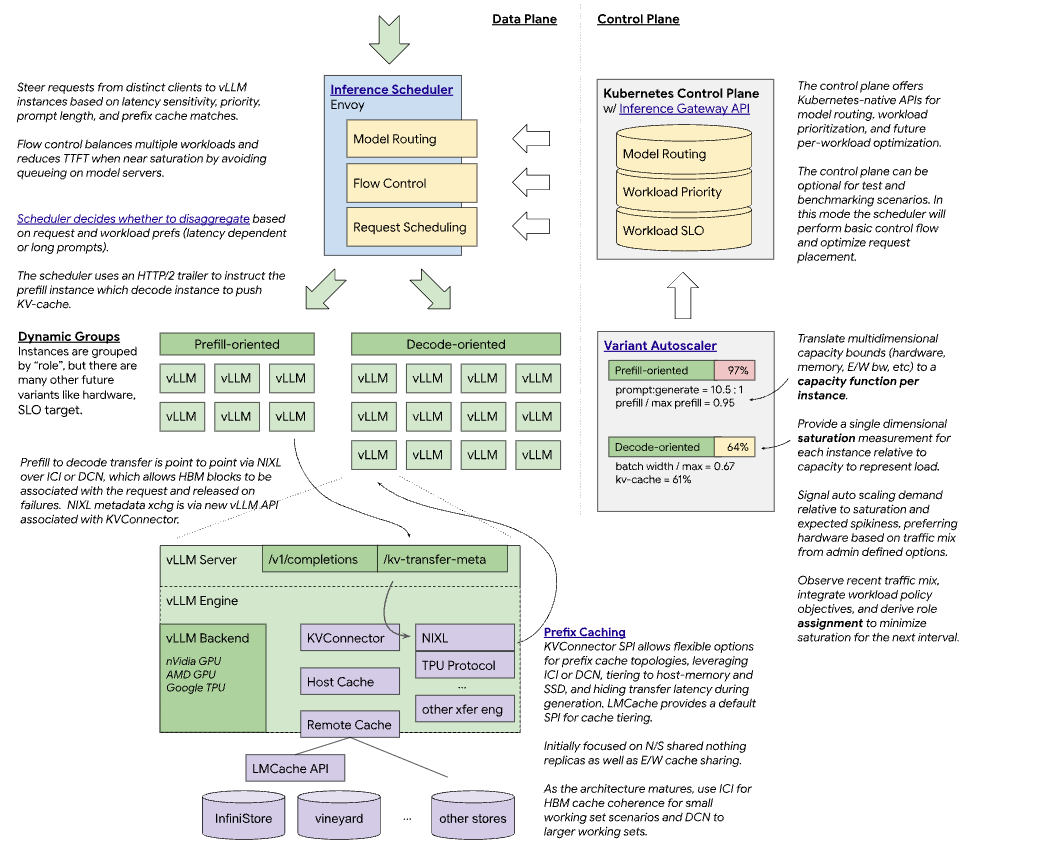
vLLM优化的推理调度器:基于IGW的可定制负载均衡模式,实现vLLM优化的调度。利用遥测数据,实现P/D、KV缓存、SLA和负载感知的决策。 使用vLLM的分解服务:在独立实例上运行预填充和解码操作,使用高性能传输库如NIXL。支持使用快速互连(IB、RDMA、ICI)的延迟优化实现和使用数据中心网络的吞吐量优化实现。 分解前缀缓存:使用vLLM的KVConnector提供可插拔的KV缓存层次结构,包括卸载到主机、远程存储和LMCache等系统。 变体自动缩放:实现流量和硬件感知的自动缩放,测量每个模型服务器实例的容量,考虑不同请求形状和QoS,评估最近的流量组合,计算最佳实例组合。
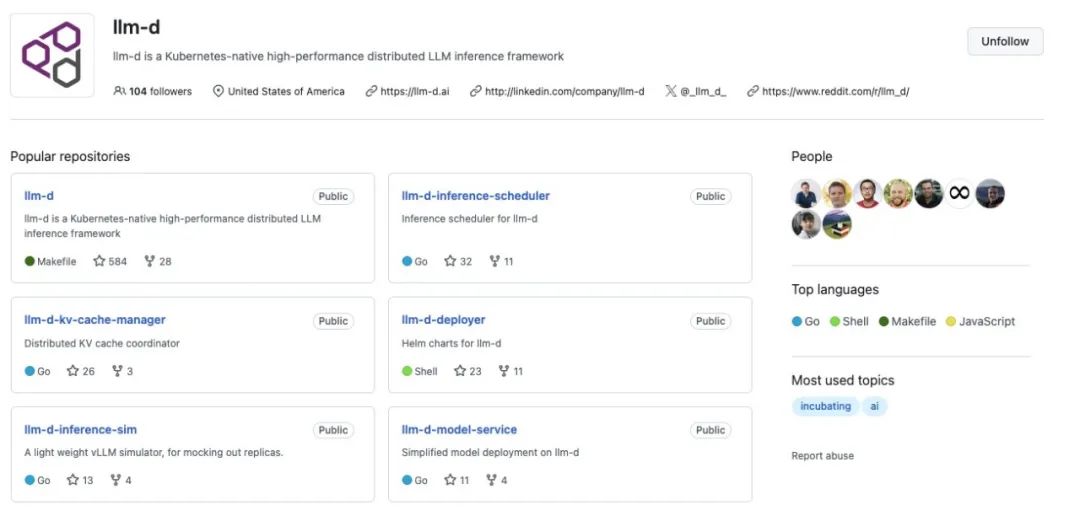
主项目仓库 包含项目文档、治理规则和整体架构设计 作为整个项目的中心枢纽
部署工具和Kubernetes的Helm图表 用于在Kubernetes环境中安装和配置完整的llm-d解决方案 提供快速入门体验
vLLM优化的推理调度系统实现 基于IGW的可定制负载均衡模式 实现P/D-、KV缓存-、SLA-和负载感知的决策 处理请求路由和流量控制
KV缓存管理系统,用于分布式缓存 提供可插拔的KV缓存层次结构 支持将KV缓存卸载到主机、远程存储和LMCache等系统
请求路由组件,用于流量管理 协助推理调度器进行请求分发 处理服务之间的通信
模型服务组件,与vLLM接口 负责模型加载和推理执行 实现分解服务功能,支持在独立实例上运行预填充和解码操作
性能测试和基准测试工具 用于评估系统性能和优化效果 帮助用户了解不同配置下的性能表现
推理模拟工具,用于开发和测试 模拟不同工作负载和流量模式 无需实际硬件即可测试系统行为
repos="llm-d llm-d-deployer llm-d-inference-scheduler llm-d-kv-cache-manager llm-d-routing-sidecar llm-d-model-service llm-d-benchmark llm-d-inference-sim"; for r in $repos; do git clone https://github.com/llm-d/$r.git; done
文章转载自AI云枢,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
