




❝开始讲算法的时候隐约有种回到20年前搞信息学奥赛拿的错觉,最近还真有人叫我开OI的班,技术扶贫怎么能收钱呢,虽然都开始扶贫大家的下一代了...
❞
串行排序
可能大家学算法的时候最开始学的就是排序算法, 而这些算法都是单机上的串行执行的排序算法。
冒泡和快排
这个就不用多解释了...
#include <stdio.h>
#include <stdlib.h>
#include <time.h>
#define swap(a, b) (a ^= b, b ^= a, a ^= b)
#define MAXN 10000
int cmpfunc(const void *a, const void *b)
{
return (*(int *)a - *(int *)b);
}
void bubble_sort(int a[], int n)
{
for (int j = 0; j < n - 1; j++)
{
for (int i = 0; i < n - 1 - j; i++)
if (a[i] > a[i + 1])
{
swap(a[i], a[i + 1]);
}
}
}
int randInt(int min, int max)
{
return rand() % (max - min) + min;
}
int main(int argc, char **argv)
{
int n1[MAXN], n2[MAXN], n3[MAXN];
struct timespec t1, t2;
srand(time(NULL));
for (int i = 0; i < MAXN; i++)
{
int value = randInt(0, 100000);
n1[i] = value;
n2[i] = value;
}
//bubble_sort
clock_gettime(CLOCK_REALTIME, &t1);
bubble_sort(n1, MAXN);
clock_gettime(CLOCK_REALTIME, &t2);
printf("bubble_sort:%ldns\n", (t2.tv_sec - t1.tv_sec) * 1000000000 + t2.tv_nsec - t1.tv_nsec);
//quick_sort
clock_gettime(CLOCK_REALTIME, &t1);
qsort(n2, MAXN, sizeof(int), cmpfunc);
clock_gettime(CLOCK_REALTIME, &t2);
printf("quick_sort:%ldns\n", (t2.tv_sec - t1.tv_sec) * 1000000000 + t2.tv_nsec - t1.tv_nsec);
return 0;
}
归并排序
