




目前只支持非推理型模型 没有会话历史的持久化存储 研究员智能体主要依赖网络搜索和爬虫工具,缺乏对结构化数据源(如数据库、API)的原生支持 对私有知识库的集成支持有限 集成MCP工具的加载过程相对简单,仅支持将工具添加到智能体中,但缺乏更复杂的交互机制,如工具间的协作、状态共享
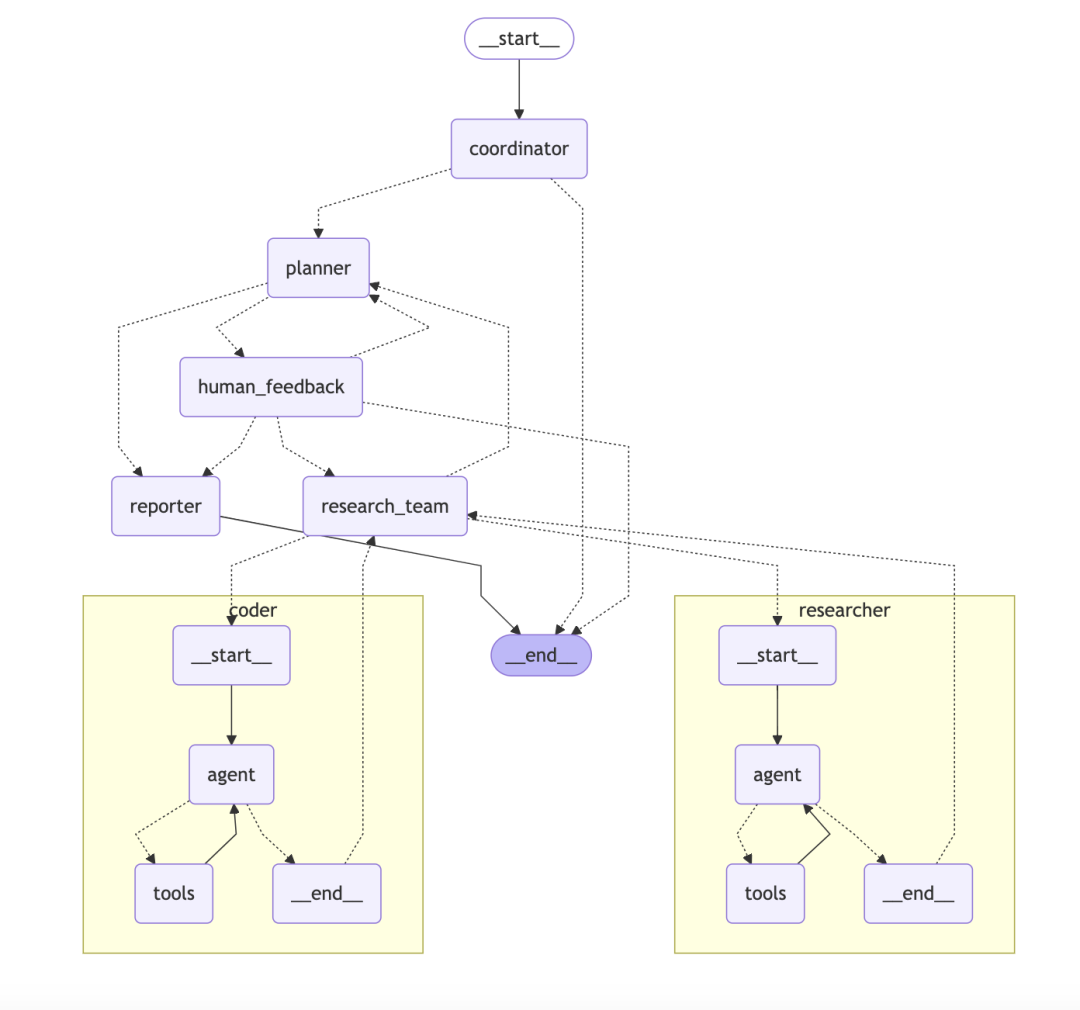
协调器(Coordinator):作为入口点,管理工作流生命周期 基于用户输入启动研究过程 在适当时候将任务委派给规划器 作为用户和系统之间的主要接口 规划器(Planner):负责任务分解和规划的战略组件 分析研究目标并创建结构化执行计划 确定是否有足够的上下文或是否需要更多研究 管理研究流程并决定何时生成最终报告 研究团队(Research Team):执行计划的专业智能体集合 研究员(Researcher):使用网络搜索引擎、爬虫等进行网络搜索和信息收集 程序员(Coder):使用Python REPL工具处理代码分析、执行和技术任务 报告员(Reporter):研究输出的最终阶段处理器 汇总研究团队的发现 处理和结构化收集的信息 生成全面的研究报告
通过litellm支持多种模型 支持Qwen等开源模型 提供OpenAI兼容的API接口
通过Tavily、Brave Search等进行网络搜索 使用Jina进行网页爬取 MCP无缝集成,扩展私有域访问等功能
支持使用自然语言交互式修改研究计划 支持类似Notion的块编辑,允许AI辅助润色
AI驱动的播客脚本生成和音频合成 自动创建PowerPoint演示文稿
Python:版本3.12+ Node.js:版本22+
克隆仓库 使用uv sync安装依赖 配置.env中的API密钥 配置conf.yaml中的模型设置 使用uv run main.py或使用bootstrap脚本运行Web UI
# 构建docker镜像docker compose build# 启动服务器docker compose up
doubao-1.5-pro-32k-250115 gpt-4o qwen-max-latest gemini-2.0-flash deepseek-v3
文章转载自AI云枢,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