这是一种简单的分治算法,通过将数据拆分成子序列,将子序列排序,然后将有序子列合并得到完全有序的序列。
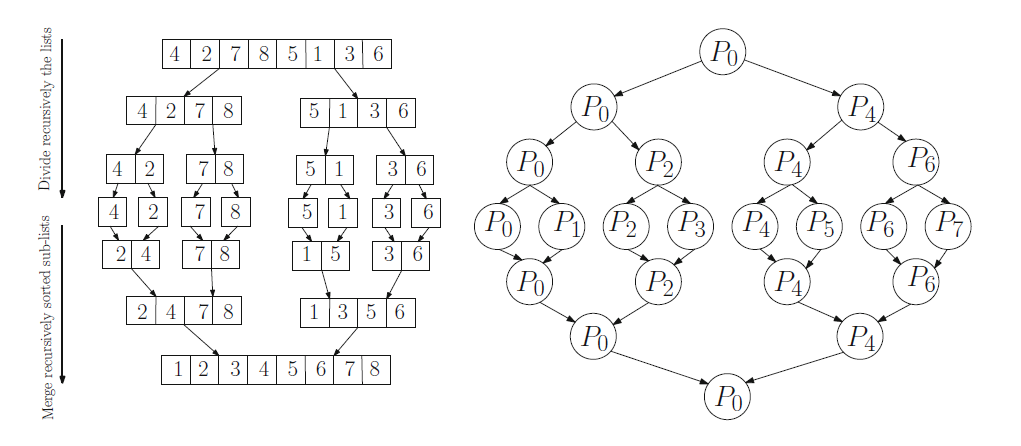
//merge A[head:mid], a[mid+1,tail], then write back to A[head:tail]
void merge(int arr[], int head, int mid, int tail)
{
int i, j, k;
int l_size = mid - head + 1;
int r_size = tail - mid;
//create temp array
int *L = (int *)malloc((l_size) * sizeof(int));
int *R = (int *)malloc((r_size) * sizeof(int));
for (i = 0; i < l_size; i++)
L[i] = arr[head + i];
for (j = 0; j < r_size; j++)
R[j] = arr[mid + 1 + j];
i = 0;
j = 0;
k = head;
//scan L and R
while (i < l_size && j < r_size)
{
if (L[i] < R[j])
{
arr[k] = L[i];
i++;
}
else
{
arr[k] = R[j];
j++;
}
k++;
}
//copy remaining
while (i < l_size)
{
arr[k] = L[i];
i++;
k++;
}
while (j < r_size)
{
arr[k] = R[j];
j++;
k++;
}
free(L);
free(R);
}
void merge_sort(int arr[], int head, int tail)
{
if (head < tail)
{
int mid = (head + tail) / 2;
merge_sort(arr, head, mid);
merge_sort(arr, mid + 1, tail);
merge(arr, head, mid, tail);
}
}
PSRS并行排序
Parallel Sorting by Regular Sampling, PSRS拼音输入法会自动联想成:破碎人生...真是有趣。这个算法分为四个阶段:
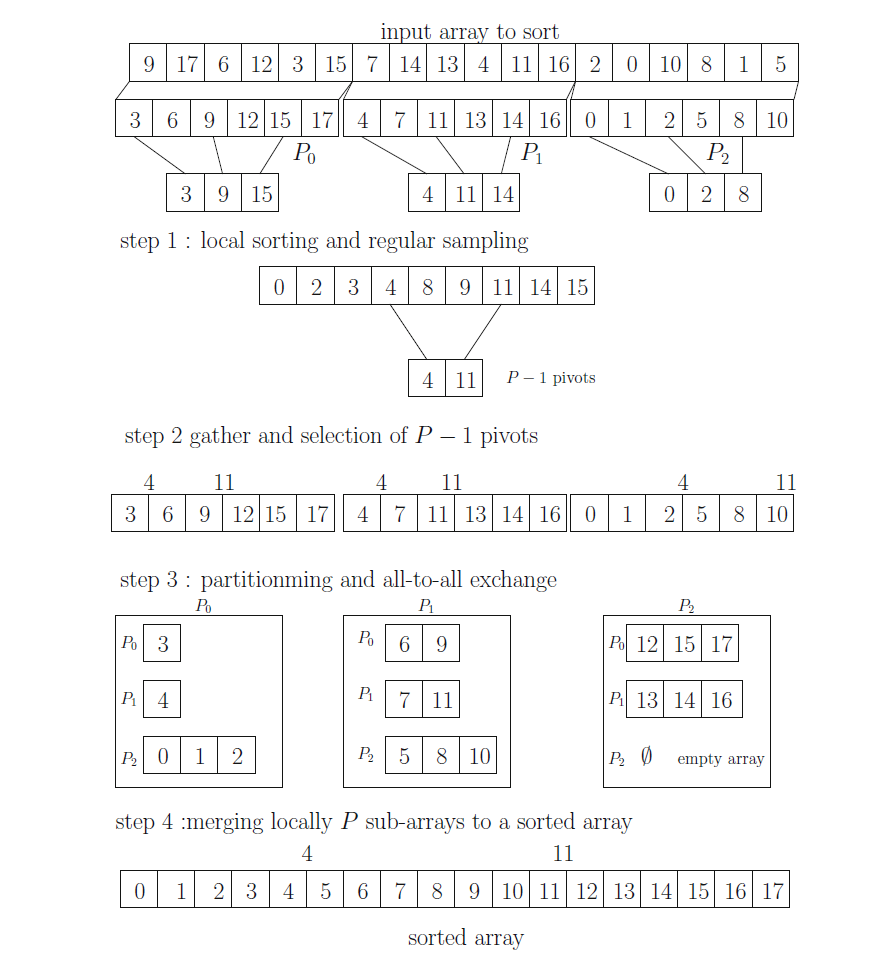
每个分区进程利用一个串行算法将本地数据排序 将本地数据正则采样,抽出关键值,然后对其归并排序后再进行正则采样 利用新的采样值对本地数据分区 合并数据,归并排序
分发数据
//scatter source data to other nodes.
int num_ele_per_node = MAXN / world_size;
int mod = MAXN % world_size;
int *sub_array = (int *)malloc(sizeof(int) * (num_ele_per_node + mod));
int s_cnt[world_size];
int s_offset[world_size];
for (int i = 0; i < world_size; i++)
{
s_cnt[i] = num_ele_per_node;
s_offset[i] = i * num_ele_per_node;
}
//剩余的分到最后一组
s_cnt[world_size-1] = num_ele_per_node+mod;
MPI_Scatterv(n4, s_cnt, s_offset, MPI_INT, sub_array, num_ele_per_node + mod, MPI_INT, 0, MPI_COMM_WORLD);
第一步,局部快排
int group_len = s_cnt[world_rank];
qsort(sub_array, group_len, sizeof(int), cmpfunc);
int *samples = (int *)malloc(world_size * sizeof(int));
选择Regular Sample
//step.1b select samples on each node
int sq_world_size = world_size * world_size;
for (int k = 1; k < world_size; k++)
samples[k - 1] = sub_array[k * num_ele_per_node / world_size];
//step.1c collect all samples
int *global_samples = (int *)malloc(sq_world_size * sizeof(int));
MPI_Gather(samples, world_size - 1, MPI_INT, global_samples, world_size - 1, MPI_INT, 0, MPI_COMM_WORLD);
选择全局分割点,并广播给其它各节点
//step.1d select pivots
int pivots[world_size];
if (world_rank == 0)
{
qsort(global_samples, (world_size - 1) * world_size, sizeof(int), cmpfunc);
for (int k = 1; k < world_size; k++)
pivots[k - 1] = global_samples[k * (world_size - 1)];
}
//step.1e bcast pivots
MPI_Bcast(pivots, world_size - 1, MPI_INT, 0, MPI_COMM_WORLD);
本地分割
//step.2a split local array
int index = 0;
int p_cnt[world_size];
for (int i = 0; i < world_size; i++)
p_cnt[i] = 0;
pivots[world_size - 1] = 2147483647;
for (int i = 0; i < group_len; i++)
{
if (sub_array[i] <= pivots[index])
p_cnt[index]++;
else
{
i--;
index++;
}
}
准备本地buffer和需要接收的数据
其中MPI_Alltoall是一个很经典的玩法,可以将每个节点的需要接收的数据同步。
//step.2b exchange each segment length from p_cnt to r_cnt
int r_cnt[world_size];
MPI_Alltoall(p_cnt, 1, MPI_INT, r_cnt, 1, MPI_INT, MPI_COMM_WORLD);
int r_offset[world_size];
r_offset[0] = 0;
s_offset[0] = 0;
for (int i = 1; i < world_size; i++)
{
s_offset[i] = s_offset[i - 1] + p_cnt[i - 1];
r_offset[i] = r_offset[i - 1] + r_cnt[i - 1];
}
int total_cnt = 0;
for (int i = 0; i < world_size; i++)
total_cnt += r_cnt[i];
int *sub_array2 = (int *)malloc(total_cnt * sizeof(int));
MPI_Alltoallv(sub_array, p_cnt, s_offset, MPI_INT, sub_array2, r_cnt, r_offset, MPI_INT, MPI_COMM_WORLD);
merge_sort(sub_array2, 0, total_cnt - 1);
最后Gather拿到所有数据
MPI_Gather(&total_cnt, 1, MPI_INT, r_cnt, 1, MPI_INT, 0, MPI_COMM_WORLD);
r_offset[0] = 0;
for (int i = 1; i < world_size; i++)
r_offset[i] = r_offset[i - 1] + r_cnt[i - 1];
MPI_Gatherv(sub_array2, total_cnt, MPI_INT, n5, r_cnt, r_offset, MPI_INT, 0, MPI_COMM_WORLD);
并行测试结果,可以见到当节点数大于2时就比qsort快了。
zartbot@zartbotWS:~/Desktop/mpi$ mpiexec -np 1 ./qs
mpi time: 30741448ns
quick_sort: 13068417ns
merge_sort: 19825194ns
zartbot@zartbotWS:~/Desktop/mpi$ mpiexec -np 2 ./qs
mpi time: 21733170ns
quick_sort: 13721354ns
merge_sort: 19732058ns
zartbot@zartbotWS:~/Desktop/mpi$ mpiexec -np 4 ./qs
mpi time: 13931970ns
quick_sort: 16625924ns
merge_sort: 20261184ns
zartbot@zartbotWS:~/Desktop/mpi$ mpiexec -np 8 ./qs
mpi time: 8299586ns
quick_sort: 16050739ns
merge_sort: 21257035ns
zartbot@zartbotWS:~/Desktop/mpi$ mpiexec -np 16 ./qs
mpi time: 4717631ns
quick_sort: 14314263ns
merge_sort: 21430261ns
zartbot@zartbotWS:~/Desktop/mpi$ mpiexec -np 24 ./qs
mpi time: 3984703ns
quick_sort: 22020000ns
merge_sort: 22696114ns
zartbot@zartbotWS:~/Desktop/mpi$ mpiexec -np 32 ./qs
mpi time: 3203447ns
quick_sort: 16230325ns
merge_sort: 21357250ns
zartbot@zartbotWS:~/Desktop/mpi$ mpiexec -np 48 ./qs
mpi time: 3565351ns
quick_sort: 15976286ns
merge_sort: 21657906ns
测试代码
#include <stdio.h>
#include <stdlib.h>
#include <time.h>
#include "mpi.h"
#define swap(a, b) (a ^= b, b ^= a, a ^= b)
#define MAXN 100000
int randInt(int min, int max)
{
return rand() % (max - min) + min;
}
void bubble_sort(int arr[], int n)
{
for (int j = 0; j < n - 1; j++)
{
for (int i = 0; i < n - 1 - j; i++)
if (arr[i] > arr[i + 1])
{
swap(arr[i], arr[i + 1]);
}
}
}
int cmpfunc(const void *a, const void *b)
{
return (*(int *)a - *(int *)b);
}
//merge A[head:mid], a[mid+1,tail], then write back to A[head:tail]
void merge(int arr[], int head, int mid, int tail)
{
int i, j, k;
int l_size = mid - head + 1;
int r_size = tail - mid;
//create temp array
int *L = (int *)malloc((l_size) * sizeof(int));
int *R = (int *)malloc((r_size) * sizeof(int));
for (i = 0; i < l_size; i++)
L[i] = arr[head + i];
for (j = 0; j < r_size; j++)
R[j] = arr[mid + 1 + j];
i = 0;
j = 0;
k = head;
//scan L and R
while (i < l_size && j < r_size)
{
if (L[i] < R[j])
{
arr[k] = L[i];
i++;
}
else
{
arr[k] = R[j];
j++;
}
k++;
}
//copy remaining
while (i < l_size)
{
arr[k] = L[i];
i++;
k++;
}
while (j < r_size)
{
arr[k] = R[j];
j++;
k++;
}
free(L);
free(R);
}
void merge_sort(int arr[], int head, int tail)
{
if (head < tail)
{
int mid = (head + tail) / 2;
merge_sort(arr, head, mid);
merge_sort(arr, mid + 1, tail);
merge(arr, head, mid, tail);
}
}
int main(int argc, char **argv)
{
int n1[MAXN], n2[MAXN], n3[MAXN], n4[MAXN], n5[MAXN];
double mpi_start_time, mpi_end_time;
struct timespec t1, t2;
srand(time(NULL));
int world_rank, world_size;
MPI_Init(&argc, &argv);
MPI_Comm_size(MPI_COMM_WORLD, &world_size);
MPI_Comm_rank(MPI_COMM_WORLD, &world_rank);
//prepare random data
if (world_rank == 0)
{
for (int i = 0; i < MAXN; i++)
{
int value = randInt(0, 100000);
n1[i] = value;
n2[i] = value;
n3[i] = value;
n4[i] = value;
//printf("number[%d] is %d\n",i,number[i]);
}
}
//scatter source data to other nodes.
int num_ele_per_node = MAXN / world_size;
int mod = MAXN % world_size;
int *sub_array = (int *)malloc(sizeof(int) * (num_ele_per_node + mod));
int s_cnt[world_size];
int s_offset[world_size];
for (int i = 0; i < world_size; i++)
{
s_cnt[i] = num_ele_per_node;
s_offset[i] = i * num_ele_per_node;
}
//剩余的分到最后一组
s_cnt[world_size-1] = num_ele_per_node+mod;
MPI_Scatterv(n4, s_cnt, s_offset, MPI_INT, sub_array, num_ele_per_node + mod, MPI_INT, 0, MPI_COMM_WORLD);
MPI_Barrier(MPI_COMM_WORLD);
mpi_start_time = MPI_Wtime();
//step.1a qsort sub array
int group_len = s_cnt[world_rank];
qsort(sub_array, group_len, sizeof(int), cmpfunc);
int *samples = (int *)malloc(world_size * sizeof(int));
//step.1b select samples on each node
int sq_world_size = world_size * world_size;
for (int k = 1; k < world_size; k++)
samples[k - 1] = sub_array[k * num_ele_per_node / world_size];
//step.1c collect all samples
int *global_samples = (int *)malloc(sq_world_size * sizeof(int));
MPI_Gather(samples, world_size - 1, MPI_INT, global_samples, world_size - 1, MPI_INT, 0, MPI_COMM_WORLD);
//step.1d select pivots
int pivots[world_size];
if (world_rank == 0)
{
qsort(global_samples, (world_size - 1) * world_size, sizeof(int), cmpfunc);
for (int k = 1; k < world_size; k++)
pivots[k - 1] = global_samples[k * (world_size - 1)];
}
//step.1e bcast pivots
MPI_Bcast(pivots, world_size - 1, MPI_INT, 0, MPI_COMM_WORLD);
//step.2a split local array
int index = 0;
int p_cnt[world_size];
for (int i = 0; i < world_size; i++)
p_cnt[i] = 0;
pivots[world_size - 1] = 2147483647;
for (int i = 0; i < group_len; i++)
{
if (sub_array[i] <= pivots[index])
p_cnt[index]++;
else
{
i--;
index++;
}
}
//step.2b exchange each segment length from p_cnt to r_cnt
int r_cnt[world_size];
MPI_Alltoall(p_cnt, 1, MPI_INT, r_cnt, 1, MPI_INT, MPI_COMM_WORLD);
int r_offset[world_size];
r_offset[0] = 0;
s_offset[0] = 0;
for (int i = 1; i < world_size; i++)
{
s_offset[i] = s_offset[i - 1] + p_cnt[i - 1];
r_offset[i] = r_offset[i - 1] + r_cnt[i - 1];
}
int total_cnt = 0;
for (int i = 0; i < world_size; i++)
total_cnt += r_cnt[i];
int *sub_array2 = (int *)malloc(total_cnt * sizeof(int));
MPI_Alltoallv(sub_array, p_cnt, s_offset, MPI_INT, sub_array2, r_cnt, r_offset, MPI_INT, MPI_COMM_WORLD);
merge_sort(sub_array2, 0, total_cnt - 1);
MPI_Gather(&total_cnt, 1, MPI_INT, r_cnt, 1, MPI_INT, 0, MPI_COMM_WORLD);
r_offset[0] = 0;
for (int i = 1; i < world_size; i++)
r_offset[i] = r_offset[i - 1] + r_cnt[i - 1];
MPI_Gatherv(sub_array2, total_cnt, MPI_INT, n5, r_cnt, r_offset, MPI_INT, 0, MPI_COMM_WORLD);
MPI_Barrier(MPI_COMM_WORLD);
mpi_end_time = MPI_Wtime();
if (world_rank == 0)
{
printf("mpi time:%15.0fns\n", (mpi_end_time - mpi_start_time) * 1e9);
}
if (world_rank == 0)
{
/* bubble_sort
clock_gettime(CLOCK_REALTIME, &t1);
bubble_sort(n1, MAXN);
clock_gettime(CLOCK_REALTIME, &t2);
printf("bubble_sort:%ldns\n", (t2.tv_sec - t1.tv_sec) * 1000000000 + t2.tv_nsec - t1.tv_nsec);
*/
//quick_sort
clock_gettime(CLOCK_REALTIME, &t1);
qsort(n2, MAXN, sizeof(int), cmpfunc);
clock_gettime(CLOCK_REALTIME, &t2);
printf("quick_sort:%13ldns\n", (t2.tv_sec - t1.tv_sec) * 1000000000 + t2.tv_nsec - t1.tv_nsec);
//merge_sort
clock_gettime(CLOCK_REALTIME, &t1);
merge_sort(n3, 0, MAXN - 1);
clock_gettime(CLOCK_REALTIME, &t2);
printf("merge_sort:%13ldns\n", (t2.tv_sec - t1.tv_sec) * 1000000000 + t2.tv_nsec - t1.tv_nsec);
//validate sort result
for (int i = 0; i < MAXN; i++)
{
if (n2[i] != n5[i])
{
printf("number[%d] is %d-%d\n", i, n2[i], n5[i]);
}
}
}
MPI_Finalize();
return 0;
}
文章转载自zartbot,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
